発展編! Haskellで「型」のポテンシャルを最大限に引き出すには?【第二言語としてのHaskell】
第二言語としてHaskellを学習するシリーズ。発展編では、実践編で定義した型と関数をモジュールにする方法と、型を見直して関数をさらに安全なものにする方法を紹介します。さらに勉強したい方向けの超発展編付き!
こんにちは。Haskell-jpの山本悠滋(igrep)です。
Haskellらしいプログラミングとは何か? について、これまで基本と実践を解説してきました。
実践編では、問題にあった型を自分で定義し、
その型を使った関数を定義していくというHaskellプログラミングの流れを、
トランプゲームのブラックジャックの手札の合計計算という例を使って学びました。
この記事ではさらに発展的なHaskellプログラミングの道を示すべく、次の2つの課題に取り組みます。
- 定義した型と関数をモジュールにする方法
- 型を見直して、関数をさらに安全なものにしていく例の紹介
記事の後半では、Haskellをさらに理解したい人が学ぶべきポイントや、役立つ教材・コミュニティなどを紹介します。
課題1. モジュールを使って、Card型の内部構造を隠蔽する
最初に取り組むのは、関数や型をモジュールにする方法です。 モジュールは、名前空間を分けることで、関数や型を再利用する際に名前が衝突してしまうのを防いだり、複数の関数や型を意味のあるまとまりに分割したりするための機能を提供してくれます。
そのため、モジュールには次のような効果があります。
- 作成した関数や型を他の人が利用できるようにする
- 作成した型の内部構造をライブラリーの利用者から隠蔽する
Haskellでより大きなアプリケーションを作るとき、モジュールに関する知識は必要不可欠になるでしょう。
以降では、説明の題材として、実践編で実装したsumHand関数とCard型を使います。
Haskellのモジュールとは
sumHandは、ブラックジャックにおける手札の最適な合計を計算する関数でした。
Card型はトランプのカードを表す型で、sumHandもCard型を利用しています。
これらをモジュールにすれば、他の人にも使ってもらえるようになります。
下記のリポジトリーに、あらかじめ筆者がHaskellのモジュールとして作成済みのものがあるので、このソースコードを見ながら解説していきましょう。
下記のコマンドを実行して上記のリポジトリーをcloneし、no-haddockという解説用のブランチに切り替えてください。
$ git clone https://gitlab.com/igrep/haskell-as-second-language-blackjack.git $ cd haskell-as-second-language-blackjack $ git checkout origin/no-haddock
cloneできたら、src/BlackJack.hsをお使いのテキストエディターで開いてみてください。
下記のようなHaskellのソースコードが冒頭に見えるはずです。
この部分が、Haskellにおけるモジュールの宣言になります。
module BlackJack ( Card(A, J, Q, K) , cardForTestData , deck , heartSuit , diaSuit , cloverSuit , spadeSuit , sumHand ) where ...
冒頭のmoduleで始まりwhereで終わる箇所では、このモジュールの名前と、このモジュールがエクスポートする関数や型、値コンストラクターの名前のリストを記載しています。
ここでエクスポートされた関数や型、値コンストラクターなどを、このモジュールのユーザーが実際に利用できるようになります。
上記の例では、それぞれ以下のようになっています。
- モジュールの名前は、
BlackJack - エクスポートする名前のリストは、丸カッコで囲った
(Card(A, J, Q, K), cardForTestData, deck, heartSuit, diaSuit, cloverSuit, spadeSuit , sumHand)
エクスポートする名前のリストには、実践編で定義したCard型やsumHand関数をはじめとして、さまざまな関数や型が列挙されているのがわかります。
丸カッコ内で改行するとき、カンマを各行の先頭に書いているところにも注目してください。行の末尾にカンマを書いてもよいのですが、Haskellコミュニティーの慣習的に、カンマ区切りのものを改行して列挙するときには行頭にカンマを書くことが多くあります。
型と値コンストラクターのエクスポートと隠蔽
エクスポートする名前のうち、特筆すべき点は、Card(A, J, Q, K)という構文です。
ここで利用しているのは、型とともに「型の値コンストラクター」をエクスポートするための構文です。
型の名前(値コンストラクター1, 値コンストラクター2, ..., 値コンストラクターN)
同じことをしようとして下記のように書いてもエラーになってしまうのでご注意ください。
module BlackJack ( Card , A , J , Q , K -- .. 省略 .. )
なお、すべての値コンストラクターをエクスポートしたい場合は、下記のように型の名前(..)と書きます。
module BlackJack ( Card(..) -- .. 省略 .. )
さて、今回書いたモジュールの宣言では、上記のようにCard(..)と書いてCard型の値コンストラクターをすべてエクスポートするのではなく、Card(A, J, Q, K)と書くことで、N以外の値コンストラクターをエクスポートすることにしました。
なぜNをエクスポートしなかったのでしょうか?
それは、このモジュールのユーザー(このモジュールをimportするモジュール)に、あり得ないカードを作らせないためです。
Card型の定義では、2から10のカードを、Nという値コンストラクターに整数Int型の値を紐付けることで表現する、という方法をとりました。
この方法のおかげで、「N2 | N3 | N4 | N5 | N6 | N7 | N8 | N9 | N10」のように数字のカードごとに値コンストラクターを作らずに済んだり、カードが取り得る値への変換を容易に書けたりするといった効果があるのでした。
しかし、この方法には、実践編では触れていなかった重要な問題が1つあります。
Int型の値は、当然、負の数や10より大きい値も取り得るので、たとえばN 3141592など、あり得ない数字のカードが作れてしまうのです!
この問題を緩和するために、上記のモジュール宣言ではNだけをエクスポートしないように設定したのです。
Card(A, J, Q, K)と書くことで、このBlackJackモジュールを使用する側では、値コンストラクターNを直接利用できなくなります。
BlackJackモジュールでエクスポートされている関数や値からしか、値コンストラクターNを使用した値を利用できなくなるのです。
定数の宣言と定義とエクスポート
このBlackJackモジュールでは、値コンストラクターNを直接使用させない代わりに、heartSuit、diaSuit、cloverSuit、spadeSuit、deckという名前の「Cardのリスト」を利用できるようにしています。
そのリストを定義しているのが以下の部分です。
suit, heartSuit, diaSuit, cloverSuit, spadeSuit :: [Card] suit = [A] ++ map N [2..10] ++ [J, Q, K] heartSuit = suit diaSuit = suit cloverSuit = suit spadeSuit = suit deck :: [Card] deck = heartSuit ++ diaSuit ++ cloverSuit ++ spadeSuit
実践編の復習もかねて、それぞれ簡単に定義を説明しましょう。
上記のHaskellコードでは、suit、heartSuit、diaSuit、cloverSuit、spadeSuit、deckという6つの定数を定義しています。
ただし、このうちheartSuit、diaSuit、cloverSuit、spadeSuitの4つは、実態としてはsuitと同じ値であるとしています。
これは、ハート、ダイヤ、クローバー、スペードというトランプの4種類のスートごとに異なる名前を定義し分けているものの、今のところトランプを表すCard型にはスートによる区別が一切ないため、いずれも実態としては同じsuitとして扱うことにしているだけです。
まったく同じ値であれば、当然のことながら型もまったく同じものになるので、上記の1行めでは下記のように名前をカンマで区切った記法でまとめて宣言しています。
-- 同じ型の定数であれば、このようにまとめて宣言できる。 suit, heartSuit, diaSuit, cloverSuit, spadeSuit :: [Card]
suitの定義も見てみましょう。
suitの定義では、基本と実践で学んださまざまな機能を活用しています。
suit = [A] ++ map N [2..10] ++ [J, Q, K]
まず、map N [2..10]という式では、実践編で学んだmap関数を使用しています。
map関数は、「<関数>と<リスト>を受け取って、<リスト>の各要素を<関数>の引数として渡して実行し、<関数>の実行結果を新しいリストに入れる」という処理を行う関数でした。
ここでは、<関数>としてNを、<リスト>として[2..10]を渡しています。
関数としてmapに渡しているNは、Card型の値コンストラクターの1つです。
下記のように宣言することで、NがInt -> Card、つまり「Int型の値を受け取ってCard型の値を返す」関数になることを思い出してください。
関数なので、当然のごとくNをmap関数の引数として渡せます。
data Card = A | N Int | J | Q | K
suitの定義に戻りましょう。
mapの2つめの引数である[2..10]は、これまで登場していない構文ですが、
「2から10までの整数のリスト」(つまり[2,3,4,5,6,7,8,9,10])を簡単に作るための構文です。
したがって、map N [2..10]という式により作られるのは、「2から10までの整数に対してNを実行し、2から10までの数字のカードのリスト」ということになります。
1つのsuitに含まれる数字(2~10)のカードをすべて作っているというわけです。
[A]とmap N [2..10]、それに[J, Q, K]の間でそれぞれ使用している++は、リストを結合する演算子です。
ここでは、エースを表す[A]というリスト、絵柄のカードを表す[J, Q, K]というリスト、map N [2..10]で作った数字のカードのリストを結合して、1つのsuitに含まれるすべてのカードのリストを作っています。
最後のdeckは、トランプのデッキ(ゲームを行うのに必要なすべてのカードをそろえたセット)を表しています。
やはりリストを結合する演算子++を利用して各スート(heartSuit、diaSuit、cloverSuit、spadeSuit)を結合し、デッキを作っています。
deck :: [Card] deck = heartSuit ++ diaSuit ++ cloverSuit ++ spadeSuit
モジュールを利用してみよう
説明が長くなりましたが、このように定義されているBlackJackモジュールを実際に利用して試してみましょう。
利用するには、記事の冒頭でgit cloneしてきたリポジトリー(haskell-as-second-language-blackjack)にcdした上で、下記のようにstack buildコマンドを実行してください。
$ stack build
もし次のようなエラーメッセージが表示された場合は、必要なバージョンのGHCがインストールされていません。
No compiler found, expected minor version match with ghc-8.0.2 (x86_64) (based on resolver setting in /home/yu/Downloads/Dropbox/prg/prj/haskell-as-second-language-blackjack/stack.yaml). To install the correct GHC into /home/yu/.stack/programs/x86_64-linux/, try running "stack setup" or use the "--install-ghc" flag.
その場合は、下記を実行してGHCをインストールしてください。
$ stack setup
stack buildが成功したことを確認できたら、下記のサンプルプログラムをsample.hsという名前のファイルにコピペしてみてください。
import BlackJack main = print (sumHand [A, J, J])
冒頭でimport BlackJackとすることで、このプログラムでBlackJackモジュールを利用可能にしています。
プログラム自体は、手札が[A, J, J]という3つのカードで構成された場合の合計点数を表示するだけの、他愛のないものです。
それでも、main関数があるので、基本で説明したように実行可能なプログラムになります(ほかのプログラムにimportしてもらうモジュールではありません)。
上記のコードをsample.hsとして用意できたら、stack ghcコマンドでコンパイルしてみましょう。
$ stack ghc sample.hs [1 of 1] Compiling Main ( sample.hs, sample.o ) Linking sample ... $
ちゃんとコンパイルできましたね(コンパイルしたコマンドを実行してみてください)。
データ型の内部構造を隠蔽する
続いて、sample.hsを次のように書き換えて、BlackJackモジュールでエクスポートされていない値コンストラクターNが利用できないことを確認してみます。
import BlackJack main = print (sumHand [A, N 9, J])
BlackJackモジュールは値コンストラクターNをエクスポートしていないので、
N 9といった式でBlackJackモジュールがエクスポートしていない値コンストラクターを使用すると、コンパイルエラーになるはずです。
やってみましょう。
$ stack ghc sample.hs
[1 of 1] Compiling Main ( sample.hs, sample.o )
sample.hs:3:27: error:
Data constructor not in scope: N :: Integer -> Card
not in scope、すなわち存在しない、というエラーになりました! 意図したとおり、BlackJackモジュールの利用者からは値コンストラクターNを隠せているようですね。
このようにBlackJackモジュールでは、利用者に直接使用されるとトランプのカードとして不適切なカードが作れてしまうNを隠す(エクスポートしない)ことで、より仕様に忠実な値を提供しています。
Haskellのモジュールという仕組みは、単に名前空間を分けるだけでなく、よくあるオブジェクト指向プログラミング言語におけるprivateメソッドのような「データ型の内部構造を隠蔽する」ための仕組みを提供できるのです。
もちろん、ここで紹介した方法が唯一のやり方ではありません。別のやり方でエクスポートする設計もありだと思います。
たとえば、「Card型の値はおろかheartSuitなども一切エクスポートせず、deckのみをエクスポートすることで、Card型の値はdeckに含まれるもののみが利用できるようにする」というモジュールにすることもできるでしょう。
実際にBlackJackモジュールを使ってブラックジャックのゲームを実装していくなら、それで十分なはずです。
いずれにしても、Haskellでは、モジュールがエクスポートする関数・型・値コンストラクターを限定することで、モジュールの利用者に対してモジュールが満たすべき仕様を確実に守らせたり、モジュールの使い方(API)をより明確に示したりすることができます。
課題2. NonEmptyを使って、もっとバグが入りにくい実装を目指す
今度は、sumHand関数やtoPoint関数の定義や型宣言の改良を通して、「型が持っている制約によって、関数に対する要件を必然的に守らせる」というHaskellの醍醐味を体感していただきます。
sumHand関数にはどんな問題があるか?
まず、そもそも現状のsumHand関数にどんな問題が残っているのかをはっきりさせましょう。
sumHand関数を実装した際、「取り得る点数すべてを組み合わせて、組み合わせごとに合計を求める」処理では、下記のようなfoldlを使用した式を組み立てました。
scoreCandidates = foldl plusEach [0] possiblePoints
その際、foldlの第2引数、すなわち<初期値>の部分を空のリストにすると、plusEachの中で呼ばれるconcatMapが空のリストを受け取ってしまい、そのままfoldlも空のリストを返してしまう、という問題がありました。
この問題は、上記の式におけるpossiblePointsの中に仮に1つでも空のリストが混ざっていた場合、同様に発生します。
でも、実際にはそうはなりません。
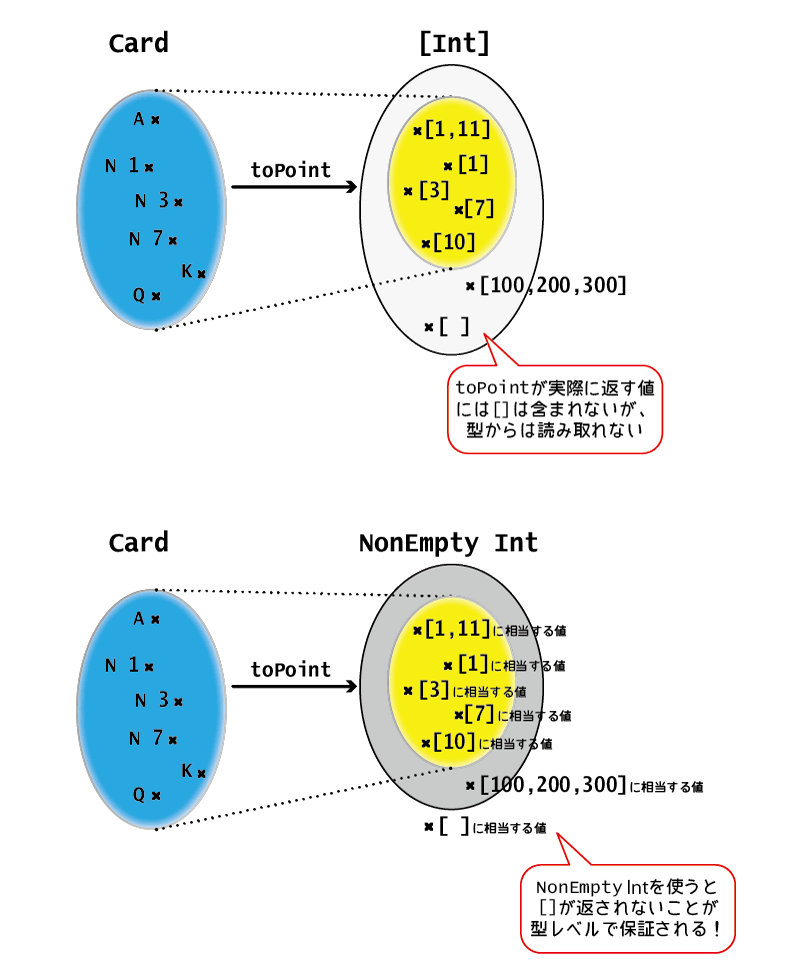
なぜなら、possiblePointsを作成する際に使ったtoPoint関数が、空のリストを返さないように作られているからです。
possiblePointsそのものが空のリストであった場合、foldl plusEach [0] possiblePointsは<初期値>として渡した[0]を返します。possiblePointsは「Intのリストのリスト」になっているため少しややこしいのですが、ここでは「Intのリストのリスト」の要素である「Intのリスト」のうちいずれか、すなわちmap関数に渡したtoPointが空のリストを返した場合を問題にしているのです。ご注意ください。
確認のために、改めてtoPoint関数の定義を見直してみましょう。
toPoint :: Card -> [Int] -- 関数の型の宣言 toPoint A = [1, 11] -- Aの場合は1と11を取り得る toPoint (N n) = [n] -- 通常の数字のカードであれば、カードに書かれた数字のみを取り得る toPoint _ = [10] -- そのほかの場合は10のみを取る
確かに、この定義を見れば、toPoint関数は「いかなる引数を受け取っても空のリストを返すことがない」ことがわかりますね。
しかしながら、このことは、toPoint関数の定義を実際に見に行かなければわかりません。
toPoint関数程度の短い単純な関数であれば、実際に実装を読むのもたいした手間ではないでしょう。
しかし、もっと複雑な関数、それも、あなたではない人が書いた関数について、はたして本当に空リストを返さないかどうかを見極めるのは困難になるでしょう。
これが、現状のtoPoint関数に残されている大きな問題です。
では、このような問題をどのような手段で解消すればいいでしょうか? Haskellでは、この問題にも「型」を利用した解決方法があります。
もしあなたがtoPoint関数(あるいは、もっと複雑な関数)を誰か別の人に書いてもらうとして、その人にtoPoint関数の振る舞いを簡単に説明し、
型宣言を教えるだけで「toPoint関数が返すリストが空でない」ことまで保証できるなら、もっと安心してtoPoint関数以外の部分の実装に取り組めるでしょう。
そこでここでは、文字通り空でないリストを提供してくれるData.List.NonEmptyというモジュールを紹介します。
Data.List.NonEmptyモジュールに入っているNonEmptyという型は、「先頭の要素」と「残りの(空かも知れない、普通の)リスト」をそれぞれプロパティとして持つことによって、必ず要素が1つ以上あるリストとなることを保証してくれます。
このNonEmptyを利用してsumHand関数とtoPoint関数、それにplusEach関数を書き換えていくことで、「型が持っている制約によって、関数に対する要件を必然的に守らせる」ことを体験してみましょう!

NonEmptyを使う
NonEmptyを使用する準備
さっそく、Data.List.NonEmptyモジュールからNonEmpty型をimportしましょう。
:|という演算子も合わせてインポートします。
import Data.List.NonEmpty (NonEmpty((:|)))
上記のimport文をコピーして、blackjack.hsの先頭に貼り付けてください。
それができたら、stack ghciコマンドを起動し、blackjack.hsを読み込んで、NonEmpty型が使用できるようになったことを:i NonEmptyで確認しましょう。
$ stack ghci > :l blackjack.hs > :i NonEmpty data NonEmpty a = a :| [a] -- Defined in ‘Data.List.NonEmpty’ instance Eq a => Eq (NonEmpty a) -- Defined in ‘Data.List.NonEmpty’ instance Monad NonEmpty -- Defined in ‘Data.List.NonEmpty’ instance Functor NonEmpty -- Defined in ‘Data.List.NonEmpty’ instance Ord a => Ord (NonEmpty a) -- Defined in ‘Data.List.NonEmpty’ instance Read a => Read (NonEmpty a) -- Defined in ‘Data.List.NonEmpty’ instance Show a => Show (NonEmpty a) -- Defined in ‘Data.List.NonEmpty’ instance Applicative NonEmpty -- Defined in ‘Data.List.NonEmpty’ instance Foldable NonEmpty -- Defined in ‘Data.List.NonEmpty’ instance Traversable NonEmpty -- Defined in ‘Data.List.NonEmpty’
上記のようにNonEmpty型の情報が出力されるはずです。
:i NonEmptyを実行した直後に出力されるdata NonEmpty a = a :| [a]という部分が、NonEmpty型の定義です。
ここまでに登場した型とは違う、ちょっと見慣れない定義ですね。詳しく解説しましょう。
あらかじめ注記しておきますが、NonEmptyの定義はHaskellにおけるほかの型の定義と比べてけっこう変わっています。
NonEmptyの定義
NonEmpty型は次のような定義になっています。
data NonEmpty a = a :| [a]
data NonEmptyで「NonEmptyという型の名前を宣言」しているのは、他の型と同じです。
しかし今回は、その後にすぐイコール記号がくるのではなく、小文字のaが続いています。
このaは、filter関数の型宣言で出てきた型変数です。
正確には、NonEmpty型が受け取る型引数の宣言です。
NonEmptyには、リストと同じように任意の型の要素を格納できなければならないので、「要素の型」として型引数を受け取るものとして定義されています。
続いて、イコールより後ろ、すなわちNonEmpty型の定義の本体に当たる部分です。ここには、Card型を定義したときと同様、NonEmpty型の値コンストラクターとその引数が列挙されているはずです。
でも、a :| [a]という構文のどこをどう読めば、値コンストラクターと引数がわかるのでしょうか……?
実は、a :| [a]の真ん中にある「:|」という、なんだか英語圏の顔文字みたいな記号が、NonEmpty型の値コンストラクターの名前です。
そして、この値コンストラクターは、左右にあるaおよび[a]という(型の値の)2つの引数を取ります。
これだけでは話が見えないと思うので、詳しく説明しましょう。
Haskellは、いろいろな記号を二項演算子として定義できるという、変わった特徴を備えています。しかも、値コンストラクターさえ、記号を使って二項演算子として定義できます。
ただし、値コンストラクターを記号で定義する場合には、必ず名前をコロン:で始めなければなりません。
実際のところ、たまにしか使われない機能なのですが、それがNonEmpty型の定義では使用されているのです。
つまり、演算子:|は、左辺にa型の値、右辺に[a]型の値(aのリスト)を受け取ることで、NonEmpty型の値を作り出します。
先ほど、NonEmptyという型は「先頭の要素」と「残りの(空かも知れない普通の)リスト」をそれぞれプロパティとして持つと述べたとおり、値コンストラクター:|は引数として「a型の値」を1つと「そのリスト」を受け取るのです。
実際にNonEmpty型の値をいくつか作って試してみましょう。
-- 真偽値の空ではないリスト > True :| [True, False] True :| [True,False] > :t True :| [True, False] True :| [True, False] :: NonEmpty Bool -- Num型クラスを実装した何らかの型aの値の、空ではないリスト > 1 :| [1,2,3] 1 :| [1,2,3] > :t 1 :| [1,2,3] 1 :| [1,2,3] :: Num a => NonEmpty a -- 文字型の空ではないリスト。 -- 文字列は文字のリストなので「空ではない文字列」とも言える。 > 'a' :| "abc" 'a' :| "abc" > :t 'a' :| "abc" 'a' :| "abc" :: NonEmpty Char -- 真偽値のリストの空ではないリスト -- 「空ではないリスト」の各要素は空になり得る点に注意 > [] :| [[True]] [] :| [[True]] > :t [] :| [[True]] [] :| [[True]] :: NonEmpty [Bool]
ちゃんとNonEmpty型の値が作れましたね。
NonEmpty型の値を操作する関数
続いて、これから使うNonEmpty型の値を操作するための便利な関数をimportします。
先ほどblackjack.hsに追記したimport文に、さらに次のimport文を書き加えてください。
import qualified Data.List.NonEmpty as NonEmpty import Data.Semigroup (sconcat)
上記のうち1つめのimport qualified Data.List.NonEmpty as NonEmptyという行では、Data.List.NonEmptyモジュールをNonEmptyという修飾語で修飾付きインポート(qualifiedインポート)しています。
このようにqualifiedで「修飾付きインポート」をすると、そのモジュールが提供している任意の型や関数を「モジュール名.名前」というふうにピリオド付きの表記で参照できるようになります。
したがって、以降ではData.List.NonEmptyの任意の型や関数がNonEmpty.<名前>として参照できるようになります。
Data.List.NonEmptyモジュールでは、NonEmpty型の値を扱う関数として、mapやfilterといった標準のリストに対する関数と同じ名前のものを数多くエクスポートしています。
NonEmpty型に対する関数と、標準のリストに対する関数とをプログラムの中で区別できるようにするために、ここでは修飾付きimportを使用しました。
2つめのimport Data.Semigroup (sconcat)では、Data.Semigroupモジュールが提供してくれるsconcatという関数をimportしています。
Data.Semigroupモジュールは、NonEmpty型とよく似たさまざまなデータ構造に対する便利な関数や型クラスを提供してくれます。
今回は、Data.List.NonEmptyをimportするだけでは使えないsconcatという便利な関数が必要だったのでimportしました。
どんな関数かは後のお楽しみに。
上記の2つのimport文を追加できたら、また:l blackjack.hsして読み込んで試してみましょう。
> :l blackjack.hs > :t NonEmpty.map NonEmpty.map :: (a -> b) -> NonEmpty a -> NonEmpty b > NonEmpty.map not (True :| [False]) False :| [True] > :t sconcat sconcat :: Data.Semigroup.Semigroup a => NonEmpty a -> a
上記のようにNonEmpty.map関数やsconcat関数などが利用できるようになっていればOKです!
toPoint関数を書き換える
それでは、いよいよNonEmpty型を使ってsumHand関数やtoPoint関数を改良してみましょう。
まずはtoPoint関数です。
toPoint :: Card -> [Int] -- 関数の型の宣言 toPoint A = [1, 11] -- Aの場合は1と11を取り得る toPoint (N n) = [n] -- 通常の数字のカードであれば、カードに書かれた数字のみを取り得る toPoint _ = [10] -- そのほかの場合は10のみを取る
ここでNonEmpty型を使う動機を思い出しておきましょう。
「toPoint関数が必ず空でないリストを返すことを、NonEmpty型に書き換えることにより、型レベルで保証したい」というのが動機です。
そこで、まずは型宣言から書き換えてみます。
toPoint :: Card -> NonEmpty Int -- 関数の型の宣言 toPoint A = [1, 11] -- Aの場合は1と11を取り得る toPoint (N n) = [n] -- 通常の数字のカードであれば、カードに書かれた数字のみを取り得る toPoint _ = [10] -- そのほかの場合は10のみを取る
NonEmpty型の値を返すように関数の本体を書き換える
当たり前ですが、上記のように型宣言を書き換えただけの状態では型エラーになってしまいます。stack ghciコマンドを使って再度blackjack.hsを読み込むと、次のような内容のコンパイルエラーがいくつも出てきて圧倒されると思います。
...
blackjack.hs:1404:13: error:
• Couldn't match expected type ‘NonEmpty Int’
with actual type ‘[Integer]’
• In the expression: [1, 11]
In an equation for ‘toPoint’: toPoint A = [1, 11]
...
これは、Couldn't match expected type ‘NonEmpty Int’とあるとおり、「型宣言に書いた型と実際にtoPoint関数が返している型が違うよ!」というエラーです。
上記以外にも似たようなエラーメッセージが出てくると思いますが、だいたい同じ内容になっているはずです。
上記のエラーメッセージの3行めでactual type(すなわちtoPoint関数が実際に返す型)が[Int]ではなく[Integer]となっているのは、Num型クラスのデフォルトがIntegerとなっているためなので、安心してください。
基本で説明したとおり、整数のリテラルの型が決定できない場合にはデフォルトとしてIntegerを採用する、というルールでした。
エラーの原因は、明らかに、toPoint関数の返す値が普通の(空かもしれない)リストのままであることです。そこで、空ではないリスト、つまりNonEmpty型の値を返すように関数の本体を書き換えましょう。
NonEmpty型の値を作るには、演算子:|の左辺に先頭の値、右辺に残りの(空かもしれない)普通のリストを渡せばよいのでした。
toPoint :: Card -> NonEmpty Int toPoint A = 1 :| [11] -- 先頭の要素1と、残りの要素11を持つNonEmpty toPoint (N n) = n :| [] -- 先頭の要素nだけのNonEmpty toPoint _ = 10 :| [] -- 先頭の要素10だけのNonEmpty
普通のリスト用の関数をNonEmpty型用の関数に切り替える
上記のようにtoPoint関数を書き換えたら、再びblackjack.hsを読み込んでみましょう。
今度はコンパイルエラーが次のように変わったかと思います。
blackjack.hs:1439:44: error:
• Couldn't match type ‘NonEmpty Int’ with ‘[Int]’
Expected type: [[Int]]
Actual type: [NonEmpty Int]
• In the third argument of ‘foldl’, namely ‘possiblePoints’
In the expression: foldl plusEach [0] possiblePoints
In an equation for ‘scoreCandidates’:
scoreCandidates = foldl plusEach [0] possiblePoints
これは、「map toPoint cardsの結果を入れた変数possiblePointsの型が異なる」というエラーです。
ここでは、foldlの3つめの引数が[[Int]](Intのリストのリスト)であることを期待しているのでExpected type: [[Int]]と表示されています。
Actual type: [NonEmpty Int]というのは、実際のpossiblePointsの型が[NonEmpty Int](「Intの空ではないリスト」のリスト)であることを指しています。
今度のエラーはどうやって直せばよいでしょうか? エラーメッセージによると、コンパイラが「期待している型(Expected type)」は[[Int]](Intのリストのリスト)です。
しかし、今実際に私たちがやっているのは、普通のリストを使わず、空ではないリスト[NonEmpty Int]を使うための書き換えです。
したがって、間違っているのは[[Int]]、すなわちfoldlの引数の型のほうです。
というわけで、foldlの引数の型がpossiblePointsの型[NonEmpty Int]となるよう、foldlの他の引数の型を変えていきましょう。
まず、foldlの第1引数、すなわち<関数>を変えます。
ここでは、plusEachという関数によって、「リストの各要素の組み合わせごとの和」を計算していたのでした。
plusEach :: [Int] -> [Int] -> [Int] plusEach list1 list2 = concatMap (\element1 -> -- 1つ目のリストの各要素を、 map (\element2 -> -- 2つ目のリストの各要素と、 element1 + element2 -- 足し合わせる ) list2 ) list1
foldlの仕様上、foldlに渡す<関数>は、第3引数である<リスト>の各要素の型を受け取れなければなりません。
ここでの<リスト>とはpossiblePointsであり、その型は[NonEmpty Int]でした。
したがって、要素の型はNonEmpty Intとなります。
というわけで、plusEach関数の型を書き換えて、下記のようにNonEmpty Intを扱うようにしましょう。
plusEach :: NonEmpty Int -> NonEmpty Int -> NonEmpty Int
foldlの仕様についてしっかりと理解している方は、実際に変更する必要があるのは第2引数の型だけであることにお気づきかもしれません。
しかし、ここでは個人的な好みにより、第1引数も戻り値の型もNonEmpty Intに変えています。
もちろん、型を変えるだけではダメで、plusEach関数が実際に使用する関数をNonEmpty型向けの関数に変えたり、戻り値をNonEmpty型の値にするよう、plusEach関数の本体も書き換える必要があります。
具体的には、これまで使用していたmap関数を、NonEmpty型用のNonEmpty.mapに変えてください。
concatMapも変える必要がありますが、残念ながらData.List.NonEmptyモジュールにはconcatMapに相当するものが存在しません。
そこで、NonEmpty.mapと、Data.Semigroupからimportしたsconcatとを組み合わせることで、NonEmpty向けのconcatMapを実装します。
sconcatは、普通のリストで言うところのconcatに相当します。
以上をまとめると、plusEachの実装は次のように書き換えられます。
複雑で面倒なことをしているように思えるかもしれませんが、ここでやっていることは、基本的には「普通のリスト用の関数をNonEmpty型用の関数に切り替える」だけです。
plusEach :: NonEmpty Int -> NonEmpty Int -> NonEmpty Int plusEach list1 list2 = sconcat ( NonEmpty.map (\element1 -> -- 1つ目のリストの各要素を、 NonEmpty.map (\element2 -> -- 2つ目のリストの各要素と、 element1 + element2 -- 足し合わせる ) list2 ) list1 )
最後の型エラーを解決する
上記のように書き換えられたら、再びblackjack.hsをGHCiに読み込ませてみましょう。
まだコンパイルエラーが出るはずですが、エラーの内容はどのように変わったでしょうか?
blackjack.hs:1548:40: error:
• Couldn't match expected type ‘NonEmpty Int’
with actual type ‘[Integer]’
• In the second argument of ‘foldl’, namely ‘[0]’
In the expression: foldl plusEach [0] possiblePoints
In an equation for ‘scoreCandidates’:
scoreCandidates = foldl plusEach [0] possiblePoints
blackjack.hs:1550:31: error:
• Couldn't match expected type ‘[a]’
with actual type ‘NonEmpty Int’
• In the second argument of ‘filter’, namely ‘scoreCandidates’
In the expression: filter (<= 21) scoreCandidates
In an equation for ‘noBust’:
noBust = filter (<= 21) scoreCandidates
blackjack.hs:1555:17: error:
• Couldn't match expected type ‘[Int]’
with actual type ‘NonEmpty Int’
• In the first argument of ‘head’, namely ‘scoreCandidates’
In the expression: head scoreCandidates
In the expression:
if null noBust then head scoreCandidates else maximum noBust
今度は、sumHand関数の中で直接使っているfoldl関数とfilter関数、head関数についてのエラーがでました。
foldl関数については、コンパイラがNonEmptyを期待(expected)しているところで実際(actual)には普通のリストが渡されているので、エラーになっているようです。
filter関数とhead関数については、コンパイラが普通のリストを期待(expected)しているところで実際(actual)にはNonEmpty型が渡されているので、エラーとしているようです。
いずれも、普通のリストと、「空ではないリスト」NonEmptyとを取り違えていることによるエラーのようです。
繰り返しになりますが、私たちは今、普通のリストを使わずに「空ではないリスト」を使用するよう書き換えているところなので、いずれも「空ではないリスト」NonEmptyを使うように寄せましょう。
foldl関数のエラーについては、引数が普通のリスト[0]になってしまっているのが問題なので、[0]を「空ではないリスト」NonEmptyに変えてください。
「先頭の要素として0だけを持つ、空ではないリスト」なので、(0 :| [])と変えるのが正解です
(丸カッコで囲うのを忘れないでください!)。
filter関数とhead関数のエラーについては、引数が「空ではないリスト」NonEmptyとなっているため、引数を受ける関数のほうをNonEmpty向けのものに変えればよいでしょう。
したがって、NonEmpty.を頭に付けたバージョン、NonEmpty.filter関数とNonEmpty.head関数に書き換えるのが正解です。
sumHand :: [Card] -> Int sumHand cards = -- 手札の各カードから取り得る点数を計算し、 let possiblePoints = map toPoint cards -- 取り得る点数すべてを組み合わせて、組み合わせごとに合計を求める scoreCandidates = foldl plusEach (0 :| []) possiblePoints -- 変わったのはここ↓ noBust = NonEmpty.filter (<= 21) scoreCandidates in -- バストしない合計点数が1つもないか調べて、 if null noBust -- 変わったのはここ↓ then NonEmpty.head scoreCandidates -- バストしない合計点数が1つでもあった場合、その中から最も高い点数のものを選んで返す else maximum noBust
さあ、これでエラーメッセージはどう変わるでしょうか? 今度こそエラーがなくなるといいですね!
> :l blackjack.hs [1 of 1] Compiling Main ( blackjack.hs, interpreted ) Ok, modules loaded: Main.
エラーがなくなりました! どうやらすべての型エラーを解決できたようです!
ここまで読んで、「maximum noBustの部分はNonEmpty向けに書き換える必要はないの?」という疑問を持つ人もいるかも知れません。
実際、普通のリスト向けのmaximum関数のままでコンパイルエラーが出ていないとおり、ここをNonEmpty向けのmaximumに変えてはいけません
(そもそも、困ったことに、なぜかData.List.NonEmptyモジュールにはmaximum関数がありません……)。
なぜなら、NonEmpty.filter (<= 21) scoreCandidatesの結果、すなわちnoBust変数の型は、普通の(空かもしれない)リストとなっているためです。
GHCiでNonEmpty.filterの型を確認しても、やはりNonEmpty.filter関数は普通の(空かもしれない)リストを返すことになっています。
> :t NonEmpty.filter NonEmpty.filter :: (a -> Bool) -> NonEmpty a -> [a]
どういうことかというと、理由は単純で、「filter関数で条件にマッチする要素を探した結果、1つもマッチする要素がなかったために、空のリストを返さざるを得ない」ということが起こりうるためです。
関数の型が関数の性質を簡潔に示す、よい例と言えるでしょう。
toPoint関数の定義をわざと間違えてみる
ここまで、「sumHand関数がtoPoint関数に対して要求する性質を型レベルで必然的に守らせる」べく、toPoint関数の戻り値の型を変える修正をしてきました。
本当にそうなっているか試すため、わざとtoPoint関数が空のリストを返すように変更してコンパイルエラーが出ることを確認しましょう。
toPoint :: Card -> NonEmpty Int toPoint A = 1 :| [11] toPoint (N n) = n :| [] toPoint _ = [] -- 間違えて空のリストを返してしまった!
上記のようにtoPoint関数を書き換えた上で、GHCiにblackjack.hsを再読み込みさせてください。
おおむね想定通りのエラーメッセージが出るかと思います。
blackjack.hs:1571:13: error:
• Couldn't match expected type ‘NonEmpty Int’
with actual type ‘[t0]’
• In the expression: []
In an equation for ‘toPoint’: toPoint _ = []
このように、間違った処理を書いた場合にコンパイルエラーを出すよう型を設計することで、実装する前にバグを根っこから摘むことができます。 実践するのは言うほど簡単ではありませんが、これからHaskellをもっと学んで複雑なアプリケーションを作ってみたいと考えたとき、ぜひこの記事を思い出してみてください!
最後に、修正後の各関数を下記にすべて再掲しておきます。
plusEach :: NonEmpty Int -> NonEmpty Int -> NonEmpty Int plusEach list1 list2 = sconcat ( NonEmpty.map (\element1 -> -- 1つめのリストの各要素を、 NonEmpty.map (\element2 -> -- 2つめのリストの各要素と、 element1 + element2 -- 足し合わせる ) list2 ) list1 ) toPoint :: Card -> NonEmpty Int -- 関数の型の宣言 toPoint A = 1 :| [11] -- Aの場合は1と11を取り得る toPoint (N n) = n :| [] -- 通常の数字のカードであれば、カードに書かれた数字のみを取り得る toPoint _ = 10 :| [] -- そのほかの場合は10のみを取る sumHand :: [Card] -> Int sumHand cards = -- 手札の各カードから取り得る点数を計算し、 let possiblePoints = map toPoint cards -- 取り得る点数すべてを組み合わせて、組み合わせごとに合計を求める scoreCandidates = foldl plusEach (0 :| []) possiblePoints -- 組み合わせた合計点数のうち、バストしない(合計点数が21点を超えない)もののみを選ぶ noBust = NonEmpty.filter (<= 21) scoreCandidates in -- バストしない合計点数が1つもないか調べて、 if null noBust -- バストしない合計点数が1つもない場合場合、組み合わせた合計点数から、適当なものを取り出す then NonEmpty.head scoreCandidates -- バストしない合計点数が1つでもあった場合、その中から最も高い点数のものを選んで返す else maximum noBust
【超発展編】もっと勉強したい人のために!
ここまで3回にわたり、主に第二言語としてHaskellを学ぼうという人向けに、Haskellらしいプログラムの書き方を知ってもらうことに主眼を置いて解説してきました。
Haskellには、この3回分の記事だけでは紹介できなかった機能もたくさんあります。 最後に、そのような機能を簡単に紹介して締めくくりたいと思います。
読んでおきたい解説書や入門コンテンツ
まず、Haskellそのものの解説書をいくつか紹介しておきます。
比較的新しい入門書として、『Haskell入門 関数型プログラミング言語の基礎と実践』『関数プログラミング実践入門──簡潔で,正しいコードを書くために』『Haskell 教養としての関数型プログラミング』の3冊があります。
とくに『Haskell入門』は、2017年9月に発売されたばかりです。実際にアプリケーションを作るところまでサポートした、かなり意欲的な内容となっています。 筆者もレビュワーとして参加しました。
上記の3つより数年前に出版され、定番の入門書となっているのが『すごいHaskellたのしく学ぼう!』です。
筆者はこの本から始めました。残念ながら古くなってしまった内容もありますが、今でも参考になる部分が多いと思います。
ウェブ上の入門コンテンツとして、下記のページもおすすめです。

各機能の使用方法を素早く学習することにフォーカスしているので、新しいプログラミング言語の勉強に慣れている人にはとっつきやすいかもしれません。
発展編でも取り上げられなかった高度な機能
Haskellや、そのデファクトスタンダードなコンパイラであるGHCには、本稿や各種の入門書ではカバーしきれない数多くの高度な機能があります。 ここでは、そうした機能をかいつまんで紹介します。
ただし、Haskellの高度な機能の話に触れる前に心にとどめていただきたいのは、次の大原則です。
すべてを完全に理解しようとは思わないでください。
これはHaskellに限った話ではありませんが、HaskellやGHCのコミュニティーでは、新しいライブラリーや機能が非常に盛んに開発され、議論されています。 加えて、もともとプログラミング言語の研究者が作った言語という背景があるためか、Haskellは歴史的にプログラミング言語についての研究の実験場といった側面もあります。
そのため、研究者でもなければ聞いたことがないような新しい概念が次々と登場します。 そして、Haskellの型システムをより柔軟でより安全にしたり、構文をより簡潔にしたりする機能として、後述するGHCの言語拡張やライブラリーに実装されていきます。
言語拡張
この先、Haskell製のライブラリーのソースコードやサンプルコードを眺めていると、ファイルの冒頭で次のような表記をたくさん目にすると思います。
{-# LANGUAGE FlexibileInstances #-} {-# LANGUAGE MultiParamTypeClasses #-} {-# LANGUAGE OverloadedStrings #-} {-# LANGUAGE TemplateHaskell #-} {-# LANGUAGE TypeFamilies #-} ...
これらは、言語拡張と呼ばれている機能を有効にする、特殊なコメントです。 言語拡張は、Haskellの標準として定められた機能に対して、(主に)GHCが加えた新しい機能です。
言語拡張は、初見では何の目的で有効にされたのかわからず、面食らってしまうことも多いと思います。 しかし、ご安心ください。 一部を除いて、言語拡張を有効にして起こる悪影響はあまりありません。
GHCが提供するHaskellに対する言語拡張は、ライブラリーが必要としているものであればとりあえずコピペして使いましょう。
stackとcabal
Haskell製のプロジェクトを本格的に作っていこうとすると、3回の記事で触れた以上に、StackとCabal(パッケージシステム)の使い方を学ぶ必要が出てきます。 さらなる使用法を簡単に知るには、手前味噌ですが下記の記事が参考になります。
{$image_5}Stackでやる最速Haskell Hello world! (GHCのインストール付き!) - Qiita{$image_6}
tanakhさんによる下記の記事もお勧めです。
{$image_7}Haskellのビルドツール"stack"の紹介 - Qiita{$image_8}
{$image_9}Stackを使って楽しくHaskellスクリプティング - Qiita{$image_10}
Lens
Lensは、「任意のデータ構造に対するjQuery」ともいわれる巨大なユーティリティーライブラリーです。 さまざまなデータ構造、特に複雑に入れ子になった構造に対して自由自在にアクセスしたり、中身を一部だけ書き換えたバージョンを返したりといった処理を、非常に簡潔に書くことができます。
日本語の入門資料としては、ちゅーんさんによる「LensでHaskellをもっと格好良く!」という発表資料がおすすめです。 Lensを導入するモチベーション、基本的な使い方、さらにLensの仕組みまで踏み込んで説明されています。
▽ LensでHaskellをもっと格好良く!{$image_11}(2015年5月30日 Lens&Prism勉強会発表資料)
なお、Haskellでは型が重要なドキュメントになるといわれますが、Lensをはじめ高度なライブラリーでは型宣言が非常に複雑で、(少なくとも慣れるまでは)型を見てもまったく理解できないことが少なくありません。 型を見るだけでは機能を理解できないライブラリーに挑むときは、サンプルコードや使い方をよく見てください。
逆に、型はわかるけど使い方がよくわからない場合には、推測して型が合うような組み合わせをいろいろ試してみるとよいでしょう。 それでもわからなければ、無理にそのライブラリーの機能を使おうとしないことです。
いずれにせよ、型を見てわからなくても、慌てる必要はありません。 どうしても使ってみたい場合は、後述するHaskell-jp(日本Haskellユーザーグループ)をはじめとするコミュニティーに助けを求めるのがおすすめです。
Monad(挑戦したけどよく分からなかった人向け)
Monad(モナド)と、Monadの扱いを楽にするdo記法は、(Haskellでは普通の)純粋な関数の組み合わせだけでは実装が困難な一部の処理を書くのに便利な仕組みです。
たとえば、下記のような処理は一見すると何も共通点がなさそうですが、全部同じMonadとして、do記法で実現できます。
- 入出力処理
- 処理が失敗した場合などにブロックから脱出すること
- 何重にもネストされた
map関数やconcatMap関数をフラットにすること - ブロックで暗黙に共有している変数の参照や更新(ダイナミックスコープのシミュレーション)
Monadは、「圏論」という数学の一分野における「モナド」という概念に由来してはいるものの、HaskellのMonadを使いこなすために圏論を理解する必要はまったくありません。 「プログラミングのためのモナド」として、圏論のモナドとは分けて考えてもいいぐらいでしょう。
残念ながら、MonadはHaskellの学習における鬼門とも言われています。 解説記事もたくさんあります。 なかでもお勧めは、筆者自身によるものも含め、下記の4つの記事です。
- {$image_12}QAで学ぶMonad - あどけない話{$image_13}{$image_14}
- 「やらなければならないこと」としてのHaskellのMonad(2014年5月11日 発表資料)
- Monadなんてどうってことなかった話(2015年3月21日 モナド基礎勉強会発表資料)
- igreque : Info -> JavaでMonadをはじめからていねいに{$image_15}
純粋にMonadの使い方のみを理解したい場合は、このセクションの冒頭で挙げた「Haskell超入門」における「Haskell アクション 超入門」以降の回を読んでみるのもよいでしょう。
Monad Transformer
Monadを使いこなせるようになると、複数のMonadの機能を同時に(同じdoブロックで)使用したくなることがあります。
Monad Transformerは、既存のMonadを組み合わせることで、そうしたニーズを満たすための仕組みです。
Monad Transformerの比較的わかりやすい解説としては、「Monad Transformers Step by Step(原文PDF)」という英文記事が有名です。日本語訳も下記にあります。
{$image_16}モナドトランスフォーマー・ステップ・バイ・ステップ(Monad Transformers Step By Step) - りんごがでている{$image_17}{$image_18}
ドキュメントやパッケージの調べ方
実際にHaskellでプログラムを書いていくと、すでに用意されている関数で欲しい型のものを知りたいといったケースが頻繁に出てくるでしょう。 そのような場合に便利なのが下記のサイトです。
いずれも、関数の名前だけでなく、関数の型から調べることができる、ほかのプログラミング言語ではちょっと珍しいタイプのドキュメント検索エンジンです。
たとえばfilter関数の型は(a -> Bool) -> [a] -> [a]ですが、
これを上記のHoogleで検索してみると、filter関数以外にもたくさんの関数がヒットするのがわかります。
ただ、詳細は割愛しますが、3つとも収録されている内容が異なっています。 どれを使うべきか簡単に言うと、本シリーズで紹介したstackを主に使って開発する場合には、StackageのHoogleを使うのが個人的なおすすめです(筆者自身これを最もよく使います)。
このあたりの使い方については、筆者が以前書いた次の記事が参考になると思います。
{$image_22}最近のHaskell製パッケージのドキュメント事情について簡単に - Qiita{$image_23}
サポートするコミュニティ
本シリーズで取り上げたことや、ここまで説明した新しいトピックなど、Haskellについて勉強していて困ったことが何かあれば、我らが日本Haskellユーザーグループ(Haskell-jp)という、Haskellユーザーのコミュニティーグループに助けを求めることを推奨します。
日本Haskellユーザーグループ(Haskell-jp)
Haskell-jpは、2017年の4月末に発足した、「日本におけるプログラミング言語Haskellの普及活動と、Haskellを利用する人々のサポートを行うグループ」です。 現在は、主に下記の活動を通して、Haskellユーザー(読者の皆さんも含まれます!)をサポートしたり、Haskellに関する情報を日本語で配信したりしています。
Redditでのサポート・議論
Redditは、日本ではあまり利用者が多くないですが、世界のすべてのウェブサイト全体で9番目に利用されている、巨大掲示板サービスです。 Haskell-jpでは、Redditの特徴がオープンな議論に向いていると考え、subreddit(Redditにおける、スレッドのグループ)を作りました。
「Haskellに関するこんなウェブページを見つけた」、「Haskellについてこんな質問がある」など、Haskellに関する話題であればどんなものでも気軽に投稿してみてください!
勉強会・イベント
以下は、Haskellに関する継続的に行われている勉強会で、筆者が把握しているものです。
- 東京都内で行われているもの
-
Haskell-jp もくもく会{$image_27}
Haskell-jp主催の勉強会です。 Haskellに関する作業をもくもくとやったり、希望者でLTを行ったりするゆるい会です。 勉強会で初めてHaskellを使い始める人から上級者まで、さまざまな人が参加します。 - {$image_28}Shinjuku.hs{$image_29}
- {$image_30}ヘイヘイHaskell騎士団{$image_31}
-
Haskell-jp もくもく会{$image_27}
- 関西で行われているもの
- どこからでも参加できる、SkypeやSlackを使ってオンラインで行われているもの
Q&Aサイト
おなじみスタック・オーバーフローとteratailにおける、Haskellタグがついた質問です。
- {$image_36}新着の 'haskell' 質問 - スタック・オーバーフロー{$image_37}
- {$image_38}Haskellのエラー・バグ・問題の解決方法|teratail{$image_39}
上記2つの質問サイトにHaskellタグのついた質問を投稿すると、次項で紹介するSlackチームの#questions-feed-jpチャンネルに自動で通知されるので、きっとサポートされやすいでしょう。
SlackとWiki
Haskell-jpが運営するSlackチームです。 こちらはRedditよりもゆるい感じで投稿されています。
- haskell-jp - SlackArchive.io(過去ログ)
- Join haskell-jp on Slack!(登録ページ)
Haskell-jpが運営しているWikiもあります。GitHubアカウントがあればどなたでも書き込めるようになっています。
中でもHaskellに関する日本語のリンク集には、今回紹介しなかったものも含め、さまざまなウェブサイトが紹介されています。 ぜひ一度覗いてみてください。
情報収集に役立つサイト
- {$image_41}Haskell News{$image_42}
- TwitterのハッシュタグやRedditの投稿、GitHubのリポジトリーなどから、Haskellに関する情報を収集して一覧にしたサイトです。 筆者はGoogle Chromeの固定タブ機能を使って、このサイトがChrome起動時に必ず表示されるようにしています (そのため、気が向いたときに見る癖ができています)。
- ▽ Haskell Antenna{$image_43}
- Haskell Newsにインスパイアされて作った、日本語のHaskellに関する情報を収集したサイトです。 こちらはHerokuの無料アカウントを通じて運営されている関係上、残念ながら正しく表示されないことも多いのですが、ぜひ覗いてみてください。
- ▽ Haskell Weekly{$image_44}
- 話題になったHaskellの記事や新しいHaskell製パッケージを、毎週紹介してくれるサービスです。 メールで購読もできます。
執筆者プロフィール
山本悠滋(やまもと・ゆうじ) {$image_45}@igrep {$image_46}igrep {$image_47}id:igrep
編集協力:鹿野桂一郎(しかの・けいいちろう、{$image_49}@golden_lucky) {$image_50}技術書出版ラムダノート




