コンテナ時代におけるオブザーバビリティの基礎
この数年であちこちで見かけるようになった「オブザーバビリティ」という言葉。コンテナが利用されるシーンが増えてきた現在におけるオブザーバビリティの基礎についてミクシィでみてねのSREグループマネージャーをつとめる清水 勲さんに解説いただきました。
1. オブザーバビリティとは
この数年で「オブザーバビリティ」という言葉はあちこちで見かけるようになりました。2022年3月にはObservability Conference 2022 というオブザーバビリティに特化したテックカンファレンスが国内で開催されたこともあり、非常に関心の高い分野であるということが伺えます。
「オブザーバビリティ」という言葉よりも「モニタリング」という言葉の方が馴染みがあるという方が多いかもしれませんが、モニタリングはシステムを監視をするという行動や活動を意味しています。一方でオブザーバビリティ(可観測性)とは「システムの状態を情報として取得できる状態」ということで、先のモニタリングのような行動や活動を意味するものではないということがわかります。
オブザーバビリティという言葉がいつ頃から出てきたのかについて調べると、これが初出かどうかはよくわかっていませんが、2013年にTwitter社が「Observability at Twitter」 という記事を公開していました。この記事では、何百ものサービスが動作するTwitterの分散システムのメトリクスを収集、保存、クエリ、視覚化することによって、問題が発生した際に原因を特定しやすくしている話が書かれています。
モニタリング(監視)をするということはだいぶ昔から必要とされてきましたが、マイクロサービスという手法が登場し、システムがより複雑化し、コンテナ化やクラウド利用の一般化などの変化によって扱うコンポーネントの数が増え、問題解決の際にはそれぞれの状態の詳細について知る必要が出てきました。こういった変化が起きている中でもオブザーバビリティを実現することで、問題解決へのスピードが高まり、ユーザーがより良い体験を得られ、開発効率の向上や組織の利益向上にもつながります。
システムにコンテナが利用されるシーンが増えてきた現在、オブザーバビリティの必要性がさらに高まってきたように思います。では従来のVM環境と何が違うのか次節で解説していきます。
2. VMとコンテナにおけるオブザーバビリティの違い
従来のVM運用におけるオブザーバビリティと、コンテナにおけるオブザーバビリティの違いについて解説します。
VMとコンテナの違いは以下の図の通りです(簡易的な図です)。
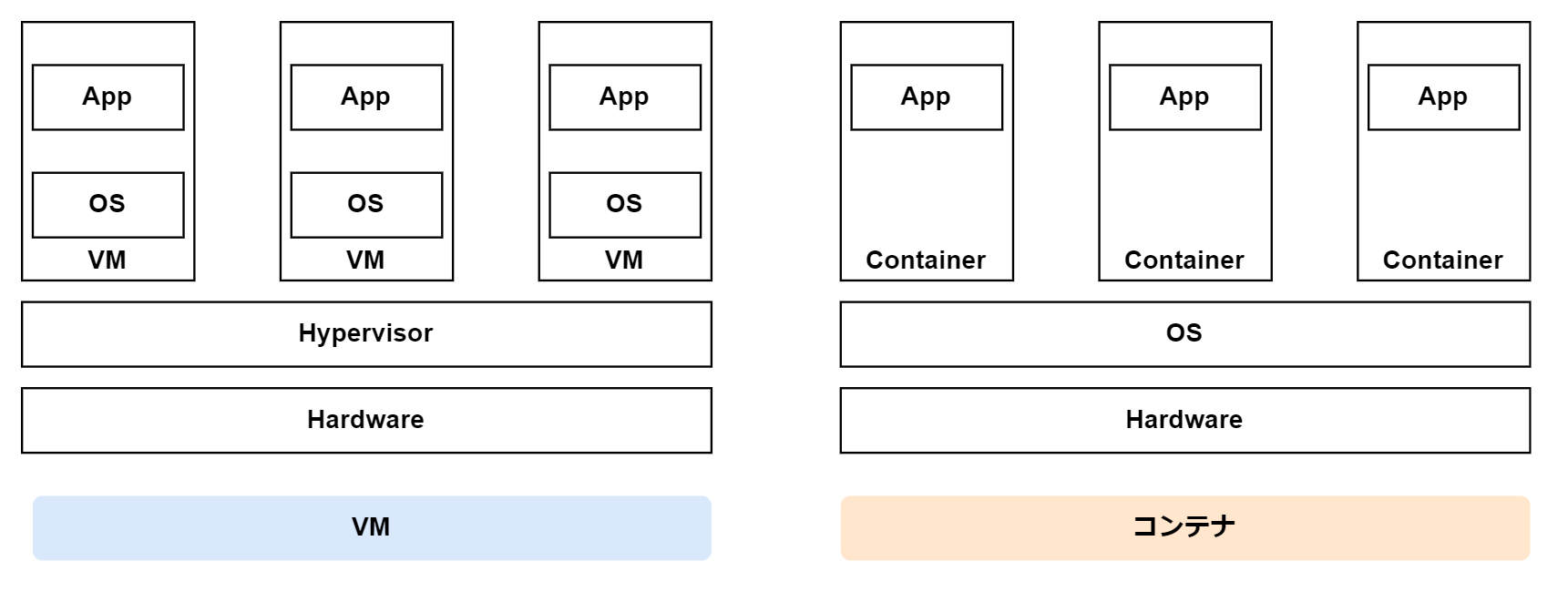
左の図はハイパーバイザーの上の独立した仮想環境(VM)内でOSが起動しアプリケーションが動作しています。対して右の図ではホストOS上にネットワークやPID、ユーザーなどの名前空間がコンテナごとに分離され、コンテナ内のアプリケーションはホストOSや他のコンテナから隔離されたプロセスとして動作しています。
次にVMとコンテナそれぞれにおいてどのようにオブザーバビリティを実現するのか、アプローチの方法はさまざまありますがここでは一例を紹介します。
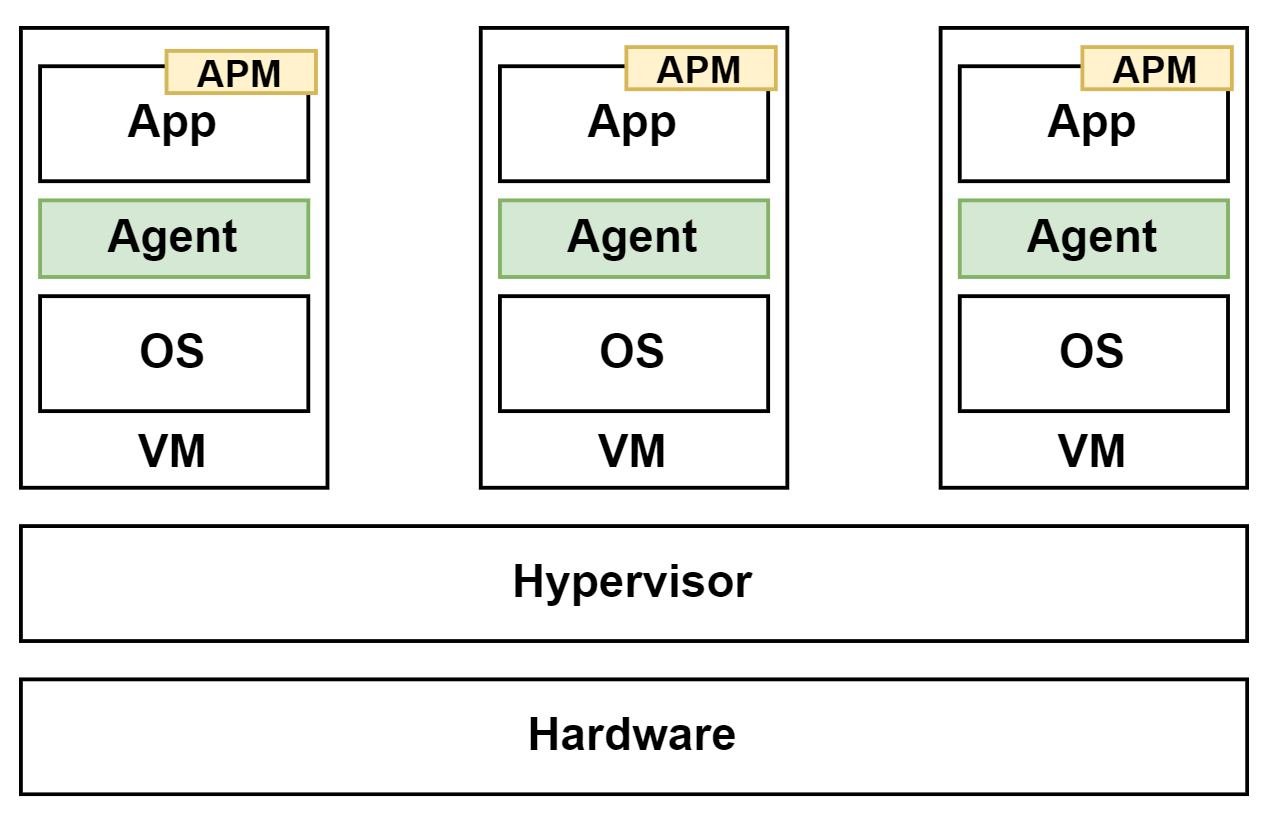
VMにおいてオブザーバビリティを実現するための方法の1つですが、各VM内にエージェントを起動させ、メトリクスやログを収集し、アプリケーションにはAPM(Application Performance Monitoring)のライブラリを導入してトレースデータを収集するといったやり方があります。
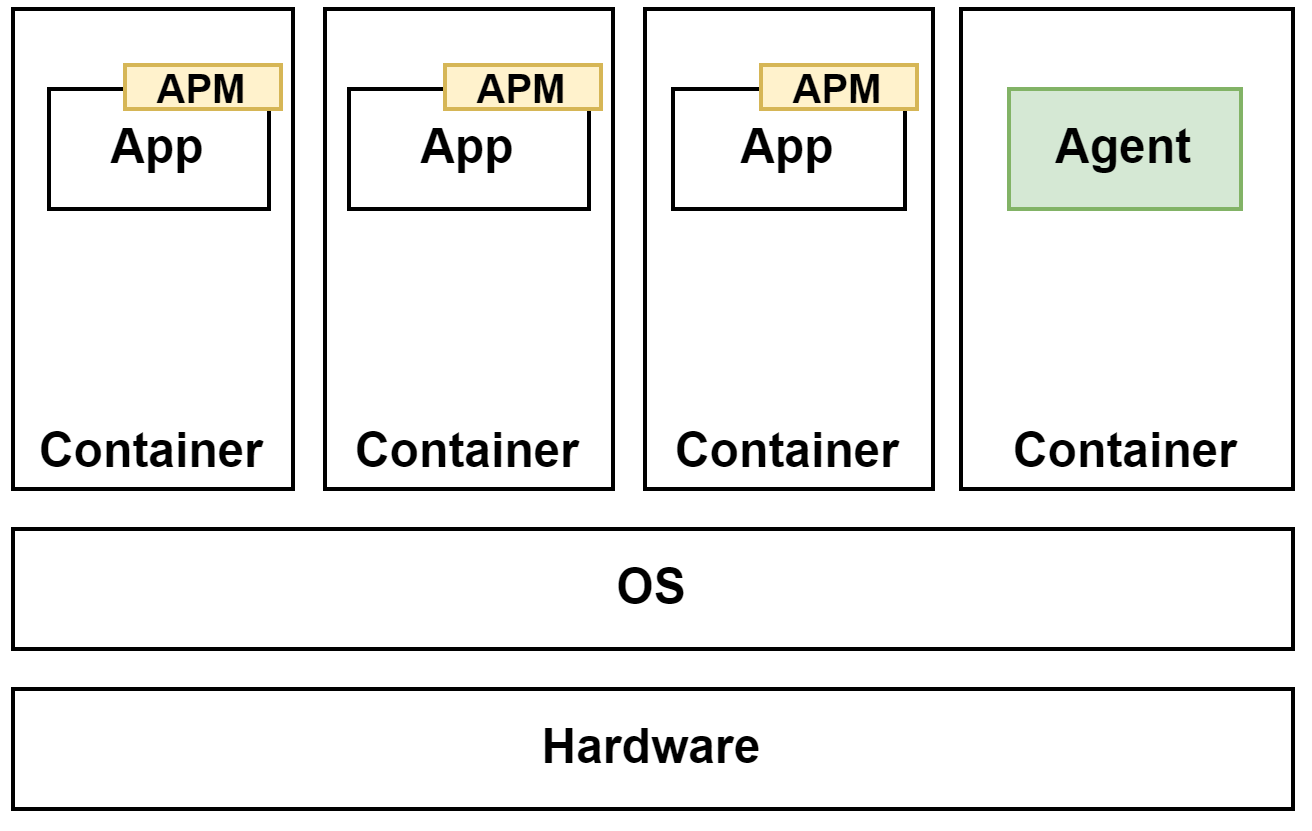
一方コンテナでは、メトリクスやログ収集用のエージェントが入ったコンテナをホストごとに用意するといった方法があります。1つのコンテナ内には1つのプロセスを動かすということが基本となっているため、ログを収集するようなエージェントはアプリケーションとは別に専用のコンテナで動かします(ホスト内でエージェントを動かすやり方もありますがここでは割愛します)。
アプリケーション側は VMと同様にAPM(Application Performance Monitoring)のライブラリを導入してトレースデータを収集することができます。
ログの収集方法
Herokuの創設者の1人であるAdam Wiggins氏は2012年にThe Twelve-Factor Appという12個のWebアプリケーションのプラクティスをまとめました。その「第11章ログ」に
> アプリケーションはログファイルに書き込んだり管理しようとするべきではない。代わりに、それぞれの実行中のプロセスはイベントストリームをstdout(標準出力)にバッファリングせずに書きだす。
https://12factor.net/ja/logsより引用
とあるように、アプリケーションは標準出力にログを出力することを勧めています。
下の図はDockerにおけるログ収集の例を示しています。
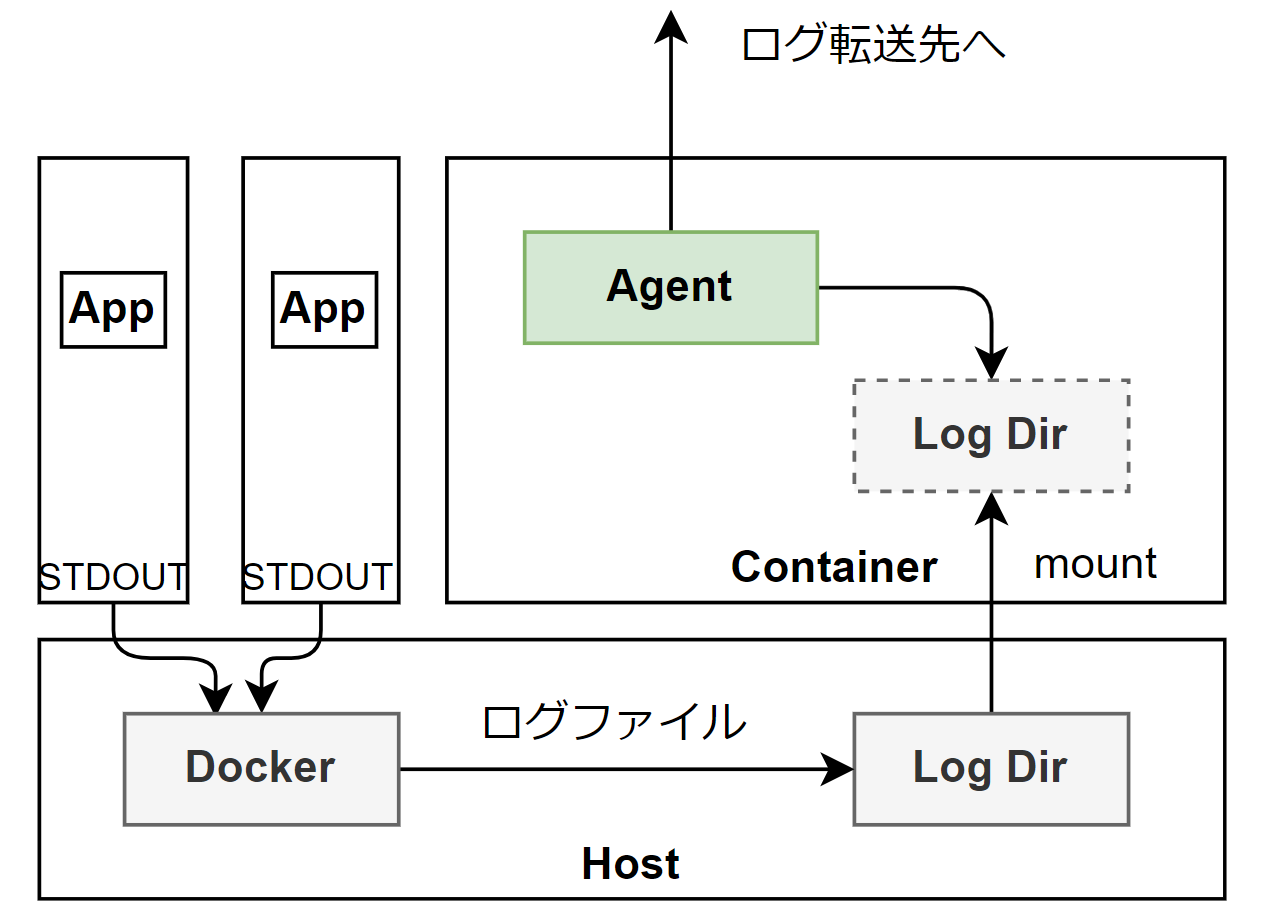
コンテナのアプリケーションが標準出力に出力したログはDockerを通じてホスト側に蓄積されていきます。ホスト側に蓄積されたログはログ収集用のコンテナにマウントし、ログ収集用のエージェントがマウントされたディレクトリからログを収集し、外部のログ転送先に転送します。
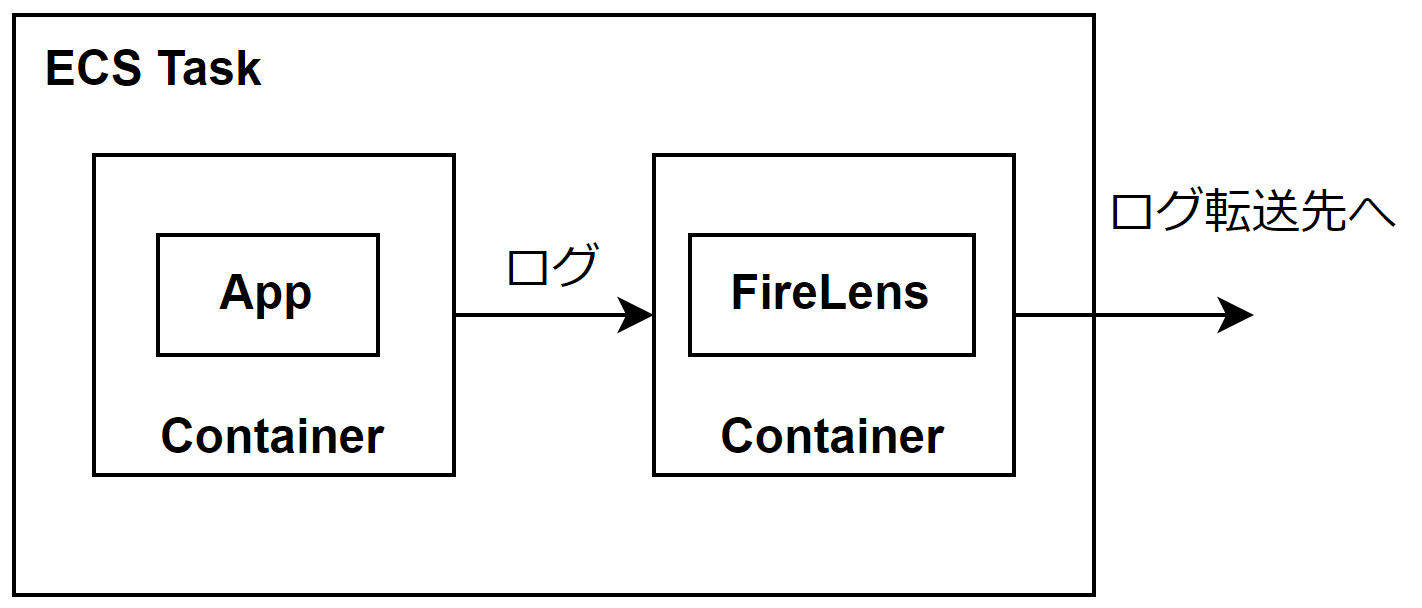
AWS Fargateのようなホストが隠蔽されているインフラではホストごとにエージェントを起動することができないため、アプリケーションのコンテナとエージェントのコンテナ(ここではFirelens)をセットにしてログを転送する場合もあります。
3. コンテナにおいて収集すべきログとメトリクスとは
コンテナにおけるログにはいくつかの種類がありますが、コンテナだからといって特別なログはあまりありません。
ログの例
いずれのログもFluentd、Fluent Bit、New Relic、Datadogなどのログコレクターを使って収集し、分析や可視化できるようにしておくとトラブルシューティングやモニタリングに役立ちます。
- アプリケーションログ
- アクセスログ
- エラーログ
- システムログ
- イベントログ
- 監査ログ
- 操作ログ
- 認証ログ
アプリケーションログ
アプリケーションが出力するログです。アプリケーションへのリクエストの情報がログに記録されます。一例として、リクエストの日時、ログレベル、リクエストパス、リクエストメソッド、クライアントのIPアドレス、ステータスコードなどがあります。エラーが発生した場合は、エラーの内容、例外情報、スタックトレースなどの情報がエラーログに記録されます。
システムログ
VMにおけるシステムログというとミドルウェアやOSのログになりますが、コンテナのシステムログは主にはコンテナ基盤のログとなります。コンテナの状態の記録や、基盤に関わるソフトウェアの状態をログとして記録しています。
監査ログ
誰がどんな操作をしたのかをログに記録します。コンテナが外部のリソースへアクセスするための認証情報を使った場合も監査ログとして記録することができます。
ゴールデンシグナル
システムのモニタリングを計画する際に推奨されるメトリクスに「ゴールデンシグナル」と呼ばれる4つのメトリクスがあります。コンテナにおいても非常に重要なメトリクスとなります。これらがどんなものなのか解説します。

1. レイテンシ
サービスに対するリクエストを処理するのにかかる時間です。ネットワークの遅延時間やアプリケーションの処理時間などがレイテンシに影響します。
2. トラフィック
単位時間あたりのリクエスト数やトランザクション数です。ストリーミングサービスの場合、ネットワークの帯域幅やセッション数なども該当します。
3. エラー
リクエストに対するエラー数の割合です。4xxエラーや5xxエラーの割合が一般的です。
4. 飽和度(サチュレーション)
CPUやメモリなどのリソースに対する負荷割合です。他にもネットワーク帯域幅の上限やディスクI/Oの限界値など、上限に対してどれだけ利用しているのかの割合を利用します。使用率が100%に達するとパフォーマンス低下するため、使用率の目標値を設定することも不可欠です。
4. ゴールデンシグナルの計測方法
ゴールデンシグナルをどのように計測するのか解説します。
1. レイテンシ
APM(Application Performance Monitoring)を使ってアプリケーションの各処理の実行時間を計測することで、例えばAPIリクエストからレスポンスまでのレイテンシを計測できます。APMはNew Relic、Datadog、Sentry、AWS X-Rayといったサービスを利用することで効率的に計測を行えます。
レイテンシはアプリケーション側だけでなく、ユーザーとロードバランサー間の通信から計測することや、ロードバランサーとそのバックエンドとの通信から計測することができます。
下の図はユーザーがロードバランサー(LB)を経由してアプリケーションにリクエストを送り、レスポンスが返るまでを表しています。
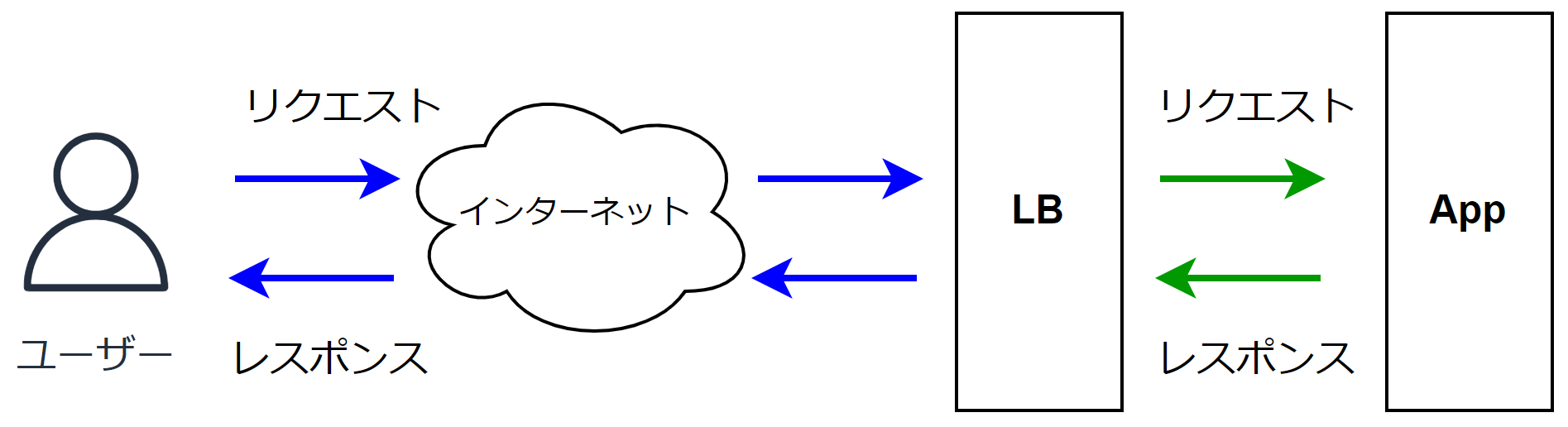
図中のユーザーとLBの間のリクエストとレスポンスにかかった時間の合計(青い矢印)、LBとAppの間のリクエストとレスポンスにかかった時間の合計(緑の矢印)、どちらもレイテンシと言えますが、前者はユーザーが体感するレイテンシ(ユーザーの回線事情やインターネットの経路、距離に影響されやすい)、後者はLBとAppの間のネットワークレイテンシとアプリケーションの処理速度によるレイテンシとなります。LBとAppの間のレイテンシは、ロードバランサーが提供するメトリクスを参照したり、ログを集計することで計測できます。
2. トラフィック
トラフィックはレイテンシの計測と同様にAPMでリクエスト数やトランザクション数を計測することができます。ロードバランサーを経由している場合はロードバランサーのメトリクスとしてリクエスト数が提供されている場合があります。またはロードバランサーやアプリケーションのアクセスログから集計をすることでトラフィックを計測できます。
3. エラー
エラーも同様にAPMで計測することができます。一般的にアクセスログにはステータスコードが記録されているため、全体のリクエストに対してエラーとなったリクエストがどのくらいの割合なのかを計測できます。
4. 飽和度(サチュレーション)
CPUやメモリ、ディスクの使用率を計測します。例えばKubernetesではkubeletに組み込まれているcAdvisorがコンテナのメモリやCPUの状況を記録しています。cAdvisorによって記録されたメトリクスはPrometheusを使って収集するのが一般的ですが、New RelicやDatadogなどのエージェントを利用して計測することもできます。
5. 収集されたデータを分析するためには
収集されたデータ、メトリクスのモニタリングや分析の方法論を紹介します。
USEメソッド
パフォーマンスエンジニアリングの分野で名高いBrendan Gregg氏が提唱したUSEメソッドと呼ばれる手法を紹介します。2012年にブラジルで行われたFISL(International Free Software Forum)で、Performance Analysis: The USE Methodというタイトルで発表していたのがおそらくUSEメソッドの初出のようです(筆者調べ)。発表の動画もありますので興味のある方は是非ご覧ください。
「USE」とは
- 使用率(Utilization) - リソースがビジー状態であった時間の割合
- 飽和状態(Saturation) - ソケットバックログや処理待ちの長さなど
- エラー(Errors) - エラーイベントの数
の3つの頭文字をとっています。

CPUやメモリ、ネットワークインターフェース、ストレージデバイスなどのリソースごとにこれらの3つを確認する手法をUSEメソッドと呼んでいます。詳細はThe USE Methodのページを読んでいただけたらと思いますが、ここではこのページで触れられているフローチャートを紹介します(下記の図は筆者が和訳したものです)。
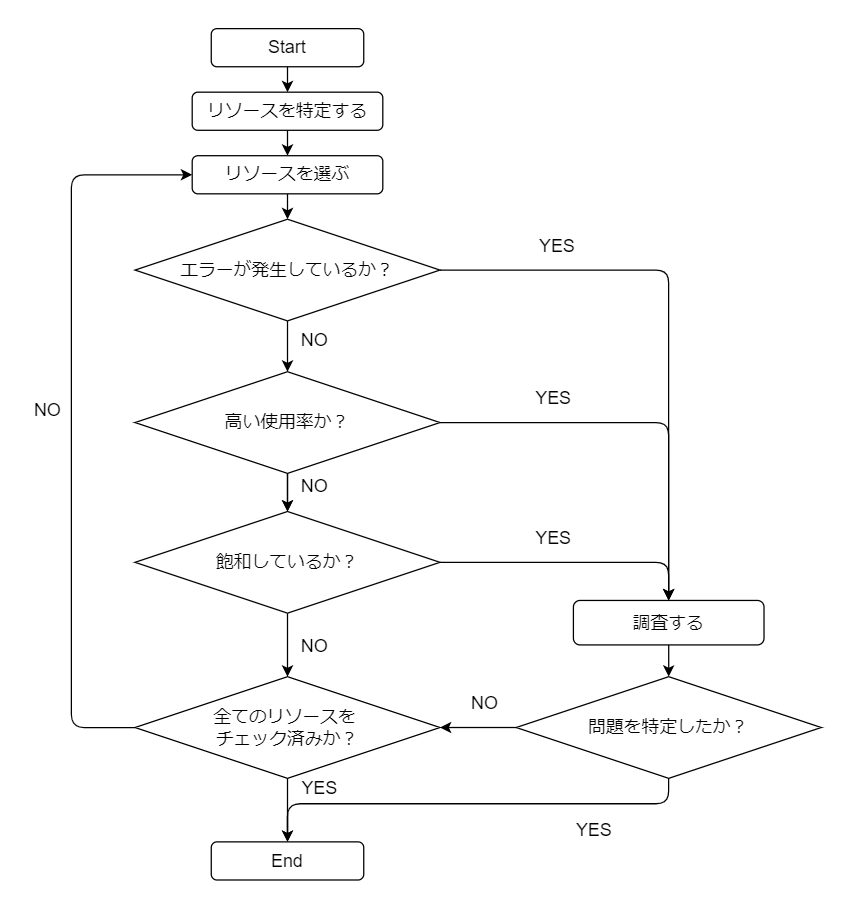
このフローチャートが示すように、USEの3つの要素のチェックを反復して行うことで、ボトルネックやエラーを特定するというものです。
REDメソッド
Tom Wilkie氏が2015年に提唱した「REDメソッド」というモニタリング手法があります。
「RED」とは
- レート(Rate) - 1秒あたりのリクエスト数
- エラー(Errors) - 失敗しているリクエスト数
- 期間(Duration) - これらのリクエストにかかる時間
の3つの頭文字をとっています。

USEメソッドはリソースに対するものでしたが、REDメソッドはサービスに対するモニタリングであるとTom Wilkie氏は述べています。
また、このREDメソッドをすべてのサービスに対してモデル化することで、サービスがどのように動作しているのかを一貫して把握することができるとしています。
REDメソッドがあれば前述のUSEメソッドが必要ないということではなく、どちらも併用するのが良いとされています。
さいごに
現在、コンテナやKubernetesの登場、そしてアーキテクチャの変化によって観測できる情報の種類が従来よりも増えてきています。本記事ではその中でも重要なメトリクスの種類や代表的な手法について紹介しました。オブザーバビリティはシステムに起きていることを把握し、安定化につながることですが、これは運用者だけに留めず、アプリケーション開発者とも連携して組織全体で実現することが重要です。ツールやダッシュボードを活用して組織内にオブザーバビリティを浸透させていくことは不可欠です。結果としてユーザーの幸福度が高まり、事業の成長や成功につながると考えています。本記事がシステムのオブザーバビリティについての理解を深めるきっかけとなれば幸いです。
清水 勲(Isao Shimizu) 


株式会社ミクシィ Vantageスタジオ みてね事業部 SREグループマネージャー
SIerで約8年経験後、2011年に株式会社ミクシィへ入社。SNS「mixi」のインフラ運用、モンスターストライクのSREを経て、現在は家族アルバム みてねのSREグループマネージャー。 世界中のユーザーが良い体験を得られるよう日々奮闘中。AWS Summit Tokyo、SRE NEXT登壇。New Relic User Group運営。キャンプとビールと音楽があれば生きていける。
SIerで約8年経験後、2011年に株式会社ミクシィへ入社。SNS「mixi」のインフラ運用、モンスターストライクのSREを経て、現在は家族アルバム みてねのSREグループマネージャー。 世界中のユーザーが良い体験を得られるよう日々奮闘中。AWS Summit Tokyo、SRE NEXT登壇。New Relic User Group運営。キャンプとビールと音楽があれば生きていける。




