
Ruby 3.1はここに注目! 新しいJITとは? デバッガ、エラーメッセージ、そして未来! リリースマネージャーに聞いた
2021年12月25日にリリースされたばかりのRuby 3.1では、どのような機能がどういった経緯で採用されているのでしょう。リリースマネージャーのnaruseさんと、フルタイムコミッターのmameさん、ko1さんに詳しくうかがいました。
プログラミング言語Rubyでは2013年の2.1.0以降、毎年クリスマス(12月25日)にメジャーバージョンアップが行われています。2021年も無事にバージョン3.1.0がリリースされました。
Ruby 3.1は、言語機能の面では全体的に穏やかなリリースにも見えますが、新しい方式のJIT(just in time)コンパイラ、標準の新デバッガー、事前アナウンスでも好評だったエラーメッセージの改善など、開発者体験の面では意欲的な内容です。今回のリリースの詳細や意図、今後のRuby開発の方向性などをリリースマネージャーの成瀬ゆい(naruse)さん、コミッターの遠藤侑介(mame)さん、同じく笹田耕一(ko1)さんに聞きました。
インタビューはリリースの内容が確定した2021年11月の開発者会議の数日後、オンライン会議ツールを用いてリモートで実施しました。聞き手は、ラムダノートの鹿野桂一郎(@golden_lucky)さんです。
- 2.6系で様子を見ている人でも3系に上げられるリリース
- 既存のMJITとは異なるアプローチの直截的なYJITを搭載
- メンテナンス性が重要な機能は企業のサポートがあってこそ
- JITのデフォルトはYJITになるのか? MJITの今後は?
- 標準装備される新しいデバッガ
- ちょっと便利になって「すごい便利」と感じるエラーメッセージ
- 普通のRubyプログラマの開発体験を向上させるリリース
- 次に何がきても選択肢としてRubyが現実的であるように
- 成瀬 ゆい(なるせ・ゆい)nurse
- 2004年にnkfライブラリのメンテナとしてRubyの開発に参加。バージョン1.9から文字コード全般に関わり、バージョン2.1から現在までリリースマネージャーを務める。トレジャーデータ株式会社に所属。
- 遠藤 侑介(えんどう・ゆうすけ)mame
- 2008年からRubyの開発に参加。テスト支援機能などの高品質化を中心に活動し、Ruby 2.0ではリリースマネージャーも努める。クックパッド株式会社で、笹田耕一氏に続く2人目のフルタイムコミッターとして、2017年からRubyの開発に専念する。
- 笹田 耕一(ささだ・こういち)ko1
- 2007年に開発したRuby用仮想マシンYARVがRuby 1.9として導入され、Rubyコミッタに。以降、RubyのGCやスレッドなど、下回りの改善を行う。2017年よりクックパッドでRubyインタプリタ開発に従事。
2.6系で様子を見ている人でも3系に上げられるリリース
── 今年もRubyのバージョンアップのシーズンがやってきました。2020年末にリリースされたRuby 3.0.0という大きなマイルストーンを越えた後、最初のメジャーアップデートになります。
nurse そうですね。Ruby 3.0系は、パターンマッチの導入などをした2.7系に続き、ユーザーにとっては比較的大きな機能変更を伴うリリースだったと思います。
3.0は「Ruby 3x3」(Ruby 2の3倍速)という目標を掲げて、JITコンパイラのMJITによるパフォーマンスの改善、Ractorをはじめとする並行処理機能の拡充、そしてTypeProfのような静的解析の導入を達成できました。
── それに比べて、今回のRuby 3.1はかなり穏やかなリリースになった印象があります。ユーザーがRuby 3.1にアップデートすべき積極的な理由は何でしょうか?
nurse 積極的なアップデートというよりむしろ、今回は「まだRuby 2.6系で止まっている」ような人がアップデートするチャンスと考えています。
mame 2.6系は2022年3月にメンテナンスが終わるので、今回のリリースでぜひ3系に上げてほしいですね。
nurse 2.7や3.0への移行では「警告がいっぱい出て大変だった」という方も少なくなかった気がします。ですが、3.0のリリースから1年が経って、2系からのアップデートに伴う既知のトラブルはだいたい解決されています。対応方法もネットを探せば出てきますし、このタイミングでぜひ3系に上げてもらいたい。そのため3.1では、あまり大きな変更を含めなかったという側面もあります。
mame 実際、互換性にはかなり気を配っていて、「これくらいなら問題ないのでは」といった機能追加の提案もかなり却下しています。
ko1 特にRailsを導入している企業などでRuby 3.0の導入に苦労したユーザーも少なくないと思うので、すぐにまた3.1で苦労しないようにという気持ちもあります。
既存のMJITとは異なるアプローチの直截的なYJITを搭載
── Ruby 3.1の大きなトピックは、何といっても新しいJITコンパイラ「YJIT」の追加だと思いますが、すでにRubyのコアには「MJIT」というJITコンパイラが含まれていますよね。
ko1 Rubyのパフォーマンス改善の歴史を振り返ると、まず2007年の1.9でYARV(Yet Another Ruby VM)を導入したことでインタプリタ本体を高速化しました。ただし、これだけではRuby 3x3で目指している「3倍の高速化」といった水準にはなかなか到達できません。
そこで2018年のRuby 2.6で導入されたのが、MJITです。
── Rubyのようなインタプリタ言語の高速化では、やはりJITが有効なのでしょうか?
ko1 一般的にはそうです。ただ、JITといっても実はいろいろな方式がありえます。MJITでは、「利用されることが多いメソッドの命令列をCのコードに変換してGCCなどでコンパイルし、その機械語の命令を実行する」という方式をとっています。
その変換とコンパイルに時間がかかることもあって、MJITで高速化できるコードはまだ限られています。JITでは性能を引き出すチューニングが大変で、MJITも導入当初はオフにする方が高速なアプリもありました。
── RubyでJITを使うかどうかはユーザーが切り替えられるんですね。
nurse rubyコマンドに--jitというオプションをつけて実行すると、MJITが有効になります。ここに新たにYJITを使う--yjitというオプションが追加されたことが、ユーザー視点からのRuby 3.1の変更です†。
† Ruby 3.1で、可能なら--jitによってMJITではなくYJITが有効になるよう変更されました。
── YJITはどのような方式なのですか?
ko1 「こういうYARVの命令は、特定のアーキテクチャのこういう機械語の命令列になる」ということが分かったら、次回以降も同じものに変換するという意味では、直截的な方式のJITです。
── よくあるJITだと、「同じメソッドが何回か実行されると分かったら、バイトコードを作っておいて以降はそれを利用する」という感じですよね。
ko1 YJITでは実際に動かす型の情報を用いて機械語の命令列を作り、実行します。
どういうことかというと、例えばメソッドがIntの値を引数にして呼ばれていて、そこで+が使われていたら、Intの+として、機械語の命令列へとコンパイルします。
── 動的に型が決まるRubyでは、必ずしも`Int`で同じメソッドが呼ばれるわけではありませんよね。
ko1 はい。もしかしたら実際にはfloatの+が使われるかもしれないので、その場合にはコンパイラに戻って機械語を作り直せるような仕掛け(ガード)を入れていくようです。でも、たいていはIntで呼ばれるだろうから、コンパイル済みの機械語がそのまま使えて、高速に実行できます。
YJITの開発者の一人であるMaxime Chevalier(@Love2Code)さんは、このアプローチを「Lazy Basic Block Versioning」と呼んでいます。
nurse あらゆる型に対応する命令列は作っておけないから、あとで必要なときにVMに戻って実行し直せるような形でバイトコードを作っておくということで、「Lazy」なんですかね。
── 何回か使われるメソッドに対して事前コンパイルをして、次回以降に使う、というわけですね。
ko1 YJITでは、これから実行する部分について、与えられたパラメータなどの型に応じた命令列を作り、それを使って実行するということです。また、条件分岐などでは、これから実際に実行する部分しかコンパイルしません。
すでにコンパイル済みのメソッドを実行するときは、その命令列を使うのですが、型が違ったり、分岐先が異なる場合には、コンパイル済みの命令列に追加する形で新しい型や分岐先の部分をコンパイルしていきます。このあたりが Lazy という言葉の意味かと思います。
メンテナンス性が重要な機能は企業のサポートがあってこそ
── Rubyではなぜ「直截的」ではないMJITがまず導入されたのでしょうか?
mame 大きな理由はメンテナンス性です。MJITは、RubyのVMの命令を再利用していったんC言語のコードを作り、それを切り貼りしてコンパイルしたものをロードするという方式です。そのため、例えば将来VMに機能が追加されても、MJITそのもののメンテナンスは最小限で済みます。
これに対し、普通のJITのように機械語を直接生成するYJITはそうはいきません。実際、現状ではx86-64アーキテクチャにしか対応できていないわけです。
nurse MJITの方式は、どうしてもコンパイルのオーバーヘッドがあるので、パフォーマンス向上には制約があります。この方式は、Vladimir Makarov(vnmakarov)さんが原形を考案し、これを最新のRubyで問題なく動くようにしてメンテナンス可能にしたものがMJITでした。
ko1 当時から、自明な方法のひとつとして、機械語を直接生成するJITを開発するというオプションはありました。ただ、どうしても「誰がそれをメンテナンスするのか」というのがネックになるんですよね。
言ってしまえば、「数パーセントのパフォーマンス改善のためにどの程度の開発リソースをつぎ込むか」という点で悩ましいわけです。
nurse 「作れば速くなるだろうな」というのは分かっても、「実際にどれくらいRailsアプリが速くなるか」までは事前に見えませんしね。
ko1 まずMJITをやってみて効果があることが分かったところで、Shopifyが正攻法のJITを開発して22%のパフォーマンス向上を実現してくれたのが、今回のYJITといえます。
▶ YJIT: Building a New JIT Compiler for CRuby — Development (2021)
── Shopifyは、ECサイト基盤でRailsを大々的に採用しているカナダの企業ですね。
ko1 はい。Shopifyは、YJITだけでなくRuby本体のバグをたくさん潰してくれたりもしていて、とても強い信頼があります。Railsの本体やRubyの本体にかかわる開発者もたくさん雇用してくれています。Kaigi on Rails 2021の発表では35人いると言っていました。
── Shopifyの規模でRubyを使い続けてくれるなら、YJITのメンテナンスも継続してくれるだろうと。
ko1 はい。先ほどから言ってる「メンテナンス性」とは、つまり「これからRubyに新しい機能が追加されるたびに、YJITも新しい機能に対応させなければならない」ということなんです。
そういう意味で、もし同じ機能が、例えば大学生個人の研究プロジェクトとして提案されていたら「どうしようか?」と悩んでしまったと思います。学生に「2022年以降もRubyを本業にしてメンテナンスを続けてくれ」とお願いするわけにもいきませんし。
mame YJITを採用した理由として「Shopifyなら、これからもメンテナンスを続けてくれるだろう」という期待もかなり大きかったことは言えるでしょう。
ko1 言語の開発側からすると、これまで「VMをどうするか」という方向で議論していたパフォーマンス改善について、今後は「YJITでどうなるか」という観点からも議論されると考えています。具体的な話はまだありませんが、例えば「YJITのために、ある機能をVMから消そう」という話が出ないとも限りません。
それに、YJITのような方式のJITを言語のコアに取り入れると、言語を作っている側で気にすべきことも増えます。先日も実際に新しい機能を取り入れる際に、YJITの開発陣に承認をもらうという過程がありました。
JITのデフォルトはYJITになるのか? MJITの今後は?
── 互換性がありパフォーマンスも高いなら、今後はYJITがデフォルトになることもありえますか?
nurse さすがにYJITは登場して1年くらいなので、これをデフォルトにしてユーザーの皆さんに安定して使ってもらえる段階には、まだ早いかなと考えています。
ko1 もっとも、いつ「安定した」と言えるかというと、そこは議論が必要でしょうね。もしかしてShopifyの規模で問題なく使えているのなら、十分に安定していると言えるかもしれません。
nurse Shopifyでも、本番ではまだYJITはオフなんじゃないかな。オンにしていたら、その事実はもっと主張されると思うので。
── もしYJITがデフォルトになったら、そのときMJITはどうなるのでしょうか?
mame 仮にYJITがデフォルトになっても「MJITを積極的にコアから切り離す」という可能性は、現状では低い気がします。YJITには未対応のアーキテクチャが多いという課題もあり、それに対してMJITには「Rubyが動けばどこでもそれなりに動く」という価値もあります。
ただし、メンテナである国分崇志(@k0kubun)さんが「消します」と言えば、もちろん消えますが。
nurse アクティブなメンテナがいる限りは消さない、ということになるんじゃないかな。
── そうなると今後のRubyには、複数のJITが同梱された状態になるんですね。
nurse 複数のJITを使い分けること自体は、それほど珍しい話ではないように思います。JavaScriptのV8にも確か2種類、一時期は4種類くらいあったはずです。
mame JITの特性には、「コンパイルにかかる時間」と「(コンパイルされたものの)実行にかかる時間」との間でトレードオフがあります。YJITは「コンパイルにかかる時間が速くて、実行速度はそこそこ」なので、それで使い分ける可能性はあるかもしれません。
例えば、YJITはどちらかというと1段階めのJITとして便利で、MJITはすごくよく使われる部分の2段階目以降に使うといった使い分けはどうでしょうね?
nurse 完全にないとは言わないけど、MJITとYJITでそういう使い分けがあるような気はしないなあ。
── RailsのようなアプリでYJIT、CPUを酷使するコードではMJITという使い分けはどうでしょうか?
nurse 確かに去年の段階では、MJITを使うとRailsが遅くなるという話はありました。ですが、YJITが出てからMJITも調整し直して、Railsの実行速度を測定してみたところ、MJITをオフにしたRubyと同じくらいにはなることが分かっています。
そういう意味では「RubyにJITを導入する際に、どこがボトルネックになるか?」を研究するときに、MJITは便利だったりしますね。何が差異を生むのかを、完全に把握できている人はどこにもいない気がします。
mame MJITでコンパイルの対象にしていた「よく使われるメソッド」の数を、100くらいから10,000に変えたところ、MJITでもRailsアプリが3%くらい速くなった、という結果もありましたね。Railsではメソッドの数がものすごく多いので、そのうち少数をコンパイルするくらいでは、むしろコンパイル時間のために全体が遅くなっていたのかもしれません‡。
‡ 最終的にRuby 3.1のリリースで、--jit-max-cacheが100から10,000に変更されています。
nurse YJITは「あまり使わないメソッドでも、確実に通る部分はとりあえずコンパイルしておく」というアプローチなので、Railsの特性に合っていたのでしょう。MJITのように外部のコンパイラに任せる方式は、自分で機械語を生成するJITに比べて、レイテンシの面では明らかに不利ですし。
mame --jitオプションのデフォルトの挙動を「YJITが対応してるアーキテクチャならYJITを使う」にする提案は、MJITの開発者である国分さん自身から出ていますね。
nurse どうかなあ。YJITが対応していないアーキテクチャでも--jitオプションはYJITにして、「YJITが使える環境でなければそもそもJITを使おうとしたときに失敗する」のが正解かも。
── Ruby 3.1のユーザーは、どういう状況でYJITを使うと判断すればいいでしょうか?
nurse むしろ、さまざまなアプリケーションでYJITを試してもらって、どうなるか教えてほしいところです。
標準装備される新しいデバッガ
── YJIT以外の大きなトピックでは、標準のデバッガとしてdebug gemが追加されています。このタイミングで新しいデバッガがリリースされたことにはどんな背景があったのでしょう。
ko1 現状、Rubyでデバッグというと、Byebugや、統合開発環境(IDE)のRubyMineや、VScodeに付いているデバッガを使うことが多いと思います。IDEのバックエンドで使われているのはdebaseですね。標準で添付されているデバッガはあまり使われておらず、整備もされていませんでした。
しかし、ちゃんと使えるデバッガがやはり標準であるべきだということと、Ruby 3.0で導入された並行プログラミング機能「Ractor」に他のデバッガが対応しきれていないことから、新しくdebug gemが作られました。Ruby 3.1 をインストールすると一緒に入ります。
── ユーザーとしては、ByebugやIDEのデバッガと何が違うのかが気になるところです。
ko1 デバッガとしての基本的な機能はByebugなどと同じなので、使い勝手が大きく変わることはないと思います。特長としては、リモートデバッグがやりやすいこと、Chromeをフロントエンドにできることなどが挙げられます。あと、速いです。
mame 従来の標準のデバッガは1行ずつフックを入れる必要があったんですが、新しいAPIで特定の行にだけフックを仕掛けられるようになって、それを使って作り直したので速い、ということですね。
ko1 特定の条件だとdebaseより速いので、かなり実用的になっていると思います。
Matz(まつもとゆきひろさん)もよく言っていることですが、いまのRubyのコアチームには「Rubyで開発するときのストレスをできるだけ減らしたい」という方針があります。
debug gemも「気持ちよくデバッグできるためには、何が必要か?」を考えて作った感じです。使ってもらった人からも「なるほど使いやすい」という声をよく聞きます。
nurse これまでは主に言語の性能や機能に注力してきたわけですが、これからは「Rubyという言語を使ってもらう開発環境」にも注力していこう、ということです。
ko1 「Rubyという言語を使う」ことで言うと、このdebug gemはほとんどRubyで書いていますが「なんて書きやすい言語だろう」と実感しました。しばらくずっとRactorを開発していて、これはC言語だし、並列プログラミングでかなり難しいので、それに疲れていたこともありますが……。
ちょっと便利になって「すごい便利」と感じるエラーメッセージ
── rubyコマンドの標準エラーメッセージも変わるんですね。11月9日のpreview 1のリリースノートでは扱いもやや地味ですが。
mame リリースノートで見ても「ふうん」という感じかもしれませんね。確かに地味な話ではあるんですが、実際に普段の開発で目にすると、「すごい便利」ってなると思います。
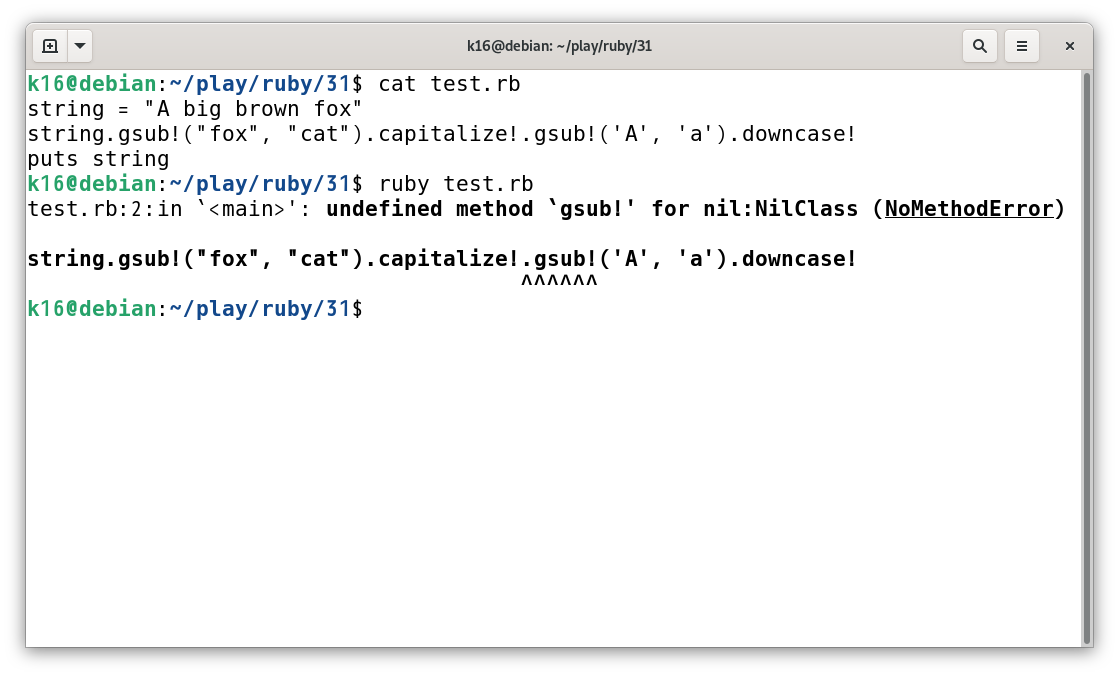
nurse いままでの行単位のエラーメッセージだと、NoMethodErrorが出て「nilにそんなメソッドはない」と言われても、「どこでnilになったのか分からん」みたいな状況がよくありましたからね。これがRuby 3.1では、「どこでエラーが出たか」を画面上に下線を引いて示してくれるようになりました。
ko1 このerror_highlightは、使うと本当に便利ですよね。
── この機能はRuby 3.0で導入された静的解析の応用なのでしょうか?
mame いや、直接は関係ありません。バイトコード上で「ここでエラーが起きる」と探し当てることと、そのエラーが「ユーザのコード上のどこで起きるか?」を示すことは違う話です。今回は後者の機能です。
nurse これはどうやって実現してるの?
mame バイトコードの各命令に、「それがAST上のどのノードに対応する命令か」に相当する情報を付随させるようにしてます。バイトコードの実行中に失敗したら、それに付随する情報を使って「AST上のどのノードか」を割り出して、そこを下線で示すような出力を作る、という感じです。
▶ Ruby 3.1はエラー表示をちょっと親切にします - クックパッド開発者ブログ
ko1 error_highlightのような仕組みを作るには、Rubyの言語機能にも拡張が必要でした。
mame そうですが、言語機能に手を入れたのはerror_highlightのためではなく、実はTypeProf for IDEという機能のためでした。これもRuby 3.1に含まれています。
Ruby 3.0では、既存のRubyのコードに対して型シグネチャを付けることを目標にTypeProfを導入したわけですが、その成果を開発環境で活用するためIDE対応させました。使うと、TypeProfが推論した型シグネチャがVScode上で示されます。
これを作るときに「IDE上で1行の中のメソッド呼び出し箇所を見つける」ための仕掛けが必要で、そのために作った機能を切り出して言語本体に組み込んだのが、error_highlightということになります。
普通のRubyプログラマの開発体験を向上させるリリース
── 普通のRubyプログラマにとって3.1はどんなリリースになると思いますか?
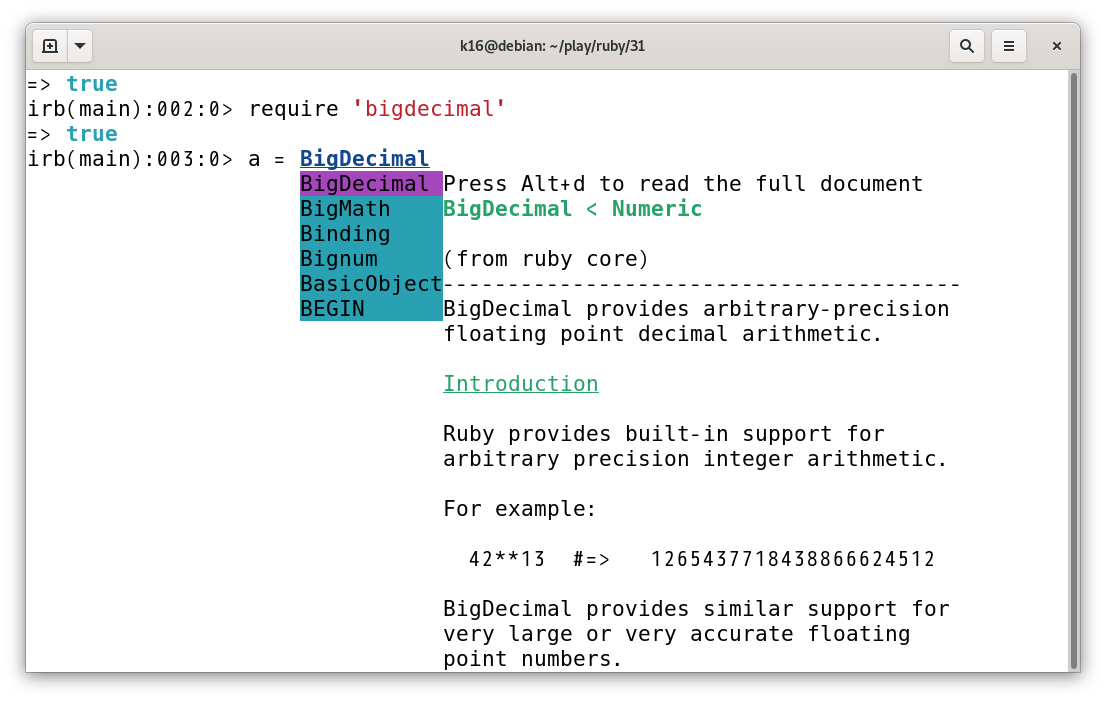
ko1 多くのRubyユーザーのふだんの開発体験は、error_highlightひとつとってもかなりよくなるはずです。irbも引き続き改善されていて、例えば補完候補がより分かりやすく出るようになりました。
それからもちろんYJITですね。コマンドラインオプションや環境変数でオンにするだけで、気軽に性能改善してもらえる可能性がある、というリリースだと思います。
mame 高性能なデバッガが標準で使えるようになったのも大きいですね。
ko1 デバッガは、自分で作っていてこういうのも何ですが「本当に困ったときに使うもの」なので、そこまで多くのRubyプログラマがすぐに助かるというものでもないかもしれません。
nurse Railsで開発している人にとって、デバッガはありがたいんじゃないかな。
── 全体を通して「開発体験を向上させる」という方向性が感じられるリリースだなとは感じました。
ko1 そうですね。遡れば2018年のRuby25(25周年イベント)でも、まつもとさんが「開発効率と保守性の向上のためのツールを整備していこう」と話していたので、そういう方向はずっとある感じです。
▶ Faas・FPGA・ヘテロジニアス…まつもとゆきひろ氏が予測する、コンピュータの未来 - ログミーTech
mame まつもとさんは対外的な場でもときどき「これからは開発環境の進化にフォーカスしていくぞ」っていう方針を示していますね。今回のRuby 3.1のリリースで必ずしもそれに呼応したわけではないんですが、確実にそういう方向性は見えると思います。
── 開発環境の充実に比べると、言語として目新しい機能はあまりない印象ですね。
mame 実際、そうだと思います。その中でも、ハッシュリテラルの略記が導入されたのはうれしい人がいるかもしれません。従来は{a: a, b: b}のように書いていたものが{a:, b:}と書けるようになりました。
── これは事実上のシンタックスシュガーの追加ですよね。むしろ、なぜ今までなかったのでしょう?
mame TypeScripに{x}でハッシュマップを作れる構文があって、Rubyにも同等の構文が欲しいという要望はあったんですが、波カッコは数学の集合の表記に使われているので反対という意見が根強かったんです。
── 集合の内包表記ではハッシュマップに見えない、ということでしょうか?
mame 実際、Pythonでは同じ構文で集合を作れますしね。
それでも需要はあるので「コロン付きで{x:}と書けるようにするのは問題ないだろう」ということで、今回のリリースで採用されました。キーワード引数で受け取ったキーと値が同じハッシュを他の関数にたらい回しする、といったときに便利かもしれません。
nurse Railsのコントローラーで取ってきたJSONを詰め替える、といった場面もよくありそうです。
ちなみに、文法まわりの新機能が少ないのは、特に意図したものではなく、たまたまですね。まつもとさんも一時期「文法はあまり変えないようにしよう」と話していましたが、今年(2021年)の初めくらいにまた「ヘンで複雑な文法を入れてこそのRubyなんだ」と達観していたので、これから新しい文法が入るかもしれません。
ko1 マクロ入れたいとかもありますね。
次に何がきても選択肢としてRubyが現実的であるように
── そろそろ3.2に向けた動きもあるでしょうが、今後のRubyが目指す方向は何でしょうか?
mame 大きな方向性はまだ決まっていません。まつもとさん自身、「3.0を出してから1、2年は次のことを考える期間にしたい」と言っています。
ko1 Ruby 4に向けてさらにパフォーマンスを向上させたいという気持ちはあるように思います。
mame 何らかの方法でベンチマークを速くできた人に懸賞金を出せないか、という話もありますね。
nurse 今後10年といった長いスパンの話としては、Webアプリケーション以外の分野でRubyを使ってもらえるようにしたい、というのはありますね。
ko1 10年前にも同じことを言っていましたね……。
mame 10年前というと、私を含めて「科学技術計算でRubyを使ってもらえるようにしたい」と言っていた人たちも少なくなかったんですよね。当時は「Rubyのような遅い言語で科学技術計算は無理」という声もありましたが、10年たってその領域をPythonが席巻している現状を見ると、複雑です。
nurse 自分は少し違う見方をしています。Pythonは10年前からポストPerlのポジションを築いていて、さまざまなところでずっと使われていました。たまたまWebアプリケーションという分野でRailsが勢いを得て、今に至っているわけです。
みんながいま機械学習でPythonを使っているのも、その当時のPythonの開発陣がその方面に注力したからというよりは、すでにもう研究室などで使われていたわけですよね。
ko1 次にRubyのようなプログラミング言語が必要になる分野といったら、何があるだろう?
mame WASMは少し気になります。Webブラウザで動かすものを作るのにJavaScriptのAPIを併用するという選択肢しかないと、そこでRubyを使ってもらう機会はほぼありません。WASMの上でRubyインタプリタを動かして実用的なアプリケーションが開発できるようになると、いいですよね。
実はRubyアソシエーションの開発助成の公募でそのような提案もあります。
▶ 2021年度Rubyアソシエーション開発助成金 公募結果発表
── JavaScript抜きでブラウザを完全に操作できる時代がきたとして、そこでインタプリタを動かすというアプローチはPythonでも可能なので、同じ土俵ですよね。
nurse 同じ土俵であれば「Rubyは開発効率がいいのでRubyを採用しよう」と言ってもらえると信じて、私たちはRubyを開発しています。なので、同じ土俵に立てるように布石を打つのが大事ですよね。
ko1 布石、とは?
nurse 例えばWASMに関して言うと、もしブラウザ上で好きな言語でアプリケーションを書ける時代がきたとして、そこでRubyが動かなかったら話にならないわけですよね。だから、そうならないように今からできることはやっておく、という意味です。
── まつもとさんが組み込み開発の領域でMRubyをがんばっているのも、同じ動機からでしょうか?
ko1 MRubyはCRubyと違うので何とも言えませんが、組み込みも「みんながCでやっていた領域で気が付いたらRubyという選択肢もある」という状況を目指しているのかもしれません。
nurse 言語を開発している自分たちの仕事は、「他の言語と対等な位置に居続ける」という状況を保っていくことなんですよね。そうすればRailsがそうであったように「Rubyの自由度を活用したライブラリやフレームワーク」がきっと登場して、Rubyをたくさん使ってもらえる。
そういう意味では、並行プログラミングの仕組みとしてRactorができたので、これを使ったアプリケーションが何か出てこないかなと期待してます。
ko1 Ruby 3.0で一通り仕組みを作ったものの、ライブラリが対応しきれていなかったので、今年(2021年)はそれを増やしていました。実際のところ、性能を出すのがすごく難しくてパフォーマンスチューニングも足りてないので、現状ではまだ少し遅いんですよね。2022年はそこを真剣にやる予定でいます。
mame そのような中でも「Ractorを使ってみよう」とチャレンジしてくれている方はいっぱいいるので、すごいと思っています。今年のRubyKaigiでも、Ractorをバックエンドにした並列テストのフレームワークが発表されています。
▶ Parallel testing with Ractors: putting CPUs to work by Vinicius Stock - RubyKaigi Takeout 2021
ko1 そういえばこの発表をしたVinicius Stock(@vinistock)さんもShopifyの方でしたね。
── たくさんのお話をありがとうございました。引き続きRubyの進化に期待しています。
▶ 参考記事: プロと読み解く Ruby 3.1 NEWS - クックパッド開発者ブログ
取材・執筆:鹿野桂一郎(技術書出版ラムダノート)
編集:はてな編集部




