
カオスエンジニアリングを導入したクックパッドの挑戦 マイクロサービス化に伴う可用性の低下に対応
料理のレシピ投稿・検索サービスのクックパッドでは2年前からカオスエンジニアリングに取り組み、さまざまな事例やノウハウを蓄積しています。クックパッドの技術部・SR(Site Reliability)グループの小杉山拓弥さんとDX(Developer Productivity)グループの鈴木康平さんに、導入の理由やさまざまな知見を伺いました。
カオスエンジニアリング(Chaos Engineering)とは、稼働中のサービスにあえて擬似的な障害を発生させることで、システムの耐障害性を検証する手法です。動画配信サービスを提供するNetflix社が2011年ごろから実践し、ソフトウェアや情報を積極的に公開したことで世界中から注目されるようになりました。
国内ではまだ導入事例も少ないなか、料理のレシピ投稿・検索サービスを提供するクックパッド株式会社では2年前からこの手法に取り組み、カオスエンジニアリングのさまざまな事例やノウハウを蓄積しています。
Chaos Engineering やっていく宣言 - クックパッド開発者ブログ
今回は、クックパッドの技術部・SR(Site Reliability)グループの小杉山拓弥さんとDX(Developer Productivity)グループの鈴木康平さんに、カオスエンジニアリング導入の理由や、この手法を成功につなげる知見について伺いました。
- まずは仮説を立てる
- ステージング環境におけるFault Injectionによる検証
- プロダクション環境での検証が必要になる理由
- 効果的な負荷試験のためツール構成を選択する
- 成熟したサービスだからこそカオスエンジニアリングが有効
- 小杉山 拓弥(こすぎやま・たくや)


- クックパッド株式会社 技術部 SR(Site Reliability)グループ
東京工業大学工学院情報通信系を修了後、2018年にクックパッド株式会社に新卒で入社。2020年7月よりSRグループリーダーを務める。最近は主に汎用負荷試験プラットフォームの整備や定期的なTest in productionに取り組んでいる。 - 鈴木 康平(すずき・こうへい)


- クックパッド株式会社 技術部 DX(Developer Productivity)グループ
2014年にクックパッドに新卒で入社。開発者の生産性を高めるため、CI環境の整備やWebアプリケーションを動かすプラットフォームの整備を主に担当している。
※新型コロナウィルス感染拡大防止の観点から、インタビューはリモートで行いました。
まずは仮説を立てる
── クックパッドは、なぜカオスエンジニアリングを導入したのでしょうか?
鈴木 前提としてクックパッドでは、これまでモノリシックだったサービスのマイクロサービス化を進めてきました(記事末の関連記事も参照)。サービス分割のプロジェクトは順調だったものの、マイクロサービス化に伴ってサービス全体の可用性が落ちている実感がありました。
なぜなら、サービス間の通信回数が増えるに伴って、通信が失敗するおそれのある箇所も増加してしまうからです。
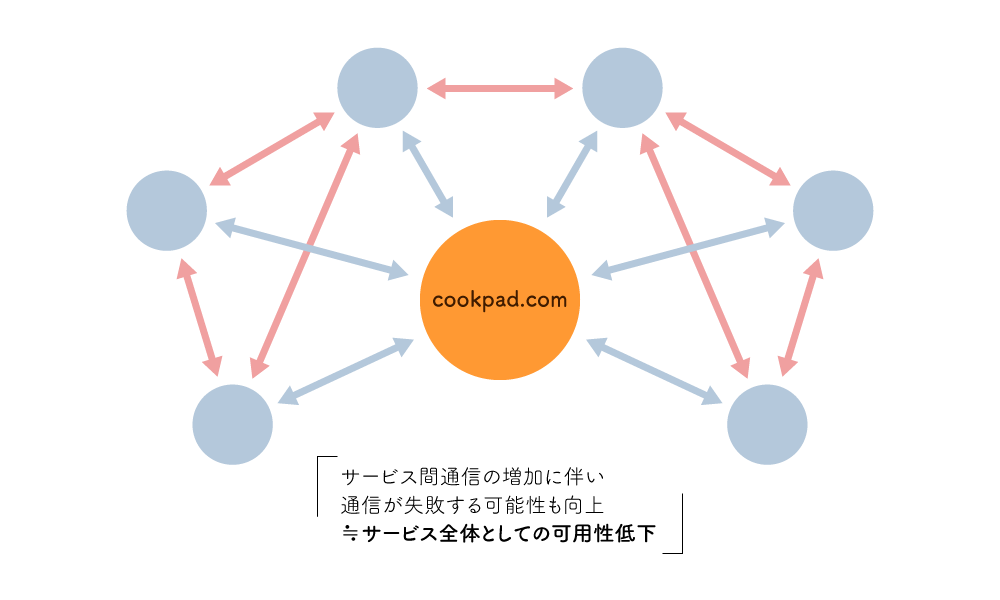
この課題を解決するため、技術部を中心に「カオスエンジニアリングが有効ではないか?」という話が持ち上がりました。そこで小杉山を主担当として、カオスエンジニアリングを推進することにしたのです。
── カオスエンジニアリングの導入を決めたといっても、まだ実践の参考にできる情報も限られていたのではないでしょうか。
小杉山 私たちが調査をはじめたのは、Netflix社がオープンソースソフトウェアとして公開したChaos Monkeyなどのツールが注目を集めていたころで、カオスエンジニアリングといえば「インスタンスやネットワークを落としてテストをする」というキャッチーな面ばかりがフォーカスされることもよくありました。
しかし、そうした表面的なテスト技法を学ぶよりも、カオスエンジニアリングにおいては「どのような思想に基づいて検証を行うのか」という理念を知ることの方が、より重要です。カオスエンジニアリングの原則を提唱した「Principles of Chaos Engineering」などは非常に役に立ちました。
他にも参考資料としては、Netflixの知見が解説された論文「Chaos Engineering paper」[PDF]や、技術ブログの記事「The Netflix Simian Army」、それから当時はまだ出版されていませんでしたが、現在であればオライリー社の書籍『Chaos Engineering』はとても参考になると思います。
例えばそういった資料には、カオスエンジニアリングにおいて仮説を立てることの重要性が記載されています。そうした情報を学べたことはとても有益でした。
── 「仮説を立てる」というのは、例えばどのようなことですか?
小杉山 冒頭で鈴木が話したように、当社においては「サービス間通信が増えることで、可用性が落ちているのではないか?」という懸念がありました。このケースにおいて仮説を立てる作業とは、通信でエラーが発生したときに「各サービスはどのようなふるまいをすべきなのか?」を考えることです。
複数のサービスが相互に通信をしているときに、いずれかのサービスがエラーになった場合、サイトの閲覧そのものができなくなるべきなのか? または、表示項目が少し欠けた状態でサイトは表示されるべきなのか? そういった仮説を立てた上で、検証を行います。
検証の結果、仮説が誤っていることが判明したならば、どのようにシステムを修正すれば適切な挙動になるのかを検討していきます。逆に、仮説を立てられない状態ならば、カオスエンジニアリングを導入するにはまだ時期尚早であるとも言えます。
ステージング環境におけるFault Injectionによる検証
── 実際にどういった検証から手を付けていったのかを教えてください。
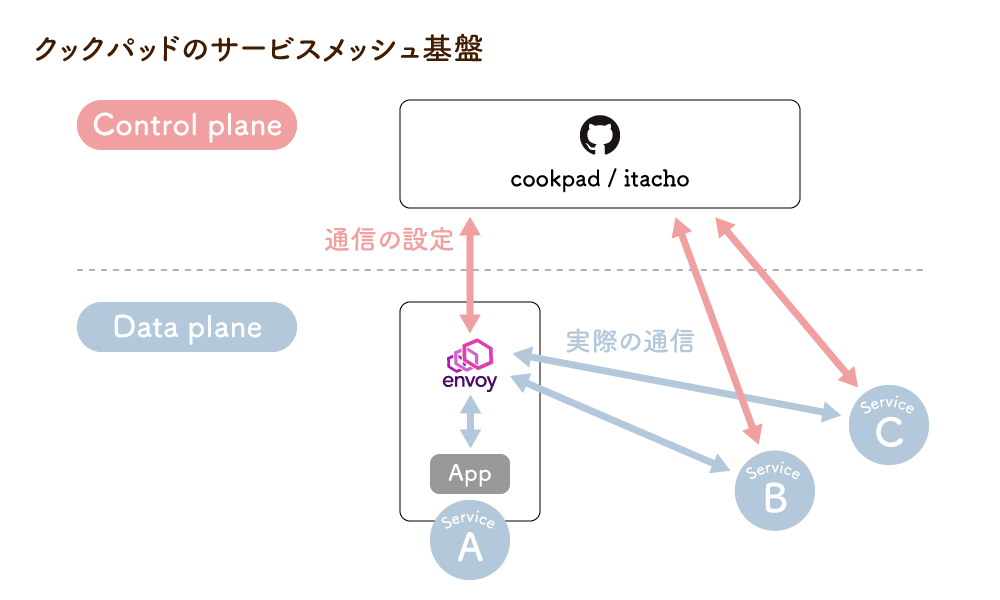
小杉山 カオスエンジニアリングの手法のひとつに、Fault Injection(障害注入)があります。当社はマイクロサービス化の推進に伴ってサービスメッシュ基盤を整備していますが、そのデータプレーンとして用いているEnvoyにはFault Injectionの仕組みが備わっているので、まずこれを活用しました。

このテストをネットワークに対して行い、想定する挙動と実態が合っているかを調べることにしました。クックパッドでは、ステージング環境もプロダクション環境も同じようなサービスメッシュ基盤を用いていますから、ユーザーに影響が出ないよう、ステージング環境で個別のサービスの検証を進めていきました。
── 検証によってどのような問題が分かったのでしょうか?
小杉山 例えばあるサービスでは、レシピ情報のAPI呼び出し結果をキャッシュしている機構に問題がありました。API呼び出しが一度失敗してしまった場合、APIの復旧後にも失敗した結果のキャッシュをひたすら返し続けていたのです。
実はこれには理由がありました。レシピ情報のAPIに障害が発生しているときに、呼び出し元がリトライをくり返すとサービスの負荷が高くなり、障害がさらに拡大するおそれがあります。つまり、延焼させない防壁のような役割を果たしていました。ところが、障害発生時のリトライ制御はサービスメッシュのレイヤーで実現できますから、アプリケーションの外でハンドリングした方がメンテナンス性に優れます。
このように不具合もいくつか発見でき修正もしましたが、全体としては自分たちが予想していたより遥かに適切なエラーハンドリングが、各サービスで行われていました。
── ネットワークに関する処理をアプリケーションレイヤーから分離できるのは、マイクロサービスや分散システムでサービスメッシュを用いる利点のひとつですね。
鈴木 そうですね。当社ではかつてExpeditorというgemを開発して、サービス間通信におけるリトライやフォールバックなどをアプリケーションレイヤーで実現しようと試みていた時期がありました。
ですが、gemはRuby言語専用のパッケージ管理システムです。マイクロサービス化が進み採用される言語・フレームワークが多様化するにつれて、Rubyでしか使えないことがネックになっていきました。
また、アプリケーションレイヤーでリトライやフォールバックなどを実現すると、各種の設定についてコンフィグファイルやプログラムの実装を読まなければ分からないという欠点も生じます。そうした課題を解決する上で、サービスメッシュの導入は非常に意義のあるものでした。

クックパッド株式会社 技術部 DX(Developer Productivity)グループ 鈴木康平さん
プロダクション環境での検証が必要になる理由
── 先ほど、Fault Injectionはステージング環境で「個別のサービス」の検証を進めたと言われましたが。
小杉山 各サービスのソースコードをひとつひとつ読みながら、他のサービスと通信が発生する箇所を洗い出し、機能ごとに検証を行っていました。
── それはかなりの作業量になりますね。
小杉山 このやり方ではスケールしませんし、全てのサービスを検証するには膨大な時間がかかります。
さらに、マイクロサービスへの移行に伴って、オーナーが明確でなくなっているサービスもありました。その場合、何らかの改修が必要になると(検証した)自分が手を動かすしかありません。
しかし、クックパッド社内で管理されているサービスには膨大な種類がありますから、とても抱えられるタスク量ではない。各サービスを個別で検証していくには限界があると考えました。
── 検証の進め方に課題が見えてきたわけですね。
小杉山 そのため、サービスの集合体である料理レシピ投稿・検索サービス「クックパッド」そのものに障害や負荷を注入し、検証する方が現実的だという考えに変わっていきました。大量のトラフィックをプロダクション環境で人工的に発生させ、システムの耐障害性を検証する方針を選択することにしたのです。
── それまでのステージング環境ではなく、検証対象をプロダクション環境に変更したのはどういった理由があるのでしょうか?
小杉山 どれだけ頑張ってステージングを構築しても、プロダクションと全く同じ検証環境を再現することは不可能です。それよりも、プロダクション環境を対象にカオスエンジニアリングを実施することで、サービスの抱える課題を洗い出そうと考えました。
── 対象とする環境を変更した後、どのような検証を行いましたか?
小杉山 重要な指標だと考えたのは、クックパッドのアクセス数が1年で最も多くなるバレンタインシーズンのトラフィックに耐えられるかどうか。そのトラフィック量を指標に、プロダクション環境に対する負荷試験を行うことにしました。
当社では毎年、バレンタインの時期には事前にシステムのキャパシティチェックを行い、大量のトラフィックに備えます。にもかかわらず2019年のバレンタインシーズンでは、トラフィックのピークでシステムのパフォーマンスが低下し、サービスが30分ほど利用できなくなりました。原因は、可用性の向上を目的としたミドルウェアのリプレイスにおける設定不備でした。
ユーザーが最も利用したいタイミングでサービスを提供できなかった。これは当社にとって真摯に受け止め、対策を考えるべき課題です。だからこそ、人工的に発生させるトラフィックの量は、バレンタインシーズンを指標としました。
効果的な負荷試験のためツール構成を選択する
── バレンタインシーズンと同じ負荷をどのように準備したのでしょう。
小杉山 トラフィック量については、ZabbixやAmazon CloudWatchで取得し続けている各種メトリクスのデータをもとに、大まかな予測を立てました。
また、クックパッドを利用するユーザーには、ログインしていないゲストユーザー、ログインユーザー、そして有料会員であるプレミアムサービスユーザーといった区分が存在します。そのうちバレンタインシーズンに増加するのはどういったアクセスなのか、ユーザー種類の内訳を把握することも重要でした。
── ユーザー種類が異なると、トラフィックの性質にも差が生じるのですか?
小杉山 例えば、クックパッドにはプレミアムサービスユーザーにのみ公開している機能があります。仮説として、バレンタインデーシーズンには普段あまりクックパッドを利用していないゲストユーザーが増えるだろうと予想しました。ゲストユーザーの割合が高くなるなら、プレミアムサービスユーザー向けの機能に対する負荷はほとんど増加しません。
また、ログインしていないユーザーが増えるということは、ユーザーごとに表示内容を出し分けるような機能はあまり利用されないことを意味します。どのユーザーにも同じ内容を表示する、キャッシュしやすいコンテンツへのアクセスが増えるわけです。
Google Analyticsを確認したところ、実際にゲストユーザーが増えていることが分かったため、人工的に発生させるトラフィックもゲストユーザーの挙動に決定しました。プロダクション環境に負荷試験ツールを用いて、ゲストユーザーのトラフィックを大量に発生させながら、サーバの各種メトリクスを監視し、検証を進めていきました。
── 負荷試験ツールには何を用いましたか?
小杉山 はじめのうちは、LocustというPython製のツールを使いました。ツールを比較・検討したなかで、プログラマブルなシナリオの書きやすさ・拡張性・開発頻度・ECS上での動作の観点で良いと感じたためです。
ですが、使用していくうちに課題が見えてきました。Locustはマスター・スレーブ構成を用いて、シナリオを実行するサーバをスケーリングさせます。ですが、このツールではスレーブの数を負荷試験の途中で動的に変動させることが難しいことが分かってきました。かといって、多くのスレーブを事前にスタンバイさせておくと、負荷試験にかかる金銭的コストが高くなってしまいます。
そのため、途中からserverless-artilleryというツールに乗り換えました。これはArtilleryというNode.js製の負荷試験ツールを、serverless frameworkを使用してAWS Lambdaにデプロイして動かせるというものです。
serverless-artilleryはサーバーレス環境上で動作するため、AWS Lambdaの起動数上限にさえ達していなければ、どこまでもスケールします。また、AWS Lambdaはリクエストの数とコードの実行時間に基づいた従量課金となっているため、金銭的コストが安く抑えられました。このツールは非常におすすめできます。
── 負荷試験の結果、何が分かってきましたか?
小杉山 一例を挙げると、予想していたよりもレシピ詳細画面のレイテンシーが大きいことが分かりました。
調査を進めていくと、不必要なリクエストやN+1クエリなど、パフォーマンスを低下させる要因が発見できました。コードを修正してパフォーマンス改善したことで、サービス提供に必要なコンテナの数も減らすことができたため、コスト削減にも結びついています。
その後も、プロダクション環境での負荷試験を継続的に行い、システムの耐障害性に問題がないかを検証し続けています。
クックパッド株式会社 技術部 SR(Site Reliability)グループ 小杉山拓弥さん
成熟したサービスだからこそカオスエンジニアリングが有効
── クックパッドの事例では、プロダクション環境での負荷試験が有効に働きました。ですが企業によっては「プロダクション環境での試験なんて、とんでもない」と社内からの拒否反応が起きるケースもあるかもしれません。そうした場合、どのように説得すべきでしょうか?
小杉山 前提として、確かにプロダクション環境での検証を行う場合は、サービスがダウンしてユーザーに影響を与えてしまう可能性をゼロにはできません。だからこそ、カオスエンジニアリングに取り組む際には社内調整を適切に行うことが大切になると思います。
例えば私たちの事例においては、真のトラフィックピークであるバレンタインシーズンにサービスがダウンするよりも、利用者が比較的少ない時間帯にサービスに負荷をかけて課題を発見した方が、ユーザーへの影響は軽減できる。その事実を社内のメンバーに伝えていく必要がありました。
それから、冒頭で「仮説を立てることが重要」と述べたことにも通じるのですが、カオスエンジニアリングによって何を解決したいのかと、その取り組みによってどれくらいサービスを改善できるのかを社内の関係者に説明できるようになってから実施しなければ、効果が薄くなってしまいます。
私の場合は、プロジェクト序盤にプロダクション環境での負荷試験についてデザインドキュメントを書き、SRグループのメンバーに内容をチェックしてもらった上で進行しました。
── とても勉強になりました。最後に、テクノロジーを事業の柱にしている企業がカオスエンジニアリングに取り組む意義についてお話しください。
小杉山 カオスエンジニアリングの導入は、システム全体が巨大であり複雑になっていることが前提であると考えています。逆にいえば、複雑性が高くない段階でカオスエンジニアリングを取り入れても、効果が薄いです。
マイクロサービスや分散システムの推進によってサービス間通信が増え、障害が発生しうる箇所が増えた状況において、システム全体の信頼性を向上させたい場合や未知の脆弱性を発見したい場合に、今回ご紹介したような手法が役に立つと私は考えています。
鈴木 小杉山と同意見で、やはりシステム全体がある程度は成熟している状況でないと、カオスエンジニアリングは有効に働きません。普段は正常に動作しているけれど、何かのきっかけでシステムが不安定になってしまう。つまり障害や大量アクセスが起きたときでないと脆弱性が見つからないようなケースにおいて、カオスエンジニアリングという手法が効果的になるはずです。
── ありがとうございました。
取材・執筆:中薗昴




