
Kaggleは実務の役に立つ? データサイエンティストがKaggleから学んだ「教師あり学習」の勘どころ
機械学習のトレーニングとして、Kaggleに挑む方は多いでしょう。ただ、Kaggleで鍛えて、データサイエンティストとしての実際の業務に生かせるの?こんな疑問にこたえるべく、日本経済新聞社のデータサイエンティスト、石原祥太郎さんが、「仕事とKaggle」の関係性を綴ります。
日本経済新聞社でデータサイエンティストとして働いている石原です。
本稿では、筆者が社外活動として取り組んでいる世界規模の機械学習コンペティション「Kaggle」を紹介します。特に「Kaggleがどのような観点で実務に役立っているか」という筆者の経験談を基に、Kaggleの魅力をお伝えすることを目的としています。
筆者は2017年10月に新卒で日本経済新聞社に入社後、2018年に個人活動としてKaggleに取り組み始めました。2019年4月には社外の知人と参加した「PetFinder.my Adoption Prediction」コンペで優勝し、12月のイベント「Kaggle Days Tokyo」でコンペ開催側の経験もあります。データサイエンティスト協会のシンポジウム登壇や、入門書『PythonではじめるKaggleスタートブック』(講談社、石原祥太郎/村田秀樹・著)の出版も経験しました。
本稿の流れを以下の目次に示します。最初にKaggleの概要を簡潔に説明し、その後に個人的なKaggleと実務との関わり方を述べます。筆者の体験談は「遊ぶ、学ぶ、広がる」という観点でまとめられます。各観点について、具体例とともに紹介していきます。
会社ごとに「データサイエンティスト」の定義や、担う役割は異なる部分があり、筆者個人の体験を一般化することは難しいかもしれませんが、Kaggleの魅力を伝える一助となれば幸いです。
Kaggleの概要
Kaggleとは、世界最大の機械学習コンペティションのプラットフォームです。企業や研究機関などが提供するデータについて、世界中から集まる参加者が機械学習モデルの性能を競います(図1)。
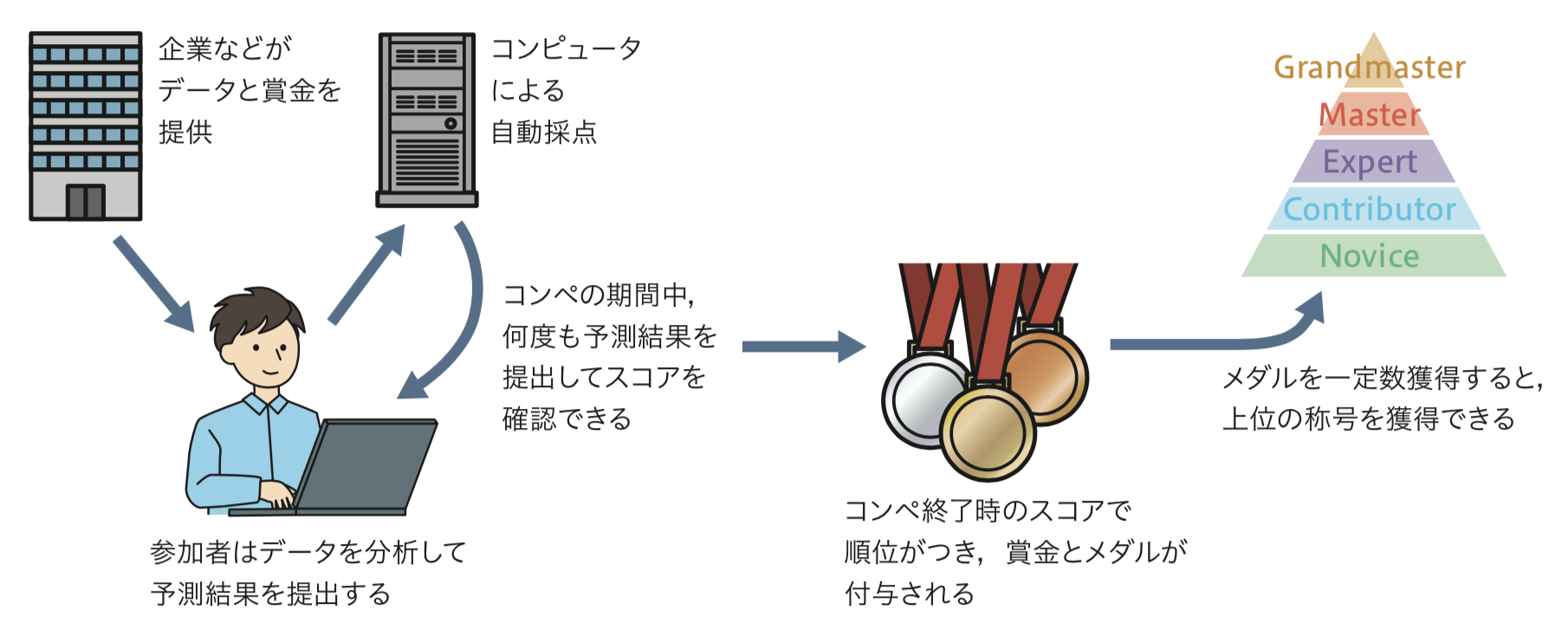
図1:Kaggleのコンペの概要(出典:『PythonではじめるKaggleスタートブック』p.13)
Kaggleで参加者が競うのは、機械学習モデルの性能です。特に「教師あり学習」に関する課題が設定されることが多いです。教師あり学習とは、コンピュータに問題と答えの対をいくつか教えることで、教わっていない問題にも正しく回答できる汎化能力をコンピュータに獲得させる手法です。
大雑把に表現すると図2のように、問題(X_train)と答え(y_train)の対応関係を学習し、教わっていない問題(X_test)に対応する値(y_test)を予測するという考え方です。
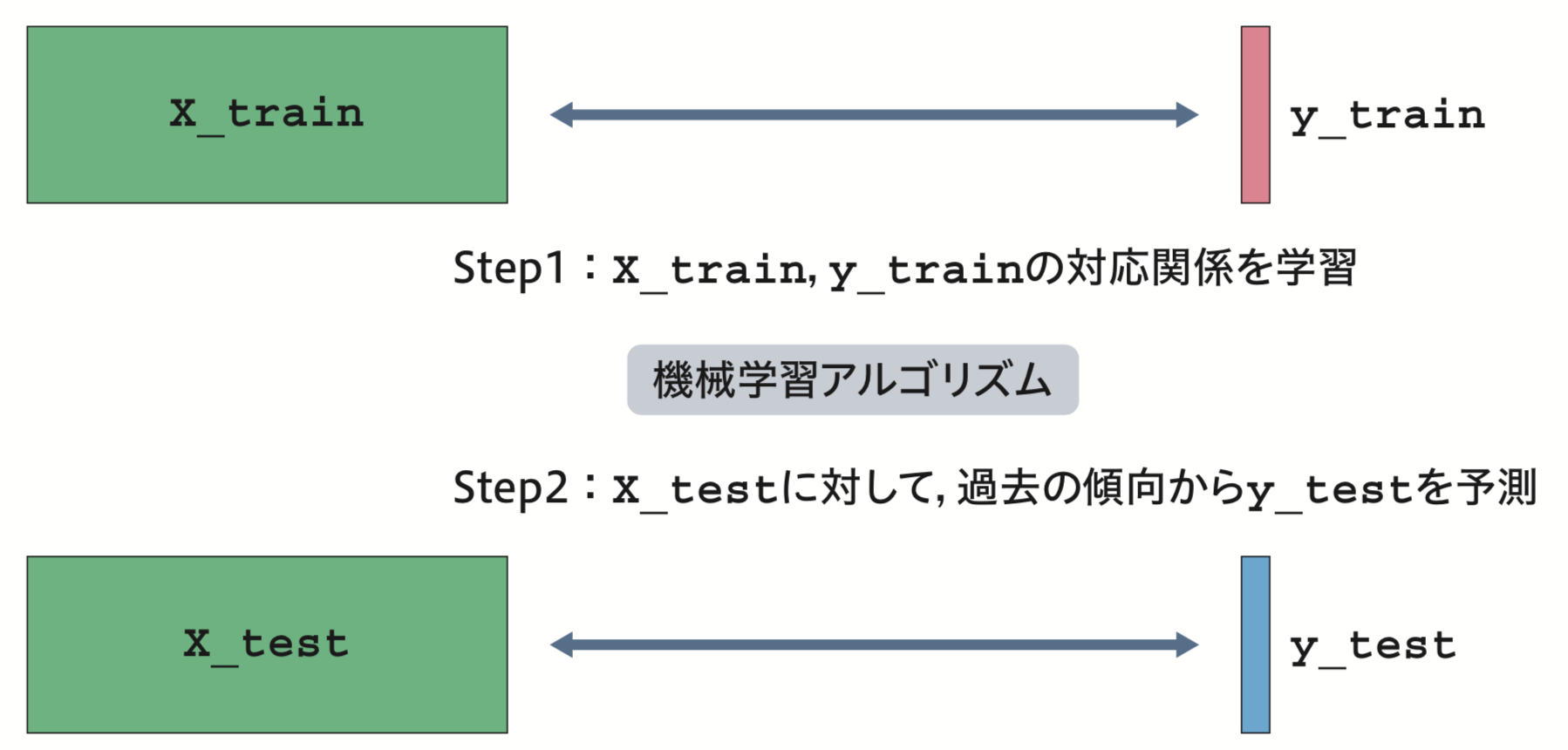
図2:教師あり学習の概要(出典:『PythonではじめるKaggleスタートブック』p.18)
こうした機械学習の技術は、日常のさまざまな場面で活用されています。例えば、迷惑メールの判定です。 この判定に教師あり学習を用いる場合、過去の「メールの情報(文面・送信アドレスなど)」と「それが迷惑メールかどうか」というデータが利用できます。これらのデータで学習させることで、新しく届いたメールが迷惑メールか否かを判定できる仕組みとなっています。
「問題」と「答え」の対応関係を学習するために、さまざまな手法(機械学習アルゴリズム)が提唱されています。近年飛躍的な進歩を遂げている「深層学習(ディープラーニング)」は、機械学習アルゴリズムの一つに当たります。
Kaggleでは、次のような情報が参加者に提供されます。
- 解くべき課題
- 課題の評価方法
- 学習用のデータセット(問題と答え)
- 性能を評価するデータセット(問題)
参加者はこれらの情報を用いて、可能な限り性能の高い予測を提出します。提出した予測は、開催側のみが把握しているy_testを用いて性能が評価されます。
与えられたデータセットをどのように予測に適した形に整形するか、どのような機械学習アルゴリズムをどのように利用するかーーなどが参加者の腕の見せ所です。
Kaggleと実務
いよいよ本題です。「Kaggleは実務に役立つか?」というのは、SNSなどで定期的に話題になります。この議論に対する2020年現在の個人的な見解を述べると「Kaggleは、実務の一部に役立つ可能性があるネットゲーム」です。
Kaggleは自分にとって、例えば旅行・映画鑑賞・食べ歩きなどに相当する位置づけです。退勤後や休日に、勝手気ままに取り組む趣味の一つとして捉えています。
あくまで趣味なのですが、私がデータサイエンティストとして実務に従事する中で、ときおりKaggleから利益を享受する場面に遭遇します。
以下では、筆者のKaggleに関する体験談を「遊ぶ、学ぶ、広がる」という観点で紹介します。
Kaggleで「遊ぶ」
筆者がKaggleを本格的に始めたのは、新卒入社後の最初のゴールデンウィークでした。筆者は学生時代の大半を研究活動と課外活動の学生新聞制作に捧げており、大学を離れた段階で特筆すべき趣味がない状況でした。長期休暇にまとまった時間が確保できたことで、学生時代から存在は知りつつも何となく忌避していたKaggleに取り組むことを決めました。
Kaggleはオンライン上で開催されているので時間を問わず参加でき、暫定の順位表が常に更新されるといったゲーム性もあります。筆者は最初に参加したコンペで上位10%に入れた成功体験もあり、完璧にのめり込んでしまいました。
Kaggle以外の機械学習コンペティションのプラットフォームにも、積極的に参加しています。例えば日本のサイト「SIGNATE」では、経済産業省が主催したコンペで3位入賞を果たしました。土日を利用し、参加者がオンラインではなく現地に集まって開催される形式のコンペにも足を伸ばしています。
熱中できる趣味に出逢えたことは、自分の人生を豊かにしてくれていると感じます。一般に企業勤めになると所属企業外での交友関係が狭くなる傾向がありそうですが、筆者の場合はKaggleなどの機械学習コンペを通じ多くの知人もできました。プライベートの充実が、本業に良い影響を与えている面もあると思います。
Kaggleで「学ぶ」
Kaggleを通じては、実務に関係する知見を学ぶ機会も多いです。
現在の業務の中では、機械学習を活用したデータ分析・機能開発を担当する場合があります。例えば、以前に日経電子版の法人向け情報サービス「日経電子版Pro」について、機械学習の教師あり学習を用いて、ユーザの利用動向からマーケティングや機能開発に役立つような気付きの抽出を試みました。
この分析では、Kaggleで学んだ、次のような教師あり学習の一連の流れを活用しました。
- 探索的なデータ分析
- 機械学習アルゴリズムの利用方法・解釈
- 評価方法の設定
1について、Kaggleでは優れた機械学習モデルを作るために、与えられたデータセットを詳細に分析する過程が大切です。データセットをさまざまな切り口で眺めることで、予測に寄与する仮説を得る目的があります。
このような探索的なデータ分析の経験は、実務に還元されています。どういう観点でデータを分析すると良いか、どのようにプログラミング言語で記述できるかなど、手持ちの選択肢が蓄積されている感覚です。
例えば、Pythonを用いることで次のようにデータセットの概要を把握しました。3、4行目ではそれぞれ、データセットの列ごとの基礎統計量・欠損値の割合を出力しています。
import pandas as pd train = pd.read_csv('train.csv') print(train.describe()) print(train.isnull().sum() / len(train))
実務の世界ではKaggleと異なり、そもそもの機械学習が価値を生みそうな課題設定の部分から、自分自身で取り組む必要があります。探索的にデータセットを分析して仮説を抽出する作業が、Kaggle以上に重要です。
2の機械学習アルゴリズムについても、入力のためのデータセットの整形方法やPythonのライブラリの使い方など、Kaggleで学んだことを用いる場面がありました。例えば、次のように「機械学習アルゴリズムでどんな情報が予測に使われたか」を確認する方法は、本分析の根幹を担っています。
feature_importance = clf.feature_importances_
機械学習アルゴリズムの解釈性は、Kaggleでもよく登場する話題です。いくつかの手法の選択肢の中から、それぞれの特徴を鑑みて業務での要件に即した手法を選択できたと考えています。
3の評価方法についても、実務では自分で設定しなければなりません。ここでは、数々のKaggleコンペに参加してきた経験が活きました。
各コンペでは、課題設定に応じたさまざまな評価指標が定義されています。コンペに取り組む中で、評価指標の特徴を身にしみて実感できるのはKaggleの利点の一つです。
よく知られた評価指標の一つに、正しく当てた割合を示す「正答率」が挙げられます。しかし正答率は、予測の対象に偏りがあると上手く機能しないという欠点があります。例えば予測の対象のうち「Aが99%、Bが1%」の場合、何も考えずに「全てA」と答えるだけで99%の性能が得られてしまいます。
本分析の予測の対象は「解約したか否か」で、一般的に解約はそれほど多い事象ではなく、不均衡なデータセットでした。そのため評価指標は正答率ではなく、予測の対象が不均衡な場合に頻繁に用いられる「AUC」を採用しました。
その他、本分析の詳細な内容については外部発表を取材してもらった記事をご参照ください。
機械学習の理論・実践以外の面でも、広くプログラミング全般に関して勉強する部分も少なくありません。
Kaggleにはソースコードを実行・公開できる「Notebooks」という環境があります。優れたプログラマのソースコードを見ることで、効率的な書き方や新しいライブラリの使い方を知ることも多いです。
Kaggleでは、チームを組んでコンペに参加できます。開催中に参加者同士でチームを組むことも可能で、時には外国人の方と一緒になる機会もあります。今まで以上に、他人に共有できる再現性のあるソースコードの書き方を意識するようになりました。
コンペの開催期間は数カ月程度あり、以前のコンペのソースコードを使い回せる場合もあります。バージョン管理システムの「Git」「GitHub」や、環境構築のための「Docker」についても、Kaggleに取り組む中で必要性や重要性を改めて実感しています。Kaggle用の自作Pythonライブラリの開発を通じては、テストコードの書き方や有り難さなども学びました。
Kaggleのようなコンペ開催のためのウェブサイトを自作している方の影響を受けて、フロントエンド・バックエンド開発にも食指が動きました。「Nuxt.js」や「Django REST framework」など、データサイエンスに留まらない領域にも手を伸ばすきっかけが得られています。
Kaggleで「広がる」
Kaggleでの学びを経て、実務で扱う領域の幅も広がっています。
現在の筆者は、新規サービスの企画・開発チームに所属しています。サービスの利用動向を分析しながら新機能の開発に取り組むうえでは、仮説に基づいて機能のプロトタイプを迅速に作成し検証していく過程が大切です。この過程に対して、Kaggleを通じてさまざまな領域を「つまみ食い」してきた経験が活きています。
例えば新機能開発のアイディアとして、新聞記事などのテキストデータを利用する場合があります。以前は機械学習におけるテキストデータの扱い方を把握できていませんでしたが、Kaggleで「自然言語処理」と呼ばれる分野のコンペに参加した経験から、伝統的なベクトル化方式や「BERT」と呼ばれる近年躍進を遂げた手法など、いくつかの選択肢を手持ちのソースコードで実装できるようになりました。
実務で初めて直面する案件でも「そもそも機械学習を使うべきか」「どういった手法があり得るのか」「どうやって性能を検証すべきか」など、ある程度の勘所を持って臨める場面が増えているように感じています。
通常業務の範疇を超えて、冒頭で述べたように2019年12月開催のイベント「Kaggle Days Tokyo」では、日本経済新聞社がデータセットを提供し、問題設計の部分からコンペ開催に携わりました。当日は世界各地から集まった88チーム149人が参加しました。コンペ設計に不備がないか最後まで不安は尽きませんでしたが、社外活動として取り組んできたKaggleに仕事として関われたことは非常に光栄でした。コンペに対する参加者の取り組みは学びが多く、得られた知見は社内に還元しています。
このコンペ開催については、情報技術とジャーナリズムに関する国際シンポジウム「The Computation + Journalism Symposium」に論文を投稿し、採択されました。2020年秋に、アメリカでポスター発表を実施予定です。筆者が企業勤めになってからもアカデミックな場に顔を出せているのは、Kaggleの恩恵の一つと言えるでしょう。
おわりに
本稿では、Kaggleの概要を簡潔に説明し、個人的なKaggleと実務との関わり方について「遊ぶ、学ぶ、広がる」という観点で筆者の体験談を紹介しました。
「Kaggleは実務に役立つか?」という問いに対する個人的な見解を通じて、Kaggleの魅力を伝えできていれば嬉しいです。
石原祥太郎(いしはら・しょうたろう)

日本経済新聞社でデータサイエンティストとして、データ分析・サービス開発に従事。研究開発部署「日経イノベーション・ラボ」にも関わる。社外活動としてKaggleに取り組み、2019年にチームで参加したコンペで優勝。入門書『PythonではじめるKaggleスタートブック』(講談社、石原祥太郎/村田秀樹・著)の執筆や、勉強会の主催・登壇など、積極的な情報発信にも努めている。




