
Kubernetes-nativeなアーキテクチャ導入の手引き 先進的なクラウド環境を最強テストベッドで体験
Kubernetes-nativeなエコシステムを実現する最強テストベッド環境です。さまざまなミドルウェアを運用したマイクロサービスをフルgRPCなサービス間通信で実現するだけでなく、CI/CDと開発環境も用意しています。
こんにちは。株式会社サイバーエージェントのAI事業本部でインフラエンジニアをしている青山真也(@amsy810)と漆田瑞樹(@zuiurs)です。今回は、Kubernetesが好きな2人が考える最強のKubernetes-nativeなお試し環境を構築してみました。記事公開時点で、総コミット数が900に迫るリポジトリになっています。
現在、Kubernetesとそれを取り巻くエコシステムは急速に発達しており、便利なツールやミドルウェアが日々生まれています。これはとてもよいことですが、一方で「どのミドルウェアをどうやって運用すればよいのか?」「どのようにアプリケーションと結合すればよいのか?」と混乱してしまう方も多いかもしれません。
そうした課題を解決するため、自前のクラスタにさまざまなミドルウェアや、それを利用したマイクロサービスをデプロイして、動作や運用感を確認できるテストベッドを作りました。

これを参照することで、マニフェストの設定例や実装例を知ることができ、さらに自分で変更して試すこともできるようになります。
また、このテストベッドではKubernetesのCRDやOperatorなどの機能をフル活用し、自動的にミドルウェアの管理を任せるKubernetes-nativeな手法を数多く利用しています。ぜひ先進的な実現方法を体験してみてください。
本記事では、このテストベッドの利用方法、アーキテクチャ、使用したミドルウェアの運用、実装などについて説明していきます。
- もう迷わない! 必要なミドルウェアの盛り合わせ
- クラウドネイティブなCI/CD! その名はGitOps
- クラウドネイティブ時代のステートフルなミドルウェア
- 次世代の標準 フルgRPC通信なモダンなアプリケーション
- 最後に ─ クラウドネイティブを実現するひとつの答え
もう迷わない! 必要なミドルウェアの盛り合わせ
クラウドネイティブに関連するミドルウェアは、CNCF(Cloud Native Computing Foundation)によるCloud Native Interactive Landscapeというページで確認できます。数多くのミドルウェアが存在しているため、これを見た多くの方が、導入で述べたように「どれを選択すればよいか分からない」という気持ちになると思います。
幸い、私たちはKubernetes界隈に長らく身を置いているため、KubeConなどさまざまなクラウドネイティブ系カンファレンスから伺える特定のコミュニティの盛り上がり具合や、CNCFプロジェクトへの採択状況から、「どのような技術・ミドルウェアが流行しているのか」をある程度認識していました。その知識をもとに、Kubernetes上で開発する際によく使われそうなミドルウェアを中心にピックアップして、このテストベッドで動かすことにしました。
しかしながら、クラウドネイティブなミドルウェアを選定するだけでは不十分です。クラウドネイティブとは、管理の容易さや、可観測性、疎結合性、回復性などの特徴を持つシステムを指すため、ミドルウェアを素の状態でKubernetes上で動かそうとすると、リソースの作成から運用まで、多大な時間を使うことになるでしょう。そこでこのテストベッドでは、そういった面倒ごとを自動的に担ってくれるOperator(カスタムコントローラ)を最大限に利用します。
KubernetesのCRDとOperatorを最大限に利用
もう少し詳しく説明しましょう。
Kubernetesには、CRD(CustomResourceDefinition)とOperatorという仕組みが用意されています。CRDは、Kubernetesがデフォルトで扱うことが可能なリソース以外の独自リソースを定義することができる機能です。例えば下記のMysqlClusterリソースのようなものも作ることができます。
apiVersion: mysql.presslabs.org/v1alpha1 kind: MysqlCluster metadata: name: product-db namespace: product spec: replicas: 2 secretName: product-db mysqlVersion: "5.7" backupSchedule: "0 0 */2 * *" backupURL: s3://product-db/
Operatorは、このCRDからリソースが実際に作られた際に処理を行うプログラムです。上記の例では、マニフェスト登録後に自動的にMySQLクラスタを作成し、運用もし続けてくれます。現在のKubernetesを前提としたシステムの多くは、このように動作させるものが多くなってきています。
海外でも「Kubernetes-native」という単語を見かけるようになりましたが、私たちはこの語句を、広義では「Kubernetesを前提として作られているもの」、狭義では上記の例のように「KubernetesのCRDを用いてマニフェストで全て定義や設定することが可能なもの」だと認識しています。
今回は、狭義でのKubernetes-nativeなテストベッドを作るべく、全体を設計しています。
Kubernetes-nativeインフラ、秘伝の書
このテストベッドでは、上述したようなミドルウェアを全て組み込むため、ECサイトを題材に構成しています。ECサイトは万人が理解しやすく、コンポーネントも多いためマイクロサービスにしやすいことも採用の意図です。
それでは、アーキテクチャ図をご覧ください。
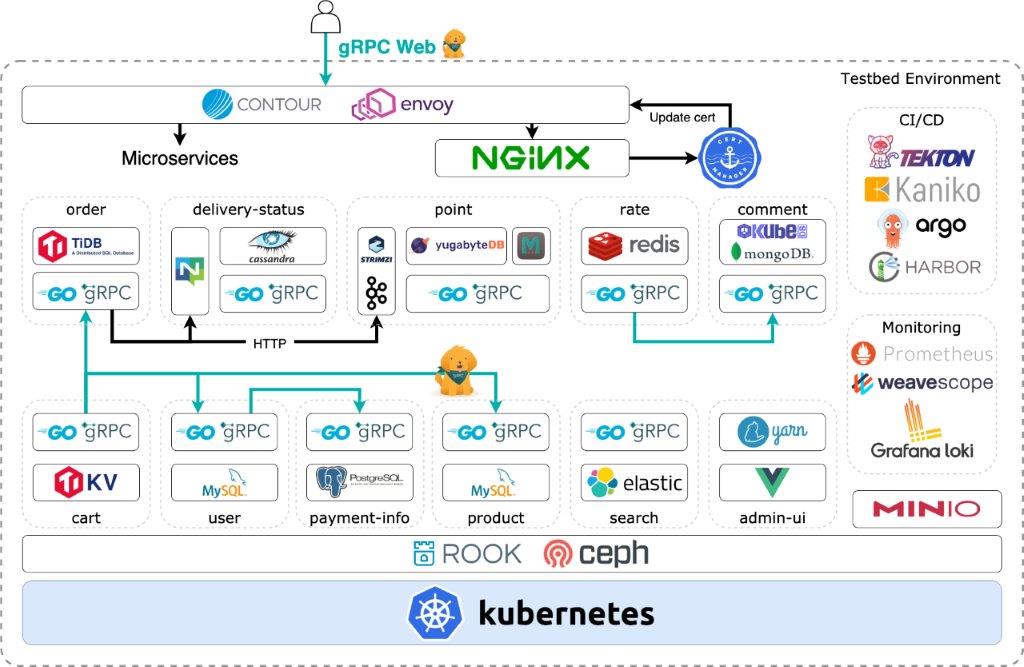
ここではCI/CDやコンテナレジストリ含め、全てがKubernetes上だけで完結しています。ストレージ基盤にはRook(Ceph)を使用しており、その上で各種マイクロサービスのデータベースなど、ステートフルアプリケーションが稼働します。
サービス間の通信は、Message Queueを除く全てをgRPCで行っており、ユーザーとそのリクエストを受け付けるL7 LoadBalancerであるContour間の通信も、gRPC(厳密にはgRPC Web)で行っています。
マイクロサービスは11個に分かれており、基本的にデータストアはそれぞれ異なったものを使用しています。各サービスの役割については、このプロジェクトの本質ではないため説明を省きますが、サービス名でいくらか理解していただけると思います。
今回ミドルウェアとして利用したOSSは次の一覧の通りです。圧巻ですね。
このテストベッドを手元の環境やクラウドで動かしたい場合は、テストベッドのリポジトリの指示に従って、準備してください。

クラウドネイティブなCI/CD! その名はGitOps
クラウドネイティブなテストベッドを開発していくにあたり、まず準備しなければならないのはCI/CD環境です。CNCFが公開しているクラウドネイティブへの道標となるCNCF TrailMapでも、CI/CD環境を準備した方がいい旨は序盤に書かれています。
アプリケーションのデプロイ、インフラの構成変更といった作業は、オーケストレーションツールであるKubernetesを使った環境でも非常に面倒です。アプリを修正するたびにコンテナイメージをビルドして、マニフェストのタグを書き換えるというのはとても単調で退屈な作業ではないでしょうか。
その作業を序盤のうちから排除することで、アプリの開発に費やす時間を増やすことができます。今回はKubernetes-nativeをテーマとして掲げているため、CI/CD環境には下記のOSSを選定しました。
| OSS名 | 用途 |
|---|---|
| Tekton(Pipeline、Triggers) | Kubernetes-nativeなCIツール |
| ArgoCD | Kubernetes-nativeなCDツール |
| Harbor | コンテナイメージを保管しておくコンテナレジストリ (CNCFのIncubatingプロジェクト) |
| Clair | コンテナイメージの脆弱性スキャナー |
| Kaniko | Kubernetes上のコンテナ上でコンテナイメージをビルドする |
上記のOSSを用いて、今回はGitOpsの環境を構築しています。Kubernetes環境におけるCI/CD環境といえばGitOpsが一番有名ではないでしょうか。
GitOpsでは「アプリケーションソースコードのリポジトリ」と「マニフェストファイルのリポジトリ」を用意しておき、CIとCDが適切に分離された状態でパイプラインを構成していきます。なお、リポジトリではなくディレクトリなどでもかまいません。
今回は、テストベッドの性質上、モノレポ構成でディレクトリを切って、1つのリポジトリの中にソースコードもマニフェストも格納しています。
なお、実務でGitOps環境を構築する場合には、ブランチ戦略を踏まえてステージング用のクラスタとプロダクション用のクラスタを用意したり、ソースコードのリポジトリに対してプルリクエストが作られた際にKubernetesの環境を作るなどして、より複雑なGitOps環境を用意することもあります。
それでは、実際に今回のテストベッド環境でGitOps環境がどのように作られているか、下図の内容を順に解説していきます。
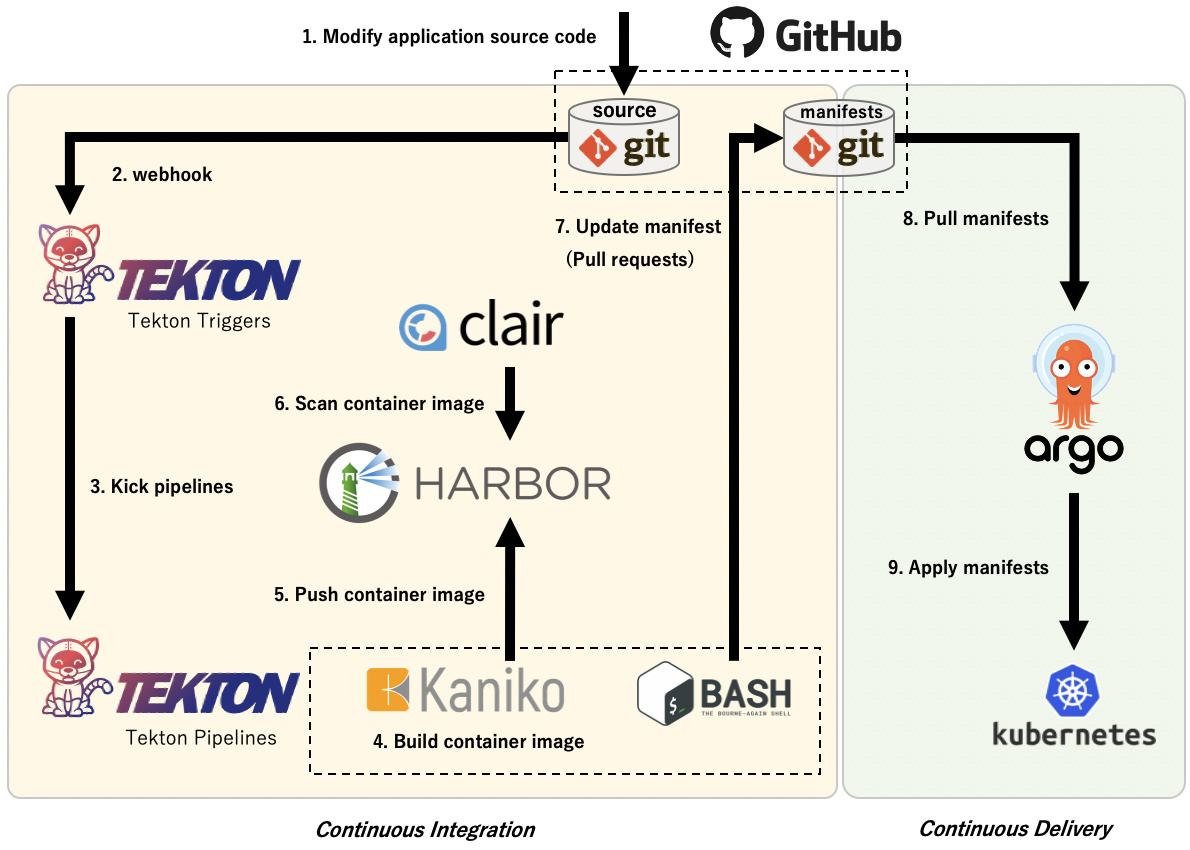
1-2. Modify application source code & Webhook
アプリケーション開発者によってソースコードのリポジトリにコミットが行われると、GitHubからTekton TriggersにWebhookが送られるように設定しておきます。
このとき、Tekton Triggersでは下記のようなEventListenerリソースのマニフェストを記載しておくだけで、Webhook先のURLをKubernetes Serviceとして払い出してくれます。
apiVersion: tekton.dev/v1alpha1 kind: EventListener metadata: name: github-listener namespace: tekton-pipelines spec: serviceAccountName: tekton-sa serviceType: ClusterIP triggers: - template: name: microservice-ci-trigger bindings: - name: admin-ci interceptors: - github: secretRef: secretName: github-webhook-credentials secretKey: github-webhook-secret namespace: tekton-pipelines eventTypes: - push - cel: filter: body.ref == 'refs/heads/develop' && !body.commits[0].message.startsWith('[Update manifest]')
今回はContourでエンドポイントを公開するためtype: ClusterIPで指定してありますが、type: LoadBalancerで指定しておけば、払い出されるグローバルIPをGitHubのWebhook先URLとして指定するだけで、トリガーを設定することが可能です。
このEventListenerを契機にして、どういったイベントタイプ(push、pullrequestなど)やペイロードで発火するかなどを設定可能です。

3. Kick pipelines
Tekton TriggersがWebhookを受けた後は、Tekton Pipelinesが発火します。Tektonでは下記のように、Pipeline定義をKubernetesのマニフェストとして定義することが可能です。もちろんGitリポジトリの登録情報やコンテナレジストリの登録情報なども、Kubernetesのリソースとして定義できるようになっています。
apiVersion: tekton.dev/v1alpha1 kind: Pipeline metadata: name: ci namespace: tekton-pipelines spec: ...省略... tasks: - name: build-and-push taskRef: name: kaniko-build-and-push ...省略... conditions: - conditionRef: check-is-target-microservice ...省略... - name: pull-request-manifest taskRef: name: pull-request-manifest runAfter: - build-and-push ...省略...
今回はコンテナイメージをビルドし、その後にマニフェストを更新するプルリクエストを送るパイプラインを組んでいます。
また、今回はモノレポ構成なので、このパイプラインが特定のマイクロサービスに対する更新かどうかを判断するためにTektonのConditionという仕組みも利用しています。

4-5. Build and Push container image
コンテナのビルドは、Kubernetes上に起動するコンテナ上でビルドを行うKanikoを利用しています。Kanikoではイメージをビルドした後で、コンテナレジストリに対してPushも行います。今回は、Kubernetes上で動作しているHarborに対して、ビルドしたイメージを保存します。
6. Scan container image
Harborへの登録後は、コンテナイメージの脆弱性スキャナーであるClairによってチェックされます。
なお、このプロジェクトの開始時点でHarborのデフォルトスキャナーはClairでしたが、今後は個人が開発しはじめてAqua Securityに買収されたことでも有名なTrivyがデフォルトとなっていくようです。本テストベッドでも将来的には置き換えていく予定です。
7. Update manifest (Pull requests)
イメージビルドが成功した後は、そのイメージを利用するようマニフェストリポジトリを書き換え、プルリクエストを作成します。このプルリクエストをマージすればクラスタに反映され、クローズすれば破棄することが可能です。
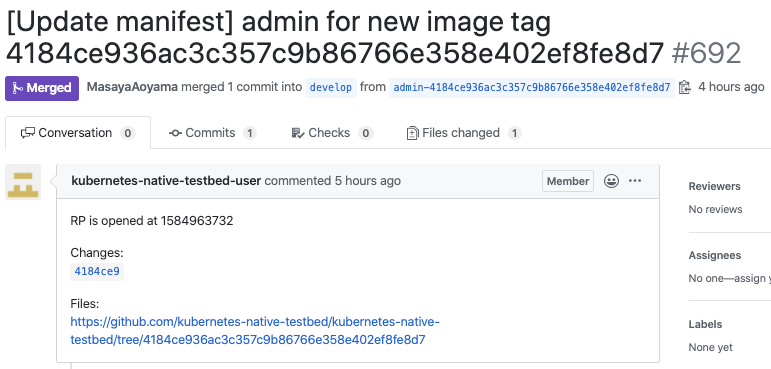
また、コンテナイメージには、ソースコードに対する変更を行ったコミットハッシュを利用して、admin:3e5a988d908f7e726c9830d5d687673307c9f636のようなタグを付けています。
そのため、プルリクエストの例にあるように変更差分や、現在クラスタにデプロイされているアプリケーションがどの時点のものなのかを、容易に確認できるようになります。
spec:
containers:
- name: admin
- image: registry-harbor-core.infra.svc.cluster.local/library/admin:3e5a988d908f7e726c9830d5d687673307c9f636
+ image: registry-harbor-core.infra.svc.cluster.local/library/admin:4184ce936ac3c357c9b86766e358e402ef8fe8d7
resources:
requests:
cpu: 100m
8-9. Pull & Apply manifests
マニフェストのリポジトリにマージされた後は、CDフェーズに入ります。
ArgoCDは、Kubernetesクラスタ上でコンテナとして動作しています。マニフェストリポジトリを監視しており、変更があるとクラスタの内部からKubernetesに対してマニフェストを適用するPull型のアーキテクチャを取っています。
ArgoCDなどを用いず、クラスタ外のCIツールがKubernetesクラスタに対してマニフェストを適用するPush型のアーキテクチャは、CIOpsと呼ばれています。このアーキテクチャの場合、CIツールがKubernetesクラスタに対して強い権限を持ってしまったり、複数クラスタに対する認証情報の管理が必要であったりと、セキュリティ上の問題が起きやすいため注意が必要です。
DNSの参照について
Kubernetesクラスタ上でコンテナを起動させる際には、KubernetesノードがコンテナイメージをPullできないといけません。
今回のテストベッドでは、ノード上で起動しているHarbor上に保存されているコンテナイメージ(harhor.infra.svc.cluster.local/library/admin:xxxxxなど)を参照するようにしている関係上、Kubernetesノード自体がCluster内DNSを参照できるようにしています。
そこで、Cluster内DNSのClusterIPを、DaemonSetを用いて/etc/resolv.confに書き込むように実装しています。
開発環境の整備: Telepresenceの役割
CI/CDから少し話題が逸れますが、今回は下記の2 つのOSSを用いて開発環境も整備しています。
| OSS名 | 用途 |
|---|---|
| Telepresence | リモートKubernetes上でローカルマシン上のプロセスをトンネリングして透過的に起動させる開発ツール |
| Skaffold | コードの変更時に自動的にコンテナイメージのビルドを行う開発ツール |
例えば、adminとuserのマイクロサービスがあったときに、外部からのリクエストはadminが受け、userに対してリクエストを送る構成だったとします。その場合、下記のように数珠つなぎでリクエストが伝搬される構成をとるのが一般的です。
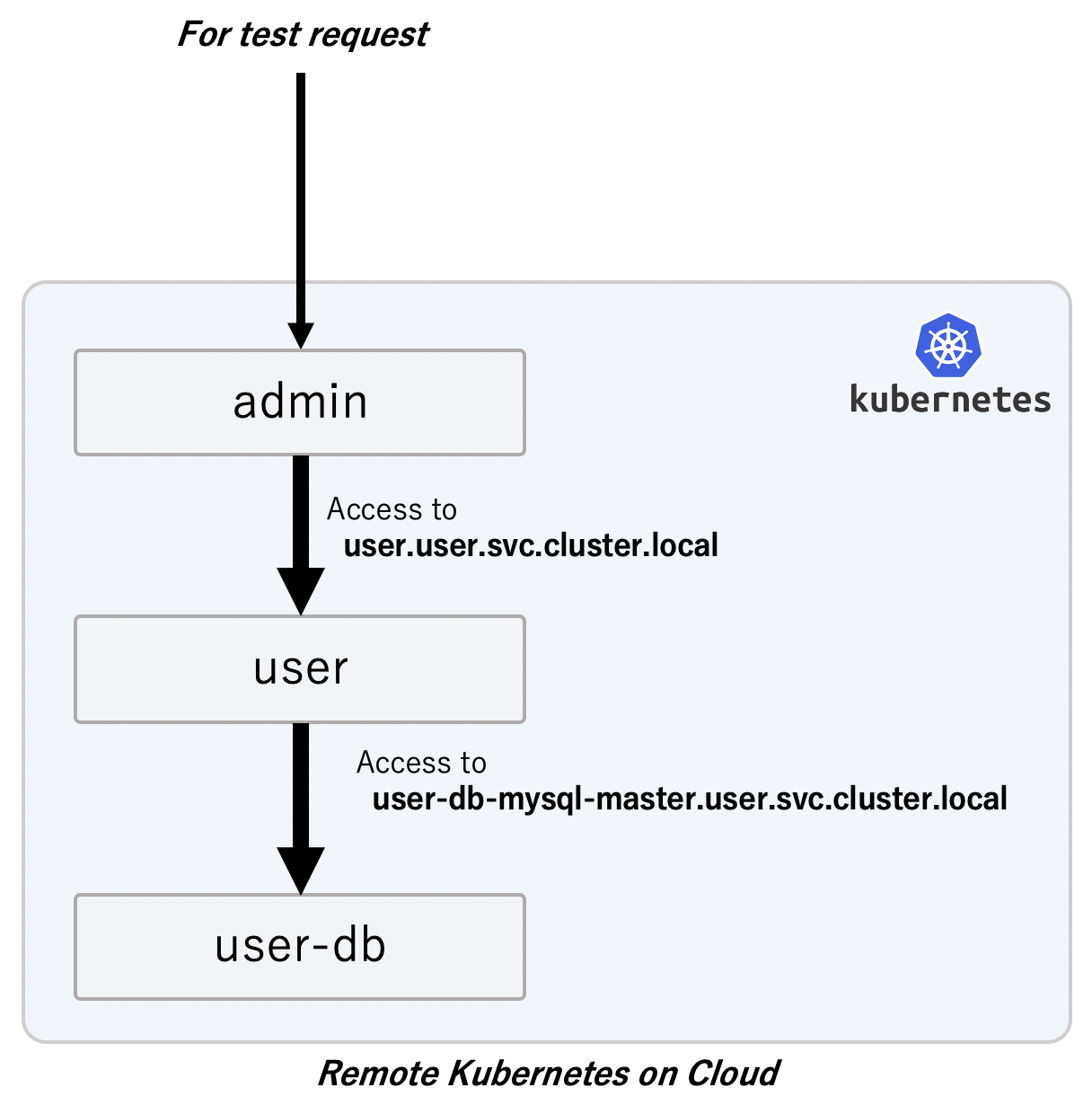
この前提があるなかでuserマイクロサービスを開発する場合、全てのマイクロサービスをローカルで動作させるのはマシンリソースの問題やデータの問題で難しい場合があります。今回のテストベッド環境もシステム全体では大量の計算資源を必要とするため、Macなどの端末上で全てを動作させることはできません。
ここで活躍するのがTelepresenceです。TelepresenceではローカルのプロセスがあたかもリモートのKubernetesクラスタのDeploymentリソースのコンテナとして存在するかのような構成を再現します。つまり、userを開発する際、リモートクラスタでadminからuserへのリクエストが送られた場合には、リモートクラスタのadminからローカルのプロセスへリクエストが転送されてきます。
また、ローカルのプロセスがuser-dbに接続しようとした際には、リモートのuser-dbに対してリクエストが送られます。TelepresenceではKubernetesのPod NetworkやService Networkに疎通性があるだけではなく、クラスタ内DNSでの名前解決も行えるようになっています。
開発環境のローカルKubernetesとSkaffold
ローカルのプロセスを立ち上げるには、docker runを実行する方法が一般的です。しかし今回はローカル側でもKubernetesクラスタを立ち上げることで、docker runの代替を行いました。この方法は既存のマニフェストを利用できるため、環境変数やSecretの設定などもそのまま流用できるといったメリットがあります。
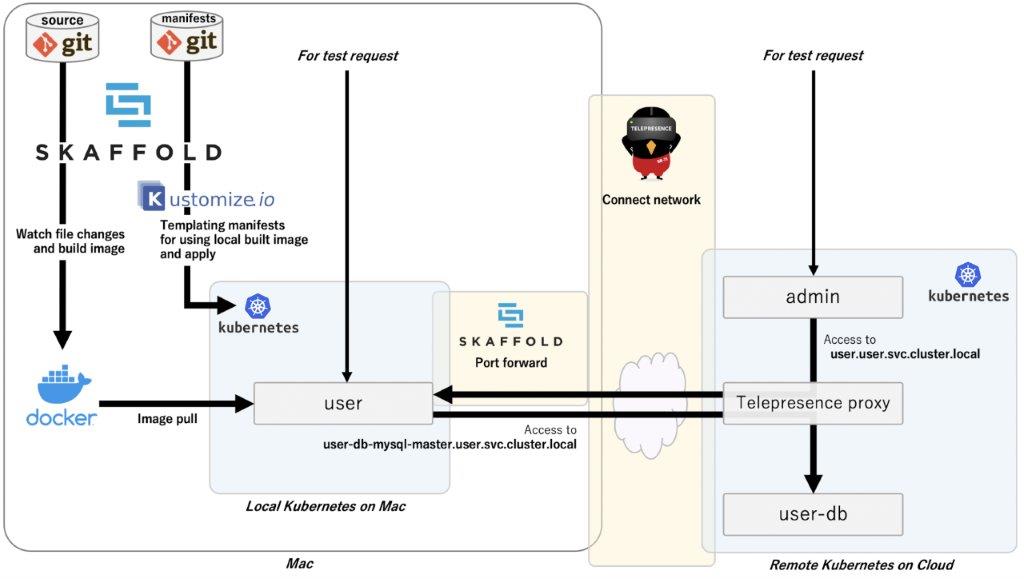
Telepresence+ローカルKubernetesで環境を構築する場合には、下記の通りいくつか考慮しなければならない点があります。
- マニフェスト適用時に、Skaffoldでkustomizeでパッチを当てる
- Skaffoldがビルドしたローカルのイメージを利用するように変更する
- ホスト側のDNS設定を利用するようにspec.dnsPolicyをDefaultに設定する
- Skaffold port-forwardを使ってホスト宛のリクエストをクラスタ内に転送されるように設定する
今回は、ローカルマシンでの開発中に生じたファイル変更をコンテナイメージのビルドやKubernetesクラスタへ反映させるためにSkaffoldを利用しているため、上記もSkaffoldの機能を使って解決することが可能です。
リポジトリに保存されているマニフェストには本番環境用のイメージが指定されているため、そのままではローカル環境での開発に適していません。そのため、Skaffoldがビルドするイメージを指定して適用するようにしています。
また、このままではローカルクラスタ上のコンテナはローカルクラスタのクラスタ内DNSを参照してしまうため、リモートクラスタのServiceに対する名前解決に失敗してしまいます。Telepresenceによってローカルのホスト側でリモートクラスタのクラスタ内DNSが利用できるようになっているため、ローカルクラスタ内のコンテナをホスト上のDNSに向けることでこの状態を解消します(spec.dnsPolicy: Default)。KubernetesのdnsPolicyのデフォルトは「ClusterFirst」であり「Default」ではないため、ローカルクラスタ内のコンテナがリモートクラスタのDNSで解決できるように明示的に設定を行っているのです。
最後に、Telepresenceはホストまでトラフィックを転送してくれますが、ローカルクラスタ内のPodまでトラフィックを転送してくれません。そのため、Skaffoldのport-forward機能を利用して疎通性を確保しています。なお、port-forwardのポート設定はServiceリソースの情報をもとに自動的に検知します。
それ以外は、開発環境でも既存のマニフェストをそのまま使えるでしょう。
クラウドネイティブ時代のステートフルなミドルウェア
今回のテストベッドでは、さまざまなKubernetes-nativeなエコシステムを採用しています。このセクションでは、そのなかでもステートフルなミドルウェアについて紹介します。一般的に、コンテナ技術はステートフルなアプリケーションには不向きとされていますが、その運用を助けるOperatorにより、今後はそういった認識が徐々に変わってくると思われます。
Operatorを使用すると、例えば「kind: MysqlCluster」リソースを作成した際に、このMysqlCluster用のStatefulSetを自動的に作成してくれます。また、データベースの障害状況に応じてServiceリソースのメンバーを入れ替えたり、自動的にバックアップを取得するなど、人間が今まで行っていたような運用を任せることができるようになります。
言い換えると、KubernetesのOperatorという仕組みは、運用ナレッジをプログラム化し、Kubernetesのライフサイクルに合わせて管理を委譲することができる機能とも言えます。
今回は、アプリケーション開発でよく利用されるデータベース、KVS、Message Queueの3つに絞って紹介します。それぞれ説明するOSSは次の通りです(上記の一覧表も参照してください)。
- データベース
- MySQL
- Vitess(CNCFのGraduatedプロジェクト)
- KVS
- Redis
- TiKV(CNCFのIncubatingプロジェクト)
- Message Queue
- NATS(CNCFのIncubatingプロジェクト)
- Apache Kafka(CNCFのSandboxプロジェクト3)
また、ステートフルなアプリケーションの根幹となるバックエンドストレージについても紹介します。
- ブロックストレージ
- Rook(CNCFのIncubatingプロジェクト)
- 共有ファイルシステム
- Rook(CNCFのIncubatingプロジェクト)
- オブジェクトストレージ
- MinIO
Kubernetes-nativeなデータベース
ステートフルなミドルウェアの代表格といえばデータベースです。一般的なWebシステムであれば、特にMySQLなどのリレーショナルデータベースが用いられることが多いのではないでしょうか。本セクションでは、MySQLベースのRDBをKubernetes上で提供するものとしてpresslabs/mysql-operatorと、Vitessについて紹介します。
presslabs/mysql-operator
MySQLを構成する際には、一般的にMaster-Slave構成などのHA構成をとり、Master障害時にはSlaveを昇格させるといった処理やLoadBalancerのメンバーを入れ替えるといった処理が必要になります。
こういった管理は、人力でやっているところもあれば、スクリプトなどを作って自動化しているところもあるでしょう。Kubernetes-nativeな方法ではOperatorが担当します。
例えばpresslabs/mysql-operatorでは、下記のようなマニフェストでMySQLクラスタを作成できます。
apiVersion: mysql.presslabs.org/v1alpha1 kind: MysqlCluster metadata: name: product-db namespace: product ...省略... spec: replicas: 2 secretName: product-db mysqlVersion: "5.7" ...省略... backupSchedule: "0 0 */2 * *" backupURL: s3://product-db/ ...省略...

presslabs/mysql-operatorでは、Master向けのServiceとMaster-Slave全体向けのServiceが作成されています。このときにMasterのPodが停止すると、Operatorが自動的にSlaveからMasterに昇格させ、ServiceのEndpointsの調整も行ってくれるようになっています。
このように、Operatorを利用することで特定のアプリケーションの管理を任せることができるため、運用負荷を減らすことが期待されています。
$ kubectl -n product get pods -o wide | grep mysql product-db-mysql-0 4/4 10.4.5.28 product-db-mysql-1 4/4 10.4.11.14 $ kubectl -n product describe service product-db-mysql-master | grep Endpoints Endpoints: 10.4.5.28:3306 $ kubectl -n product describe service product-db-mysql | grep Endpoints Endpoints: 10.4.11.14:3306,10.4.5.28:3306 $ kubectl -n product delete pods product-db-mysql-0 pod "product-db-mysql-0" deleted $ kubectl -n product describe service product-db-mysql-master | grep Endpoints Endpoints: 10.4.11.14:3306
Vitess
Vitessは、CNCFのプロダクトのひとつで、MySQLのMaster-Slave構成のペアを複数構成して、自動的にシャーディングを行うことでWriteに対してもスケーラブルにできます。アプリケーションはVTGateと呼ばれるプロキシを介してアクセスを行うことで、リクエストが適切に分散されるような構成となっています。
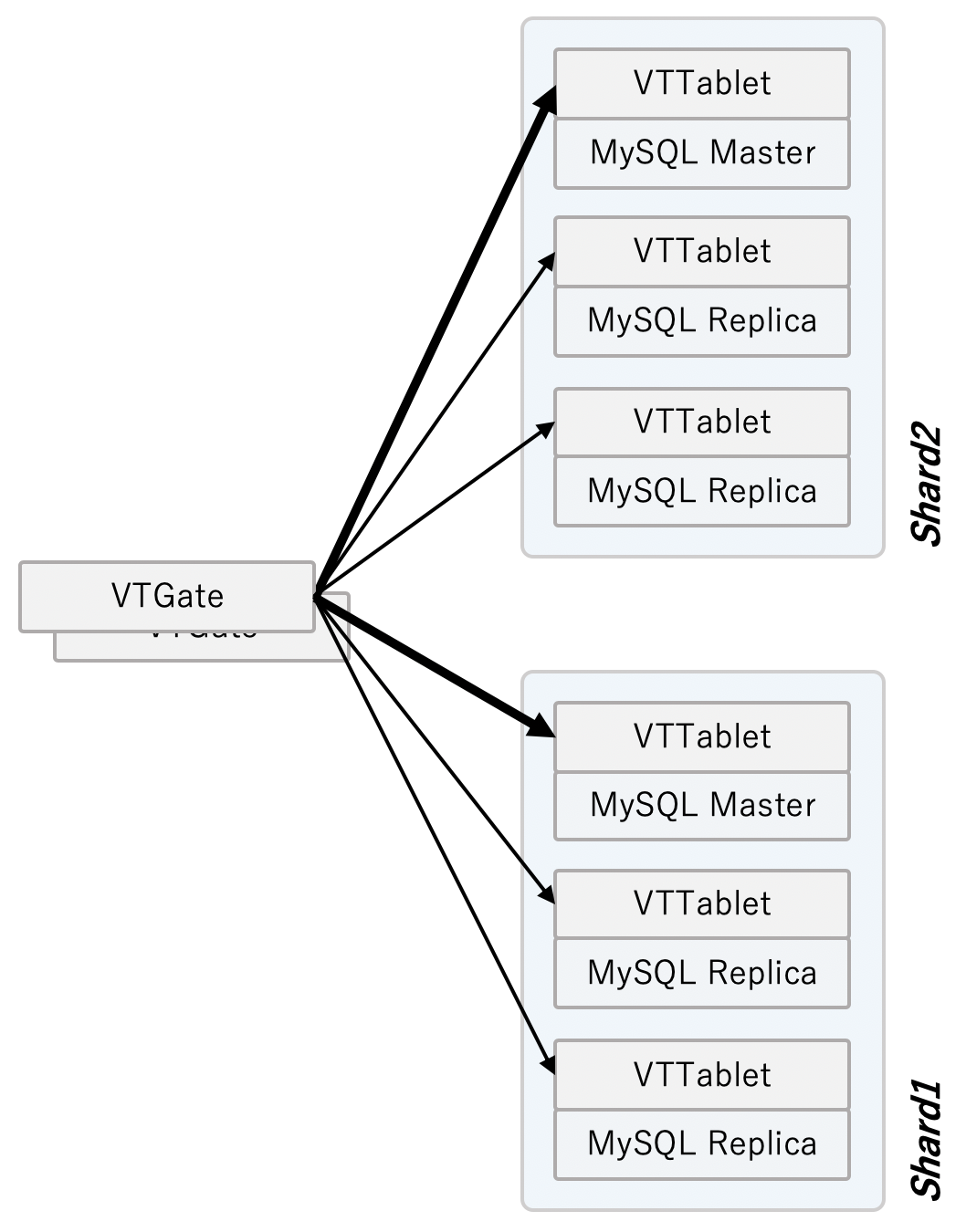
Vitess自体は、成熟したプロダクトとして、CNCFのGraduated(卒業)プロジェクトに認定されていますが、Vitessのアーキテクチャは上述の通り少し複雑なため、Kubernetes上で動作させる際はOperatorを用いたくなります。
VitessのOperatorには次の2種類が存在します。
- Vitessが提供しているもの
- Vitess as a Serviceを提供しているPlanetScale社が公開しているもの
前者は開発があまり芳しくありません。一方で、後者はPlanetScale社というVitessのSaaSを提供する開発力のある会社が開発しているため、今後が期待されます。現状で後者はまだpre-alphaステージで、OSS公開を進めている段階なので、より開発が進めば、将来的にはこのテストベッドにも組み込んでいく予定です。
Kubernetes-nativeなKVS
KVSは、構造がシンプルなデータの格納や、高速なアクセスのためのデータキャッシュなどに使われるデータベースで、アプリケーション開発において非常に重要な要素のひとつです。本セクションではその中でも、RedisとTiKVについて紹介します。
Redis
Redisは、広く使われている有名なKVSです。永続化、シャーディング、レプリケーション、メッセージングなどさまざまな機能を持っていながら、操作は非常にシンプルでなじみやすいのが特徴です。
本テストベッドではこれをKubernetes-nativeにするため、spotahome/redis-operatorというOperatorを利用します。StatefulSet上で稼働するため、標準でRedisの永続化設定が有効化されています。このOperatorはRedisの冗長化の仕組みを利用しており、非常に設計が綺麗にできています。
Redisの冗長化の仕組みには、大きく分けてReplication、Redis Cluster、Redis Sentinelの3つがあります。ReplicationはデータのMasterとなるRedisを設定し、そのデータをコピーします(厳密にはMasterがSlaveに対して値の更新をかけます)。これはデータの同期のみを保証し、可用性は担保しません。
Redis Clusterは、シャーディングと高可用性を提供する機能で、マルチマスター構成になっており、キーのハッシュに応じて保存するMasterを決定します。また、Masterが落ちると、SlaveがMasterに昇格します。
そしてRedis Sentinelは、Managed Replicationのようなもので、Sentinelという別のノードが各種Redisノードの設定を管理して、Masterの障害時にReplicationの設定を書き換えてくれます。こちらはシャーディングは行いませんが、高可用性を提供します。そしてこのOperatorでは、このRedis Sentinelを利用しています。
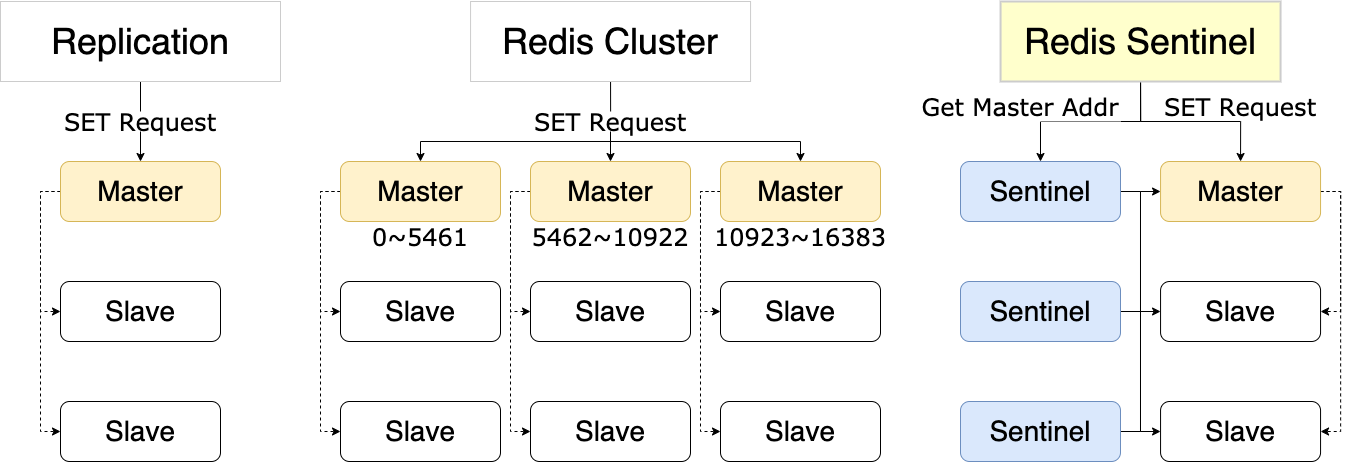
注意点として、Redis Sentinelでは各種ノードをSentinelが管理しているため、直接Masterにアクセスせず、SentinelにMasterの情報を問い合わせる必要があります。Slaveの取得についても同様です。これにより得られたエンドポイントに対してアクセスして、各種の操作を行う必要があります。
Sentinelに毎回問い合わせるとパフォーマンスに影響があるため、基本的にKeepAliveを用いてノードに接続します。Masterに障害が起きてFailoverすると自動的にコネクションが切られるため、そのときはSentinelへの問い合わせからやり直します。
TiKV
次に、TiKVについて説明します。TiKVはもともとTiDBのバックエンドデータストアとして使用されていた分散KVSで、2019年の5月にCNCFプロジェクトのSandboxからIncubatingに昇格したミドルウェアです。Incubatingプロジェクトは、とてもよくできたプロジェクトが並んでいるため、将来の期待も高まっています。
TiKVは分散KVSですので、標準でクラスタを構成します。TiKVクラスタはデータの同期とクエリを処理するTiKVと、シャーディングやTiKVノードの管理などをするPlacement Driver(PD)から構成されます。データはRegionという単位に分割され、それぞれがRaftによってノード間のデータ一貫性が保たれています。1つのノードが複数のRaftグループに属することからMulti-Raftと呼ばれています。
このように複数のRaftがある場合、クライアントはリクエストをする際に対象のキーがどのRaftグループに属するのか、そのRaftグループのLeaderのIPが何であるのかを知る必要があります。それを教えてくれるのがPDであり、Redis Sentinelに似たような役割を果たします。この仕様上、毎回PDに問い合わせる必要がありますが、ここはgRPCで問い合わせることによって、コネクションの確立によるレイテンシを小さくしようとしています。
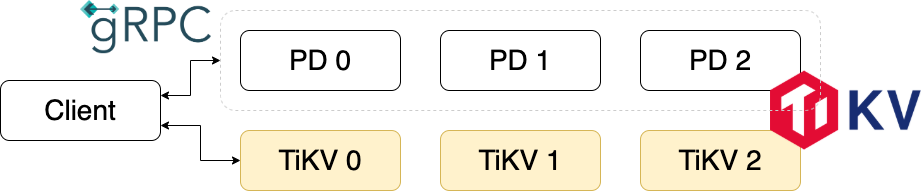
余談ですが、TiKV専用のOperatorは存在しません。その代わり、TiDB OperatorのTiDBレプリカ数を0にすることによって、TiKVのクラスタを作成できます。詳しくはこちらのマニフェストをご覧ください。
Kubernetes-nativeなMessage Queue
Message Queueはその名の通り、メッセージのキューイングを行って、サービス間の仲介をする仕組みです。これにより、システムに疎結合性をもたらすことができます。
例えば、サービス間で直接通信をしないことによって、リクエストを受ける側のサービスが捌ききれなくなってしまったときも、送る側がタイムアウト待ちからのコネクション溢れで落ちるといったことがなくなります。また、開発時もどのトピックに流すかということだけ決めておけば、送る先のAPIを理解せずとも実装を進めることができます。
NATS
このひとつとして、クラウドネイティブ界隈ではNATSが有名です。Kubernetesやインフラ監視ツールPrometheusのインテグレーションが充実しており、CNCFでもIncubatingプロジェクトに入っています。
NATSは、メッセージ配信として「At Most Once」と「At Least Once」の機能を備えていますが、本テストベッドで使用しているNATS Serverは、前者のAt Most Onceになります。つまり、メッセージの受け取り手がいなかったりすると、メッセージは消失します。
後者はNATS Streaming Serverを利用すると実現できるようになります。NATS Streaming Serverは永続化もサポートしているため、将来的にそちらのOperatorを使用したいと思っています。
NATS Serverの環境は、Operatorであるnats-io/nats-operatorを使うことで、簡単に用意できます。認証も非常に簡単に設定することができ、下記のようにServiceAccountに紐付けたりすることが可能です。認証用の設定ファイルを作ることも可能で、別の名前空間(namespace)からアクセスする際はこちらの方法が使えます。
apiVersion: nats.io/v1alpha2 kind: NatsCluster metadata: name: delivery-status-queue spec: size: 3 version: "1.2.0" pod: enableConfigReload: true auth: enableServiceAccounts: true --- apiVersion: v1 kind: ServiceAccount metadata: name: nats-admin-user --- apiVersion: nats.io/v1alpha2 kind: NatsServiceRole metadata: name: nats-admin-user labels: nats_cluster: delivery-status-queue spec: permissions: publish: [">"] subscribe: [">"]
NATSにおけるメッセージングの種類は、「Pub-Sub」「Request-Reply」「Queue Group」の3つがあります。
Queue Groupは送られたメッセージをSubscribeしているいずれかのクライアントに送るというもので、メッセージをWorkerのどれか1つで処理するようなモデルとは相性がよいです。Conn.ChanQueueSubscribe()という関数でQueue GroupとしてSubscribeでき、メッセージはGoの機能であるChannelを介して送られてきます。
msgCh := make(chan *nats.Msg, 64) // Subscribe: msgCh 経由でメッセージを受け取るようにする sub, _ := conn.ChanQueueSubscribe(oq.subject, "delivery-status-group", msgCh) defer sub.Unsubscribe() msg := <-msgCh // さまざまな処理
他の種類については、公式の図を確認してみてください。
Apache Kafka
Message QueueといえばKafkaもあります。このOperatorとしてstrimzi/strimzi-kafka-operatorがあるのですが、こちらもCNCFプロジェクトのSandboxに入っています。ミドルウェア本体ではなくOperatorが入ることはけっこう意外ですが、従来のミドルウェアをKubernetes-nativeにするミドルウェアと考えると、自然な気もします。
Kafkaにおいて、Topicに入れられたデータたち(Partition)は永続化されますが、Operatorでも同様に永続化されます。設定としては、storageフィールドのtypeにjbodを指定して、PVC(PersistentVolumeClaim)用の情報を渡すだけで完了します。揮発性(ephemeral)ストレージも指定できますが、当然ながら復旧したStatefulSetがデータを復元できるとは限らないため、PVCを設定した方がよいでしょう。
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: point-queue spec: kafka: version: 2.4.0 replicas: 3 listeners: plain: {} tls: {} config: offsets.topic.replication.factor: 1 transaction.state.log.replication.factor: 1 transaction.state.log.min.isr: 1 log.message.format.version: "2.4" storage: type: jbod volumes: - id: 0 type: persistent-claim size: 10Gi deleteClaim: false class: rook-ceph-block

このOperatorを使っていてよいと感じた点は、TopicをCRDで管理しているところです。このように明示的にリソースを宣言することで、そのMessage Queueがどのようなキューを持っているのかが明確になるところが「Kubernetes-nativeらしいな」という気持ちになりました。
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaTopic metadata: name: point-topic labels: strimzi.io/cluster: point-queue spec: partitions: 1 replicas: 1

Kubernetes-nativeなStorage
Kubernetes上で提供するブロックストレージ、共有ファイルシステム、オブジェクトストレージについて紹介します。
Rook: ブロックストレージ、共有ファイルシステム
ブロックストレージをKubernetes上で提供するソフトウェアとしては、CNCFがホストしているRookをはじめとして、Rancher Labs社が開発しているLonghornや、StorageOSなどがあります。このテストベッドでは、Rookを利用しています。
Rookは、Cephを管理するものだと捉えられがちですが、もともと多種多様なストレージを管理するために作られたプロジェクトであるため、Ceph以外にもさまざまなストレージプロバイダが利用可能です。このテストベッドでは王道構成であるRook Cephを用いています。
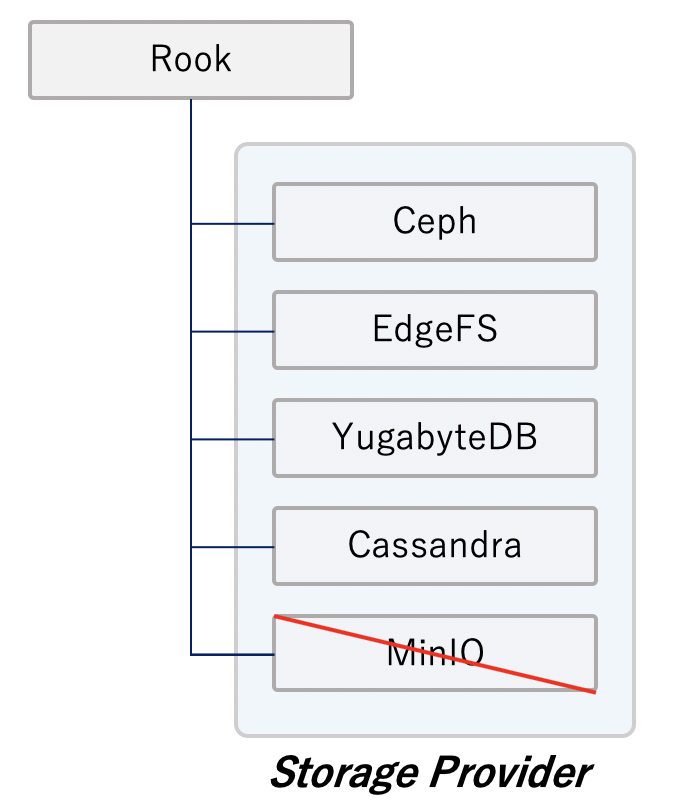
RookではCephクラスタを管理することができ、Cephクラスタからプールを払い出してブロックストレージをStorageClass経由で提供するところも、Kubernetesのマニフェストで管理することが可能です。
実は、Rook Cephでは、ブロックストレージだけではなく共有ファイルシステムも提供可能になっています。
プロダクション構成では、Cephクラスタが動作するノードはTaintsなどを用いて専用ノードにした方が安定しそうですが、今回は実際のワークロードのコンテナと混在させたハイパーコンバージド構成にしています。
MinIO: オブジェクトストレージ
最後に、オブジェクトストレージでは、MinIOを利用しています。かつて、Rookが提供していたMinIO用のOperatorがあったのですが、すでに廃止されています。現在推奨されているのは、MinIO公式が提供しているminio-operatorです。今回はそちらを利用しました。
MinIOは、S3互換のAPIを持っているため、AWS CLIからMinIOのファイルをやり取りすることが可能です。今回は、productマイクロサービスで商品画像を保管する部分でもMinIOを利用している他、mysql-operatorがデータベースをバックアップする際に利用する保存先としても利用しています。
次世代の標準 フルgRPC通信なモダンなアプリケーション
最後にgRPCを用いたサーバー・クライアント通信について説明します。gRPCはHTTP2上でRPC通信を行うプロトコルです。IDLを用いてAPI仕様の記述ができるため、送信・受信するメッセージの形式が明確になり、サーバー・クライアントの実装がしやすくなるという利点があります。
テストベッド環境では、ブラウザのUI画面を含め、全てのマイクロサービスがgRPCでやりとりをしています。gRPCの実装に関しては詳しい記事がWeb上にたくさんあるため、このセクションでは、ブラウザからgRPC通信を行うgRPC Webと、認証・認可の仕組みに重点をおいて述べていきます。
gRPC Web
gRPC Webは、名前の通りWeb上でgRPCリクエストを発行するプロトコルで、gRPCとは別のものです。ここで「どういうことだ?」と疑問を持たれる方もいるかもしれません。なぜなら、gRPCはHTTP/2上のプロトコルであるため、理論的にはブラウザでも同様にgRPCを使えるはずだからです。しかしながら、gRPC通信をする上で使用されている一部の機能がブラウザ側に実装されていないため、こういった別のプロトコルが定義されています。
さて、これを用いてサーバーと通信するわけですが、そもそもサーバーはgRPCしか受け付けていないため、下記のようにどこかでリクエストを変換するプロキシを挟む必要があります。このプロキシによって、ブラウザ・プロキシ間はgRPC Webで通信が行われ、プロキシ・サーバー間でgRPC通信が行われるようになります。
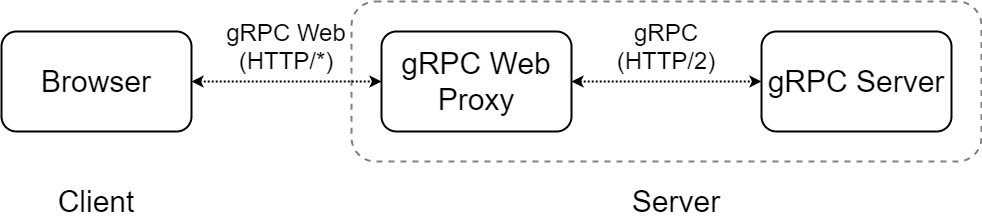
こうした記述を読むと、従来のようにREST APIをgRPCに変換するサーバーが必要なのかと思われるかもしれませんが、gRPC Webでは自前でプロキシを実装する必要がないため、負担が相当に軽減されています。また、gRPCに近い形で仕様が策定されているため、プロトコル変換のオーバーヘッドも非常に小さいです。
このgRPC Web Proxyには、Envoyを利用します。EnvoyにはgRPC WebとgRPCを相互変換する機能(envoy.grpc_web)があるため、それを使います。これはHTTPフィルタという動的にリクエストを細工する機能の一部です。
本テストベッドでは素のEnvoyではなく、そのOperator(Ingressコントローラのようなもの)であるContourを採用しているのですが、実は前述のフィルタはデフォルトで有効になっているので、Contourの設定は特にせずとも動きます。
Kubernetes側が行うべき設定としては、ContourがバックエンドサーバーにHTTP/2で流すようにするため、Serviceに対して次のAnnotationを追加してあげる必要があります。
projectcontour.io/upstream-protocol.h2c: 'PORT_NUM'
これにより、EnvoyのCluster設定セクションにhttp2_protocol_optionsが追加されます。ちなみにサーバー内通信は暗号化していないので「h2c」としていますが、暗号化している場合は「h2」と指定してください。
apiVersion: v1 kind: Service metadata: name: product namespace: product annotations: contour.heptio.com/upstream-protocol.h2c: "8080" spec: type: ClusterIP ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 8080 selector: service: product role: app
ContourによるエンドポイントのDelegation
gRPC Webのクライアント実装に入る前に、リクエストを受け付けるエンドポイントの設定に触れようと思います。基本的にマイクロサービスの開発では、不慮の事故を避けるため、自分の名前空間(namespace)以外のリソースはできるだけ触らないことが望ましいでしょう。
よく使われる方法は、IngressとServiceのExternalNameを使用して、名前空間越しにリクエストを投げるというものです。本テストベッドで使用しているContourのHTTPProxyリソース(Ingressリソースのようなもの)では、より簡単にそれを実現できます。
下記マニフェストは、infraのnamespaceにいる中枢のHTTPProxyから/productというパスでアクセスが来た際に、productのnamespaceにいるHTTPProxyの設定を参照するということを実現する例になります。当然ですが、この中枢となるHTTPProxyはブラウザ・プロキシ間の通信を担うため、TLSの設定が推奨されます。また、ブラウザ仕様でInsecureな通信が弾かれてしまったりするため、設定したほうがトラブルがありません。
apiVersion: projectcontour.io/v1 kind: HTTPProxy metadata: name: namespace-delegation-root namespace: infra spec: virtualhost: fqdn: testbed.example.com tls: secretName: testbed-cert includes: - name: product namespace: product conditions: - prefix: /product routes: - services: - name: default-http-backend port: 8080 --- apiVersion: projectcontour.io/v1 kind: HTTPProxy metadata: name: product namespace: product spec: routes: - services: - name: product port: 8080 conditions: - prefix: /product pathRewritePolicy: replacePrefix: - replacement: /product
本環境ではcert-managerを利用して、証明書を動的に更新するようにしています。詳しくはこちらのマニフェストを参考にしてください。
gRPC Webのクライアント実装
インフラ周りが整ったところで、クライアントを実装していきます。まずgRPC Webリクエストを発行するため、Protobuf定義から専用のコードを生成する必要があります。前準備として、gRPC Web用のジェネレーター(protoc-gen-grpc-web)をインストールし、いつものようにprotocを使って生成します。
protoc-gen-grpc-webのインストールについては公式ドキュメントを参照してください。コード生成は複数のジェネレーターを使って同時に行うことができるため、開発時は以下のように実行していました。
protoc ./protobuf/sample.proto \ -I ./protobuf \ --go_out=plugins=grpc:./path/to/server_dir \ --js_out=import_style=commonjs:./path/to/client_dir \ --grpc-web_out=import_style=commonjs,mode=grpcwebtext:./path/to/client_dir
Goのコードはそのマイクロサービスのディレクトリへ、JavaScriptとそのgRPC Web用のコードはクライアントのディレクトリへ出力しています。gRPC Webの生成コードはこのようになっています。
これでクライアント実装の準備が整ったので、基本的なgRPC Webリクエストの実装方法を見てみましょう。下記のコードはVue.jsを用いた実装で、Cartマイクロサービスを例にしています。
const {ShowRequest, ShowResponse, Cart} = require('./protobuf/cart_pb.js'); const {CartAPIClient} = require('./protobuf/cart_grpc_web_pb.js'); export const cart = new Vue({ el: '#cart', data: { endpoint: window.location.protocol + '//' + window.location.host + "/cart", form: { userUUID: '', cartProducts: [], }, }, created: function() { this.client = new CartAPIClient(this.endpoint); }, methods: { showCart: function() { const req = new ShowRequest(); req.setUseruuid(this.form.userUUID); this.client.show(req, {}, (err, resp) => { if (err) { console.log(err); } else { console.log(resp); } }); } } });
ここで大切な点は、次の4つです。
- 1行目: リクエスト・レスポンス・構造体の定義をrequireする
- JavaScriptジェネレーターによって生成されたコード
- 2行目: gRPC Webリクエストを送るためクライアント定義をrequireする
- gRPC Webジェネレーターによって生成されたコード
- 14行目: gRPC Webクライアントのインスタンスを作成
- 20行目: リクエストを構築して、gRPC Webクライアントの関数を呼び出す
これだけでgRPC Webリクエストを送ることができます。後は、返ってきたレスポンスのフィールドを参照して、好きなように処理を記述できます。
以上でだいたいのニーズに応えられると思いますが、もしかしたら1つのアクションの中で複数のリクエストを送信したいということがあるかもしれません。ここで呼び出したgRPC Webクライアントはリクエストを非同期で行うため、1つ前のリクエストの結果を使って次のリクエストをしたい場合は、Promiseを使用して結果を待機する必要があります。
JavaScriptに慣れている人はサッと実装できてしまうかもしれませんが、実はPromiseインスタンスを作るコードはすでに用意されています。それがPromiseClientです。このクライアントはリクエストを発行するPromiseを返してくれるため、私たちはそれをasync関数内で、awaitを用いて待ってあげるだけでよいのです。
// ...省略... const {CartAPIClient, CartAPIPromiseClient} = require('./protobuf/cart_grpc_web_pb.js'); // ...省略... commitCart: async function() { const req = new CommitRequest(); // ...省略... // other request const sreq = new ShowRequest(); sreq.setUseruuid(this.commitform.userUUID); const resp = await this.promiseClient.show(sreq, {}); const cartProducts = resp.getCart().getCartproductsMap(); // ...省略... this.client.commit(req, {}, (err, resp) => { if (err) { console.log(err); } else { console.log(resp); } }); } // ...省略...
JWTを用いたリクエストの認証・認可
最後に、我々はセキュリティのため、ユーザーの認証・認可を行わなければなりません。認証はユーザー・パスワードの組み合わせで行っており自明なため、このセクションではgRPCリクエストをJSON Web Tokens(JWT)を用いて認可する方法について説明します。
JWTとは、JSONオブジェクトをサーバー・クライアント間で安全に送信できる仕組みです。JSONオブジェクトは、base64エンコードされた後、トークンを発行するサーバーによって署名され、トークン検証時にそれが不正に書き換えられていないかを確かめることができます。そのため、認可のためのトークンとして広く使われています。署名には鍵が必要であり、これにはHMACといった暗号化方式や、RSAやECDSAといった公開鍵暗号を使用できます。
今回は、ECDSAの521-bitで鍵を作成してみましょう。作成した鍵はプログラムが読めるように、SecretなどでKubernetes上に保存して渡してあげます。テストベッドではそのままGitHubに上げていますが、この秘密鍵は絶対に漏れてはいけないものですので、自身のプロダクトで同じようなことをする場合は、必ずkubesecなどで暗号化したりしてください(これが漏れてしまうと署名済みトークンを作り放題になってしまいます)。
openssl ecparam -name secp521r1 -genkey -noout -out id_ecdsa_521 openssl ec -in id_ecdsa_521 -pubout -out id_ecdsa_521.pub
まずトークンを発行する方法について、下記のGoのソースコードをもとに説明していきます。このコードでは、JWTのライブラリとしてdgrijalva/jwt-goを使用しています。
// server impl token := jwt.New(jwt.SigningMethodES512) claims := token.Claims.(jwt.MapClaims) claims["role"] = role claims["exp"] = time.Now().Add(time.Hour * 24).Unix() signKey, _ := jwt.ParseECPrivateKeyFromPEM([]byte(privateKey)) tokenString, _ := token.SignedString(signKey)
流れとしては、使用する暗号鍵の種類を指定して、トークンのClaim(これがクライアントへ渡したいデータになります)にデータを設定した後、あらかじめ用意しておいた鍵をパースして、署名生成に使用します。これだけでトークンの生成は完了です。Claimにはユーザーの役割を識別するための情報と、有効期限を設定しています。
クライアントは、上記のような処理を行う認証エンドポイントを叩いた後、そのトークンを受け取ってCookieに保存します。以降は、その値を参照してgRPC Webリクエストヘッダーにその情報入れてリクエストを発行します。
function GetTokenMetadata() {
const token = GetTokenFromCookie(); // Cookie から Token を取り出す自作関数
return {'x-testbed-token': token};
}
// omitted
this.client.show(req, GetTokenMetadata(), (err, resp) => { ... });
ヘッダー名は、x-testbed-tokenとしましょう。HTTPのヘッダー名は基本的に大文字小文字を区別しないため、予期しないバグを防ぐためにも小文字で統一しておくとよいかもしれません。このリクエストヘッダーの値は、リクエストを発行する関数の第2引数に設定することが可能です。
最後に、トークンを検証する方法について説明します。クライアントによって設定されたリクエストヘッダーはContext内に保存されており、google.golang.org/grpc/metadataパッケージのFromIncomingContext()を使うと簡単にその値を取得できます。
import ( "google.golang.org/grpc/metadata" ) func VerifyToken(ctx context.Context, publicKey string) error { header, _ := metadata.FromIncomingContext(ctx) tokenStr := header[tokenHeaderName][0] type RoleClaims struct { Role string `json:"role"` jwt.StandardClaims } token, _ := jwt.ParseWithClaims(tokenStr, &RoleClaims{}, func(t *jwt.Token) (interface{}, error) { verifyKey, _ := jwt.ParseECPublicKeyFromPEM([]byte(publicKey)) return verifyKey, nil }) if claims, ok := token.Claims.(*RoleClaims); ok && token.Valid { return nil } else { return fmt.Errorf("token is not valid") } }
次に、Claimのデータ構造を定義しています。基本的に書かなければいけないのはユーザー定義のClaim名であり、有効期限として入れたexpフィールドは予約済みのClaim名となっているため、jwt.StandardClaimsという構造体を埋め込むだけで定義できます。そして受け取ったトークンをパースして、Validならそのトークンは改ざんされていない正しいトークンであると判断できます。
パースに使用しているParseWithClaims()の第3引数は、検証用の鍵を取得するための関数が定義できます。この関数には未検証のパース済みトークンが渡ってくるため、例えば複数の暗号化方式を使用している場合には、ここでトークンのヘッダーを参照することによって、適切な検証鍵を返すといった実装も可能になります。
この例ではユーザーの役割(Role)を入れただけで特に何もしていませんが、その情報に対してどんな操作を許可するかなどを組み込むと、より認可らしさが出ると思います。以上により、認証・認可を実現することができました。
最後に ─ クラウドネイティブを実現するひとつの答え
このテストベッドでは、Kubernetes-nativeなエコシステムを中心的に利用しつつ、次の3点を紹介しました。
- アプリケーションの開発後に即座に安定してリリースできるCI/CDと開発環境
- 自動管理されたステートフルなミドルウェア
- フルgRPCでハイパフォーマンスなサービス間通信
こういった機能を利用することで、私たちは最小限の労力でサービスを作り出し、新しい機能を安定的に提供し続けることができます。これこそが、クラウドネイティブを実現するためのひとつの答えなのではないでしょうか。
現時点では一部発展途上な部分もありますが、今後はクラウドネイティブが一般的になる世界が来ることでしょう。ぜひ皆さんも体験してみてください。
※クラウドネイティブな時代では、アプリケーションだけでなくそれを支える基板側も適切にアップデートされていかなければなりません。そのため、このテストベッドで利用されているOSSは時流の流れとともに別のクラウドネイティブなプロダクトに置き換えられていく予定です。また、そうした提案やコントリビューションもお待ちしております。
※このプロジェクトはほとんどが真面目に設計を行いましたが、さまざまなKubernetes-nativeなデータストアを利用するために技術選定を行うMiddleware-driven Development(MDD)な部分がいくつかあります。ワークロード特性に合致したデータストアを選べているわけではないため、その点はご了承ください :)
※この記事は2020年4月9日時点の情報をもとに記載しています。テストベッド環境も進化をし続けているため、最新の状態はdevelopブランチの状態を確認してください。
青山 真也(あおやま・まさや) 


2016年新卒入社。GKE互換なコンテナ基盤をゼロから構築。Kubernetes・クラウドネイティブ領域のCyberAgentのDeveloper Expertsとしても従事。国内カンファレンスでのKeynoteや海外カンファレンス等、登壇経験多数。世界で2番目にKubernetesの認定資格を取得。著書に『Kubernetes完全ガイド』等。現在はOSSへのContribute活動をはじめ、Cloud Native Days TokyoのCo-chair、CNCF公認のCloud Native Meetup TokyoやKubernetes Meetup TokyoのOrganizerなどコミュニティ活動にも従事。



2018年サイバーエージェントに新卒入社。普段はOpenStackやKubernetesなどのインフラ基盤運用。最近は自社開発のKubernetes基盤のためのCluster Autoscalerを実装したり、機械学習を用いてメトリクスを予測するためにHPAの機能拡張などを行っている。タイピングが好き。
編集:中薗 昴




