
gRPCでインターフェースを再整理してからサービスを分割─freeeの段階的なマイクロサービス戦略
マイクロサービスの導入事例を、中の人に聞いてみいます。本稿では、SaaS型クラウドサービスを提供するfreee株式会社CTOの横路隆さんに、マイクロサービス導入前のシステムが抱えていた課題、そしていかにして既存のシステムをマイクロサービスに置き換えていくか、といった戦略を語っていただきました。
- 課題:リポジトリの肥大化に伴ってリリース頻度が低下
- 戦略1:サービスを切り出す前にインターフェースを再整理
- 戦略2:サービスは分離してもデータベースは分離しない
- 戦略3:仕様を変えてでも分離しやすいデータ構造を作り出す
- 戦略4:コンテナやKubernetesでデプロイフローを標準化
- まとめ:変化に強くなることがマイクロサービス化の本質
サービスを構成するシステムを分散・細分化するマイクロサービスアーキテクチャ。この手法を導入する企業は、徐々に増えています。しかし、マイクロサービス化のためのベストプラクティスを見出すのは難しいでしょう。どの企業も手探りの状態で、アーキテクチャ改善の取り組みをしているのが現状です。
そんな中で、巨大なサービスを持つ有名IT企業は、どうやってマイクロサービス化を推進しているのでしょうか。今回は「会計freee」や「人事労務freee」など、中小企業をはじめとした法人・個人事業主向けのSaaS型クラウドサービスを提供するfreee株式会社の事例を取り上げます。
話し手は、同社のCTOである横路隆さん。聞き手を務めるのは、株式会社ウルフチーフの代表取締役であり、アーキテクチャ設計のスペシャリストでもある川島義隆さんです。多数のプロダクトを持つfreeeが選んだ、マイクロサービス化の手法に迫ります。



freee株式会社共同創業者CTO。慶應義塾大学大学院理工学研究科修了。学生時代にインターンでエンタープライズ向けWebアプリの開発を経験。新卒で入社したソニーを経て、2012年7月に元Googleの佐々木大輔とCFO株式会社(現・freee株式会社)を共同創業。好きなプログラミング言語はRuby、JavaScript、Scala、Haskell。趣味はピアノ・オルガン・シンセサイザーなどキーボード演奏。
川島 義隆(かわしま・よしたか) 

株式会社ウルフチーフ 代表取締役。TIS株式会社にて19年半、さまざまな業種のシステムアーキテクチャ設計を担当し、2018年に退職、株式会社ウルフチーフを創業する。以降流しのアーキテクトとして、前職時代から書き溜めていたOSSプロダクトや技術記事を元に、様々な現場でアーキテクチャの設計や研修を実施している。
課題:リポジトリの肥大化に伴ってリリース頻度が低下
川島 freeeではどのような課題を解決するためにマイクロサービス化を検討されたのでしょうか?
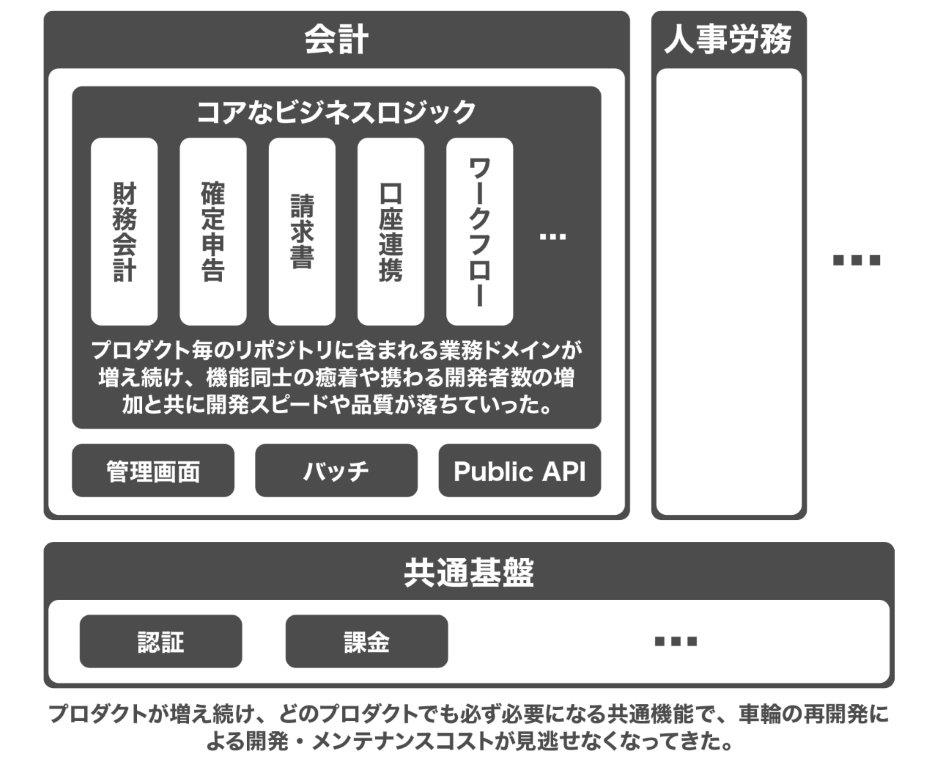
横路 freeeのプロダクトの成り立ちからお話しすると、「会計freee」の最初のリリースが2013年で、翌年に「人事労務freee(当時の名称は給与計算freee)」をリリースしました。その段階で既に、各プロダクトや認証・認可を扱うサービス基盤などは、リポジトリやサービスを分割する形で開発・運用を行っていたんです。
しかし、プロダクトがマーケットフィットして成長していく過程で、一つひとつのリポジトリが徐々に肥大化してきました。なぜなら、会計や人事労務に関連する新機能については、別のリポジトリに切り出すのではなく、開発スピードを優先して会計・人事労務それぞれのリポジトリで実装するケースが多かったためです。
そうした運用を続けるうち、2016年ごろから徐々にリリース頻度の低下が課題になってきました。
さまざまな機能が会計・人事労務のリポジトリに含まれているため、「一回あたりのリリースに含まれるコミット数が多く、何かの不具合があると全ての機能がリリースできない」「開発前の影響範囲調査に時間がかかる」といった課題が生じてきたんです。
川島 その状態ですと、関係のない箇所の修正が重要な機能にまで影響を与えてしまうことがありますから、大変ですよね。そうした課題を解決する手段の1つが、マイクロサービス化だったのですね。
横路 そうです。freeeのマイクロサービス施策には、2つの目的がありました。1つは、今お話ししたような障害発生のリスクや影響範囲調査のコストを低減し、開発のスピードとプロダクトの品質を向上させることです。
もう1つは、複数のプロダクトで横断的に使われるような機能をマイクロサービス化することで、機能の横展開を容易にすることです。
freeeは今後、統合型クラウドERPとして多種多様なプロダクトのリリースを加速していく予定のため、全てのプロダクトで共通的に使われる機能が出てきます。そうした機能は、マイクロサービスとして切り出すことで再利用を容易にした方がいい。つまり、プロダクト戦略とマイクロサービスとの親和性が高かったということです。
川島 freeeのプロダクトにはさまざまな機能があるかと思いますが、どのような基準でマイクロサービス化の優先順位を付けたのでしょうか?
横路 優先度を決めるにはいくつかの観点がありました。まず、マイクロサービス化により生産性や再利用性が向上する機能であること。これは、前述の「課題を解決する」という意味で重要です。
そして、売り方や作り方も含めて、プロダクトの成長戦略に沿っていること。マイクロサービスの利点の1つとして、事業として今後伸ばしていきたい機能をサービスとして独立させることで、高速にイテレーションを回せるという側面があります。つまり、「事業として何を磨いていきたいか?」をベースにマイクロサービス化すべき機能を検討していく方法です。
さらに、データが万が一漏洩した場合に大きな危険性がある機能を分離しておくという観点もあります。例えば、個人情報を扱う機能の安全性を高めるため、関係するソースコードのみをマイクロサービスとして切り出すという方針も考えられます。
それから、データの結合度です。当然ながら、双方向のデータ依存がある機能はサービスとして切り離しづらく、単方向にのみデータ依存している機能の方が切り離しは容易です。こうした観点に基づき、マイクロサービス化すべき機能の優先順位を付けていきました。
戦略1:サービスを切り出す前にインターフェースを再整理
川島 優先順位を検討した結果、まずどのような機能をマイクロサービスとして切り出したのでしょうか?
横路 最初に切り出したのは、申請や承認におけるワークフローを管理するための機能です。もともと、この機能は「会計freee」だけに実装されていましたが、他のプロダクトにおいても汎用的に使われることが予想されたため、マイクロサービス化する方がいいと判断しました。
川島 どのような流れで、マイクロサービス化を進めていきましたか?
横路 ワークフロー機能はもともと「会計freee」との結合度が高かったため、会計を担当しているエンジニア数名でプロジェクトチームを構成し、移行計画の壁打ち相手としてfreeeのアーキテクトチームのメンバーにも参画してもらいました。
川島 チーム編成の後は、どのような作業を行いましたか?
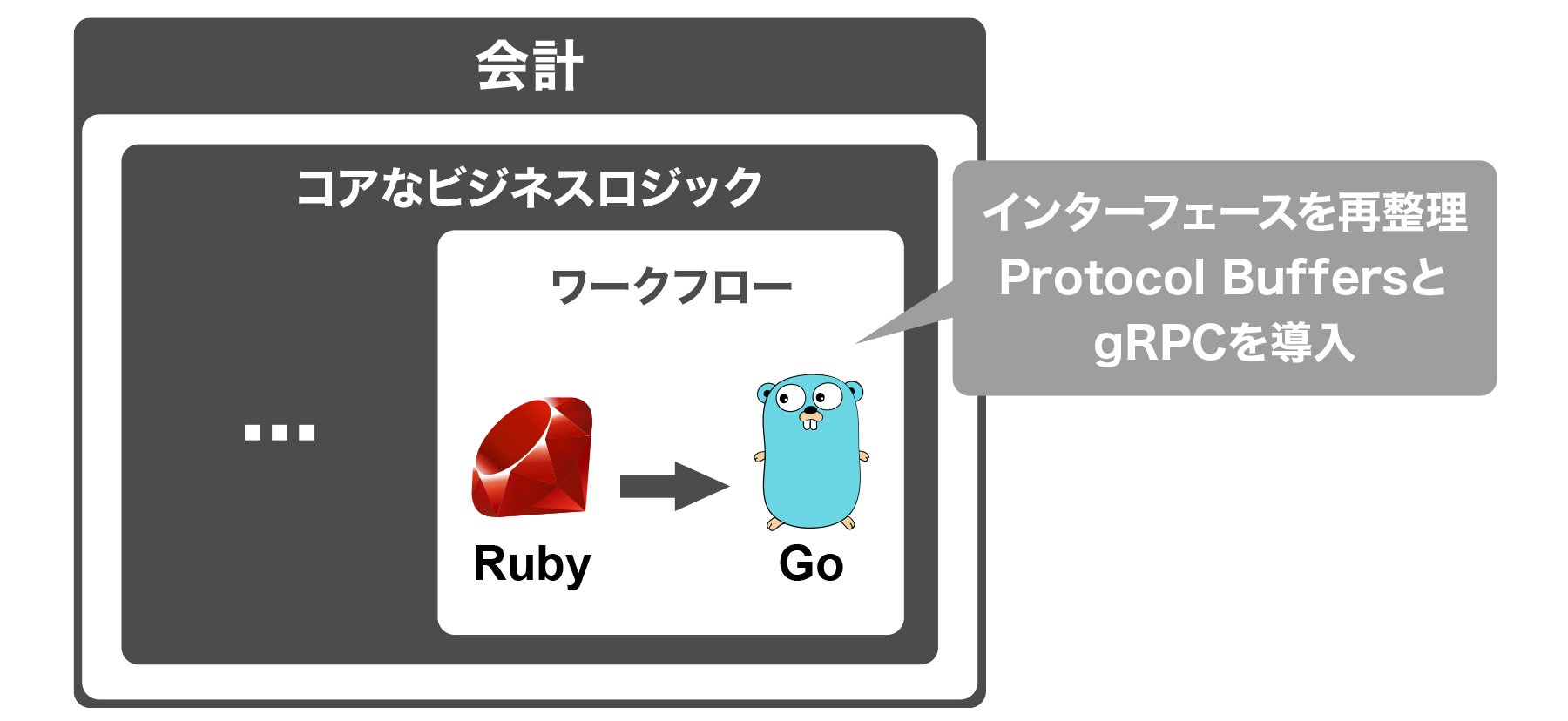
横路 最初に実施したのは、インターフェースの再整理です。なぜなら、会計freeeでは動的型付け言語であるRubyを採用していることもあり、各種APIにおいて入出力のパラメーターの型が不明瞭になっているものがあったため、そのインターフェースを明確にした上で、サービスの分割手段を検討すべきだと考えました。
型が不明瞭というのは、例えば「最初にAPIを開発したエンジニアは数値型を意図していたはずなのに、文字列型でもコードが動く状態になっている」ようなケースです。しかも、続いて「なぜか文字列型を正として機能追加されている」などの事態が発生していました。
インターフェースを整理するタイミングで、Protocol Buffers†とgRPCを導入しました。これにより、「モノリシックなアプリケーションだが、モジュール境界はgRPCでやり取りしている」という状態をまず構築しています。
あるべき型をリバースエンジニアリングしながらProtocol Buffersでインターフェースを定義する作業は手間がかかりましたが、この工程を経ることでAPIの全体仕様が明確になり、後続のマイクロサービス化の作業が格段に楽になりました。このときに併せて、Ruby on Railsで書かれた既存のコードベースをGoで書き直していく作業も実施しています。
† Protocol Buffersでは、インターフェース定義言語(Interface Definition Language)を用いてAPIの期待する入力・出力形式を記述するため、型の定義が明確になるという特徴がある。
戦略2:サービスは分離してもデータベースは分離しない
川島 Go言語は、gRPCとの親和性という意図から選ばれたのでしょうか?
横路 別の意図での採用でしたね。メモリフットプリントを削減しやすいことや、スループットに優れる点、goroutineによる並行処理の容易さなどが、Goを採用した理由です。
川島 インターフェースの再整理やgRPCの導入、さらにはRubyからGoへの書き換えを行うとなると、コードの修正量も大きかったと思います。新・旧コードの動作が同一であることを、どのように保証されましたか?
横路 旧ロジックと新ロジックの挙動を実データを使って自動的に確認できるツールを作り、再帰的なテストを行いました。そうすることで、アプリケーションの挙動の同一性を担保しています。
さらに、いきなりデータベースレイヤーを分離するのではなく、まずはアプリケーションレイヤーのみを分離しました。「サービスは分離しているが、データベースは分離していない」というフェーズを挟むことで、切り戻しが容易な状態を保ったんです。
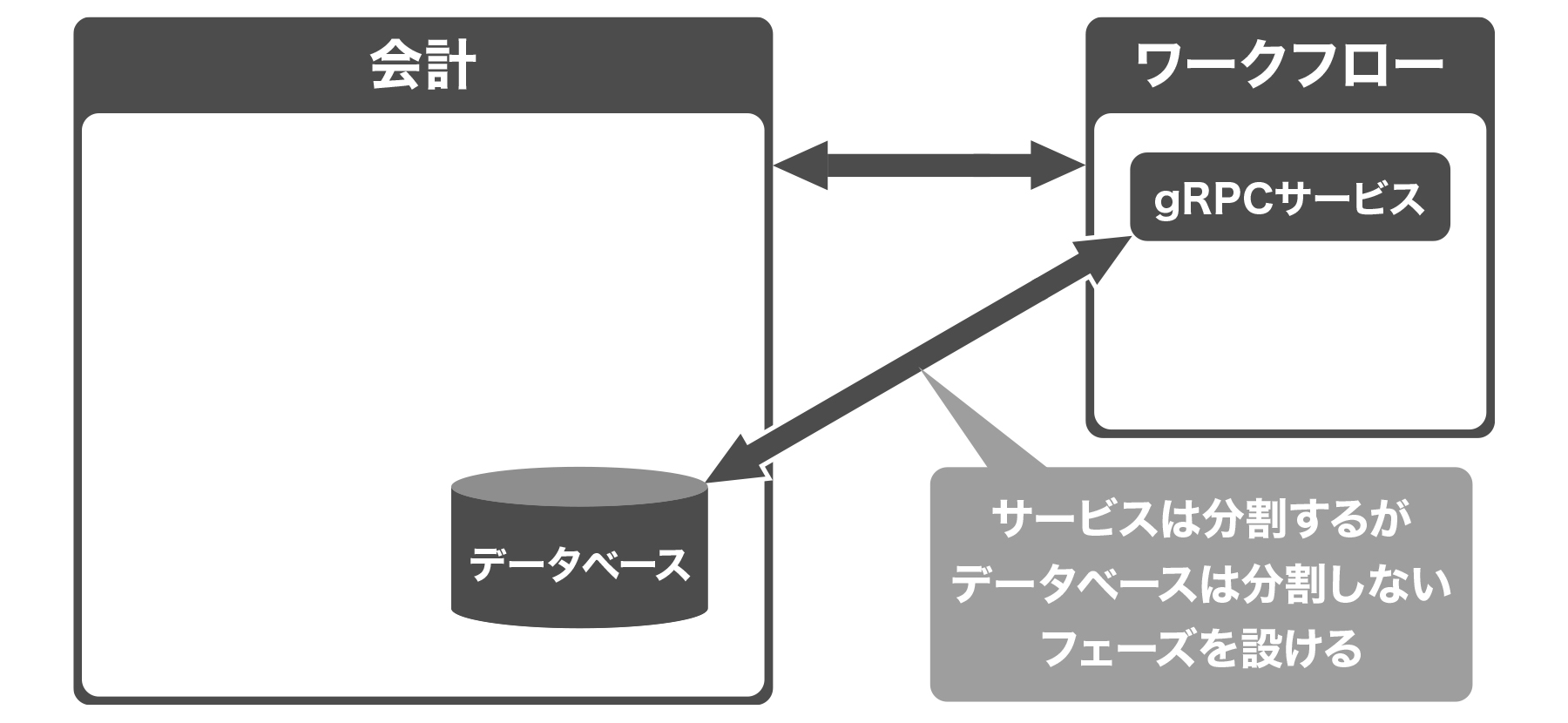
川島 それは、サム・ニューマン(Sam Newman)の著書『Monolith to Microservices』(O'Reilly、2019年)でも解説されているパターンですね。サービスのみをまずは分割して安全性を担保してからデータベースを切り離すという手法は、マイクロサービスにおける有効な移行パターンの1つです。
戦略3:仕様を変えてでも分離しやすいデータ構造を作り出す
川島 他には、どのような機能をマイクロサービス化しましたか?
横路 一例として、レポート機能が挙げられます。これは、お客さまが入力した会計データのレポートを出力するものです。もともとこの機能では、レポート集計時に毎回全ての計算がいちから走る作りになっていました。
川島 毎回集計してもパフォーマンスには問題がなかったのでしょうか?
横路 はじめはレコード数も少なかったですし、レコード数が増えてもAmazon RDSのインスタンスタイプを上げるだけでうまくいっていたんです。
freeeではマルチテナントDBの形態を取っており、全ユーザのデータが1つのデータベース内に格納されていますが、初期のfreeeでは個人事業主または小規模な企業だけを対象ユーザーとして想定しており、そのためレコード数がそれほど多くありませんでした。
それに、金銭的コストをかけて相当にスペックの良いデータベースインスタンスを使っていました。いわゆる、札束で殴るアプローチで、なんとかなっていたわけです。
しかし、freeeの事業が成長するにつれ、より規模の大きなお客さまも対象顧客にすべきフェーズが訪れました。そうしたお客さまの場合、数十万~数百万レコードを毎回集計することになるため、パフォーマンスに課題が生じる可能性が高い。アーキテクチャの見直しが必要になりました。
川島 どのようにアーキテクチャを変更したのでしょうか?
横路 CQRS(データの読み取りと書き込みのモデルを分離するアーキテクチャパターン)に基づいて、アーキテクチャを刷新する方針をとりました。
変更前のアーキテクチャでは、全てのデータ書込みをひとつのDBに同一のDBトランザクション内で行い、トランザクション一貫性を重視するような設計をとっていました。これを、最初の書込みのタイミングでイベントをAmazon Kinesisに送り、それをトリガにワーカーが非同期で後続の書込み処理をするよう変更しました。
このとき、参照・分析のユースケースに合わせた中間データを先に集計し、適材適所なデータストアに書き込んでおくことで、先ほどの毎回集計する負荷を解決できました。
さらに、イベントの処理状況は、Amazon DynamoDBで管理しています。
これで、データベースにかかる負荷を大きく軽減できます。しかし、このアーキテクチャは結果整合性的なアプローチであるため、入力された会計データがレポートに反映されるまでの即時性を保証できなくなる欠点が生じます。
プロダクトマネージャーやUXデザイナーと相談して、「UI/UXをどう変えれば、レポート出力までに多少の時間がかかっても、お客さまが安心して待機できるか?」を検討しました。結果として、レポートが出力されるまで「レポート集計中」というテキストを表示すると、お客さまに不安な気持ちを抱かせずに済むことが分かってきました。

川島 ときにはユーザー体験を変えてでも、アーキテクチャを最適化することが必要になるのですね。
横路 そうですね。特定の機能を仕様変更することで、データの依存関係をシンプルにでき、かつユーザー体験を損なわないようなケースでは、こうしたアプローチも有効だと思います。
川島 この事例は「ACIDではなく結果整合性を選ぶことで、データベース負荷を軽減する」というアプローチでした。一方で、「マイクロサービス化したものの、複数のサービス間でトランザクションの一貫性を担保しなければいけない」というケースもあるかと思います。そうしたケースの場合、freeeではどのような対応を行う予定でしょうか?
横路 そうした状況が生じた場合は、基本的にデータベースレイヤーで分散トランザクションを検討するか、アプリケーションレイヤーでデータ整合性を担保するしかないでしょうね。
分散トランザクションにしても、アプリケーションレイヤーでマイクロサービスのトランザクションを扱うTCC(Try-Confirm/Cancel)パターンやSagaパターンなどにしても、いずれも実装コストの高い設計パターンです。できることなら、回避したい。そのため、今のところは「できるだけACIDが求められるデータ同士はデータベースを分割しない」という方向性でアーキテクチャを検討しています。
オライリーから出版されている『進化的アーキテクチャ』(2018年)‡に「サービスベースアーキテクチャ」というパターンが紹介されていますが、それに近いアプローチですね。「データベースは一緒だけれど、サービスだけ分かれている」という特性を生かして生産性を上げるのも、現実解として許容できる手法だと考えています。
‡ 原書は、Neal Ford、Rebecca Parsons、Patrick Kua『Building Evolutionary Architectures』(O'Reilly、2017年)。
戦略4:コンテナやKubernetesでデプロイフローを標準化
川島 freeeではコンテナオーケストレーションとしてKubernetesを採用していることも印象的です。これは、どのような意図からでしょうか?
横路 本質的には、Kubernetes導入より「コンテナ化」に要点が置かれています。コンテナを使うことで、開発環境やステージング環境、本番環境などの差分を吸収し、同じアプリケーションがどの環境でも動くのを保証できること。かつ、アプリ側でどんな技術スタック使っていてもインフラの運用を標準化できることなどが、コンテナ採用の理由です。
マイクロサービス化が進む中、各サービスに必要なインフラやデプロイフローが異なるケースが、徐々に生じてきました。そうした課題を解決する上で、コンテナやKubernetesが有効な手段になっています。
マイクロサービスをKubernetesで運用することで、依存関係をコンテナに閉じ込め、かつデプロイフローも標準化できるため、運用コストを最適化できるからです。もともとKubernetesをAmazon EC2上で動かす構成で運用を行っていましたが、運用コスト軽減のためAmazon EKSが登場して以降は、そちらに移行しています。
現在、マイクロサービスを含め10以上のサービスがAmazon EKSで稼働中で、最終的には全てのサービスをKubernetes化する予定です。
まとめ:変化に強くなることがマイクロサービス化の本質
川島 その他に、マイクロサービス化にあたって工夫したことはありますか?
横路 マイクロサービスというより、技術選定に関する工夫ですが、技術をトップダウンで決め過ぎないことを意識しています。
エンジニアは「自分自身の意思で技術選定を行った」「技術がビジネスのインパクトに結びついた」という経験を積むことが、スキルアップに直結します。だからこそ、その経験をなるべく多くのメンバーに積ませてあげたい。メンバーが成長するからこそ、会社が成長すると言いますか。
セキュリティなど事業継続リスクに直結する部分や、ひとたび意思決定したら長期にわたって変えられない部分はトップダウンで決めるべきですが、そうでない部分はみんなが決めてくれたらいい。失敗したら、そこから学んで次はもっとうまくやれたらそれがいい。
各エンジニアが創意工夫することでサービスが成長し、ユーザーにとっての価値向上につながることが重要だと思っています。
川島 横路さんの持つマインドが伝わってきます。最後に、大規模なサービスを持つ企業がマイクロサービス化に取り組む意義について、ご説明ください。
横路 マイクロサービス化の本質とは、変化に強くなることだと考えています。一般論として、プロダクトや組織が大きくなっていくとアジリティも落ちるし、さまざまなものを変えにくくなるんですよね。企業としての弾力性がなくなってくると言いますか。
その反面、事業環境の変化のスピードは速くなっていきますから、大きな企業であればあるほど、各種の事業施策のイテレーションを高速で回せることの価値が相対的に大きくなります。だからこそ、プロダクトや技術的な意味での「変化しやすさ」を維持し続けるのが、開発組織にとっては非常に重要なんです。
磨きたい事業領域にエンジニアリングパワーを投下すれば、施策を高速で回せるというケイパビリティを担保することが、現代におけるIT企業の競争力につながります。そのための有効な手段の1つが、マイクロサービスであると考えています。

取材・執筆:中薗昴




