
機械学習を記事配信に採用したママリ - 0から構築したレコメンドエンジンのアーキテクチャ設計
コネヒト株式会社が運営する女性向け情報サービス「ママリ」では、2019年12月に記事配信で機械学習によるレコメンドエンジンを構築、2020年初頭にテストが完了しました。 機械学習を採用した背景、設計したアーキテクチャとテストの結果について伺いました。
コネヒト株式会社が運営する、女性を対象とした情報サービス「
ママリでは2019年12月、サービス内に掲載する記事の配信について機械学習を採用したレコメンドエンジンへ変更し、2020年初頭にテストが完了、いよいよ正式リリースとなりました。
機械学習を採用した背景、設計したアーキテクチャとテストの結果、そして今後の展望について、コネヒト株式会社執行役員CTOの伊藤翔さん、機械学習エンジニアの野澤哲照さんにお話を伺いました。

- 伊藤 翔(いとう・しょう/写真左)
- コネヒト株式会社 執行役員CTO
1986年生まれ、慶應義塾大学卒。学生時代からプログラミングに興味をもち金融系のSIerに新卒入社。その後、Web系の受託会社を経験する中で、自社サービスをつくりたいと思うようになり、Supershipに入社。2017年にグループ会社であったコネヒトに出向し、「ママリ」のAPI開発や「ママリプレミアム」の立ち上げを経験。リードエンジニアや開発部部長を歴任し、2019年6月にCTOに就任。 - 野澤 哲照(のざわ・たかのぶ/写真右)
- コネヒト株式会社 機械学習エンジニア
新卒でSlerに入社。主に薬品や食品などを扱うメーカー企業向けのERPパッケージを扱い、要件定義から開発・導入・保守まで幅広く経験。2019年3月に機械学習エンジニアとしてコネヒトに入社。機械学習(NLP・推薦システム)のモデリング・API開発をメインとしつつ、インフラ(AWS)も勉強中。
“ママの一歩を支える”サービスとして
――ママリはどのようなサービスでしょうか?
伊藤 「ママの一歩を支える」をブランドミッションとした、女性向けのQ&Aアプリ・情報サイトです。「ママに寄り添う」をモットーに、日本全国のプレママ・ママに役立つさまざまな情報を発信し、専門性の高い医学的な記事については専門家の監修を付けてお届けしています。
2014年のサービス開始以来、“スマホファースト”で開発を進めてきました。その後、順調にユーザー数が増えていったのですが、2018年2月にテレビCMを公開して一気に認知度が上がり、2020年2月現在、アプリ会員登録数は240万人となり、その年に出産をしたママ3人のうち1人にご利用いただけている規模感まで成長しています。
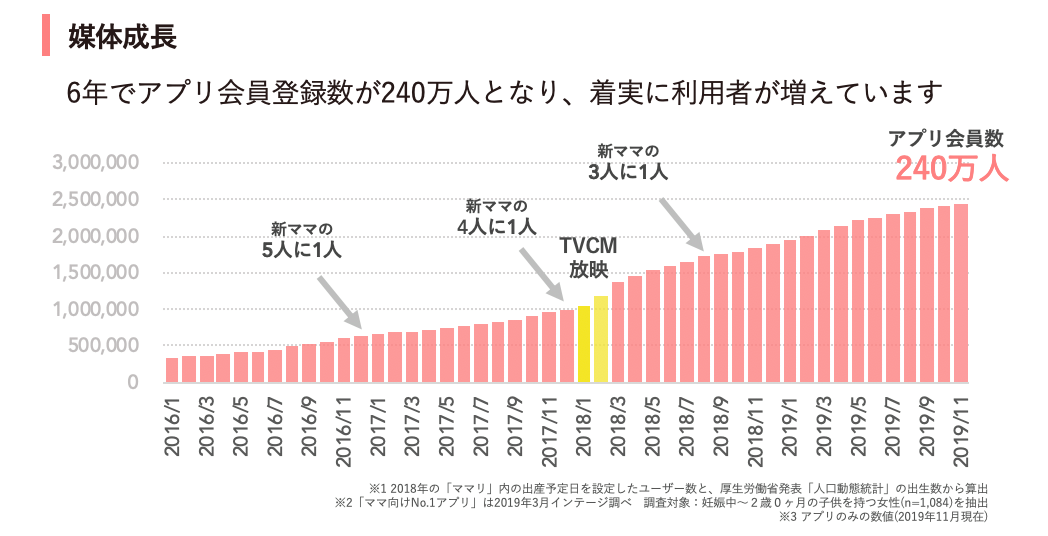
コネヒト株式会社によるアプリ会員数の資料
――現在の開発体制はどれくらいの規模ですか?
今の体制は、プロダクト開発のエンジニアが8名ほど、今回お話しする機械学習およびインフラを横断的に見るエンジニアが2名です。
レコメンドエンジンアップデートの舞台裏
ルールベースでの限界を感じた
――それでは、新機能の目玉である記事配信のレコメンドエンジンについて詳しく教えてください。まず、どのような背景で機械学習の採用を決めたのでしょうか?
野澤 私たちが考える理想の記事配信方法は、「検索しなくても、その時ユーザーが欲しい情報をお届けできること」です。検索するには検索のためのキーワードが必要になります。サービスの成長とともに記事数も増加してきており、ユーザー自身の考え方や前提知識によっては、本来欲しい情報にたどり着くことが難しくなってきています。
加えて「子育て層のユーザー」という切り口1つとっても、0才児と2才児のママでは、悩みや欲しい情報がまったく異なります。
このような背景から、これまで人的に行っていたルールベースでの記事配信に対し限界を感じていました。それが、機械学習を採用したレコメンドエンジン開発のきっかけです。
機械学習が与える「気持ち悪さ」を防ぐ
――採用に当たって課題などはなかったのでしょうか。
伊藤 野澤が申し上げたように、ユーザー数の増加、記事数の増加、そして、世の中の変化に合わせて、アイデアを出し合い、議論しました。その中でルールベースのまま進めていくことも考えとしてはありましたが、そうすると、新しい要件が増えるたびにif文を増やす……なんていうことになりかねません(苦笑)。
また、すでにカスタマーサクセスチームによるコミュニティ運営では、運用コスト削減の観点から機械学習を利用し、一定の成果が出ていました。単純なルールベースの運用を機械学習に置き換えて成功している事例も増えてきており、今後サービスをグロースさせるため機械学習を活用することは必要不可欠だと判断して、導入に踏み切りました。

伊藤 翔さん
伊藤 一方で、機械学習をはじめ、AIに関する技術はコモディティ化してきているものの、実サービスに導入してみないと分からないことも多いと思います。例えばユーザーが住んでいる場所の近くの情報ばかりがレコメンドされるなど、自分としては何も入力していないのに極端に先回りされた情報が届くと、「気持ち悪さ」を感じさせてしまいます。
機械学習を採用するに当たって、この「気持ち悪さ」を感じさせないためにはどうするか。これを最初の課題の1つとして開発を進めました。
行動ログ、クラスタ、ユーザー属性による構造化
――世の中の流れ、技術の進歩、そして、ママリが目指す理想形、それらを組み合わせた結果としての機械学習型レコメンドエンジンの開発がスタートしたわけですね。それでは、実際にどのようなアーキテクチャで設計をしたのか、詳しく教えていただけますか。
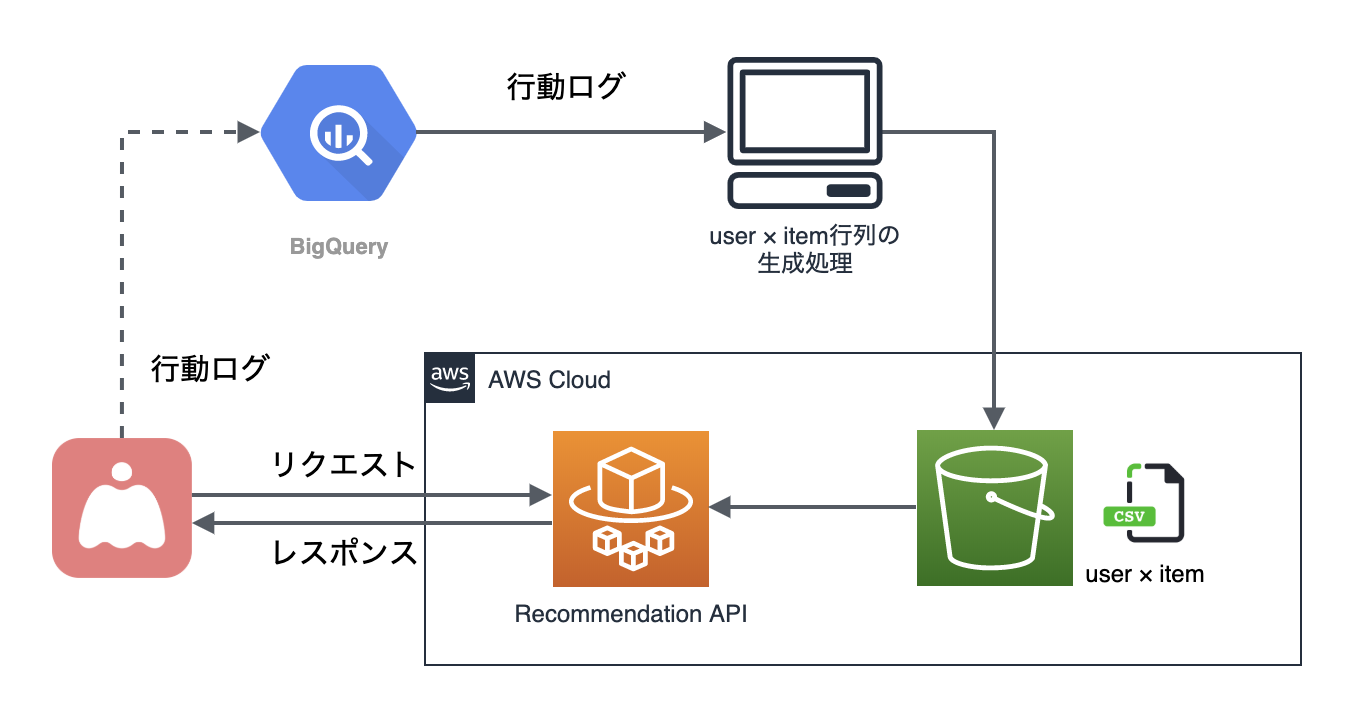
野澤 プロダクション環境では、下記のような構成に切り替えました。Step Functionsで囲まれた部分が機械学習ワークフローです。
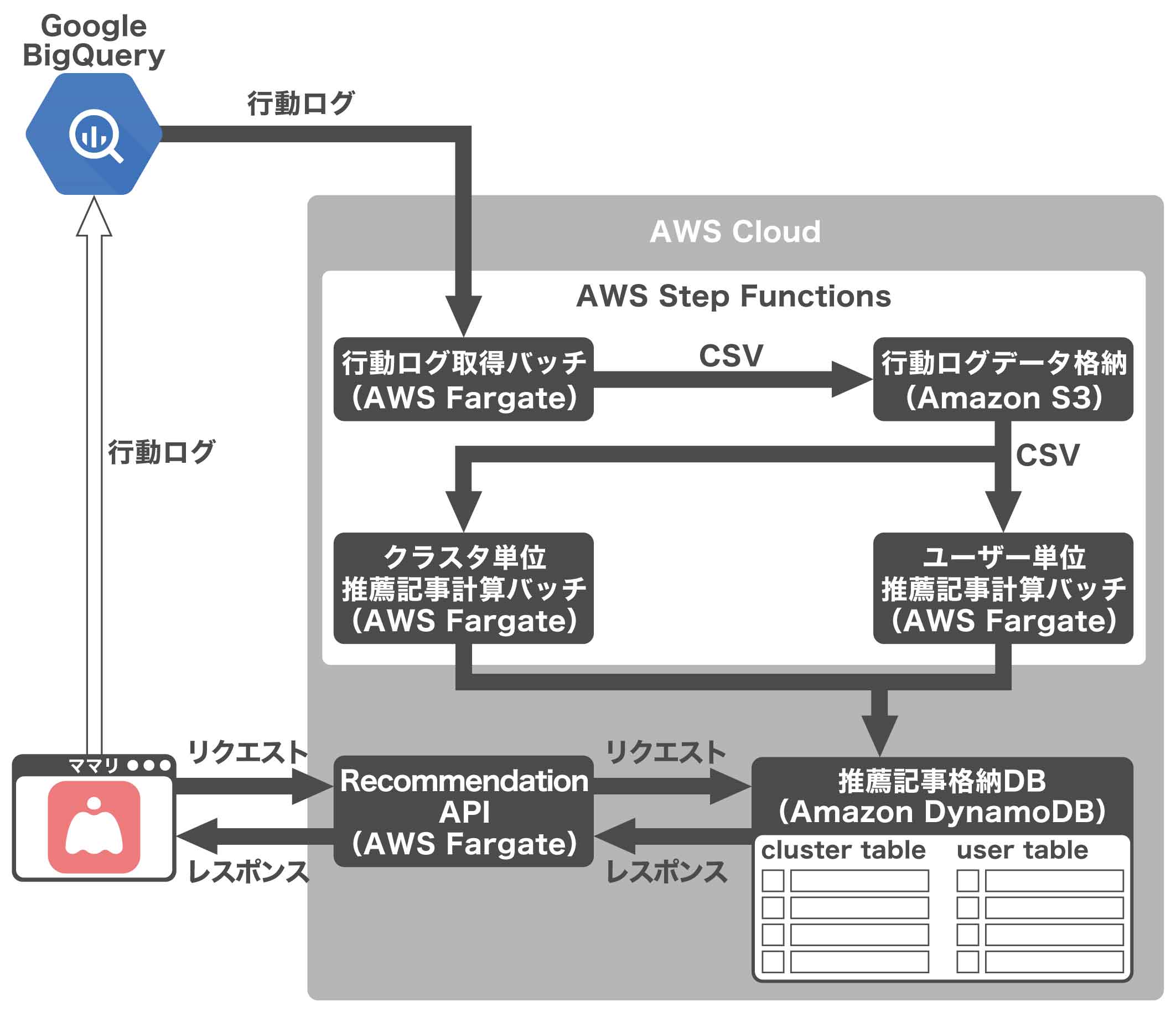
野澤 ママリのアプリでは、ユーザーひとりひとりの行動ログがBigQueryに蓄積されています。そこから「行動ログ取得バッチ」を使って構造化前の生データを集計・加工し、機械学習で扱えるデータ構造に変形した上で、一度ストレージに保存します。そのデータを「クラスタ単位」と「クラスタ×ユーザー単位」の2種類に分け、推薦記事を計算しています。
ここでいうクラスタとは、あるルールに基づきユーザーをハードクラスタリングしたものを指します。
レコメンドエンジンを構築する際、まずはデータの理解を深めるためにログの分析を行いました。その結果、ユーザー属性単位で閲覧する記事の種類についてある程度偏りがあることが判明し、その結果をもとにユーザーを10種類ほどのクラスタに分類しました。
上図のクラスタ単位における計算部分では、以下のようにクラスタ粒度でRatingテーブルを作成し、推薦記事を計算しています。こうすることで、新規ユーザーに対してもある程度嗜好性を考慮した記事を推薦できるようにしています。
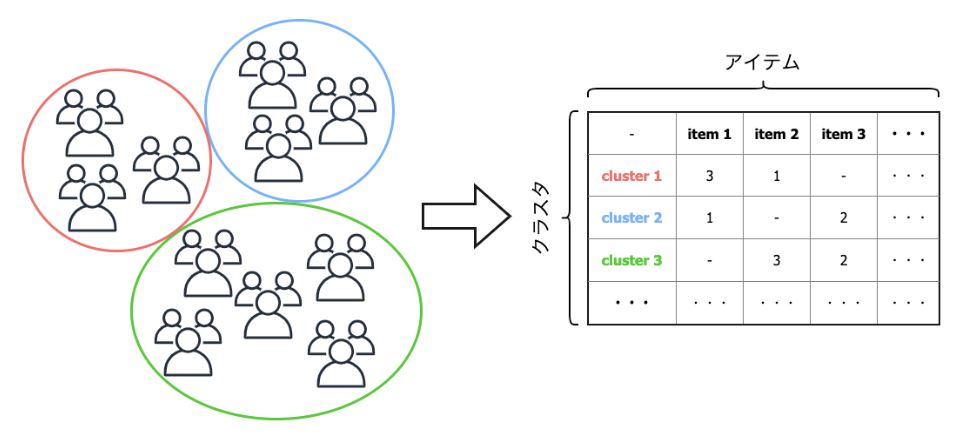
クラスタ単位の推薦記事計算例
野澤 一方、ユーザー単位の計算部分では、ユーザーごとにそれぞれのクラスタ内で推薦記事を計算しています。
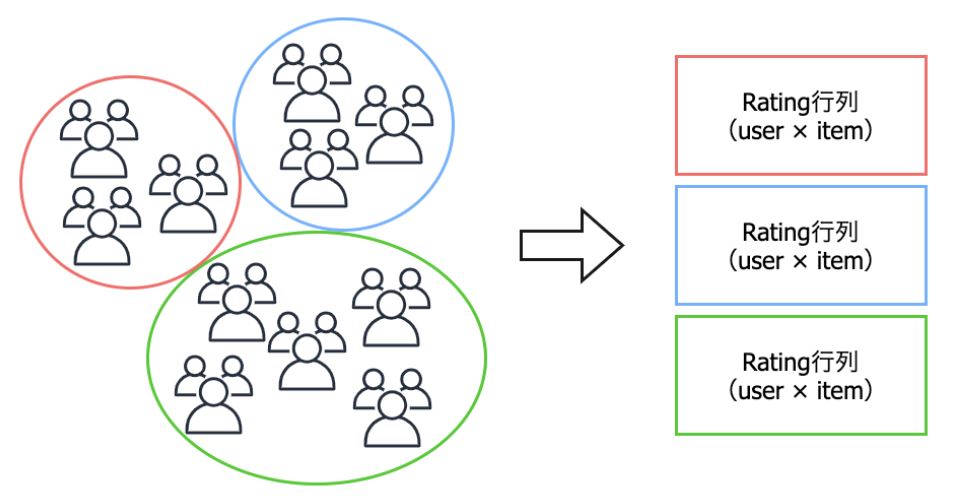
クラスタ×ユーザー単位の推薦記事計算例
野澤 これら2種類の単位で計算された記事をデータベースに格納し、その中から記事を配信するという仕組みです。
伊藤 機械学習を含むバックエンドは、すべてAWSを利用しています。BigQueryから取得し加工したデータの格納先にはAWS S3を、推薦記事の格納データベースにはAmazon DynamoDBを、そして、各種機能はすべてAWS Fargate(コンテナ)による、サーバレスアーキテクチャで構築しています。
2種類のアルゴリズムとA/Bテストによる最適化
――全体のアーキテクチャが決まり、いよいよテスト段階に入ったということですね。最初期の学習データはどのように準備したのでしょうか。
野澤 まず全ユーザーの直近3週間の行動ログ(アプリの閲覧履歴、ユーザーのアクションを含む)を取得し、構造化しました。

野澤 哲照さん
野澤 そこからデータを時系列に、古い2週間と直近1週間に分割し、前者を学習データ、後者をテストデータとしてオフライン検証を行いました。今回は「0→1」での導入だったため、レコメンドの精度よりは実装までのスピードを意識しました。そのため、アルゴリズムには、業界内での成功事例があり、かつ比較的実装コストも低い協調フィルタリングと、Matrix Factorization(MF)を採用しました。
それぞれ簡単にご説明します。
協調フィルタリング・Matrix Factorization共にuser×itemのRating行列が基本となります。今回、Ratingはある程度ヒューリスティックに決定しました。
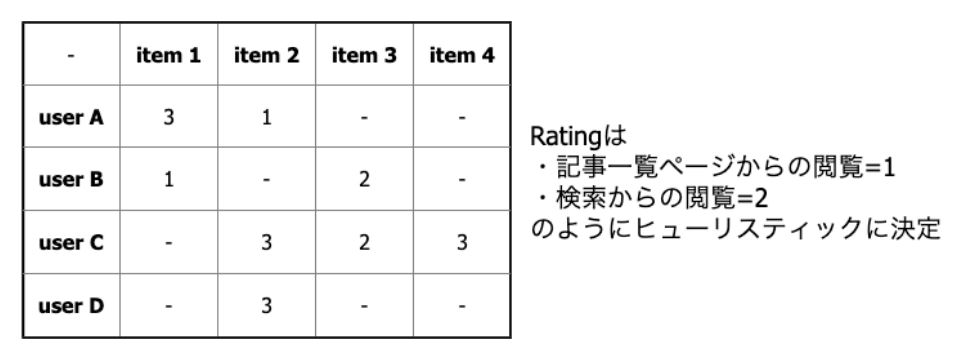
基本となるRating行列の一例(-は未評価)
野澤 協調フィルタリングは大別して「ユーザーベース」と「アイテムベース」の手法があります。今回実装したのはアイテムベースの協調フィルタリングです。
まず、上記Rating行列から全てのアイテム間の類似度を計算して、類似度行列を生成します。この時の類似度計算方法には「ユークリッド距離」や「コサイン類似度」を使用できます。今回はコサイン類似度を使用しました。
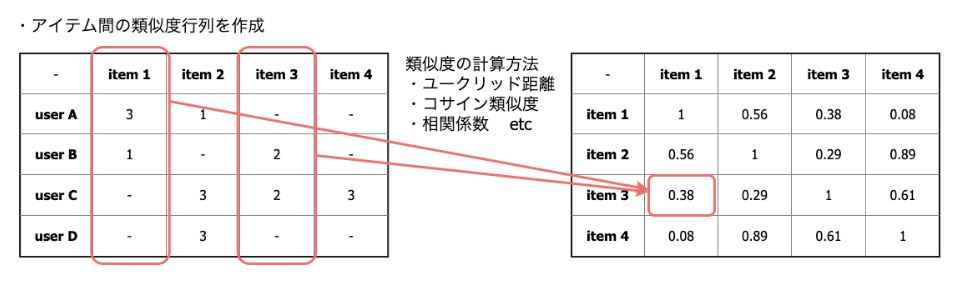
類似度行列作成例
野澤 次に、推薦アイテムを計算したいユーザーのベクトルと、この類似度行列の積をとります。下記例では、user Dに対して推薦したいアイテムを計算しています。計算結果からすでに評価しているitem 2を除外すると、item 4の値が一番高いため、user Dにはitem 4を推薦すればよい、ということになります。
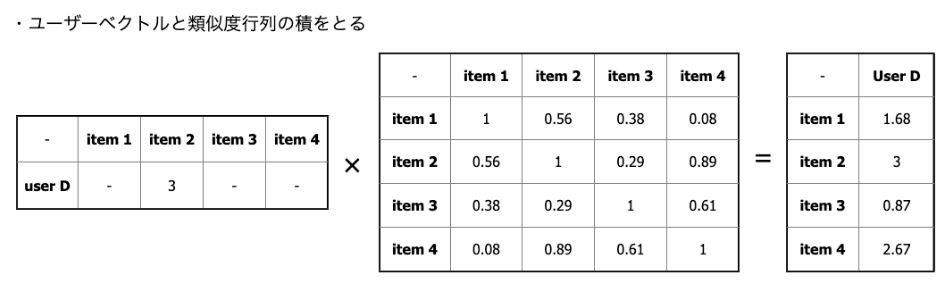
user Dに対する推薦記事計算例
野澤 Matrix Factorizationはその名前の通り、Rating行列をuserの特徴量行列(P)とitemの特徴量行列(Q)に分解します。
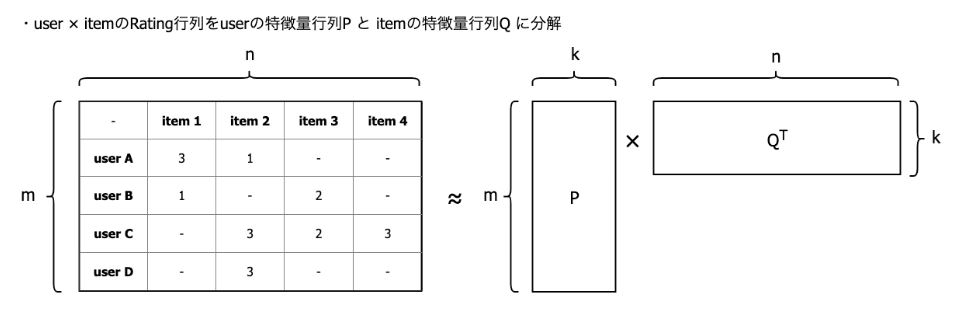
行列分解例
野澤 そして、分解された2つの行列の積をとると、新しいuser×itemのRating行列が生成されます。このRating行列は密な行列となるので、値の高いアイテムをそのまま推薦すればよいことになります。例えば、user Aに対してはすでに評価しているitem 1とitem 2を除外すると、item 3を推薦すればよい、ということになります。
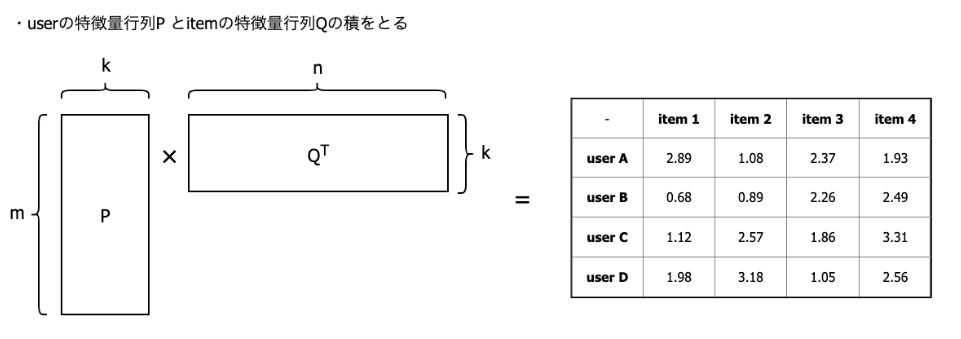
最終的な推薦アイテム計算例
野澤 オフライン検証では、そのアイテムをクリックするか否かを評価するため、Recall@20の指標を用いました。Recallとはユーザーが実際に嗜好したアイテムのうち、推薦したアイテムでカバーできたものの割合です。
協調フィルタリング・Matrix Factorizationの両方でスコアを計算した結果、Matrix Factorizationの方が若干良いスコアが出ました。しかし、どちらも想定よりかなり低いスコアとなり、この時は不安が大きかったのを覚えています。
そもそもオフラインでの評価は、我々がおすすめしようとするまいと、ユーザーが嗜好(クリック)したものを予測しているので、それを正確に予測できることにどれだけ意味があるのか、という議論ポイントはあると思っています。そんな中でオフライン検証ではあまり良い予測ができないケースもある――良い予測ができても、それがそのままオンラインでの精度にならない、ということを学べたのは、今回の収穫の1つであったと感じています。
伊藤 開発者としては非常にもどかしい結果だったのは事実です。とはいえ、PoC1ばかり進めていても仕方ありません。そこで、スピード感を持って開発するために積極的にプロダクション投入することでエンジンの性能を上げる方針にシフトし、オフライン検証の結果から、まずMatrix Factorizationによる機械学習を採用したエンジンを使い、実際のユーザーの皆さまに向けてA/Bテストを実施しました。
野澤 A/Bテストでは、CTRが7ポイント向上したこと、検定を行いそのCTRに有意差が確認できたことから、今回のレコメンドエンジンで一定の成果が認められました。開発担当の立場としてはホッとしています(笑)。
また、冒頭で説明した構成図は最終的なもので、A/Bテスト時の構成はかなりシンプルです。
全体のアーキテクチャを先に設計・構築してしまうと、実装までのスピードが遅くなったり、仮に良い結果が得られなかった場合の時間的・金銭的コストが大きくなってしまいます。そのため、下図のような最小限の構成としました。
A/Bテスト後の結果とこれから
――A/Bテストでは一定の成果が得られた、ということでいよいよ正式リリースに向けて動き出すわけですね。最後に、A/Bテストの結果からの講評、そして、これからの展望について教えてください。
伊藤 このご質問については、さまざまな考え方があると思っています。
私の場合、新技術を試す場合は「現状維持ができれば成功、上がればなお良し」という考えで評価することが多いです。今回のケースにおいても、そもそもルールベースでの限界を感じており、また、このままサービスが続けばルールをメンテナンスするための人的コストが上がっていくという背景があったため、「CTRが変わらなければ良し」と考えていました。結果として、A/BテストでのCTR向上で成功と捉えています。
野澤 CTRが向上したことは素直にうれしかったです。ただ、今回はまだスタートラインに立っただけで、これからいろいろな課題が見えてくると思います。
先にもお話しした通り、初手で大切なことは「検証・実証までのスピード」と「検証結果から正しく知見が得られること」だと思っており、今回はその2点について意識的に取り組みました。
今後、このレコメンドエンジンをユーザーの方々に使っていただき、定期的に効果測定しながら、より良い情報を配信できる最適なレコメンドエンジンに育てていきたいです。
コネヒトの機械学習チームは結成されて1年足らずで、自分のスキル・経験共に未熟な部分も多いと感じています。一方、サービスとしてはとても魅力的で面白いデータがそろっており、データや機械学習を活用することで、まだまだ成長させられると思っています。このような資産を最大限に生かしていけるよう自己研鑽し、チームやサービスの成長に貢献するとともに、「日本全国のママの一歩を支えることのできる存在」を目指していきたいです。
伊藤 機械学習という技術は、これからどんどんコモディティ化が進んでいくと思います。振り返ってみると、2010年代は、スマートフォン・クラウドの一般化、普及フェーズの10年でした。2020年代は、機械学習を含めたAIが一般化、そして、普及していく時代になると考えています。
そういう時代ですので、ママリでも機械学習を活用しながらより良いプロダクトを作っていきたいと考えています。私としては、機械学習そのものだけではなく、プロダクトの質を高めること、例えば冒頭で述べたような「気持ち悪さ」を解消できるよう、エンジニアはもちろんデザイナーとも話を進めながら、多くのママユーザーに使われる「ひとりひとりにとって最善のUX」を提供できるよう、取り組んでいくつもりです。
取材・文・構成:馮富久(株式会社技術評論社)
Proof of Conceptの略。新しい技術やアイデアが実現可能かどうかを事前に検証すること。↩




