
KotlinをKotlinらしく、そして可読性を高く保つ運用知見 - エキスパート長澤太郎に聞く実装のイロハ
近年注目を集めるKotlinはどのように書き、どのように運用するのがいいのか。2012年からKotlinに親しむUbie社の長澤太郎さんに、その経験から得られたKotlinノウハウを聞きました。
2011年7月に登場したJVM言語・Kotlinは、近年多くの注目を集めている言語の1つです。Androidアプリの開発言語としてGoogle I/O 2017で正式採用されたことも契機となり、Kotlinはその存在感を一挙に高めました。
そして、この言語に黎明期から親しみ続けてきたのが、Ubie株式会社の長澤太郎(ながさわ・たろう/ 

2012年3月に早稲田大学情報理工学科を卒業し、メーカー系SIerに入社。2013年10月にエムスリーに入社し、その後2018年4月に現在所属するUbieに入社。Kotlinを用いたサーバーサイド開発やReact+TypeScriptによるフロントエンド開発を行う。日本Kotlinユーザグループ代表。Kotlin黎明期より、国内での技術啓蒙、コミュニティ活動に取り組む。著書に『Kotlinスタートブック - 新しいAndroidプログラミング』『Kotlin Webアプリケーション - 新しいサーバサイドプログラミング』(いずれもリックテレコム刊)など。
- Kotlinが解決した、Javaの言語仕様上の課題
- 「今ならまだ、Kotlinの先駆者になれる」
- レビューの徹底と規約の整備によって、難読コードを防ぐ
- どの機能から、Java → Kotlinのマイグレーションを行うか
- IntelliJ IDEAをフル活用して、ソースコードを洗練させる
- どんなプラットフォームでも、Kotlinが動く世界に
Kotlinが解決した、Javaの言語仕様上の課題
——Kotlinは、Javaとの高い互換性を持ち、かつJavaよりも簡潔なプログラムが書ける言語として登場したと認識しています。Javaがもともと抱えていた、言語としての課題はどのような点にあったとお考えでしょうか。
長澤 何点かありますが、まずJavaにはどうしても「記述が冗長である」という課題を抱えていたと考えています。例えば、変数宣言で「クラス名 変数名 = new クラス名();」のように型の情報を二重で書く必要があるなど、記述のくり返しが多くなってしまう傾向があります。もっとも、現在のJavaには型推論の機能が備わっており、大きく改善している部分ではあります。
さらに、Javaのソースコードでは「ボイラープレートの記述が多くなりやすい」という課題も挙げられます。データを輸送するオブジェクトにgetterやsetter、equals、hashCodeなどのメソッドを書くのが典型的な例です。シンプルなフィールドだけを持つクラスでも、ボイラープレートのコード量が多く、本質的な記述が埋もれがちだという課題がありました。
それから、「nullの扱い」に関する課題もあります。Javaではプリミティブ型ではないすべての変数にnullを代入可能です。かつ、nullの可能性がある変数にも簡単にアクセスできてしまうため、NullPointerException発生の原因になります。
こうした課題に対し、nullを防ぐためのAnnotationやOptionalクラスなどの導入によって回避しようと試みてきました。ですが言語組み込みの機能ではないので、ユーザーが使い方を間違えたり、意図的にそうした機能を使わなかったりすれば、依然としてnullを扱うリスクは残ってしまいます。
——Kotlinはどのような言語仕様を盛り込むことで、その課題を解決したのでしょうか?
長澤 記述の冗長さは、型推論によって解決されています。先ほど説明したように、Javaでは変数宣言の際に型の情報を二重で書く必要がありましたが、Kotlinは一方を省略可能になっています。
変数宣言だけではなく、ジェネリクスなどさまざまな機能において、推論可能な部分であれば型の記述を省略できます。また、ボイラープレートの課題は、プロパティという機能やdata classという仕組みを用いて、コードを自動生成することで解決しました。
——null安全性についてはどうでしょうか?
長澤 Kotlinでは変数の種類に応じて「nullが代入可能か、そうではないか」が明確に決められています。そしてnullが代入可能な変数にチェックもなしにアクセスすると、コンパイルエラーになってしまうのです。if文を用いてnullではないことを確認する、nullの可能性がある箇所専用の文法を使うなど、nullの扱いを工夫する必要があります。
こうした言語組み込みの機能を充実させることで、NullPointerExceptionを発生させない工夫がなされています。
「今ならまだ、Kotlinの先駆者になれる」
——Kotlinが2011年7月に登場した後、約半年後の2012年初頭には、長澤さんは「Kotlinエバンジェリスト」を自認し、ブログなどで情報発信をされています。なぜ、これほど早くKotlinに注目されたのですか?
長澤 その頃からJavaのプログラムを書いていたので、JVM言語であることにすごく親近感が湧いたからです。
他のJVM言語としてGroovyやScalaがありますが、Groovyは動的言語なのでちょっとJavaとはジャンルが違うのかなと感じたのと、Scalaの仕様は独自色が強いと感じられて、当時の自分にとっては習得が難しかったです。一方のKotlinは、Javaからの仕様上の大きなジャンプがないため、学習コストが低いと感じられた大きな魅力でした。
それに、登場したばかりの言語だからこそ、「他の人たちはまだ注目してないのでは」「今ならKotlinの先駆者になれるかも」という思いもありました。

——「徐々にKotlinの人気が出てきた」と感じた契機はありましたか?
長澤 個人的な感覚では、2015年に2つの大きなイベントがあったと思います。1つ目は、Androidエンジニアである「きりみん」さんが、「2015年のAndroid開発はKotlinで決まりかもしれない」というブログを書き、非常にバズったことです。これをきっかけに「Kotlinはやはり良い言語なんだな」と思い始めました。
2つ目は、その年の4月にAndroidの技術カンファレンス「DroidKaigi」の第1回目が開催されたのですが、私が登壇した「新言語KotlinでAndroidプログラミング」というセッションにかなりの反響があったことです。そういった出来事を経験して、Kotlinの将来性を感じました。
それから個人的に思い出深いのは、Google I/O 2017でAndroidの開発言語としてKotlinが公式採択されたことですかね。その瞬間が一番嬉しかったというか、Kotlinをやってきて良かったと感じた瞬間でした。このアナウンスを皮切りに、Kotlinを導入している企業が増えていったように思います。
レビューの徹底と規約の整備によって、難読コードを防ぐ
——ここからは、Kotlinを使ううえでの注意点を伺いたいです。長澤さんは過去にKotlinは表現力が高いからこそ「後で読み返せないコードが増産される、プログラマの『暴走』が起こりがち」という話をされていました。どのような機能が、暴走を助長してしまうのでしょうか?
長澤 表現の豊かさにつながる機能としては、拡張関数とラムダ式の2つが大きいです。
——それぞれの機能の概要を解説していただけますか?
長澤 拡張関数は、既存のクラスやインターフェースなどに対して、メソッドのような機能を追加できるものです。例えば、標準で用意されているStringクラスに対して、任意の操作を追加できるのです。
ただ、拡張関数の使用には注意が必要です。privateな拡張関数であれば、比較的カジュアルに使っても問題になることはないでしょう。しかし、publicな拡張関数が多用されてしまうと「プロジェクト内で、どのクラス・インターフェースにどんな機能拡張が行われているか」を把握するのが大変になってしまいます。ソースコードをIDEで閲覧する分には定義元にジャンプできるのでまだ理解しやすいですが、GitHub上のコードレビューではそれができず、開発メンバーの混乱を招く原因になります。
もうひとつのラムダ式とは無名関数の記述方法の1つです。Kotlinにおける関数は独立した構成要素であるため、文字列や数値のように変数への代入や引数への受け渡しが可能です。Kotlinは拡張関数とラムダ式を組み合わせることができるため、書き方によっては特定の人にしか読めないような複雑度の高いプログラムになってしまうんです。
——複雑な記述が多用されると、読むのが大変ですね。そういった事態をどのように防ぐべきでしょうか?
長澤 ソースコードレビューの際に、複雑度の高い書き方をしていないかチェックするのが重要になります。コーディング規約を整備するのも有効です。私が在籍しているUbie株式会社の場合は、他の方々にも参考になればと思ってKotlinのコーディング規約をGitHub上で公開しています。
それから、ktlintというKotlin用の静的な文法解析ツールがあるので、機械的にチェックできる部分に関してはツールの助けを借りてみてください。

Ubie社が公開する、コーディング規約の一部。長澤さんをはじめ、豊富なKotlinの運用知見に基づくノウハウが記載される。
どの機能から、Java → Kotlinのマイグレーションを行うか
——JavaからKotlinへの移行を行う際に、優先的に置き換えたほうが良い機能はありますか?
長澤 かつて、Kotlinの挙動がまだ不安定だった頃(バージョン1.0より前の頃)は「テストコードからKotlin化していくといいです」とアドバイスしていました。実際に、そういう移行プランをとっていた企業も多かったような気がします。
現在のKotlinは挙動が安定しているので、テストコードだけではなく、いきなりプロダクトのコードに適用しても大丈夫だと思います。置き換えやすい機能としては、ドメイン層のようにライブラリ・フレームワークの影響を受けにくいPOJO(Plain Old Java Object)の箇所などが挙げられます。
——それはなぜですか?
長澤 Javaのフレームワークの機能にべったり依存している部分の場合、意図せぬ挙動が起きるケースがあるからです。例えば、コードを自動生成するようなAnnotation Processingツールなどは、ハマることがあります。ツールの実行とKotlinのビルドが走るタイミングの順序が適切でない場合にエラーが起きてしまう、という事例を目にしたことがあります。
——そういった処理を制御するのは、骨の折れそうな作業ですね。POJOから置き換えた方がいいのも納得です。他に、JavaからKotlinへの移行にあたり、注意すべき点はありますか?
長澤 これはKotlinを使い始めたばかりの方に向けたアドバイスですが、最初はKotlinらしいコードを無理に書かなくてもいいと思います。よりKotlinに慣れてから、リファクタリングしていく、という方針でいいと思います。
——“Kotlinらしいコード”とは、どのようなものでしょうか?
長澤 「Kotlinの持つ機能を適切に使えているコード」だと思います。例えばごく簡単な例ですが、以下のようなif文の書き方をJavaではよく見ますよね。
if (*** some conditional judgment ***) {
System.out.println("OK");
} else {
System.out.println("NG");
}
同じ処理をKotlinらしい書き方に直すと、以下のようになります。Kotlinにおけるifは式であり値を返すことが可能なので、その特徴を生かしたコードになっている、というイメージです。
val msg = if (*** some conditional judgment ***) "OK" else "NG" println(msg)
前者のコードの場合は「条件分岐」と「出力」のパートが混在していますが、後者のコードの場合は処理を「条件分岐」と「出力」という2つの塊に分けており、可読性がより高まっています。
IntelliJ IDEAをフル活用して、ソースコードを洗練させる
——Kotlinのリファクタリングを行ううえで、役に立つノウハウは他にありますか?
長澤 IntelliJ IDEAには「どう書けば、よりKotlinらしいコードになるか」を提案してくれる以下のgifのような機能があります。提案に従って修正することで、リファクタリングの方法を学ぶことが可能です。
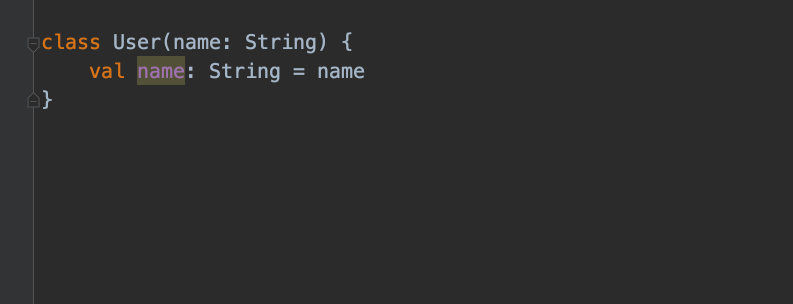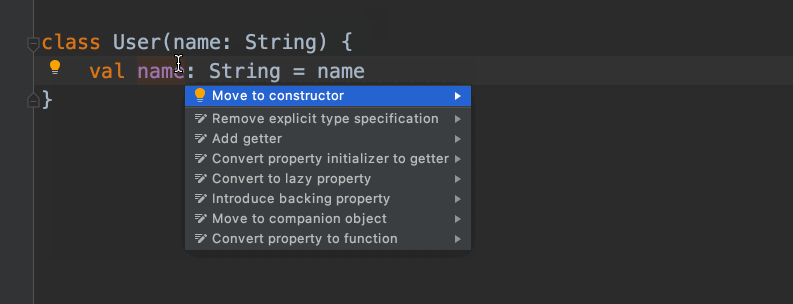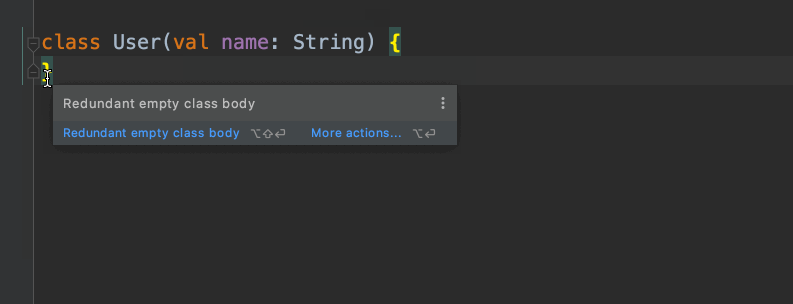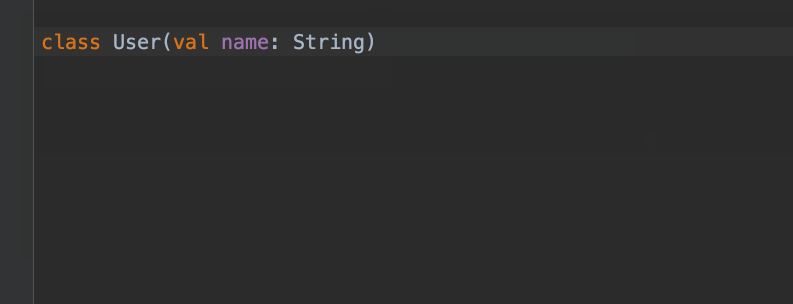
画面を順に説明してみましょう。

例示で書いたこちらのコードでは、コンストラクタ引数をそのままプロパティにセットしていますが、これは冗長な記述方法です。このような場合……
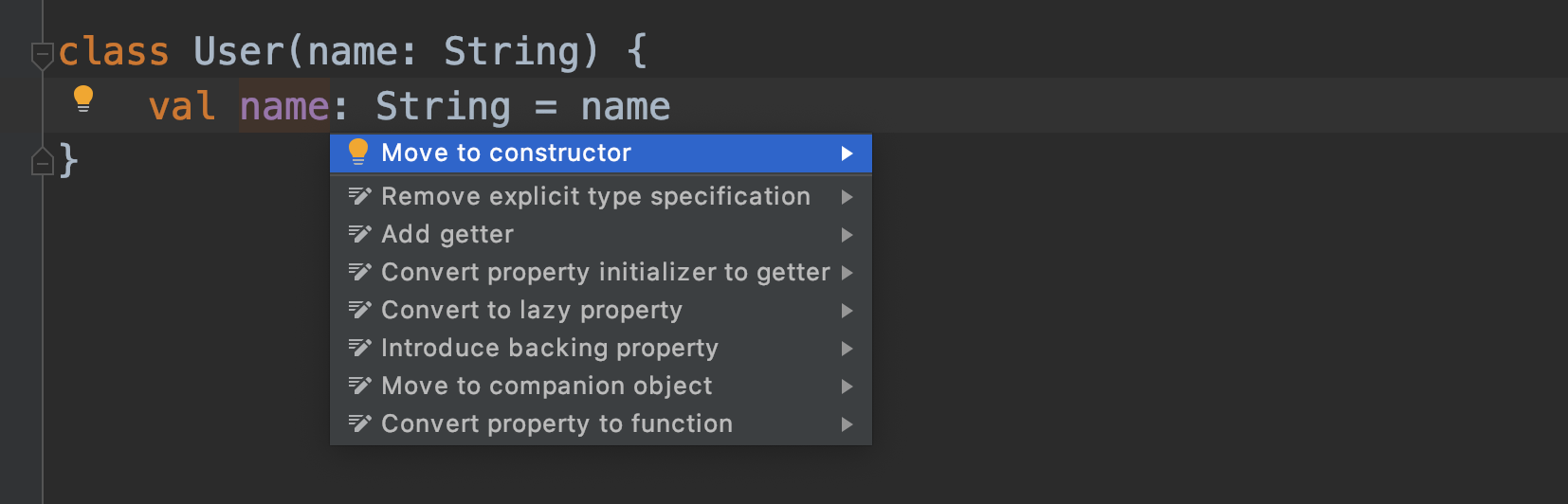
IntelliJ IDEAがプロパティnameをコンストラクタに移動するというアクションを提案します。これを選択すると……
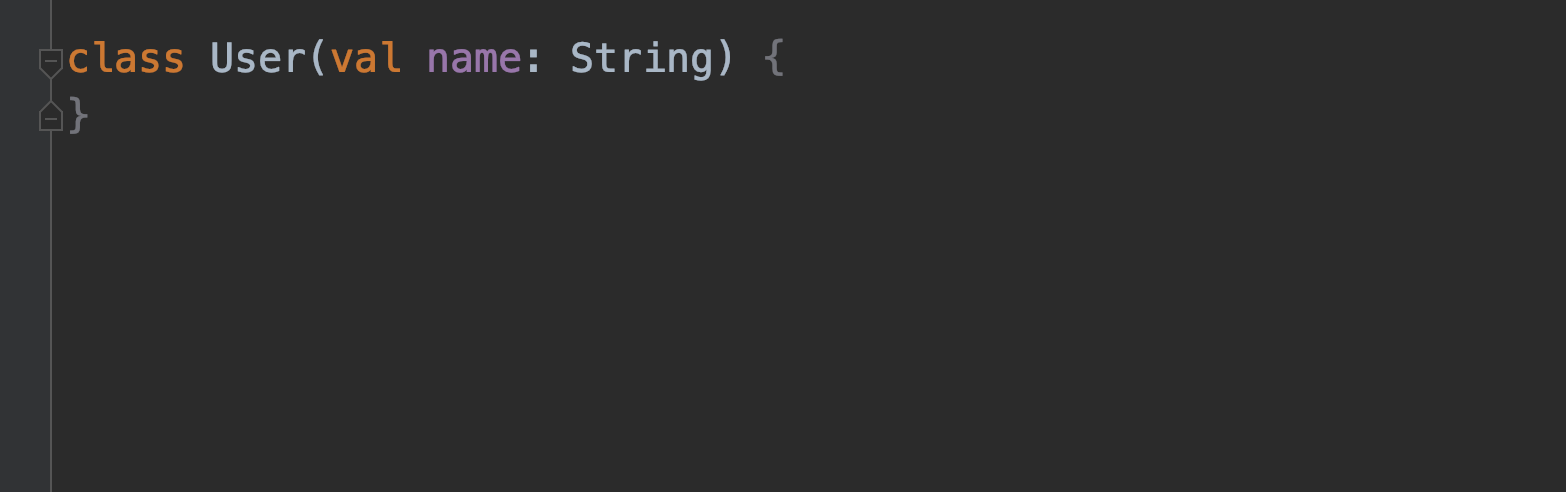
このように記述にたどり着けます。さらに、クラスの中身が空なので{ } も不要であるという提案もしてくれます。
また、IntelliJ IDEAにはJavaのコードをKotlinのコードに自動変換してくれる機能もあります。コード変換の範囲はプロジェクト全体でもファイル単体でもいいですし、JavaのコードをコピーしてKotlinのソースにペーストすればKotlinに変換できるような機能もあります。自動変換なので人間の手直しが必要になる部分もありますが、それでも十分に役立つはずです。以下に簡単なサンプルを示します。
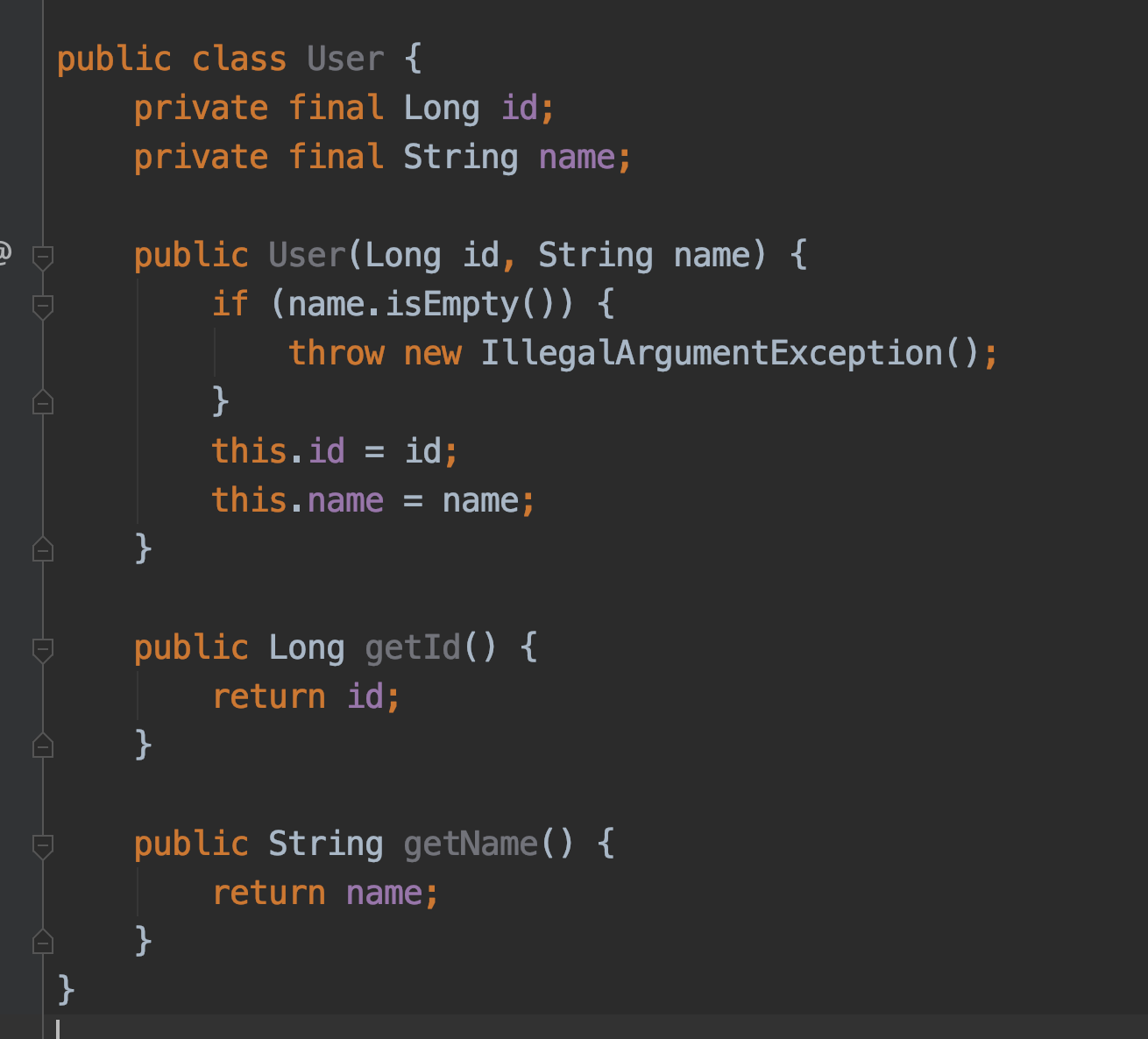
これは、ごくシンプルなJavaのコードですが、IntelliJ IDEAならばワンクリックで以下のようなKotlinコードに自動変換してくれます。
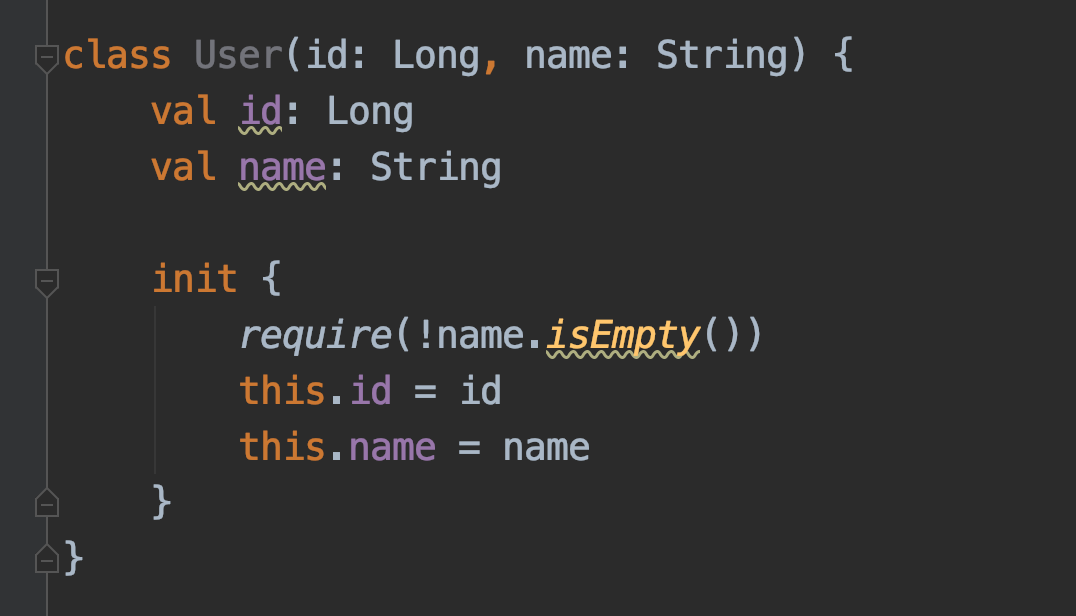
こちらの自動変換されたコードでも十分使用できますが、isEmptyメソッドの呼び出し結果の反転は、Kotlinの標準ライブラリが提供する拡張関数isNotEmptyに置き換え可能です。この点を考慮すると、以下のような記述に整理できます。
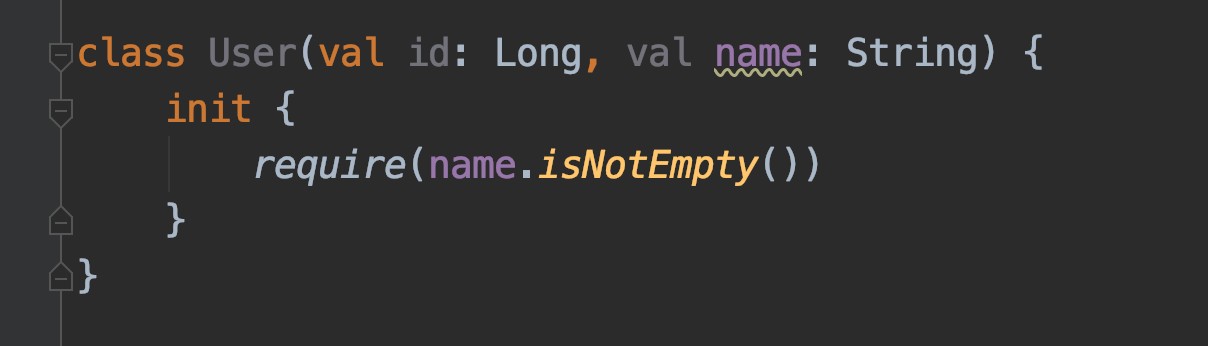
コンストラクタ引数からプロパティへのセットを、手動で簡略化してみました。このように、自動変換といっても、実用を意識すると手直しが必要になってくる部分はあります。それでも、Kotlinを触り始めたばかりの方にとっては、JavaからKotlinにスイッチするための大まかなガイドラインを学ぶうえで非常に便利です。
KotlinとIntelliJ IDEAはどちらも開発元がJetBrainsなので、非常に相性が良いです。Kotlinの新しいバージョンが出たら対応するプラグインも即座にリリースされますし、古いバージョンのKotlinから新しいバージョンのKotlinへと自動的にマイグレーションできる機能もあります。
どんなプラットフォームでも、Kotlinが動く世界に
——今後、Kotlinはどのように発展していくと思いますか?
長澤 Kotlinの次のバージョンである1.4では「今後、Kotlinが動くプラットフォームをさらに広げていく」と予告されています。既にKotlinはJVMやAndroidだけではなく、JavaScriptやiOSなどでも動くようになっていますが、その領域をより拡大していく方針です。Kotlinを学んでおけば、さまざまな領域でその知識を活かせます。
それに、JetBrainsはKotlinに本気で注力していますから、言語のパフォーマンスやコードの品質などはより向上していくはず。さらに便利な言語になっていくと思います。

——今後の発展が楽しみです! では最後に、これからKotlinに携わる方々にメッセージをお願いします。
長澤 Kotlinに興味を持たれた方は、ぜひコミュニティにも参加してみてください。例えば、GitHub上のKotlinコミュニティKEEP(Kotlin Evolution and Enhancement Process)では、Kotlinに取り込むべき仕様について世界中の人々が活発に議論しています。また、年に1回のペースで開かれている、Kotlin公式の海外カンファレンスであるKotlinConfは、気軽に参加はできないかもしれませんが、情報をフォローしていくと面白いはずです。
また、日本国内には私が運営に携わっている日本Kotlinユーザグループというコミュニティがあり、勉強会やカンファレンスなどを定期的に開催しています。Kotlinについて勉強したり、情報発信したり、ユーザー同士で交流できる場所を用意しています。ぜひ気軽に、Kotlinに触れてみてください。
取材・執筆:中薗昴




