
AWS導入~スケールまでの変遷を事例に学ぶ - コンテナ化のために「みてね」が選んだ構築戦略
これからAWSを導入する、AWSに入門するといった方に向け、AWSの導入のための基本的な戦略や考え方を事例で紹介します。多岐にわたるAWSの機能をいかに活用するか。サービス立ち上げから、その後のスケールまで、実際の現場でどのようにAWSを活用しているかを、株式会社ミクシィで「みてね」のインフラをリードする清水勲さんが語ります。
今や全世界のWebを支えるクラウドとして欠かせない存在となったAWS(Amazon Web Services)。さまざまな規模、目的のWebで活用されている中、持続的・永続的なサービス設計・開発・運用をするには、日々の情報収集と、時代に合わせたアップデートが求められます。
今回、株式会社ミクシィが提供する「家族アルバム みてね」でのAWS活用事例をもとに、AWS活用のヒントと勘所を一緒に探りましょう。
みてねは2015年4月にリリースされ、2019年11月現在、600万ユーザを突破し、日本国内だけではなく、海外での利用も増え続けている写真・動画共有サービスです。その急速な成長は、安定・堅牢なインフラが支えています。
今回お話を伺ったのは、株式会社ミクシィ みてねのSREとしてサービスのインフラ管理をリードする清水勲(しみず・いさお/ 
これからAWS導入を検討している担当者、また、スケールにおけるポイントを知りたいエンジニアへ、最新ノウハウをお届けします。

清水 勲さん:株式会社ミクシィ みてね事業部 開発グループ SRE 。2003年にSIerに入社。その中で自社プロダクトの開発チームに参加し、Webアプリケーション開発に関わる。その延長として2009年にAWSに触れ、インフラエンジニアとしてのキャリアを積む。2011年、株式会社ミクシィに転職。SNS「mixi」のインフラ運用チームとして、基盤開発・運用保守を行う。その後、2014年にモンスターストライクチーム、2018年2月に現在のみてねチームに異動し、SREとして活躍する。
- 安定・堅牢なインフラが支える「みてね」。AWS導入の背景
- 次のフェーズに進むためのアーキテクチャ変更へ
- みてねコンテナ化への道~AWS機能のアップデートとコンテナ化のメリット
- ここだけは押さえておきたい!AWS導入にあたってのポイント2020
- 【まとめ】みてねのAWS選択時のポイント
- 2020年に向けて、これからのみてねのインフラとAWS
安定・堅牢なインフラが支える「みてね」。AWS導入の背景
―まず、現在のみてねにAWSを導入した背景について教えてください。
清水 私自身、AWSに触れたのは今から約10年前、前職時代にあるプロダクトを試作する際、サーバにAWSを選んだのがきっかけでした。その当時のAWSは、現在ほど多様な機能はなく、AWS=EC2というイメージの中、オンプレミスではない選択肢として、また、スモールスタートがしやすい環境として注目を集め始めていました。
その後、ミクシィへ入社したのですが、当時はまだ、みてねはもちろん、モンスターストライク(ミクシィが提供するゲームアプリ)もなく、SNS「mixi」のインフラエンジニアとして、サーバ運用管理に関わっていました。そして、モンストチームを経て、2018年2月に現在のみてねチームへ配属されています。
ですから、私自身はみてねの立ち上げに直接関わっていはいないのですが、みてねの開発メンバーの1人がAWSの経験者であったこと、そして、他の選択肢がある中で、開発のしやすさ、規模感、コストなどがマッチしたことが、AWS選択の理由になったと聞いています。
AWSを選択した決め手になったのは次の二点だと言えますね。
- スモールスタートで立ち上げやすい
- ブログや文献など、AWSのノウハウに関する情報量が多い
ミクシィとしては、mixi、モンストと非常に大規模なサービスの開発、運用経験がある中、サービス初期からAWSを使った「みてね」は、それらとはまったく異なる運用管理体制になります。また、ゼロベースのプロダクト開発だったという点からも、AWSを選んだというのは、私自身も納得できます。
次のフェーズに進むためのアーキテクチャ変更へ
―AWS採用の背景は、いわゆるスタートアッププロダクトとして王道であったと言えますね。その後、現在はみてねの次のフェーズに向けて新しい取り組みに進んでいると伺いました。そのあたりについて詳しく教えてください。
清水 最新の取り組みの前に、これまでのみてねのアーキテクチャや開発体制について説明します。
みてねはインフラにAWS、サーバサイドにRuby on Railsを採用したサービスです。ユーザ向けのクライアントはiOS/Android(スマートフォンアプリ)およびPC(Webブラウザ)となります。
2019年11月現在、ユーザ数は600万人を超え、日本をはじめ、多言語対応により北米や欧州などワールドワイドで展開しています。
現在のみてねは、大きく3つのエンジニアチームに分かれています。
- アプリ開発チーム(クライアントサイド/サーバサイド)
- コンテンツ開発チーム(AIおよび機械学習によるサービス開発)
- SREチーム(サービス全体の運用保守改善)
私が所属するのがSREチームです。
開発当初は数名のエンジニアによる力技開発
みてねの開発を始めた当時はエンジニアの数は少なくて、チームも複数に分かれておらず、3、4名がフルスタック(すべてを担当する)エンジニアとして、日々開発に取り組んでいました。実は、つい最近(ユーザ数300万人)ぐらいまでは、エンジニアはほぼ全員フルスタックの開発をしていました。
その後、ユーザ数が400万人に近づいたころから、クライアント/サーバサイド開発以外のインフラの運用保守、SREが必要となり、現在の体制になっています。
サービスの規模とクオリティ向上に向けての取り組み
そして、エンジニアチームが細分化し、これからのみてねを考える際に、アーキテクチャの見直しをすることになりました。そのころ、世の中的には、DockerやKubernetesを活用する、いわゆるインフラのコンテナ化が主流になり、また、サービス開発においても、マイクロサービス化の動きが活発になってきたように思います。ちょうど2018年初頭ぐらいでしょうか。
そして、2018年4月、私が主導する形で、みてねのインフラにおけるコンテナ化がスタートしました。

みてねコンテナ化への道~AWS機能のアップデートとコンテナ化のメリット
―なぜ、コンテナ化をすることになったのでしょうか? ただ流行っているからという理由以外に、みてねの中で顕在化した課題、また、そのときに考えた、次のフェーズでのみてねのインフラ像など、詳しく教えてください。
清水 みてねが2015年にリリースされてから4年が経ち、この間、さまざまな技術トレンドが生まれました。開発当初は最適と思って採用した技術の中には、その後、開発が停滞したり、主流ではなくなった技術もあります。
みてねのコンテナ化移行を決めた一番の理由が、これら使用している技術(OpsWorksやChef)の外的要因(時代遅れ化)です。
OpsWorksは、ChefやPuppetなどのマネージド型インスタンスを利用できるようになる、AWSで用意されている構成管理サービスで、みてねの開発プラットフォームであるRuby on Railsとの相性が良い機能として、開発当初から採用していました。
サービス立ち上げ時のエンジニアの数が少ない場合であれば、採用する技術への合意も早く、また、多少の困難(技術に対する理解度や仕様の共有)も、エンジニア同士で解決できます。
しかし、みてねのサービス拡大とともに、開発する機能の多様化、関わるエンジニアの数の増加により、開発・運用・保守体制について見直す必要性が出てきました。その1つの答えが、3つのチームへの細分化です。
加えて、OpsWorksのアップデート速度の低下、Chefレシピファイルの複雑性やメンテナンスコスト、デプロイ時間の増加などにより、サービス拡大に対して、技術自体がボトルネックになってしまったのが、コンテナ化へ移行するきっかけでした。
コンテナ化移行前のみてねのインフラアーキテクチャ。
どのようなアーキテクチャへ移行するかを検討した結果、私自身のその当時の知見や周囲の技術トレンドから「コンテナ化」が良いのではと考えました。次のようなメリットがあったからです。
- デプロイが早くなり、結果としてユーザメリットにつながる
- 開発スピードを上げられる
- スポットインスタンスの活用などから、コストも下げられる(サーバに対しての集積度が高まる)
さらに、サービス拡大時にもう1つ重要な、エンジニアの確保という点でも、コンテナ化はメリットがあります。というのも、採用活動をする際、必須の技術としてOpsWorksに限定するよりも、コンテナ技術としたほうが、採用可能性のあるエンジニアの数が増えるからです。
―現在、みてねインフラのコンテナ化はどのぐらい進んでいますか?
まだ移行真っ最中です。
具体的に動き出したのが2018年4月頃から、私が中心となって移行作業に入ったのですが、コンテナ化のメリットについては、私自身は理解している一方で、みてねのプロジェクトチーム全体に理解してもらうには少し時間がかかったのを覚えています。そのため、コンテナ化がもたらすメリットについて、非エンジニアのメンバも含むチーム内に向けたドキュメント作りなど、チームに向けてプレゼンテーションを行いました。
開発とは直接関係ないと思われるかもしれませんが、チームで開発し、運用保守をしていくのであれば、メンバ間の合意形成と共有は必須ですし、また、ドキュメントを準備することで、自分自身の理解や新しい発見にもつながりました。
そして、ようやくコンテナ化が動き出しました。このときAWSにはAmazon ECSとAmazon EKSの2つのコンテナサービスがあり、どちらを選ぶか、悩みました。
ただ、世の中の流れとして、Kubernetesへの注目度が高まり、現在オープンソースとして開発され、継続的に改善もされ、多くのエンジニアが関わり様々な情報もアウトプットされていることから、Kubernetesを使える、Amazon EKSを採用しています。
Kubernetesは、マイクロサービス化のプラットフォームとしても、開発やメンテナンスのしやすさ、開発チームの作りやすさといった点で人気があり、これからのWebサービス・プロダクト開発を担う技術になっていくのではないでしょうか。
2019年11月現在、まさにコンテナ移行の最終段階で、2019年度内には、OpsWorksからAmazon EKSへ完全移行できるよう目指しています。
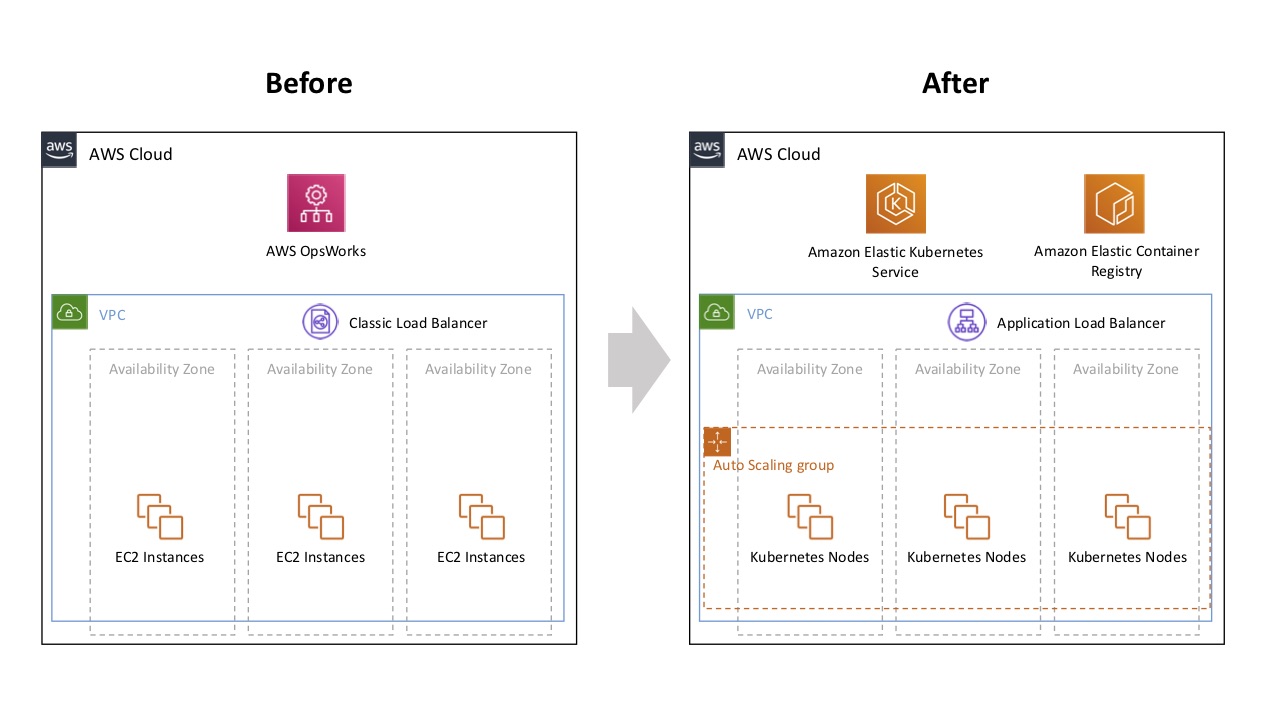
清水さんによる、みてねインフラのビフォー / アフター図。
コンテナ化移行の背景に関しては、AWS Summit 2019で発表させていただき、以下の資料が公開されていますので、併せてご覧ください。
ここだけは押さえておきたい!AWS導入にあたってのポイント2020
―サービスの成長の裏側には、活用する技術の最新動向をキャッチアップしながら、SREとしてAWSをはじめとしたインフラ技術やシステムのアップデートを行っているのですね。ここで、今後AWSを活用し、サービス開発・運用を考えているエンジニアの方へ、清水さんが考えるAWS導入のポイントを教えていただけますか。
清水 今お話したように、インフラのコンテナ化、プロダクトのマイクロサービス化は、2019年現在のWebサービス・プロダクトの主流です。ですから、この流れに乗ることは、技術的観点から見ても、情報量の多さ、エンジニアの確保のしやすさなど、さまざまな面でメリットがあります。
一方、コンテナ化だけで見れば、実はAWSでなければいけないというわけではありません。他のIaaSクラウドサービスなど、KubernetesやDockerを活用できる環境であれば良いわけですから。
では、なぜ私たちがAWSでコンテナ化を進めたかというと、すでにAWSを理由していたことやAWSにコンテナ技術が実装されていたことに加えて、みてねというサービスにおいて、核となるストレージサービスにS3(AWSのクラウドストレージサービス)を使用している点が挙げられます。S3をそのまま使いながら、コンテナ化移行をしやすいという非常に大きなメリットがあったからです。
その他、私が考えるAWSのメリットは、AWSを中心としたエンジニアコミュニティが成熟し、進化し続けている点、そして、オンライン・オフラインとも活発に活動している点です。AWSコミュニティで活動するエンジニアたちと情報交換・共有しやすい環境がある、というのは、私たちがAWSを使い続けている理由の1つでもあります。
他にも、AWSは設計の仕方、運用方法によってコスト調整がしやすい点も、AWSを選ぶ理由として挙げておきたいですね。この点は、汎用的なノウハウにはしづらい部分ですが、自分たちが運用保守を行っているサービスをきちんと理解し状況に合わせていくことで、サービス運用コストを抑えることができます。
ただ、本質としては、エンジニアが使いやすい技術、クラウドを利用することが、そのエンジニアが開発するサービスにとって一番良いことであることは、改めてコメントいたします。

【まとめ】みてねのAWS選択時のポイント
サービス立ち上げ期
- スモールスタートで使える機能を選ぶ
- 開発構想段階で潮流となっている技術を選び、AWSとの相性を考える
- 自分(エンジニアチーム)の扱いやすい言語/環境との相性を見る
- AWSコミュニティに参加し、情報を収集する
サービス成長期
- AWS新機能への情報アンテナを高く持つ
- 自社のサービスの分析を継続的にきちんと行い、機能ごとのコスト意識を持つ
- ユーザ環境の進化に合わせて、AWSおよびインフラのアップデートを考える
2020年に向けて、これからのみてねのインフラとAWS
―最後に、2020年に向けて、清水さんが考えているビジョン、また、みてねのインフラの目指すものを教えてください。
清水 まずは、コンテナ化を完全に終え、コンテナ化されたインフラの上で、みてねの安定した運用を行っていきます。
コンテナ化が完了すればサービス開発のスピードがさらに上げられますし、ユーザの皆さんの期待にも迅速に応えられるようになります。みてねのように、画像や動画など、大容量かつ大規模な生データを扱うサービスにとって、安定したデータ管理とデータ処理パフォーマンスの向上は非常に重要で、サービスの質に直結します。
また、いまAWSに期待しているのが、AWS Media ServicesとAWS 機械学習ソリューションです。
AWS Media Servicesのラインナップの1つであるAWS Elemental MediaConvertは動画変換機能を提供するサービスで、保管するメディアを最適な形に変換し、管理できるようになります。ただ、現在は、私たちのような個人向けサービス用に用意されたものではなく、映像・放送サービス向けの面が強いので、今後、私たちのようなサービスにも適した機能と料金体系が実装されてくれることに期待したいですね。
AWS 機械学習ソリューションの1つであるAmazon SageMakerは、AWSに用意されている機械学習モデルの構築、トレーニング、デプロイ手段を提供する機能です。
みてねには現在「1秒動画」という、ユーザ自身がアップした写真を1秒の動画に自動でまとめて閲覧してくれる機能をご用意しています。Amazon SageMakerは1秒動画作成の際に利用しています。みてねユーザの方々がアップロードした写真群を、サービス側で自動的に、ユーザにとって最も快適な形で提供できるよう、AWSの機械学習ソリューションを活用していきたいです。
このように、AWSはインフラだけではなく、サービスとも密接に関わる機能が多数ありますし、日々、新しい機能も増え続けています。これからも、SREとして、インフラに加えて、インフラ以外の技術に関しても、新しい情報をキャッチアップし、たくさんの方に使っていただける「みてね」を提供していけるよう、取り組んでいきたいです。
―ありがとうございました。
取材・文・構成:馮富久(株式会社技術評論社)




