
実践データサイエンス─サンプルコードと図表で学ぶ、前処理・モデル評価・パラメータチューニング
実践とともに、データサイエンスに入門しよう!敷居が高いと思われがちなデータサイエンスですが、データの前処理からの手順は意外とシンプルです。本記事では、データの前処理や特徴量の作成、モデルの評価・訓練、ハイパーパラメータの調整など、基本的な知識をサンプルコードと図表を見ながら学びます。
データサイエンティストとしてのスキルを向上させるには、データの前処理や特徴量の作成、モデルの評価・訓練、ハイパーパラメータの調整など、広域にわたる知識を身に付ける必要があります。
この記事は、そうした知識を「サンプルコードと図表を見ながら、分かりやすく学習できること」を目指して作成されました。記事内では、新米データサイエンティストのOさんが登場して、ある案件のデータ分析を担当します。読者のみなさんも、ぜひOさんと一緒にプログラムを書き、問題を解いてみてください。
それでは、データサイエンスの基礎知識を学んでいきましょう!
- ストーリー:新米データサイエンティストOさんの挑戦
- 分析を始める前の準備
- 1. データを理解する
- 探索的データ解析(Exploratory Data Analysis)
- 2. 特徴量の作成
- 3. モデルの評価方法を決める
- 4. モデルの訓練
- 5. ハイパーパラメータの調整
- 6. テストデータで確認する
- まとめ
ストーリー:新米データサイエンティストOさんの挑戦
新米データサイエンティストのOさんは、あるサービス(保険、不動産、ECサイトなど)を運営している会社のデータサイエンティストです。ある日、営業担当者から次のような相談を受けました。
「最近出した複数の新商品をお客さまにおすすめしているのだが、買ってくださる方とそうでない方がいる。データ分析をして、新商品を好みそうなお客さまを見つけることはできますか?」
よく話を聞いてみると、「新商品を購入する確率が高いお客さまに対して、優先的に売り込みたい」ことが分かってきました。「これはデータサイエンティストが得意な問題だ」と感じたOさんは、この問題に取り組んでみようと決意しました。ちなみに、今は営業担当者の経験と勘と度胸でおすすめしているようです。
Oさんは、この問題は機械学習でいうマルチクラス分類やマルチラベル分類、レコメンド問題など複数の方法で解決できるのではと考えました。しかし、このような案件を担当するのが初めてだったOさんは、まずはこれを簡単な問題に落とし込み、果たして解ける問題なのかどうかを確認しようと思いました。
Oさんは、以下の入力と出力の関係性を導くことができれば、新商品の購入有無を予測できると考えました。
- 入力:ユーザー情報、過去の商品購入情報
- 出力(予測対象):新商品の購入有無
この関係性を学習できれば、「どういったお客さまが新商品を買ってくれそうか?」「どの商品を買っていたお客さまが新商品を好んでくれそうか?」が分かりそうです。新商品を好みそうなお客さまに、優先的におすすめすることが可能になります。
検討の結果、下記のような二値分類の問題に落とし込みました。
- ユーザー情報と過去の商品(Item A~I)の購買履歴データを使って、現在の商品の購入有無を予測する
- まずは簡単に、現在購入可能な1つの商品(Item X)の予測ができるかどうかを確認する
これを専門的に言うと「Item Xの購入有無の予測(二値分類)」となります。
この問題を解くため、Oさんは以下の方針で進めようと考えました。
- データを理解し、分析・前処理をする
- 予測に有効そうな特徴量を作成する
- モデルの評価方法を決める
- モデルを訓練する
- チューニングをして、モデル精度を高める
- 新たなデータで予測結果を確かめる
さて、Oさんはそれぞれのタスクをどのように解決していったのでしょうか? 1つずつ見ていきながら、データサイエンスの世界に飛び込んでみましょう!
分析を始める前の準備
データを分析する前に、いくつか準備することがあります。
データセットの用意
まずは、データセットの用意です。Oさんはデータエンジニアと協力して、下記のようなデータセットを作成しました。
- user_table.csv
-
- 新商品(Item X)を売り込みにいったユーザーの情報が入ったテーブル
- 欠損値がある
- 重複するデータもある(データ収集ミスなどが原因)
- historical_transactions_AtoI.csv
-
- 過去購入可能だった商品 Item A~I に関する購買履歴のテーブル
- 過去に何も購入していないユーザーはデータが存在しない
- historical_transactions_X.csv
-
- 現在購入可能な商品 Item X に関する購買履歴のテーブル
- 過去に何も購入していないユーザーはデータが存在しない
※コードを実際に手元で確かめたい場合、データセットは下記にあります。

分析に使用するPythonライブラリの用意
今回、Oさんが分析に使用するPythonライブラリは以下の通りです。
| ライブラリ | 用途 |
|---|---|
| numpy | 行列の取り扱い |
| pandas | 表の取り扱い |
| scikit-learn | 機械学習 |
| matplotlib | グラフの描画 |
| seaborn | グラフを綺麗にする |
| category_encoders | カテゴリ変数の変換 |
読者のみなさんの環境で入っていないライブラリがあれば、次のコマンドを実行してインストールしてください。
$ pip install -U [ライブラリ名]
次のように、全てのライブラリを一括でインストールすることもできます (既に入っているライブラリのバージョンが上がるため、不都合がある場合は個別にインストールしてください)。
$ pip install -U numpy pandas scikit-learn matplotlib seaborn category_encoders
1. データを理解する
データサイエンスにおいては一般的に、データの特性をつかみ、仮説と検証を繰り返すことでモデルを改善していくというプロセスが取られます。本章ではその第一歩として、データの基本的な情報を確認することから始めましょう。
基本構成の確認
まず、各データの構成から確認していきましょう。データを読み込んだ後、各データのカラム構成を確認します。
# データ処理のためのライブラリ import numpy as np import pandas as pd # 可視化用のライブラリ import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns sns.set() sns.set_style(style='dark') # 1セルの実行結果を複数表示するための便利設定 from IPython.core.interactiveshell import InteractiveShell InteractiveShell.ast_node_interactivity = "all"
# データの読み込み users = pd.read_csv('user_table.csv') historical_transaction = pd.read_csv('historical_transactions_AtoI.csv') X_transaction = pd.read_csv('historical_transactions_X.csv')
# 各データの中身確認(最初の3つ) users.head(3) historical_transaction.head(3) X_transaction.head(3)
それぞれ次のようになります。
| user_id | name | nickname | age | country | num_family | married | job | income | profile | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14742 | Richard Chen | kathryn77 | 20.0 | NaN | 1.0 | 0.0 | Human resources officer | 394.0 | Last sit star physical accept. Actually relate... |
| 1 | 21530 | Kayla Garcia | brandtalexander | 59.0 | Saint Kitts and Nevis | 4.0 | 0.0 | Teacher, early years/pre | 370.0 | Door entire as. Whose suddenly mission hold.\n... |
| 2 | 34985 | Troy Blackwell | richardfarmer | 44.0 | Iraq | 3.0 | 2.0 | Forensic psychologist | 326.0 | Writer drug a tax. Team standard both write pr... |
| user_id | price | num_purchase | item | |
|---|---|---|---|---|
| 0 | 0 | 867 | 3 | C |
| 1 | 0 | 947 | 2 | F |
| 2 | 0 | 815 | 2 | D |
| user_id | price | num_purchase | item | |
|---|---|---|---|---|
| 0 | 1 | 137 | 1 | X |
| 1 | 7 | 137 | 1 | X |
| 2 | 9 | 137 | 1 | X |
カラムの意味を理解する
カラムとは、データの列である属性(例えば、年齢や価格)を表します。今回用意したカラムは、それぞれどのような意味を持っているのでしょうか。
user_table(コード上はusers)
| カラム | 意味 |
|---|---|
user_id |
ユーザーを区別するための識別子 |
name |
名前 |
nickname |
ニックネーム |
age |
年齢 |
country |
国籍 |
num_family |
家族の人数 |
married |
0: 未婚/1: 既婚/2: 離婚 |
job |
職業 |
income |
収入 |
profile |
プロフィール |
historical_transactions_AtoI(コード上はhistorical_transaction)
| カラム | 意味 |
|---|---|
user_id |
ユーザーを区別するための識別子 |
price |
購入単価 |
num_purchase |
購入個数 |
item |
購入した商品の種類(A~I) |
historical_transactions_X(コード上はX_transaction)
| カラム | 意味 |
|---|---|
user_id |
ユーザーを区別するための識別子 |
price |
購入単価 |
num_purchase |
購入個数 |
item |
購入した商品の種類(このテーブルにはXしか入っていない) |
データ不備への対応
「与えられたデータが分析に使用しても問題ない品質かどうか?」を確認することは、地道ではありますが、非常に重要なプロセスです。
データ不備の代表的なケースとして、次のような場合が挙げられます。
- 重複が存在する
- 欠損が存在する
そもそも、これらが起きるとなぜ問題なのでしょうか。
1. 重複が存在する
データ送信システムの不具合や考慮漏れなどによって、同一の内容であるにもかかわらず、データが重複して保存されてしまうケースがあります。
データに重複が含まれていたとき、本来は同一の内容であるにもかかわらず、モデルがその部分を「新しい別のデータ」であるとして大きな比重で学習してしまい、結果的に過学習になるなど、意図しないことが生じるリスクがあります。そのため、事前に重複を削除しておく必要があります。
もちろん、もともとは別のデータにもかかわらず、偶然レコードの値が一致しているという場合には、重複を削除する必要はありません。
2. 欠損が存在する
モデルによっては、データの欠損部分をそのまま利用できない場合があります。学習に使用できる情報が少ないと、モデルの性能は低下してしまう可能性があります。
加えて、例えば最も基礎的な予測モデルの1つである「線形回帰モデル」では、欠損を含むデータはそもそも入力ベクトル(行列)として適切ではなく、そのまま使用できません。したがって、欠損に直面した際は、何らかの方法で欠損値補完を行うことがあります†。
欠損値の補完では、次のような方法が代表的です。
- 0、-1、-999で埋める(学習に含まれない値での補完)
- 各カラムの平均値で埋める
- 他のカラムを利用して推測した値で埋める
ですが、最も良い補完方法はデータごとに異なるので、試行錯誤して方法を定めるのが良いでしょう。
また、欠損に対する別の対処として、欠損を含むデータはそもそも学習に用いないという方法もあります。
†Note: データによっては、「データが欠損している」という情報自体が意味を持つことがあります。
例えば、最大1000人が参加するマラソン大会の成績データにおいて、“途中棄権”したユーザーについては「順位」カラムの値が欠損しているようなケースを考えてみましょう。この場合は「欠損している」ことを示すため、順位として取り得ない-1や1000000などの値で補完することがあります。
このように「欠損」自体を表現することが重要な場合には、下記のような補完も有効かもしれません。
- 量的データ
- 各カラムが取り得ないほど大きな、もしくは小さな値で埋める
- 質的データ
- 「欠損」カテゴリを作成する
重複データへの対処
早速、実際のデータを使って、重複の確認と、重複部分の削除を行ってみます。
users、historical_transaction、X_transactionのそれぞれについて、重複除去前・後のデータフレームの形を比較してみましょう
# 重複するデータを削除 names = ['users', 'historical_transaction', 'X_transaction'] dfs = [users, historical_transaction, X_transaction] for name, df in zip(names, dfs): print(f"{name} - shape before: {df.shape}") df.drop_duplicates(inplace=True) df.reset_index(drop=True, inplace=True) print(f"{name} - shape after: {df.shape}")
この実行結果は次のようになります。
users - shape before: (50103, 10)
users - shape after: (50000, 10)
historical_transaction - shape before: (169379, 4)
historical_transaction - shape after: (152200, 4)
X_transaction - shape before: (6444, 4)
X_transaction - shape after: (5618, 4)
各データには重複がありましたが、上記の処理によって重複部分をきちんと削除できたようですね。
欠損データへの対処
欠損値が存在した場合、どのような値で埋めるべきなのかはデータの分布や特性、データの作成仕様によっても異なります。
今回は、ある程度分析を行った後で、どのような値で埋めるかを定めます。後半パートの「欠損の確認」にて、欠損値を埋めることにします。
探索的データ解析(Exploratory Data Analysis)
分析対象データの特性を表現する値のことを、特徴量と言います。モデル性能の向上のためには特徴量の作成が必要であり、実際の業務においては、モデルの予測精度に寄与するだけではなく、その解釈可能性も求められる場合があります。
次に挙げるステップで進めると、仮説を持ちながら特徴量を作成できるため、その解釈可能性も担保しながら、モデル構築を行いやすくなります。
- データをさまざまな角度から分析して、データ傾向やデータ発生メカニズムについて仮説を持つ
- その仮説を元に、データをよりよく表現する特徴量を作成する
- 作成した特徴量をモデルに組み込んで、精度への寄与を確認する
また、仮説を持つことで新たな着想が生まれやすくなるため、やみくもに特徴量を作成するよりも、新たな特徴量のアイデアが生まれる可能性も向上するでしょう。
ここでは、1.にあたる探索的データ解析(Exploratory Data Analysis、EDAとも呼ばれる)を行い、本データがどのような特徴を持っているかを可視化してみましょう。データの特性をとらえ、特徴量に組み込んでいくことで、モデル精度の向上が期待できます。
データをより使いやすい形に
与えられたデータから、新商品(Item X)の購入有無の予測に効果的なデータの傾向を見出すため、データを結合して使いやすい形にします。
もともとhistorical_transactions_Xの列Xには、Item Xの購入個数が含まれていますが、今回はXが0(購入していない)か1(購入している)かの予測を行うため、次のように置き換えることにご注意ください。
-
X >= 1(Xを1個以上購入している)ならば、X = 1 -
X == 0(Xを購入していない)ならば、X = 0
コードは次のようになります。
# Item A~I それぞれの合計購入数を算出 pv_ht = pd.pivot_table(historical_transaction, index='user_id', columns='item', values='num_purchase', aggfunc='sum').reset_index() users_item_num = pd.merge(users, pv_ht, how='left', on='user_id') users_item_num[historical_transaction.item.unique()] = users_item_num[historical_transaction.item.unique()].fillna(0) # Item X の合計購入数を算出 pv_pt = pd.pivot_table(X_transaction, index='user_id', columns='item', values='num_purchase', aggfunc='sum').reset_index() users_item_num = pd.merge(users_item_num, pv_pt, how='left', on='user_id') users_item_num[X_transaction.item.unique()] = users_item_num[X_transaction.item.unique()].fillna(0) # Item X の値を購入有無(0,1)に書き換える users_item_num['X'] = users_item_num['X'].apply(lambda x: 1 if x >= 1 else 0).values users_item_num.head(3)
結果は次のようになります。
| user_id | name | nickname | age | country | num_family | married | job | income | profile | A | B | C | D | E | F | G | H | I | X | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14742 | Richard Chen | kathryn77 | 20.0 | NaN | 1.0 | 0.0 | Human resources officer | 394.0 | Last sit star physical accept. Actually relate... | 3.0 | 3.0 | 2.0 | 0.0 | 2.0 | 0.0 | 0.0 | 1.0 | 2.0 | 0 |
| 1 | 21530 | Kayla Garcia | brandtalexander | 59.0 | Saint Kitts and Nevis | 4.0 | 0.0 | Teacher, early years/pre | 370.0 | Door entire as. Whose suddenly mission hold.\n... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 1 |
| 2 | 34985 | Troy Blackwell | richardfarmer | 44.0 | Iraq | 3.0 | 2.0 | Forensic psychologist | 326.0 | Writer drug a tax. Team standard both write pr... | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 |
ここでは、下記のようなデータを結合しました。
- 各ユーザー(
user_id)のItemA~Iそれぞれの合計購入数 - 各ユーザー(
user_id)のItemX購入有無
また、各ユーザーについて、商品に対するデータが存在しない(つまり一度も購入したことがない)場合は、購入していないことを表す0で補完しています。
データの可視化
各カラムとXの値の関係を可視化してみましょう。各カラムの値ごとにXの平均値がどのように変化しているのかを見て、どのようなカラムが特にXに影響を与えていそうかを見ていきます。
比較的広範囲のデータ分析においては、共通するデータ操作が多いため、よくあるデータ操作については自分で関数を定義して、使い回せるようにしておくと便利かもしれません。
今回は、代表的な操作である下記の関数を用意しました。
grouping- データフレーム(
pd.DataFrame)の特定の列に対して、指定したkey(s)/value(s)での集約特徴量を計算する plot_target_stats-
groupingで作成したデータに関して、次の値に関する2軸グラフの作成を行う-
X_count:keyごとのレコード数 -
X_mean:keyごとのXの平均値
-
関数のコードは次のようになります。
def grouping(df, cols, agg_dict, prefix=''): """特定のカラムについてgroup化された特徴量の作成を行う Args: df (pd.DataFrame): 特徴量作成のもととなるdataframe cols (str or list): group by処理のkeyとなるカラム (listで複数指定可能) agg_dict (dict): 特徴量作成を行いたいカラム/集計方法を指定するdictionary prefix (str): 集約後のカラムに付与するprefix name Returns: df (pd.DataFrame): 特定のカラムについてgroup化された特徴量群 """ group_df = df.groupby(cols).agg(agg_dict) group_df.columns = [prefix + c[0] + '_' + c[1] for c in list(group_df.columns)] group_df.reset_index(inplace = True) return group_df def plot_target_stats(df, col, agg_dict, plot_config): """指定したカラムとtargetの関係を可視化する Args: df (pd.DataFrame): 可視化したい特徴量作成のもととなるdataframe col (str): group by処理のkeyとなるカラム agg_dict (dict): 特徴量作成を行いたいカラム/集計方法を指定するdictionary """ plt_data = grouping(df, col, agg_dict, prefix='') # 2軸グラフの作成 fig, ax1 = plt.subplots(figsize = (15 , 7)) ax2 = ax1.twinx() ax1.bar(plt_data[col], plt_data['X_count'], label='X_count', color='skyblue', **plot_config['bar']) ax2.plot(plt_data[col], plt_data['X_mean'], label='X_mean', color='red', marker='.', markersize=10) h1, label1 = ax1.get_legend_handles_labels() h2, label2 = ax2.get_legend_handles_labels() ax1.legend(h1 + h2, label1 + label2, loc=2, borderaxespad=0.) ax1.set_xticks(plt_data[col]) ax1.set_xticklabels(plt_data[col],rotation=-90, fontsize=10) ax1.set_title(f"Relationship between {col}, X_count, and X_mean", fontsize=14) ax1.set_xlabel(f"{col}") ax1.tick_params(labelsize=12) ax1.set_ylabel('X_count') ax2.set_ylabel('X_mean') ax1.set_ylim([0, plt_data['X_count'].max() * 1.2]) ax2.set_ylim([0, plt_data['X_mean'].max() * 1.1])
各カラムごとのレコード数とXの平均値を可視化する
上記で定義した関数を使用して、データの関係を見ていきましょう。
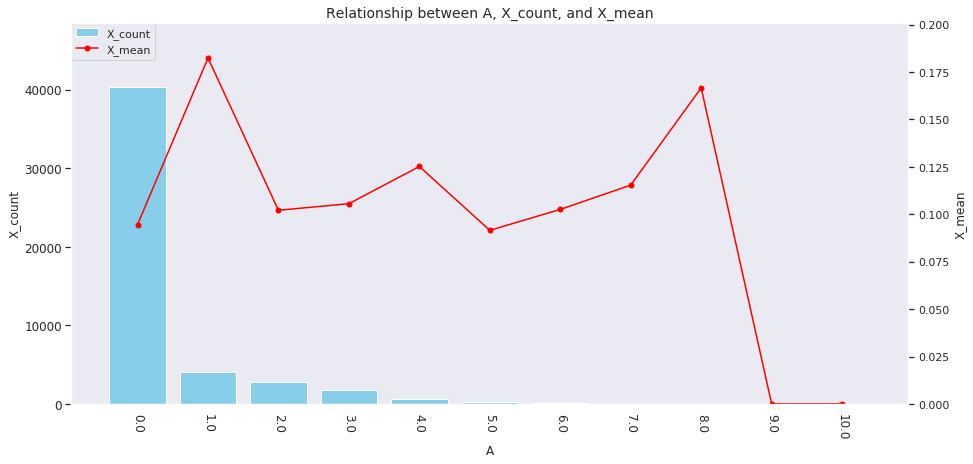
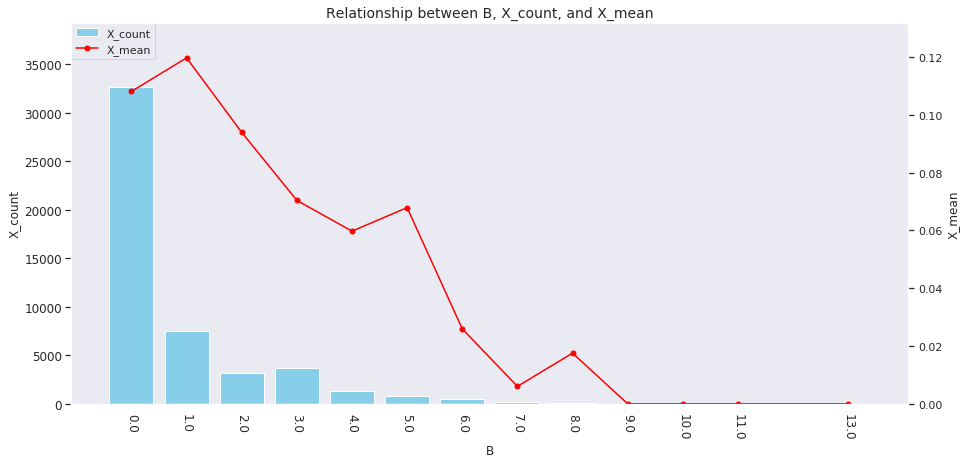
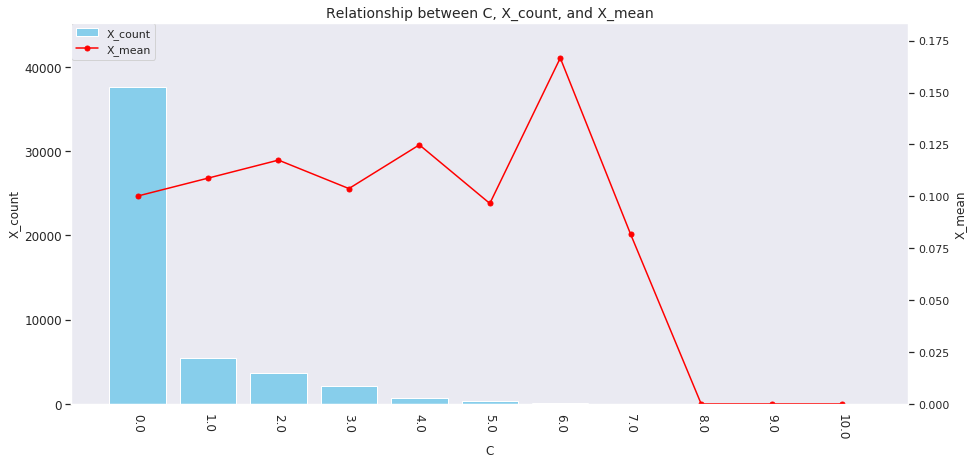
for col in ['age', 'country', 'num_family', 'married', 'job', 'A', 'B', 'C', 'D','E', 'F', 'G', 'H', 'I']: agg_dict = { 'X' : ['count', 'mean'] } plot_config = {'bar': {'width': 0.8}} plot_target_stats(users_item_num, col, agg_dict, plot_config)
各カラムとXの値の関係は、それぞれ次のようになります。
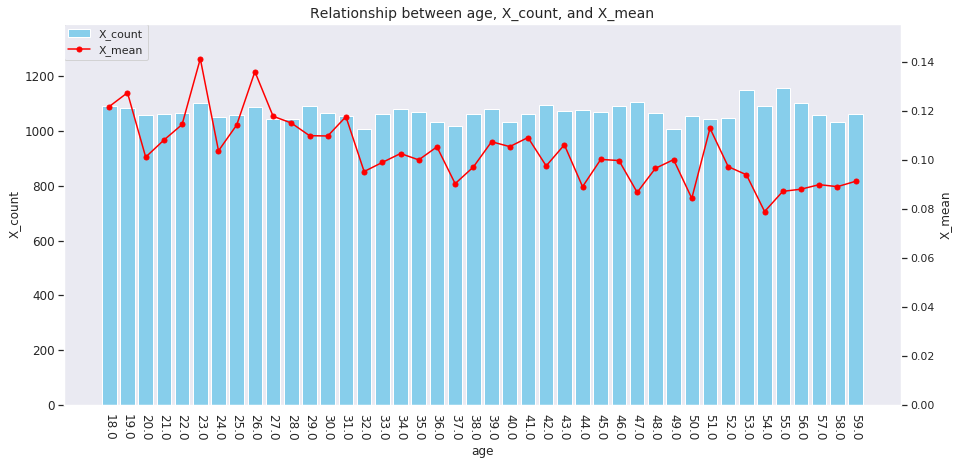
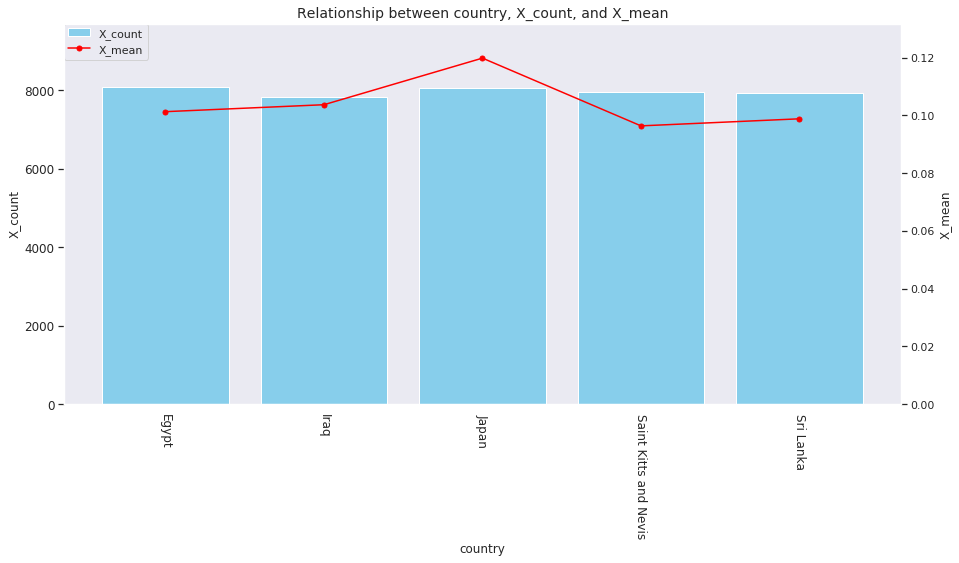
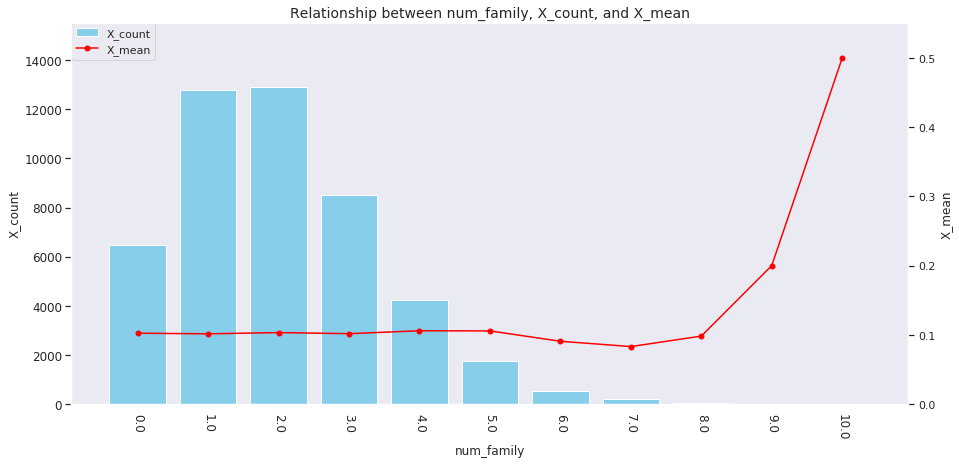
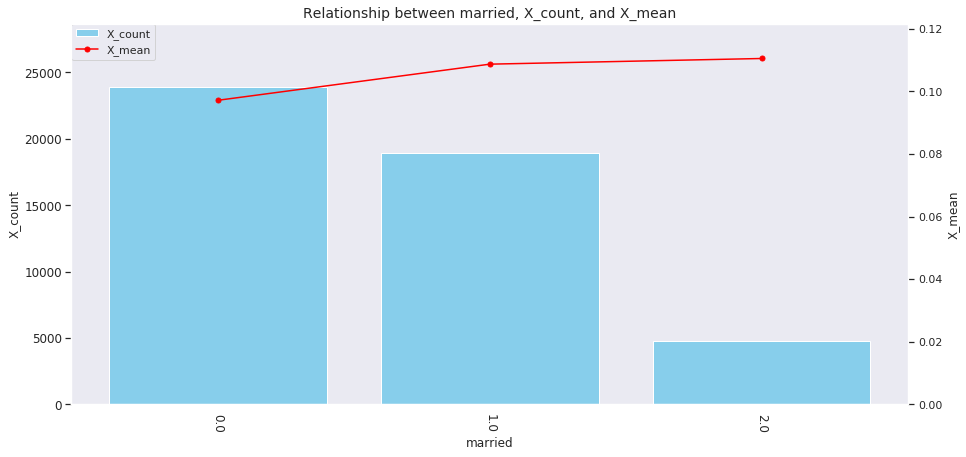
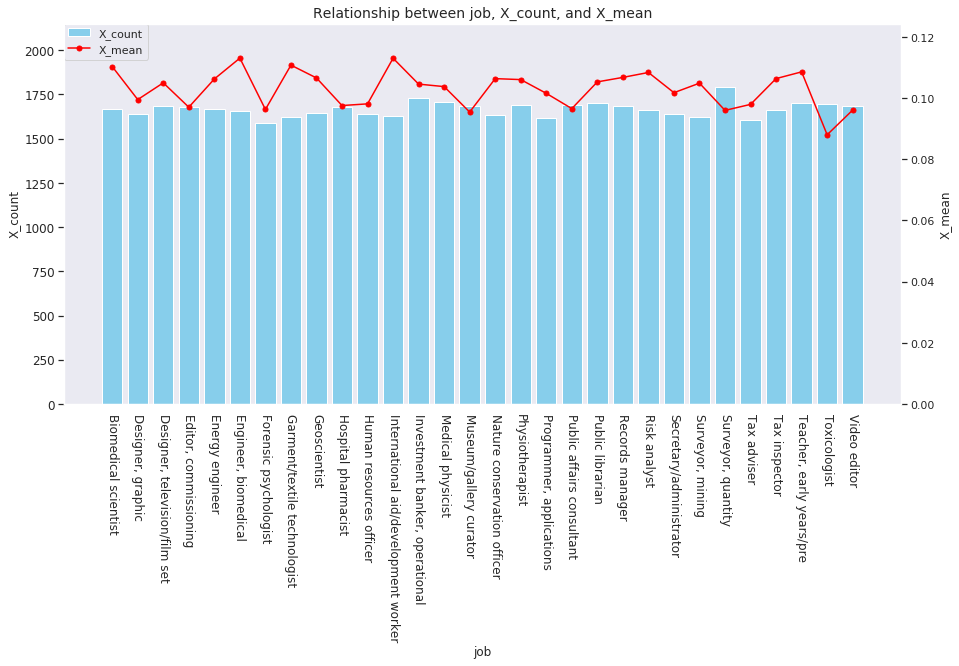
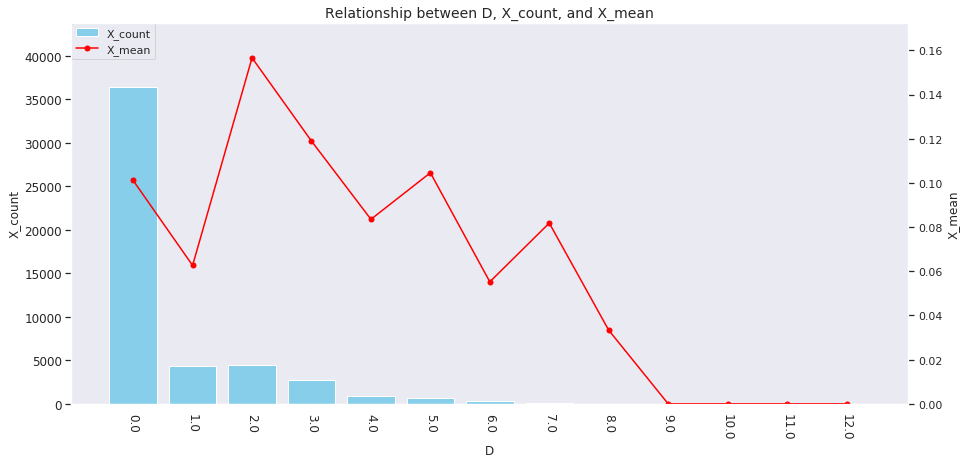
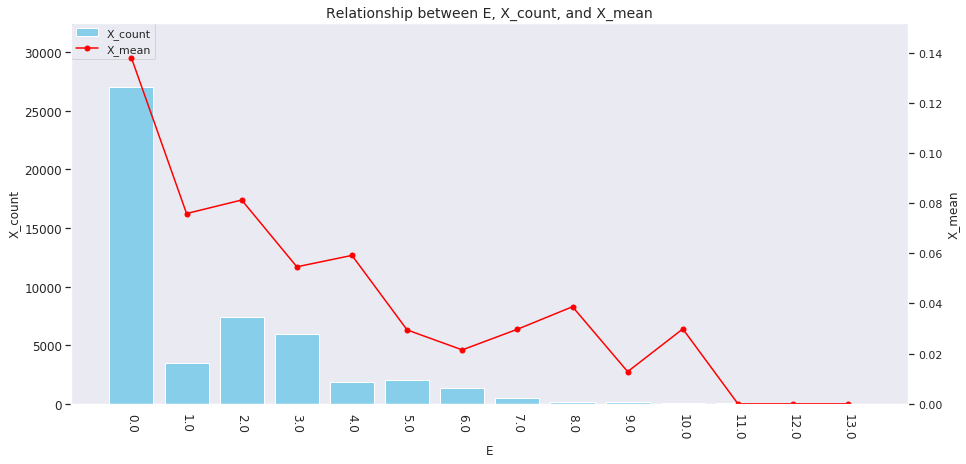
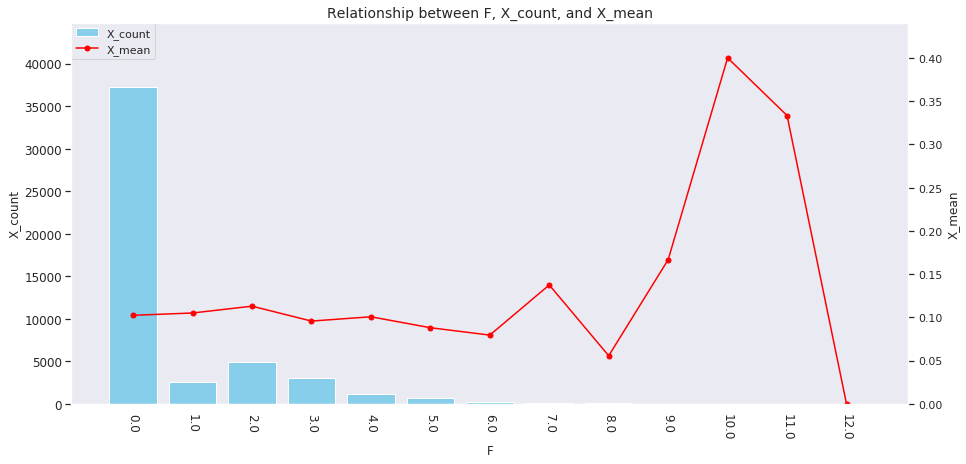
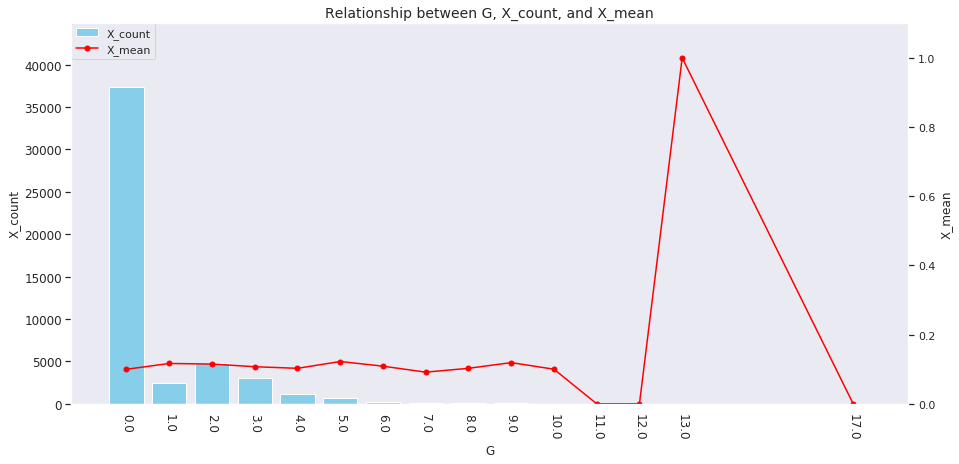
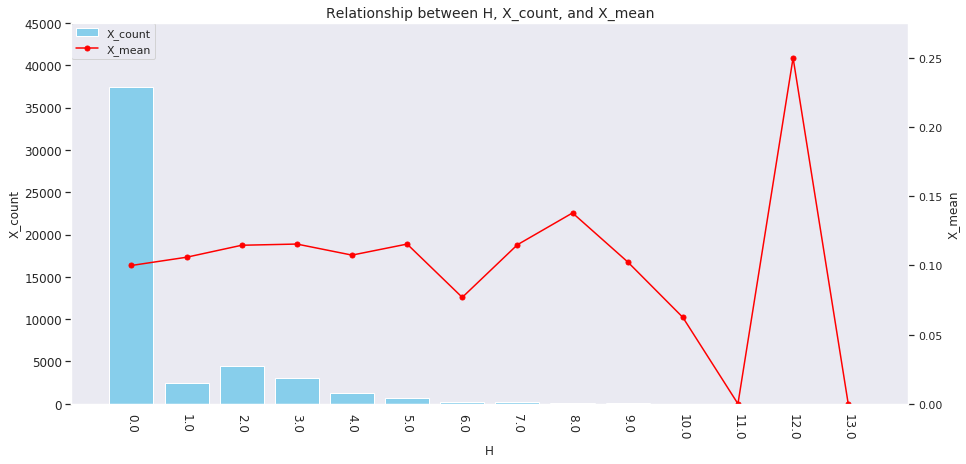
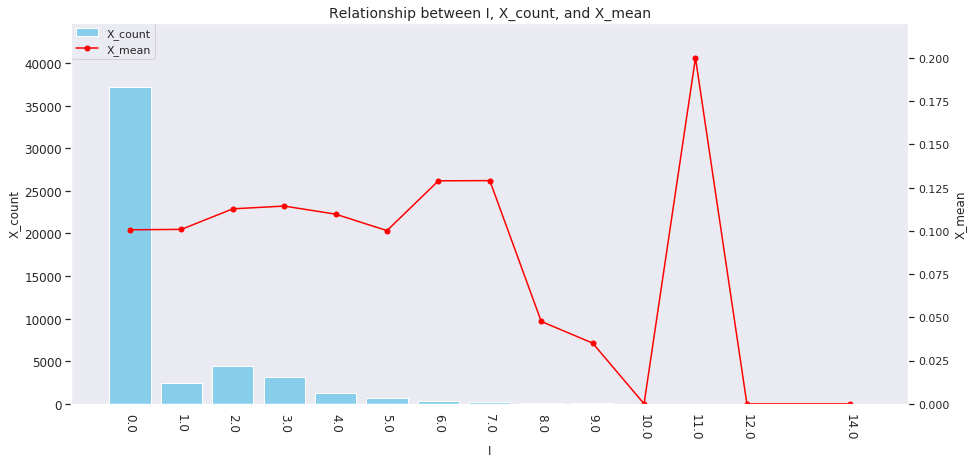
incomeは一意な値が多い連続変数であるため、100単位にまとめてXとの関係を見てみましょう。
tmp_df = users_item_num.copy() tmp_df['income_100'] = (tmp_df['income'] // 100 * 100) plot_config = {'bar': {'width': 60}} plot_target_stats(tmp_df, 'income_100', agg_dict, plot_config)
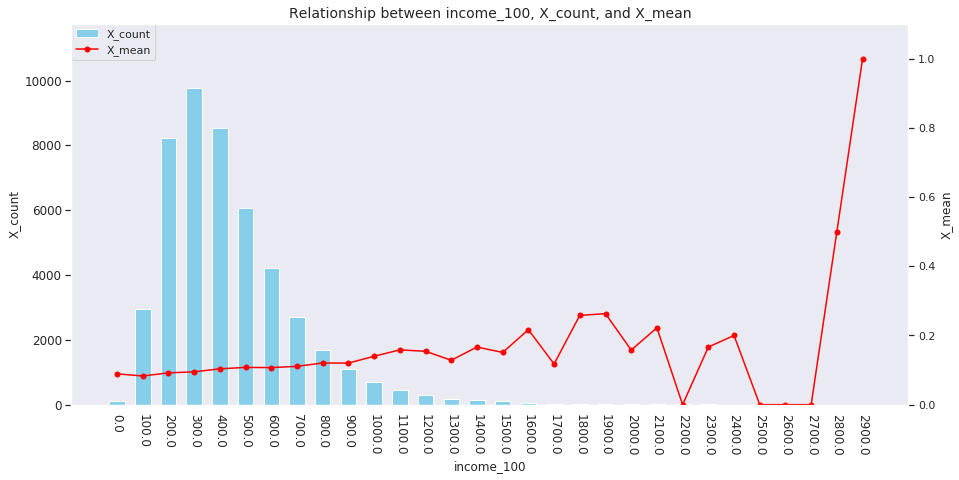
これを見ると、次のそれぞれとX_meanには関連がありそうです。
-
age、country、num_family、married、jobの値 -
A~Iの購入数 -
incomeの値
イメージしやすいincomeの例を取ると、次のような仮説が立てられます。
「
incomeが多い人ほどその分可処分所得も多いと考えられるため、Xを購入しやすい」
欠損の確認
モデルを学習させる上では、「欠損値をどのように処理するか?」も重要です。下記のように、変数の特性を踏まえて補完を行うか、あえて「欠損している」ということ自体を表す値を入れるか、などを行って対応することが多いです。
| 尺度名 | 変数の特性 | 例 |
|---|---|---|
| 名義尺度 | 区別・分類のために付与されたラベル | 受験番号 |
| 順序尺度 | 大小関係のみに意味があり、その間隔や比率には意味がない | 順序 |
| 間隔尺度 | 大小関係に加えて「差」にも意味がある (けれど「比」には意味がない) |
温度 |
| 比例尺度 | 大小関係に加えて「差」にも「比」にも意味がある | 年齢 |
また、メジャーな機械学習ライブラリ「LightGBM」のように、欠損値を含んでいても学習可能(対処可能)なモデルもありますので、柔軟に対応する必要があります。
手始めに、pd.DataFrame.isnull()で各カラムの欠損レコード数を調べましょう。
names = ['users', 'historical_transaction', 'X_transaction'] dfs = [users, historical_transaction, X_transaction] for name, df in zip(names, dfs): print("==================================") print(f"{name} : null value - counts") print("==================================") print(df.isnull().sum())
出力は次のようになります。
==================================
users : null value - counts
==================================
user_id 0
name 0
nickname 0
age 5126
country 10134
num_family 2563
married 2447
job 0
income 2519
profile 0
dtype: int64
==================================
historical_transaction : null value - counts
==================================
user_id 0
price 0
num_purchase 0
item 0
dtype: int64
==================================
X_transaction : null value - counts
==================================
user_id 0
price 0
num_purchase 0
item 0
dtype: int64
また、pd.DataFrame.info()では、カラムの型やメモリ使用量だけではなく、欠損の有無も確認できます。
for name, df in zip(names, dfs): print("==================================") print(f"{name} : info") print("==================================") df.info()
出力は次のようになります。
==================================
users : info
==================================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50000 entries, 0 to 49999
Data columns (total 10 columns):
user_id 50000 non-null int64
name 50000 non-null object
nickname 50000 non-null object
age 44874 non-null float64
country 39866 non-null object
num_family 47437 non-null float64
married 47553 non-null float64
job 50000 non-null object
income 47481 non-null float64
profile 50000 non-null object
dtypes: float64(4), int64(1), object(5)
memory usage: 3.8+ MB
==================================
historical_transaction : info
==================================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 152200 entries, 0 to 152199
Data columns (total 4 columns):
user_id 152200 non-null int64
price 152200 non-null int64
num_purchase 152200 non-null int64
item 152200 non-null object
dtypes: int64(3), object(1)
memory usage: 4.6+ MB
==================================
X_transaction : info
==================================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5618 entries, 0 to 5617
Data columns (total 4 columns):
user_id 5618 non-null int64
price 5618 non-null int64
num_purchase 5618 non-null int64
item 5618 non-null object
dtypes: int64(3), object(1)
memory usage: 175.6+ KB
上記から、age、num_family、income、job、marriedには欠損が存在することが分かりました。学習データとして使えるようにするため、これらを処理していきましょう。
欠損値をどう処理するか?
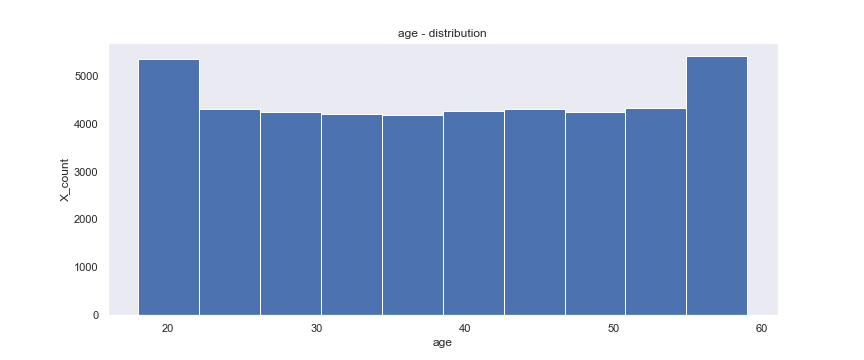
各カラムの欠損値を処理する方法を決めるために、各カラムの分布を見てみましょう。
ageとnum_familyとincomeの分布を見るコードです。
missing_num_columns = [
'age',
'num_family',
'income',
]
for col in missing_num_columns:
plt.figure(figsize=(12, 5))
plt.hist(users[col])
plt.xlabel(f"{col}")
plt.ylabel("X_count")
plt.title(f"{col} - distribution")
plt.show()
出力は次のようになります。
marriedとcountryの分布を見るコードです。
missing_cat_col = [
'married',
'country'
]
for col in missing_cat_col:
plt.figure(figsize=(12, 5))
sns.countplot(x=col, data=users, color='salmon')
plt.title(f"{col} - distribution")
plt.show()
出力は次のようになります。
さて、分布を確認したら、その特性を踏まえて欠損値を補完しましょう。補完には、次のようなさまざまな方法があります。
- 平均値で補完
- 0で補完
- 最頻値で補完
今回は、各カラムを下記のように補完してみましょう。
| 補完の方法 | カラム |
|---|---|
| 平均値で補完 |
age num_family income
|
| 最頻値で補完 |
married country
|
その他にも、国籍や職業ごとの値の分布が大きく異なる場合、それらのグループ内の平均値で埋めた方が効果的である場合もあります。実際の業務やコンペにおいては、複数の手法を試してみることをおすすめします。
age、num_family、incomeの各カラムは、平均値で補完します。: `
for col in missing_num_columns: column_mean = users_item_num[col].mean() users_item_num[col].fillna(column_mean, inplace=True)
marriedとcountryは、最頻値で補完します。
for col in missing_cat_col: column_mode = users_item_num[col].mode()[0] users_item_num[col].fillna(column_mode, inplace=True)
最頻値には複数候補があり得ますが、最も小さいインデックスで出現した要素で補完することにします。
2. 特徴量の作成
これまで見てきた内容を踏まえて、特徴量を作成していきましょう。
集約系特徴量
上述の探索的データ解析(EDA)から、age/incomeはXの予測に寄与しそうだということが分かりました。しかし、単にその値を見るだけでは分からないこともあります。
incomeが500であるユーザーを例に考えてみると、次の2つではincomeの値が持つ意味合いも異なりそうです。
-
incomeの平均値が500の国のユーザー -
incomeの平均値が100の国のユーザー
つまり、次の仮説が立てられそうです。
「
incomeの平均が高い国のユーザー(A)は、incomeの平均が低い国のユーザー(B)と比較して生活に必要な収入も高いため、AとBの収入が同じならば可処分所得は相対的に低くなる」
このように検討を進めて、今回はcountry、jobごとのincome、ageに関する基本的な統計量を特徴として加えてみましょう。
例えば、jobごとにincomeがどのような分布なのかを確認してみます。
plt.figure(figsize=(15, 7)) sns.violinplot(x = 'job', y = 'income', data = users_item_num, split=True) plt.title("Distributions of Income (job)", fontsize=14) plt.xticks(rotation=-90, fontsize=12)
出力は次のようになります。
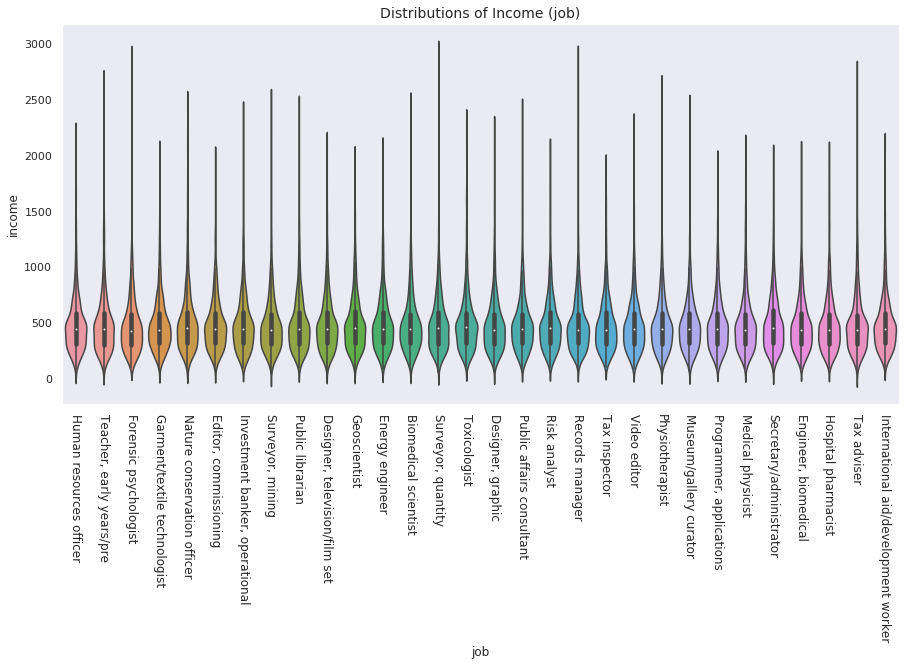
jobごとのincomeの分布は、最大値・最小値に特に大きな差がありそうです。平均や標準偏差も加えつつ、users_item_numに特徴量として追加します。
value_agg = {
'age' : ['max', 'min', 'mean', 'std'],
'income' : ['max', 'min', 'mean', 'std'],
}
for key in ['country', 'job']:
feature_df = grouping(users_item_num, key, value_agg, prefix=key + "_")
users_item_num = pd.merge(users_item_num, feature_df, how='left', on=key)
そのほか下記も、userやグループについて有用な情報となり得ます。
-
userのincome、ageが、各グループの平均income、ageからどれくらい乖離しているか -
userの家族一人あたりの収入:income/num_family - 各グループの
income、ageの分布の幅(=最大値と最小値の差)
これらを特徴として加えてみましょう
for col in ['country', 'job']: for value in ['age', 'income']: users_item_num[f'{value}_diff_mean_{col}'] = users_item_num[col +"_" + value + "_mean"] - users_item_num[value] users_item_num[f'{value}_diff_max_min_{col}'] = users_item_num[col +"_" + value + "_max"] - users_item_num[col +"_" + value + "_min"] users_item_num['income_per_num_family'] = users_item_num['income'] / (users_item_num['num_family'] + 1)
users_item_num.head()
結果は次のようになります。
| user_id | name | nickname | age | country | num_family | married | job | income | profile | A | B | C | D | E | F | G | H | I | X | country_age_max | country_age_min | country_age_mean | country_age_std | country_income_max | country_income_min | country_income_mean | country_income_std | job_age_max | job_age_min | job_age_mean | job_age_std | job_income_max | job_income_min | job_income_mean | job_income_std | age_diff_mean_country | age_diff_max_min_country | income_diff_mean_country | income_diff_max_min_country | age_diff_mean_job | age_diff_max_min_job | income_diff_mean_job | income_diff_max_min_job | income_per_num_family | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14742 | Richard Chen | kathryn77 | 20.000000 | Egypt | 1.000000 | 0.0 | Human resources officer | 394.0 | Last sit star physical accept. Actually relate... | 3.0 | 3.0 | 2.0 | 0.0 | 2.0 | 0.0 | 0.0 | 1.0 | 2.0 | 0 | 59.0 | 18.0 | 38.488919 | 11.488339 | 2638.0 | 41.0 | 481.814959 | 247.222994 | 59.0 | 18.0 | 38.871353 | 11.237528 | 2174.0 | 74.0 | 484.455412 | 253.751663 | 18.488919 | 41.0 | 87.814959 | 2597.0 | 18.871353 | 41.0 | 90.455412 | 2100.0 | 197.000000 |
| 1 | 21530 | Kayla Garcia | brandtalexander | 59.000000 | Saint Kitts and Nevis | 4.000000 | 0.0 | Teacher, early years/pre | 370.0 | Door entire as. Whose suddenly mission hold.\n... | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 1 | 59.0 | 18.0 | 38.604308 | 11.514098 | 2454.0 | 58.0 | 481.484634 | 248.547022 | 59.0 | 18.0 | 38.888917 | 11.544594 | 2638.0 | 69.0 | 487.119827 | 270.619618 | -20.395692 | 41.0 | 111.484634 | 2396.0 | -20.111083 | 41.0 | 117.119827 | 2569.0 | 74.000000 |
| 2 | 34985 | Troy Blackwell | richardfarmer | 44.000000 | Iraq | 3.000000 | 2.0 | Forensic psychologist | 326.0 | Writer drug a tax. Team standard both write pr... | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 59.0 | 18.0 | 38.416330 | 11.591621 | 2869.0 | 73.0 | 482.984206 | 252.340702 | 59.0 | 18.0 | 38.188403 | 11.751286 | 2866.0 | 97.0 | 468.473441 | 242.034700 | -5.583670 | 41.0 | 156.984206 | 2796.0 | -5.811597 | 41.0 | 142.473441 | 2769.0 | 81.500000 |
| 3 | 31854 | Suzanne Ray | nicole40 | 52.000000 | Sri Lanka | 1.999072 | 0.0 | Garment/textile technologist | 673.0 | Evidence try next degree man local. Movie sea ... | 1.0 | 0.0 | 0.0 | 1.0 | 6.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 59.0 | 18.0 | 38.795739 | 11.516541 | 2909.0 | 72.0 | 485.212130 | 253.421128 | 59.0 | 18.0 | 38.254593 | 11.481565 | 2018.0 | 73.0 | 483.005898 | 241.025513 | -13.204261 | 41.0 | -187.787870 | 2837.0 | -13.745407 | 41.0 | -189.994102 | 1945.0 | 224.402715 |
| 4 | 46689 | Susan Horn | heather38 | 38.544257 | Japan | 1.000000 | 0.0 | Nature conservation officer | 306.0 | Voice after assume hard tonight. Recent try ma... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 3.0 | 0.0 | 0.0 | 0.0 | 0 | 59.0 | 18.0 | 38.486635 | 11.489549 | 2412.0 | 78.0 | 489.089053 | 253.191859 | 59.0 | 18.0 | 38.330285 | 11.564120 | 2454.0 | 79.0 | 494.977408 | 261.818781 | -0.057622 | 41.0 | 183.089053 | 2334.0 | -0.213972 | 41.0 | 188.977408 | 2375.0 | 153.000000 |
特徴量を使用してモデルの学習を行う
ここまで、いくつかの特徴量を作成してきました。これらを使用して実際にモデルの学習を行いましょう。
学習に使用する特徴量を選定するため、事前にカラムを整理しておきます。現時点で学習に使用するデータは全てusers_item_numに含まれているため、このカラムの中から学習に使用するカラムを選定します。
| カラム | 説明 |
|---|---|
feature_num_columns |
特徴量として使用する数値カラム |
cat_columns |
特徴量として使用するカテゴリカル変数カラム |
target_column |
目的変数であるX∈ {0, 1}が入っているカラム |
なお、「∈ {0, 1}」は「0または1の値を取る」という意味です。
# train に使用するcolumnsを選択する def choose_feature_column(df, feature_cat_columns): feature_num_columns = [col for col in df.columns if col not in ['user_id', 'X'] and df[col].dtype != 'O' and col not in feature_cat_columns] return feature_num_columns feature_cat_columns = ['country', 'job', 'married'] feature_num_columns = choose_feature_column(users_item_num, feature_cat_columns) target_column = 'X'
feature_num_columns
['age',
'num_family',
'income',
'A',
'B',
'C',
'D',
'E',
'F',
'G',
'H',
'I',
'country_age_max',
'country_age_min',
'country_age_mean',
'country_age_std',
'country_income_max',
'country_income_min',
'country_income_mean',
'country_income_std',
'job_age_max',
'job_age_min',
'job_age_mean',
'job_age_std',
'job_income_max',
'job_income_min',
'job_income_mean',
'job_income_std',
'age_diff_mean_country',
'age_diff_max_min_country',
'income_diff_mean_country',
'income_diff_max_min_country',
'age_diff_mean_job',
'age_diff_max_min_job',
'income_diff_mean_job',
'income_diff_max_min_job',
'income_per_num_family']
users_item_num.drop(['user_id', 'name', 'nickname', 'profile'], axis=1, inplace=True) feature_cat_columns = ['country', 'job', 'married'] target_column = 'X'
3. モデルの評価方法を決める
前処理と特徴量エンジニアリングを終えると、さっそくモデルを作りたくなります。しかし、その前に「モデルを評価する方法」について検討しなければなりません。
この節では、本格的にモデルを学習する前に必要なモデルの評価方法について説明します。
モデルを評価するためのデータ作成
予測や分類をするモデル作成の目的は、未知のデータに対して高い精度で予測を行うことです。精度、とは便利な言葉ですが、具体的にどんな指標が良いかを定めて議論しないと意味をなしません。
この「高い精度」とは何かを、評価方法を定める中で具体的にしていきます。
やりがちなミス ~訓練データだけでモデルの性能を評価してしまう~
さまざまな場面で見かけるやりがちなミスは、訓練データだけでモデルの性能を評価してしまうことです。例えば、データセット全てを訓練データとして使って学習し、その時の精度をモデルの良し悪しの決定に使い、サービスへのモデル導入の意思決定に利用することが挙げられます。
その訓練データに対して求めた誤差や精度は、カンニング(チート)したようなものと言えるので、本来評価したい“未知のデータ”に対する性能を適切に確認できません。
データの分割
それでは、どのようにすれば適切にモデルの性能を評価できるのでしょうか?
一般的には、あなたがもっている学習データを「訓練データ」と「テストデータ」に分割し、訓練データだけでモデルを学習し、テストデータでモデルの性能を評価します。学習時に与えられた訓練データだけではなく、未知の新たなテストデータに対するクラスラベルや値も正しく予測できる能力を、汎化能力と言います。前述の通り、テストデータはモデルの学習や評価には使うべきではありません。基本的には最終的な評価だけに使うべきです。
それでは、モデルの学習の最中に、どうやってモデルの良さを測るのでしょうか? ここでも、訓練用とテスト用とにデータを分割するような方法が取られます。一般的には、訓練データからテストデータを模した「検証データ」を作って、モデルを評価します(図1)。また、検証データを使って精度を評価する一連の作業はバリデーションと呼ばれます。
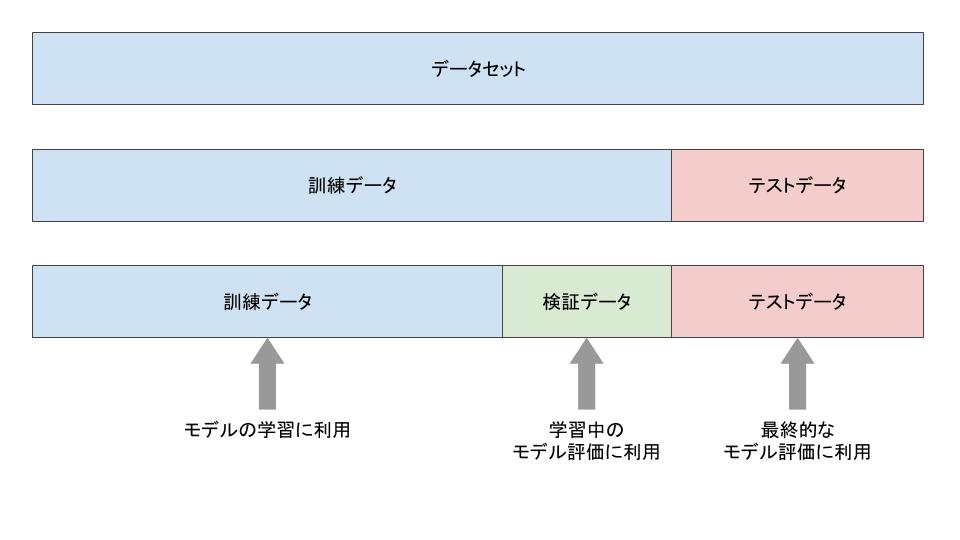
図1: 訓練データ、検証データ、テストデータの分割
Note: 「テストデータを検証データに使えば良いのでは?」と思った方もいるかもしれません。しかし、テストデータを検証データとして何度も利用した場合、テストデータに対して過学習(overfitting)してしまう恐れがあります。
そうなった場合、未知のデータに対する真の予測性能を測ることが難しくなってしまいます(どれだけ過学習しているのか分からなくなってしまう!)。ですので、テストデータとは別に検証データを用意する方が安全です。
それでは、scikit-learnにある、データを分割してくれる便利な関数train_test_splitを利用して、データセットを訓練データとテストデータに分割してみましょう。
# 本章の説明のために、まずデータセットを作成します # X: 全データセット(特徴量) # y: 全データセット(教師信号、ターゲット、target) X = users_item_num[feature_num_columns] y = users_item_num[target_column]
# データセットを訓練データとテストデータに分割 # X_train: 訓練データの特徴量 # y_train: 訓練データの教師信号 # X_val: テストデータの特徴量 # y_val: テストデータの教師信号 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True, random_state=42)
1行でデータを分割できました。実行内容を詳しくみてみましょう。
test_size=0.3で、データセットの3割をテストデータとして分割しています。shuffle=Trueで、データセットをシャッフルしてから分割できます。
Note:
random_state=42と設定することで、毎回同じように分割してくれます。コードを実行するたびに結果が変わるのを防ぐことができます。さて、訓練データとテストデータに分割できたので、次は学習中のモデル評価に必要な検証データを作ってみたいと思います。さまざまな分割方法があるのですが、今回は特に重要な以下の3つを見てみましょう。
- ホールドアウト法(Hold-out)
- K-Fold クロスバリデーション
- Stratified K-Fold クロスバリデーション
ホールドアウト法(Hold-out)
この方法は、図1で説明したような、もともとの訓練データの一部を検証データとして利用し、残りのデータを新たな訓練データとする単純な方法です。未知のテストデータに対して予測を行う状況を、手元で模擬できます。
通常のホールドアウト法をコードで書くと、以下のようになります。先ほど使用したtrain_test_splitを、ここでも使うことができます(testをvalと読み換えると分かりやすいと思います)。
# Hold-out # Input # X_train: 訓練データの特徴量 # y_train: 訓練データの教師信号 # Output # X_train_new: 分割された新たな訓練データの特徴量 # y_train_new: 分割された新たな訓練データの教師信号 # X_val: 分割された新たな検証データの特徴量 # y_val:分割された新たな検証データの教師信号 X_train_new, X_val, y_train_new, y_val = train_test_split(X_train, y_train, test_size=0.3, random_state=42)
状況を整理しましょう。2回コードを実行しました。このとき、以下のデータが存在しています。これらのデータを用いることで、モデルの学習と評価を適切に行うための準備ができました。
| データ | 特徴量 | 教師信号 |
|---|---|---|
| 訓練データ | X_train_new | y_train_new |
| 検証データ | X_val | y_val |
| テストデータ | X_test | y_test |
しかし、ホールドアウト法はシンプルな方法ですが、「検証データを増やすと訓練データが少なくなってしまう」「逆に検証データを減らすと評価の信頼性がなくなってしまう」という問題点もあります。
次に解説するクロスバリデーション法では、この問題をうまく対処してくれます。業務ではもちろん、Kaggleなどのデータサイエンス競技でも、クロスバリデーションを行ってモデル評価をすることが一般的です。後述する「モデルの訓練」や「ハイパーパラメータの調整」では、このクロスバリデーションを用います。
クロスバリデーション法(Cross validation)
この手法は、ホールドアウト法のプロセスを複数回ずらしながら繰り返すことで、モデル評価をします。つまり、学習に使用するデータの量を保ちながら、訓練データ全体に対して評価することが可能になります。
ホールドアウト法に比べてデータを有効活用できるので、よく使われる評価方法です。クロスバリデーションの中でも、特にK-Fold法とStratified K-Fold法は重要な方法です。
K-Fold
まず、よく利用されるK-Foldという方法を紹介します。
K-Foldは、訓練データをK個に分割し、検証データをずらしながらK回ホールドアウト法を繰り返します(図2)。分割されたそれぞれのデータをFoldデータと呼びます。
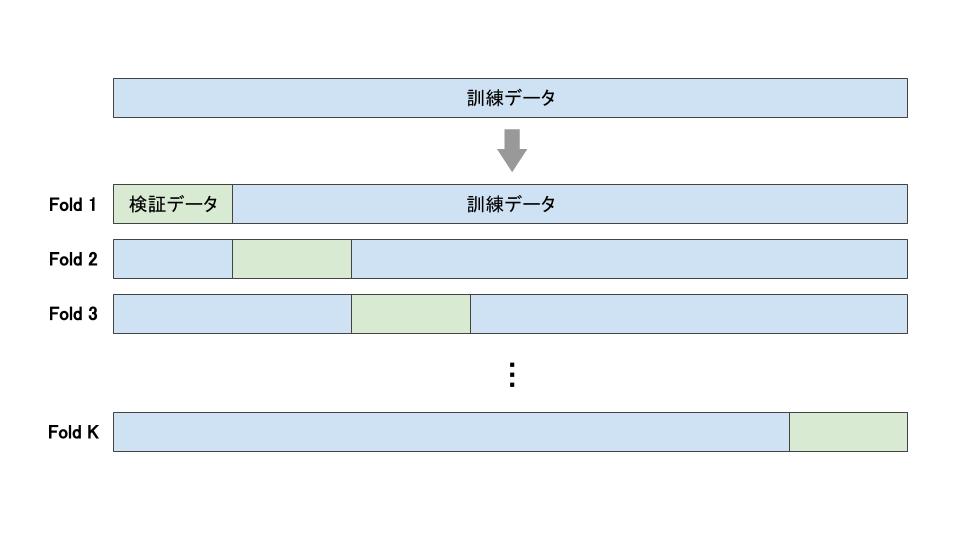
図2: K-Foldの分割方法
コードで書くと、以下のようになります。
from sklearn.model_selection import KFold kf = KFold(n_splits=5, shuffle=True, random_state=42) for train_index, val_index in kf.split(X_train): # 検証データをずらして 5 回繰り返される # データの分割 # 学習データ: X_train_fold, y_train_fold # 検証データ: X_val_fold, y_val_fold X_train_fold, X_val_fold = X_train.iloc[train_index], X_train.iloc[val_index] y_train_fold, y_val_fold = y_train.iloc[train_index], y_train.iloc[val_index]
K-Foldのクロスバリデーションでデータを分割したとき、作成されるモデルもK個になります。一般的には、K回それぞれの性能を平均して、モデル評価を行います。
先ほどのコードに、モデルの学習と予測、精度の計算を加えた簡易的なコードは以下になります。
from sklearn.model_selection import KFold from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score from sklearn.preprocessing import StandardScaler kf = KFold(n_splits=5, shuffle=True, random_state=42) accuracies = [] # 各Foldの予測精度を格納するリスト for train_index, val_index in kf.split(X_train): # 検証データをずらして 5 回繰り返される # データの分割 # 学習データ: X_train_fold, y_train_fold # 検証データ: X_val_fold, y_val_fold X_train_fold, X_val_fold = X_train.iloc[train_index], X_train.iloc[val_index] y_train_fold, y_val_fold = y_train.iloc[train_index], y_train.iloc[val_index] # 学習データの成形(正規化) scaler = StandardScaler() X_train_fold_scale = scaler.fit_transform(X_train_fold) X_val_fold_scale = scaler.transform(X_val_fold) # モデルの学習 model = LogisticRegression(class_weight='balanced') _ = model.fit(X_train_fold_scale, y_train_fold) # 予測 y_pred = model.predict(X_val_fold_scale) # ここでモデルの評価を行う acc_fold = accuracy_score(y_true=y_val_fold, y_pred=y_pred) accuracies.append(acc_fold) acc_mean = np.mean(accuracies) # 各Foldの精度を平均する print(f"Mean accuracy: {acc_mean:.1%}")
出力は次のようになります。
Mean accuracy: 53.3%
具体的なモデルの説明や評価の解釈は、次節(モデルの訓練)で深く見ていきます。
Stratified K-Fold
K-Foldのクロスバリデーションではランダムにデータを分割しましたが、それぞれのFoldに含まれる教師信号に偏りが出てしまう場合もあります。今回の問題のような場合、ランダムに分割すると、各Foldの中で購入したデータが全く入らないことが生じてしまう可能性もあります。そうなると、K回のモデル評価がそれぞれ大きくブレてしまい、適切な評価が難しくなります。
そこで用いられるのが、Stratified K-Foldという方法です。層化抽出法(Stratified sampling)という技法を使うことで、分割された各Foldの教師信号の割合をほぼ等しくすることができます(図3)。それにより、K回行うモデルの評価を安定させることができます。今回の問題では、それぞれのFoldに含まれる商品Xの購入割合が近くなります。
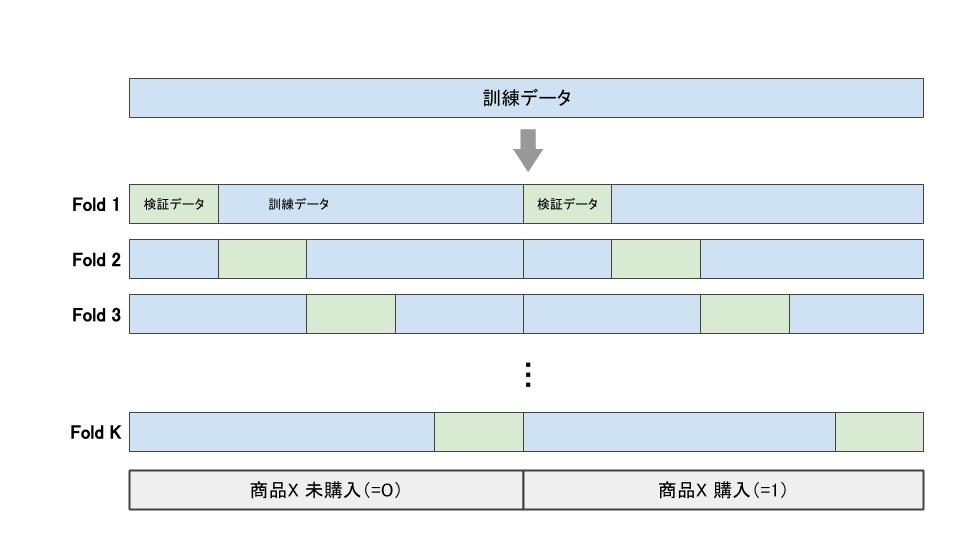
図3: Stratified K-Foldの分割方法
K-Foldと同じような方法で、Stratified K-Foldも以下のようなコードで実行できます。Stratified K-Foldの特徴を見るために、各分割ごとの教師信号が1になる割合を表示しています。
from sklearn.model_selection import StratifiedKFold skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42) for iteration, (train_index, val_index) in enumerate(skf.split(X_train, y_train)): # 検証データをずらして 5 回繰り返される # データの分割 # 学習データ: X_train_fold, y_train_fold # 検証データ: X_val_fold, y_val_fold X_train_fold, X_val_fold = X_train.iloc[train_index], X_train.iloc[val_index] y_train_fold, y_val_fold = y_train.iloc[train_index], y_train.iloc[val_index] y_train_positive_ratio = y_train_fold.mean() y_val_positive_ratio = y_val_fold.mean() print(f"Iteraion {iteration}: train {y_train_positive_ratio:.1%} val {y_val_positive_ratio:.1%}")
出力は次のようになります。
Iteraion 0: train 10.4% val 10.4%
Iteraion 1: train 10.4% val 10.4%
Iteraion 2: train 10.4% val 10.4%
Iteraion 3: train 10.4% val 10.4%
Iteraion 4: train 10.4% val 10.4%
どの分割も同じ10.4%になっていることが分かります。
違いを見るために、先ほどのK-Foldでも試してみましょう。
from sklearn.model_selection import KFold skf = KFold(n_splits=5, shuffle=True, random_state=42) for iteration, (train_index, val_index) in enumerate(skf.split(X_train)): # 検証データをずらして 5 回繰り返される # データの分割 # 学習データ: X_train_fold, y_train_fold # 検証データ: X_val_fold, y_val_fold X_train_fold, X_val_fold = X_train.iloc[train_index], X_train.iloc[val_index] y_train_fold, y_val_fold = y_train.iloc[train_index], y_train.iloc[val_index] y_train_positive_ratio = y_train_fold.mean() y_val_positive_ratio = y_val_fold.mean() print(f"Iteraion {iteration}: train {y_train_positive_ratio:.1%} val {y_val_positive_ratio:.1%}")
多少ですが、教師信号の割合がブレていることが確認できます。
Iteraion 0: train 10.3% val 10.9%
Iteraion 1: train 10.3% val 10.8%
Iteraion 2: train 10.4% val 10.3%
Iteraion 3: train 10.4% val 10.2%
Iteraion 4: train 10.6% val 9.6%
ここまで、モデルを適切に評価する際のデータセットの分割方法について解説してきました。今回は少し不均衡な教師信号をもつデータなので、次節の「モデルの訓練」では実際にStratified K-Foldを利用してモデルを作成してみたいと思います。
Note: ここで紹介した手法以外にも、重要な検証方法は数多く存在します。その中でも、次の2つの手法は実ビジネスでもしばしば登場するので、覚えておくと良いでしょう。
- Group K-Fold
- 同じグループのデータが、訓練データと検証データの両方に現れないようにするクロスバリデーションの一種。例えば、1人のユーザーから複数データが集まり、かつそのデータ間に相関が高いような課題において、新しいユーザーに対する汎化性能を検証したいときに利用される(このときのグループはユーザー個人になる)
- Time Series Split
- 直近の観測データに相関があるような時系列データの分割方法の一種。訓練データをシャッフルせず、(訓練データ、テストデータ)の時系列を崩すことなく、ずらしながら検証データを作成する
詳細はscikit-learnのドキュメントに記載されているので、興味のある読者は scikit-learnのクロスバリデーションのドキュメントや クロスバリデーションの分割方法の可視化などを参考にしてみてください。
モデルの評価指標
さっそく「モデルの訓練」に進みたいところなのですが、手を動かす前に検討すべきことが、あと1つあります。モデルの評価指標です。
モデルを学習したら、そのモデルを使って実際に予測するわけですが、予測値を問題に合った適切な指標で評価する必要があります。不適切な評価指標で予測結果を評価してしまった場合、意図した評価ができなかったり、誤った判断をしてしまう可能性があるからです。データサイエンスをする上で最も気を付けなければいけないポイントの1つと言えるでしょう。
今回の問題は、二値分類です。0か1のどちらか一方で予測をする場合、一般的にはAccuracyやPrecision、Recall、F1などがよく使われます。0から1の確率のような値(0.3や0.9など)で予測する場合は、AUC(Area under the ROC curve)やloglossが多く使われます。
また、現実によくある問題では、正例の予測をうまくできているかを評価したくなります(正例を他の負例よりも大きい確率で予測できているか?)。そのような場合によく使われるのがAUCです。本分析でもAUCを使います。AUCの詳しい説明は省きますが、興味のある読者はWikipediaの解説などを参考にしてみてください。
AUCは0~1の値を取り、1になるほど性能の良さを表します。予測結果がランダムの場合は0.5に近い値になります。実際にデータサイエンスを行う際には、パラメータや特徴量の異なる複数のモデルを作って、どのモデルが良いかを比較すると思います。AUCは、単に予測値によるランク(大小関係)を元に算出されるので、使用するアルゴリズムに依らず、安定した評価値を出すことができます。
そのおかげで、複数モデルの比較も容易になります。例えば、モデルAが[0.9, 0.8, 0.7]と予測し、モデルBが[0.3, 0.2, 0.1]と予測した場合、どちらもAUCの値は等しくなります。今回の問題に照らし合わせると、予測確率が高いお客さまから営業をしたいので、モデルAとモデルBの評価値は同じになってほしいです。そのため、今回の問題で評価指標の1つにAUCを使うのは理にかなっていると言えます。
しかし、“ビジネスとしての評価”では、解釈性の高いAccuracy、Precision、Recall、F1なども重要ですので、それぞれの性質を理解して問題にあった(複数の)指標を用いることも大事です。
下記にAUCの使い方を示します。
from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import roc_curve, auc # モデルの学習 clf = RandomForestClassifier(n_estimators=100, random_state=42) clf.fit(X_train_new, y_train_new) # 確率値の予測 y_val_pred = clf.predict_proba(X_val)[:, 1] # AUC の計算 fpr, tpr, thresholds = roc_curve(y_true=y_val, y_score=y_val_pred) y_auc = auc(fpr, tpr) print(f"AUC = {y_auc:.4}")
出力です。
AUC = 0.6568
次章の「モデルの訓練」では、AUCをモデルの評価指標とし、実際の利用方法や解釈の仕方を見てみたいと思います。
Note: ここで、よく間違えられる目的関数(objective function)と評価関数(evaluation function)の違いと注意点を簡単に解説します。
| function | 説明 | 例 |
|---|---|---|
| 目的関数 | 学習アルゴリズムが最適化(min/max)したい関数。基本的に微分可能であることが求められる。 | logloss、MSEなど |
| 評価関数 | 複数のモデルからどれが最良なモデルかを評価する関数(指標)。主に学習後に利用されるが、イテレーションを伴うようなモデルでは、その停止基準として利用することもあるので、学習中にも使われることがある(Early Stoppingなど)。 | AUC、accuracyなど |
これらは混同されやすいのですが、それぞれの目的の違いを覚えておけばモデルの学習やビジネスでの利用を適切かつ安全に行うことができます。覚えておいて損はありません。
Note: 今回選択したAUCは、直接微分することが不可能なので目的関数として基本的に利用できませんが、そのような微分不可能な指標を、直接または近似的に最適化しようとする興味深い研究もあります。Yan, L., et al. (2003)、Cortes, C., Mohri, M. (2004)、Herschtal, A., Raskutti, B. (2004)、Eban, E. E., et al. (2016)
4. モデルの訓練
データの準備ができ、検証方法と評価指標が固まったらモデルの訓練に移ります。今回は、ロジスティック回帰とランダムフォレストという2つのモデルを使います。
ロジスティック回帰は、線形モデルの一種です。「回帰」という名前ですが、分類に使われる手法です。各特徴量の値に重みをつけて足し合わせ、シグモイド関数をかけたものを「targetが1の確率」とみなします。
ランダムフォレストは、決定木をベースとした非線形モデルの一種です。特徴量とサンプルから一部抜き出して決定木をつくることを繰り返し、作った複数の決定木の予測結果を平均して予測を行います。
これらの手法は取り回しが容易ということもあり、ベースラインとしてよく用いられます。
ロジスティック回帰
scikit-learnでは、sklearn.linear_model.LogisticRegressionとして実装されています。
ロジスティック回帰を使う上で注意すべき事項は、以下の2つです。
- カテゴリ変数のダミー変数化
- 各特徴量の正規化(標準化)
カテゴリ変数のダミー変数化
ロジスティック回帰は、特徴量の値を利用する手法です。各カテゴリが0, 1, 2, 3, ...のように連番で表されていたとき、カテゴリ2はカテゴリ1の2倍、カテゴリ3はカテゴリ1の3倍の影響があると認識されてしまいます。
これを防ぐために行うのがダミー変数化(One Hot Encoding)です。例えば全部で5つのカテゴリがあるとします。その場合、カテゴリ0を[1, 0, 0, 0, 0]、カテゴリ1を[0, 1, 0, 0, 0]のように、該当する場所だけに1が立ったベクトルに変換します。これを行うことで、カテゴリ同士に大小関係をつけることなく、各カテゴリの有無という形で表現することができます。
今回使用するcategory_encodersライブラリでは、OneHotEncoderとして実装されています。
各特徴量の正規化(標準化)
ロジスティック回帰は特徴量の値を利用する手法ですので、0~1のように狭い範囲でばらついている特徴量と-30000~800000のように広い範囲でばらついている特徴量が混在していた場合、学習に悪影響が出てしまいます。
各特徴量からの影響度を揃えるために行うのが、正規化(標準化)です。代表的な方法として、各変数を平均0、標準偏差1に揃える方法(sklearn.preprocessing.StandardScaler)と、各変数を最小値0、最大値1に揃える方法(sklearn.preprocessing.MinMaxScaler)が存在します。
ランダムフォレスト
scikit-learnでは、sklearn.ensemble.RandomForestClassifierとして実装されています。
ランダムフォレストの特徴は、特徴量同士の関係(相互作用)を考慮でき、良い精度が出るという点です。特徴量の正規化が必要ないといううれしい性質もあります。
from sklearn.model_selection import KFold, cross_validate from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier
X = users_item_num[feature_num_columns + feature_cat_columns] y = users_item_num[target_column] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=True, random_state=42)
パイプラインを使おう
ロジスティック回帰はデータに対して正規化を行う必要がありますが、ランダムフォレストは正規化を行う必要はありません。このように、実務で複数のモデルを扱う際は「データに対して微妙に異なる処理を行った後にモデルを学習する」というケースが多く存在します。
しかし、データを2種類用意して「いま使うモデルはロジスティック回帰だから正規化したデータを使って、こっちのモデルはランダムフォレストだから正規化していないデータを使って……」などとやっていると煩雑ですし、ミスも発生します。
これを解決するために使われる機能が、パイプラインです。パイプラインを利用すると、このモデルのときは必ずこの前処理をやる、といった一連の処理をまとめて定義できます。
scikit-learnでは、sklearn.pipeline以下にパイプライン機能がまとまっています。make_pipelineという関数に、行いたい処理を順番に渡すことで、パイプラインを作成することができます。
from sklearn.pipeline import make_pipeline from category_encoders import OneHotEncoder # ロジスティック回帰のパイプライン lr_model = make_pipeline( OneHotEncoder(cols=feature_cat_columns, use_cat_names=True), StandardScaler(), LogisticRegression(), ) # ランダムフォレストのパイプライン rf_model = make_pipeline( OneHotEncoder(cols=feature_cat_columns, use_cat_names=True), RandomForestClassifier(), )
評価を行う
モデルが定義できたら、5-foldクロスバリデーションで評価を行います。評価指標にはAUCを用います。scikit-learnではsklearn.model_selection.cross_validateとして実装されています。
return_estimatorというオプションをTrueにすることで、各Foldで訓練されたモデルも得ることができます。
lr_scores = cross_validate(lr_model, X_train, y_train, cv=kf, scoring='roc_auc', return_estimator=True) print('LR', lr_scores['test_score'].mean()) rf_scores = cross_validate(rf_model, X_train, y_train, cv=kf, scoring='roc_auc', return_estimator=True) print('RF', rf_scores['test_score'].mean())
出力です。
LR 0.653455962519973
RF 0.6174744734247983
5. ハイパーパラメータの調整
さて、各モデルの評価値が得られましたが、これで終わりでよいのでしょうか。ロジスティック回帰とランダムフォレストではロジスティック回帰の方が良い値が出ましたが、これが果たしてベストなのでしょうか。多くの場合、デフォルトのパラメータで出した結果は、まだまだ改善の余地があります。
モデルを改善する方向性の1つが、ハイパーパラメータの調整です。ハイパーパラメータとは「モデルが自動で学習するのではなく、外から指定する必要があるパラメータ」を表します。分かりやすい例としては「ランダムフォレストで作成する決定木の数」が挙げられます。
調整すべきハイパーパラメータ
scikit-learnのドキュメントを読んで、あまりにたくさんのオプションがあることに驚いた人も多いでしょう。モデルに対する理解がおろそかなままハイパーパラメータを調整しようとすると、精度に大きく影響する項目を調整していなかったり、逆に全く精度に関係ない項目をがんばって調整してしまったり、といったことが起こります。
ハイパーパラメータを調整するには、モデルに対する理解が不可欠です。とはいえ、この記事で各モデルのアルゴリズムの詳細に立ち入るのは現実的ではありませんので、ロジスティック回帰とランダムフォレストについて、主要なハイパーパラメータを紹介します。
ロジスティック回帰
ロジスティック回帰では、penalty、l1_ratio、Cは最低限調整しましょう。これらは、重みの大きさに対するペナルティを決める項目です。
ロジスティック回帰の学習では、予測誤差の大きさと回帰係数の大きさを重み付けして足し合わせ、それを最小化していきます。予測誤差の大きさを重く見る(重みの大きさに対するペナルティを小さくする)場合、より正確に値を予測する、柔軟なモデルが学習されます。一方で、回帰係数の大きさを重く見る(重みの大きさに対するペナルティを大きくする)場合、訓練データにフィットし過ぎない、頑健なモデルが学習されます。
penaltyはペナルティの種類を表しており、l1、l2、elasticnet、noneのいずれかを取ります。l1を採用した場合、多くの係数が0になり、l2を採用した場合、係数が全体的に小さくなるという特徴があります。
elasticnetはl1とl2を混ぜたペナルティであり、混ぜ方の比率を決めるのがl1_ratioというパラメータです。l1_ratio=1のときl1と一緒になり、l1_ratio=0のときl2と一緒になります。したがって、penaltyにはelasticnetを選択しておき、l1_ratioを0~1の範囲で調節するのが良いでしょう。
Cはペナルティの大きさを表しています。内部では逆数で扱われているので、小さい値の方が大きなペナルティがかかります。
ロジスティック回帰の詳細を知りたい方は、scikit-learnのドキュメントにあたるとよいでしょう。
ランダムフォレスト
ランダムフォレストでは、n_estimatorsを調節しましょう。n_estimatorsはランダムフォレスト内部で構築する決定木の数を表しています。
調節とは言うものの、基本的には大きい値を設定した方が精度は良くなります。ただ、大き過ぎる値を指定しても計算時間の無駄ですので、何種類か試して精度が十分上がりきっていることを確認すれば十分でしょう。
ハイパーパラメータの調整方法
ハイパーパラメータの良し悪しを評価するのは、やはりバリデーションにおける精度です。試すハイパーパラメータを決めて、バリデーションで精度を確認、という流れを何度もくり返すことになります。もちろん、これを手動でやるのは大変ですから、ライブラリに任せましょう。
scikit-learnにはsklearn.model_selection.GridSearchCVやsklearn.model_selection.RandomizedSearchCVという機能が存在します。前者はグリッドサーチという手法で、後者はランダムサーチという手法でハイパーパラメータを探索してくれます。
グリッドサーチの発想は単純で、各ハイパーパラメータに対して候補を与えると、全ての組み合わせを試して最も良いものを選びます。ランダムサーチでは各ハイパーパラメータに対して範囲を与え、その範囲でランダムにハイパーパラメータを決め、指定した回数試した中で最も良いものを選びます。
直感的にはグリッドサーチの方が良いように思えるかも知れませんが、同じ数の候補を試した場合、ランダムサーチの方が良いハイパーパラメータ候補にたどり着きやすいことが知られています(J. Bergstra, Y. Bengio. 2012)。
from sklearn.model_selection import GridSearchCV # make_pipelineを使った場合、クラス名とパラメータ名をアンダーバー2つでつなぐ lr_params = { 'logisticregression__penalty': ['elasticnet'], # penaltyはelasticnetのみ 'logisticregression__solver': ['saga'], # elasticnetを使う時はsagaを指定する 'logisticregression__l1_ratio': [i*0.2 for i in range(6)], # 0から1の範囲で0.1刻み 'logisticregression__C': [10**i for i in range(-3, 4)] # 10^(-3)から2^3の範囲で } rf_params = { 'randomforestclassifier__n_estimators': [100*i for i in range(1, 6)] # 100から500まで100刻み } # scoring(評価指標)とcv(バリデーションの分割方法)の指定を忘れない lr_gscv = GridSearchCV(lr_model, lr_params, scoring='roc_auc', cv=kf) rf_gscv = GridSearchCV(rf_model, rf_params, scoring='roc_auc', cv=kf) # グリッドサーチを実行 lr_gscv.fit(X_train, y_train) print('LogisticRegression') print(f'best_score: {lr_gscv.best_score_}') print(f'best_params: {lr_gscv.best_params_}') rf_gscv.fit(X_train, y_train) print('RandomForest') print(f'best_score: {rf_gscv.best_score_}') print(f'best_params: {rf_gscv.best_params_}')
LogisticRegression
best_score: 0.6567899204040524
best_params: {'logisticregression__C': 0.01, 'logisticregression__l1_ratio': 0.8, 'logisticregression__penalty': 'elasticnet', 'logisticregression__solver': 'saga'}
RandomForest
best_score: 0.6991768975654966
best_params: {'randomforestclassifier__n_estimators': 500}
Note: Optunaなどのベイズ最適化
過去に試したパラメータ群から次に探索すべきパラメータを推定して、効率的に探索を進めていく手法をベイズ最適化と言います。
Optunaは、ベイズ最適化を実現するライブラリの1つで、深層学習ライブラリChainerで有名なPreferred Networksが開発しています。
効率的にパラメータを探索する機能のほかにも、探索を中止/再開する機能や、改善しそうにない試行を途中でやめる(枝刈りをする)機能が搭載されています。
少しでも精度を上げたいケースや、1回の試行が重いようなケースで効果を発揮するでしょう。
6. テストデータで確認する
学習が終わりハイパーパラメータの調整も済んだら、最後にテストデータで精度を確認します。テストデータでの評価を何度も行ってしまうと、テストデータの「未知」データとしての価値が薄れてしまうので、テストデータでの評価は極力低回数に抑えましょう。
GridSearchCVやRandomizedSearchCVを使うと、最適パラメータで学習し直したモデルが返ってきますので、そのモデルを使ってpredictを行いましょう。
from sklearn.metrics import roc_auc_score # predict_probaを使用することで各クラスに対する確率を得る # 今回ほしいのはtarget=1の確率なので、[:, 1]でアクセスすればよい lr_pred = lr_gscv.predict_proba(X_test)[:, 1] rf_pred = rf_gscv.predict_proba(X_test)[:, 1] print('LR', roc_auc_score(y_test, lr_pred)) print('RF', roc_auc_score(y_test, rf_pred))
出力です。
LR 0.6448146686923748
RF 0.6939487804562314
これがロジスティック回帰とランダムフォレストを使用した場合の精度です。
次のアクション
結果が出たら、結果の吟味に入ります。今回使用した2つのモデルはあくまでベースラインとして使われるものですが、課題によってはこれ以上の改善は必要ない場合があります。
モデルを改善したことによってどれほどビジネス的な意味があるかを考え、さらなる精度改善に取り組むべきか熟考すべきでしょう。精度改善は終わりがありませんので、時間的コストと得られる利益を比較して、ほどよいところで終わらせる必要があります。
今回の場合、「予測値が高い順にソートしたリストを営業担当者に見てもらい、納得感があるかを確認する」というアプローチも有効でしょう。その際は特徴量の重要度を可視化するのも良いでしょう。
精度改善が必要という結論になった場合、主要なアプローチは以下の4点です。
- 重要な特徴量を選定する
- 新たな特徴量を作成する
- モデルの種類を変更する
- より細かくハイパーパラメータチューニングを行う
まとめ
データサイエンスは敷居が高いと思われがちですが、各場面で行なっていることは意外とシンプルですよね? ここでお見せした一連の作業は、どのような問題でも基礎となる重要な手順になります。
さて、Oさんがここで行なった分析をレポートにまとめ、担当者に報告したところ「十分な精度が出ているのでぜひモデル導入をしたい! 他の商品も予測できるモデルもお願い!」との高評価な返答を無事得ることができました。
次の目標は、複数の商品を予測できるモデルを作って、それを有効活用できるシステムやフローを構築し、もっとデータサイエンスで事業に貢献することです。読者のみなさまも似たような状況に直面したときには参考にしてみてください。
基礎的なデータサイエンスを覚えたOさんは、次の挑戦へ向けて走るのみ。頑張れOさん!
田中 一樹 (たなか・いっき)


2017年にDeNA入社後、データサイエンティストとしてアプリゲーム『逆転オセロニア』に関するAI機能の開発に取り組む。現在は、多様な事業へのデータサイエンス活用を目指した研究開発や課題発掘に携わる。学生時代からデータ分析の大会に没頭し複数大会で入賞。Kaggle Master。
山川 要一 (やまかわ・よういち)


京都大学大学院にて修士取得後、2014年新卒入社。事業状況の変化が激しいゲーム領域の中における分析チームリーダーとしての事業推進・分析経験を活かし、現在はオートモーティブ事業部にて分析業務を推進している。
鈴木 天音 (すずき・あまね)


東京大学大学院にて修士取得後、2019年4月にDeNAに新卒で入社。Kaggle Master。大学院では化学と機械学習を組み合わせたケモインフォマティクスを専攻。現在はデータサイエンスチームのメンバーとして、エネルギー事業における分析・開発に携わっている。
《技術監修》 松井 健一(株式会社ディー・エヌ・エー)




