
マイクロサービスにおけるWeb APIスキーマの管理 ─ GraphQL、gRPC、OpenAPIの特徴と使いどころ
マイクロサービスにおける通信方式の選択について、おおた(ota42y)さんが、GraphQL・gRPC・OpenAPIといった主なWeb APIスキーマの管理の利点と使い分けを解説します。
近年流行しているマイクロサービスアーキテクチャにおいては、「どういった通信方式を選ぶか」が開発の効率やサービスの信頼性、パフォーマンスを大きく左右します。この記事では、GraphQL・gRPC・OpenAPIそれぞれの利点と適切な使い分けについて解説します。
- マイクロサービスにおけるWeb API管理の重要性
- Web APIのインタフェース定義手法の比較
- どの手法を導入するのが良いのか
- 「複数の通信方式を組み合わせる」という選択肢も
- おわりに ─ プラクティスや開発環境に応じて総合的に判断
マイクロサービスにおけるWeb API管理の重要性
マイクロサービスによって構築されたアプリケーションは、複数の独立したサービスが互いに連携することで、1つのアプリケーションとして動作します。サービスごとに持っているデータは異なるため、APIを適切に用いて複数のマイクロサービスからデータを取得する必要があります。
特定のサービスでは、自身が持つデータだけで処理が完結しない場合もあります。その場合、事前に、もしくはリクエストのたびに、マイクロサービス内の他のサービスに対して必要な情報を問い合わせ、複数の情報をまとめた上で処理する必要があります。
1つのモノリシックなシステムであれば、これはデータベースへのクエリ発行や別モジュールのメソッド実行などで済みますが、マイクロサービスの場合は各サービスが独立しているため、通信によって問い合わせるのが一般的です。
つまり、マイクロサービスでは、ユーザが触れるアプリとバックエンドとの通信、バックエンドのサービス同士の通信といったように、モノリシックなシステムと比べてより多くのWeb APIを定義する必要があります。また、基本的にサービスが違うと管理するチームも違うため、アプリケーションの作り方や、用いられているプログラミング言語まで変わる(Polyglot)場合があります。
そのため、Web APIを使う側がコードを読まなくても、ある程度処理の概要が分かるような管理方法が重要になるわけです。
Schema First DevelopmentとWeb API
Web APIの管理は、Schema First Development(スキーマファースト開発)という開発手法においても、同様に重要です1。これは「最初にWeb APIの仕様(スキーマ)を決め、そのスキーマが満たされる前提のもとにサーバ・クライアントが同時に開発を進め、最後に結合する」という開発手法です。
サーバ・クライアントの接続部分であるスキーマをはじめに決定し、それを元に作業を始めるため、結合時に認識のズレが起きにくく、開発の効率化が期待できます。マイクロサービスにおいては前述のようにWeb APIが多く作られるため、開発の効率化やミスを減らすことの重要性がとても高いです。
また、この手法ではドキュメントに流用可能なスキーマが同時に作られるため、その特徴も開発効率の向上に寄与してくれます。
人ではなくプログラムが処理できるよう管理する
このように、マイクロサービスにおいてWeb APIを管理することは重要ですが、大量のWeb APIをきちんと管理することの難易度は高いです。
例えば、WikiやExcelといったテキストのドキュメントとして仕様を記述する場合、「実装とドキュメントが紐付いていないため、コード変更がテキストに反映されない」「ドキュメントの定義をコードが正しく実装してない」など、実装とドキュメントの乖離が発生します。そうなると、ドキュメントの信頼度が下がって使われなくなってしまいますし、間違ったドキュメントに依存したアプリケーションが複数できると、それらを直すのは非常に困難になります。
このように、人の手による温かみのある管理は、多くの場合、破綻します。
この問題に対して、プログラムとして処理可能な方法でWeb APIを記述することで、ある程度の解決が見込めます。自然言語による説明文に加え、必要とするパラメータやレスポンスの形式、データの型などはプログラムによって自動的に判定できます。
そのため、プログラムの単体テスト時に形式をチェックしたり、定義を用いてシリアライズすることで定義したとおりの形式でしか送れないようにするなど、インタフェースとスキーマの定義をそろえることができます。また、コード生成による実装量の軽減なども期待できます。
Web APIのインタフェース定義手法の比較
今回は、このようなWeb APIのインタフェースを定義するという観点から、その用途として使える通信方式としてOpenAPI、gRPC、GraphQLの3つを挙げ、それぞれの特徴や技術選択時の観点について紹介していきます。
厳密にはそれぞれ対象とする領域が違うため、全体を比較しようとするのは難しいのですが、今回は「マイクロサービスにおいて各サービスのWeb APIのインタフェースを記述する」という用途に限定して比較します。
なお、本セクションに掲載したサンプルファイルは、次のリポジトリに置いています。gRPCとGraphQLでは動作するコードを用意しています。

OpenAPI ─ REST APIの資産を生かして導入できる
OpenAPIは、OpenAPI Initiativeが策定しているREST APIのインタフェースを記述する仕様です。かつてはSwaggerと呼ばれていましたが、Swaggerのバージョン2.0がOpenAPI Initiativeに寄贈された後、OpenAPI 2.0という名称に変更されました2。

この仕様では、REST APIのURLやリクエスト・レスポンスの形式を、JSONまたはYAMLで記述します。特定のプログラミング言語に依存しない、独立した定義ファイルとなっています。
OpenAPIの2019年7月の最新バージョンは3.0.2で、本記事ではこのバージョンをもとに紹介します。
OpenAPI 3の定義をYAMLで書いた場合、以下のような形になります。
openapi: 3.0.0 info: title: Sample API version: 0.1.0 paths: "/apps": post: requestBody: content: 'application/json': schema: "$ref": '#/components/schemas/app' responses: '200': "$ref": '#/components/responses/appResponse' "/apps/{id}": parameters: - name: id in: path required: true schema: type: integer get: responses: '200': "$ref": '#/components/responses/appResponse' delete: responses: '204': description: delete app components: schemas: app: type: object description: application data properties: id: type: integer responses: appResponse: description: get selected app content: 'application/json': schema: "$ref": '#/components/schemas/app'
これで定義されたサーバでは、POSTの/appsにidを指定してデータを作成し、作成時のidをGETの/apps/{id}にパスパラメーターとして指定するとデータが取得できます。不要になったら、DELETEの/apps/{id}でデータを削除できます。
また、GETとPOSTにおいて200のレスポンスは同一で、idを持つオブジェクトがapplication/jsonで返ってきます。POSTのリクエストをcurlで表現すると、以下のリクエストとレスポンスになります。
$ curl -X POST "https://editor.swagger.io/apps" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"id\":42}" { "id": 42 }
今回の例では、JSONのAPIのみを紹介していますが、POSTするmultipart/form-dataやx-www-form-urlencodedなどもサポートしており、一般的なREST APIの用途はほぼカバーしていると思います。
OpenAPIの定義を読んで処理する多様なツール
OpenAPIの定義は、JSONまたはYAMLファイルの書き方に準拠しています。テキストやWikiに定義を書くのとほとんど変わりません。ですが、構造化されており、プログラムが処理しやすい形式になっているため、OpenAPIの定義を読み込んでさまざまな処理をしてくれるツールが存在します。
例えば、筆者はサーバのリクエスト・レスポンスの形式がOpenAPI 3の定義どおりかどうかを検証するツールをRubyで作っています。また、定義ファイルからさまざまなプログラミング言語のクライアントライブラリを作成してくれるOpenAPI Generatorというツールもあります。
定義ファイルからパラメータを設定して、リクエストを試せるインタラクティブなドキュメントを作成してくれるSwagger UIや、実装をもとにOpenAPIの定義を作成してくれるFastAPIのようなフレームワークも存在します。
その他にもさまざまなツールが作られています。公式リポジトリの実装例紹介や、OpenAPI.Toolsでは多種多様なツールが紹介されていますし、ここに載っていないものもたくさんあります。
また、OpenAPIの仕様は、後述するgRPCやGraphQLと比べると規模が小さく、複雑ではないため、定義を読み込む実装を自分で作ることも簡単です。
特定の言語に依存せずREST APIの仕組みを生かせる
OpenAPIは特定の言語に依存しない定義であるため、さまざまな言語の実装を利用できます。REST APIを拡張するものであるため、導入・学習コストは低く、既存のフレームワークをそのまま使うなど、今ある技術的資産を最大限に活用しながら導入できます。
また、実際の通信は既存のREST APIの仕組みを使うため、HTTP層でのキャッシュやメトリクス収集、ルーティング管理などあらゆる層の仕組みをそのまま生かせます。RESTは事実上Webの標準技術であり、さまざまなベストプラクティスを集めたものであるため、REST APIに流用できる資産はとても多く、インタフェース定義を加えるOpenAPIの費用対効果は高いと言えます。
gRPC ─ HTTP/2とProtocol Buffersによる高いパフォーマンス
gRPCとは、CNCF(Cloud Native Computing Foundation)がホストしているRPC(Remote Procedure Call)のフレームワークの1つです。もともとはGoogleが社内で使っていたもので、CNCFに寄贈されました。

gRPCではHTTP/1やJSONなどさまざまな組み合わせがあり得ますが、本記事ではHTTP/2とProtocol Buffersを前提として進めます。
gRPCではIDL(インタフェース技術言語)でリモート呼び出しのインタフェースの記述や、やり取りするデータの構造を記述し、各プログラミング言語に対して実装を生成します。
gRPCの定義ファイルとGo言語による実装例
gRPCの例を紹介します。まず、定義ファイルは以下のようになります。
syntax = "proto3"; import "google/protobuf/empty.proto"; package pb; service Application { rpc GetApps (google.protobuf.Empty) returns (Apps) {} } message App { int64 id = 1; string description = 2; } message Apps { repeated App items = 1; }
これはApplicationというサーバに対してGetAppsというRPCを実行できる定義です。GetAppsは引数を取らず、Appの配列をitemsという要素に詰めて返します。
protocコマンドでこの定義から言語毎のコードを生成し、アプリケーションコード側から読み込んで使います。
Goのサーバでは、上記で定義したRPC名と同じインタフェースを持つ関数を定義して、以下のように実装します。今回は、固定で2つのデータを返すように実装しています。その後、この関数をインタフェースに持つオブジェクトを、gRPCのフレームワークに登録します。クライアントからアクセスがあると、登録したオブジェクトの関数をフレームワークが実行します。
type server struct{} func (s *server) GetApps(ctx context.Context, in *empty.Empty) (*app.Apps, error) { ret := &app.Apps{ Items: []*app.App{ &app.App{ Id: 1, Description: "description", }, &app.App{ Id: 2, }, }, } return ret, nil } func main() { fmt.Println("start") lis, _ := net.Listen("tcp", "0.0.0.0:80") s := grpc.NewServer() app.RegisterApplicationServer(s, &server{}) if err := s.Serve(lis); err != nil { fmt.Println("failed server %v", err) } }
アクセスするクライアント側のコードは、以下のようになります。生成されたコードの対応するメソッドを呼ぶと、通信の後にデータが入ったオブジェクトが得られます。
func main() { conn, _ := grpc.Dial("server_host:80", grpc.WithInsecure()) defer conn.Close() client := app.NewApplicationClient(conn) res, _ := client.GetApps(context.TODO(), &empty.Empty{}) for _, item := range res.Items { fmt.Printf("result: id = %v, description=%s \n", item.Id, item.Description) } }
多様な言語サポート、静的型付き言語に便利なシリアライズ
gRPCは、複数の言語を公式にサポートしており、サーバサイドの言語はもちろん、WebやAndroid、iOSといったエンドユーザーが直接触れる場面でも使えるようになっています。
デフォルトでHTTP/2とProtocol Buffersを用いたやり取りが行われるため、データ量や通信コストが抑えられており、高いパフォーマンスが期待できます。また、データはフレームワークによって自動でProtocol Buffersにシリアライズ/デシリアライズされるため、インタフェース宣言どおりの型になり、静的型付き言語においては特に便利です。
言語のサポートがない、HTTP/2が使えないなど、gRPCが使えないクライアントに対しても、gRPCの定義ファイルを元にREST APIでアクセス可能なゲートウェイを作成するgRPC-gatewayというライブラリも存在しているため、マイクロサービスで複数の言語を使い分けている場合は、一部だけgRPCにしないという方針も選択できます。
GraphQL ─ クライアント側の自由度が高いクエリ言語
GraphQLとは、GraphQL Foundationがホストしているクエリ言語です。もともとはFacebookが開発していたものですが、GraphQL Foundationに移管されました。

GraphQLでは、やりとりするデータのスキーマを、独自言語を用いて定義します。クライアント側は、取得したいデータを専用のクエリ言語で指定し、実行用のWeb APIに送ります。サーバ側はクエリを受け取ると、そのクエリの定義どおりにデータの取得や更新処理を行い、通常はJSONでレスポンスを返します。
graphql-rubyによるGraphQLの実装例
GraphQLの例は、以下のようになります。実装としてはgraphql-rubyを利用しています。まず、以下のようにスキーマを定義し、やり取りするデータの形式を決定します。
module Types class Application < GraphQL::Schema::Object description "Application's Object Type" field :id, Integer, null: false field :description, String, null: true end class Player < GraphQL::Schema::Object field :id, Integer, null: false field :name, String, null: false end end
次に、データを取得するクエリ定義を記述します。ここではクエリのフィールド名とパラメータ、およびレスポンスとしてどういったスキーマなのかを定義します。実際にデータを取ってくる処理は、graphql-rubyではフィールド名と同名のメソッドを使うというルールがあるため、そちらを使います。
このメソッドの中は普通のRubyコードが書けるようになっており、通常はDBに問い合わせなどを行ってデータを作ります。今回はapplicationsというフィールドでTypes::Applicationの配列が、Integer型のidを必須として要求するplayerというクエリで、TypesPlayerのデータを1つレスポンスとして返します。
require 'graphql' require_relative 'types' class QueryType < GraphQL::Schema::Object field :applications, [Types::Application], null: false do description 'Get all applications' end def applications [ { id: 1 }, { id: 2, description: 'id=2 application' } ] end field :player, Types::Player, null: false do argument :id, Integer, required: true end def player(id:) { 1 => { id: 1, name: 'Honoka'}, 2 => { id: 2, name: 'Mari'} }.fetch(id) end end
このクエリを、GraphQLのスキーマとして定義します。
require 'graphql' require_relative 'query' class Schema < GraphQL::Schema query QueryType end
最後に送られてきたJSONデータをスキーマのexecuteメソッドに渡すと、GraphQLの処理系が処理し、必要なデータを取得します。
result = Schema.execute(params[:query]) json result
このエンドポイントがlocalhost:14567で動いていると仮定すると、以下のようにリクエストを送ってデータを取得できます。
$ curl -X POST -d '{"query": "{ applications { id description } player(id: 1) { name } }"}' -H "Content-Type: application/json" localhost:14567/graphql { "data": { "applications": [ { "id": 1, "description": null }, { "id": 2, "description": "id=2 application" } ], "player": { "name": "Honoka" } } }
id=2のPlayerだけ、かつidもレスポンスに含めるようなクエリにしてみます。
$ curl -X POST -d '{"query": "{ player(id: 2) { id name } }"}' -H "Content-Type: application/json" localhost:14567/graphql { "data": { "player": { "id": 2, "name": "Mari" } } }
このように、GraphQLでは送信するクエリを変えるだけで取得するデータを自由に変更できるため、サーバ側の修正は全く必要ありません。
GraphQLの具体的な内容についてもっと詳しく知りたい方は、より詳細に解説した記事がありますのでご覧ください。
取得するデータの種類などをクエリで自由に変更できる
GraphQLによって作られたサーバアプリケーションの場合、GraphQLの処理系から要求されたデータを返すだけで、処理系がクエリに沿ってレスポンスのJSONを組み立ててくれます。そのため、レスポンスに含まれるデータの種類やデータの中の必要なフィールドは、クライアント側から送るクエリによって決定されます。
前述したOpenAPI(REST API)やgRPCは、規定の方法で呼び出すと定義しているスキーマに沿ったデータが返ってくるため、レスポンスの形式は固定されています。そのため、クライアント側から取得したいデータが変わった場合、これらの方法では複数回通信をするか、もしくは新しいWeb APIを定義する必要があります3。
しかし、GraphQLでは、一度の通信で取得するデータをクエリによって自由に変えられるため、取得するデータを変える場合にはクライアント側を変更するだけでよく、開発の効率化や通信回数・通信量の節約が容易に実現できます。
また、GraphQLはクエリをサーバに送るだけで動作するため、クライアント側ではライブラリがなくても使うことができます。
どの手法を導入するのが良いのか
各手法の特徴が出そろったところで、実際にマイクロサービスのWeb APIを定義する方法としてどれが良いかを考えます。なお、OpenAPIはREST APIと組み合わせて使うもののため、REST API+OpenAPI、gRPC、GraphQLを比較していきます。
この3つの関係性を大まかに捉えると、「かつてはREST APIが事実上のスタンダードだったが、いろいろな所で使われるうちに適応しにくいケースが出てきて、そうした課題を解決するためにgRPCやGraphQLが出てきた」という流れだと言えます。
そのため、gRPCやGraphQLが有効に効く場面では、これらを用いた方が問題をスマートに解決できます。ただし、gRPCやGraphQLはこれまで積み上げられてきた有形無形の資産をある程度捨てているため、まだ実装が追いついていない領域があります。そのため、場合によってはこれらの通信方式が得意な領域であっても、利用を避けた方が良いケースもあります。
どの手法もWeb APIのインタフェースを定義し、実際に定義どおりのリクエスト・レスポンスにすることは可能であり、その点においてあまり差違はありません。そのため、導入や運用にかかる労力や今後の拡張性、インタフェース以外への拡張などが、比較における観点となります。
最終的には、チームの練度やマイクロサービスの構成、既存資産などさまざまな面から検討して、ケース・バイ・ケースで結論を出すべきでしょう。ここでは、各手法の特徴をふまえて、それぞれが有効に働く場面をまとめていきたいと思います。
OpenAPI ─ Webフレームワークや既存の仕組みを活用したい
OpenAPI+REST APIが有効な場合について考えます。この手法の利点としては、学習コストが少なく、既存の仕組みを最大限に利用できるところです。
REST APIは、開発・運用ともに長年の知見に溢れており、問題が起きにくい、または起きても対処法が確立されていることが多いです。また、フレームワークや周辺ツール、APMやCDNといった各サービスのサポートも大きいため、少ない学習コストでそれなりのレベルのものを構成できます。
OpenAPIは、REST APIの拡張であり、既存資産の上にそのまま構築できるため、このような既存のフレームワークやSaaSなどとの連携がほぼ全て使え、選択肢が非常に多様です。そのため、次のような場合には、OpenAPIがかなり有効だと思います。
- Webフレームワークを採用しておりREST APIを作成するコストが低い
- Readが多くてCDNがとても効果的
各チームの練度がバラバラの場合でも、既存の知見を生かすことで問題に対処しやすいため、他の手法に比べて運用時の安定性も高いです。
ライブラリ選定の大変さやREST APIゆえのデメリットも
一方で、OpenAPI自体は書き方のルールでしかありません。実際の処理に影響を及ぼすには、エコシステム上にあるさまざまなツールの中から、自分たちの環境に適切なツールを選定し、組み合わせる必要があります。
スキーマを定義して開発するという点において、gRPCやGraphQLは、導入するだけでひととおりが入る“お任せ”的な手法です。それに対して、OpenAPIはアラカルト的な手法であり、ライブラリの選定などが必要な分だけ、難易度が高くなります。
また、OpenAPIはあくまでも既存のREST APIを拡張するものであるため、その枠組以上のことはできません。今回の話の本筋からはそれますが、gRPCやGraphQLはサーバプッシュなども機能の範囲に含まれるため、このような仕組みを入れたい場合は別の技術を導入する必要があります。
さらに、HTTPキャッシュといった既存のHTTPの資産の一部はWebブラウザと相性が良いものが多く、ネイティブアプリやSPAのバックエンドとしてのAPIサーバとして考えた場合には、REST APIで使えるものは限定的です。特に、マイクロサービス同士の通信ではキャッシュが効かないこと、もしくは通信がデータセンター内で完結することが多いと考えられるため、gRPCのような通信方式の方がパフォーマンスに優れています。
また、クライアント側で同時に取得したいリソースが大量に存在する場合、または頻繁に変わる場合はGraphQLが有効であるため、そちらを選択するのも良いと思います。
導入が容易でREST APIの力を最大限引き出す
まとめると、OpenAPI+REST APIは既存の有形無形の資産が多く、各種Webフレームワークとの連携も難しくないため、コストを抑えて導入でき、起きた問題に対しても対処がしやすいです。
しかし、REST APIの領域を超えた問題を解決することは難しいです。gRPCやGraphQLが解決しようとしている問題については、これらを用いた方がよりスマートに解決できるでしょう。導入しようとしているマイクロサービスにgRPCやGraphQLによって解決できる問題があり、開発や運用時の未知の問題に対して適切に対処するリソースがあるならば、将来的な発展を考えてこれらを利用するのも1つの選択肢です。
一方で、導入先のマイクロサービスでその領域が問題になっていない、もしくは十分なリソースを確保できないのであれば、OpenAPIを利用することで労力に対してとても良い結果が得られると考えられます。
gRPC ─ 対応している言語なら開発や通信効率が良い
gRPCが有効なときについて考えます。この通信方式は、もともとGoogleのデータセンター内で使われていたという出自からも分かるように、マイクロサービス同士の通信において、開発や通信の効率に優れたとても良い選択肢です。
また、静的型付き言語においては、生成したコードによって型を保証したり、IDEによる補完が期待できるため、開発者体験の向上も見込めます。OpenAPIやGraphQLでもシリアライズをProtocol Buffersにして通信効率を上げたり、クライアントライブラリを生成することで同じレベルの開発者体験は実現できますが、gRPCではそれらが全てフレームワークに含まれているため、導入・運用がとても楽です。
さらに、サーバプッシュなど、Web API以外の用途にも活用できるため、マイクロサービス全体の技術統一にもつながります。
gRPCはあくまでフレームワークであり、その上でどのようなRPCを行うかは利用者側に任せられています。REST APIではRESTという大きな方向性があったため、パスやHTTPメソッドによってある程度の方向性が決められましたが、gRPCにはそれがありません。
指針になるものとして、GoogleはAPI設計ガイドを公開しており、gRPCはREST APIと似た考え方でリソースを設定していくことが推奨されています。そのため、この方針に沿った形であれば、後述するGraphQLと比べて、設計の学習コストは相対的に低く抑えられます。

メインの開発言語で良い実装があるか
gRPCは規模が大きいフレームワークのため、良い実装がない言語において、自分で実装するのはあまり現実的ではありません。例えば、RubyのgRPC実装は他の方法と比べてまだ運用の難易度が高くなっています4。
また、通信まわりを全てフレームワークが隠蔽しており、シリアライズ形式もProtocol Buffersを用いているため、特に通信まわりに問題があった際のデバッグは、JSONと比べて困難です。通信にHTTP/2を利用するので、ロードバランサなどのミドルウェアや使用しているフレームワークがHTTP/2に対応していない場合、導入がより困難になります。HTTPレイヤのキャッシュのような仕組みも現状ではサポートされていないため、キャッシュ効率が良いアプリケーションの場合は、パフォーマンスの改善が見込めない可能性があります。
つまり、gRPCの良い実装がない言語をメインで使用している場合や、使っているWebアプリケーションフレームワークが対応していない場合は、かなりのリソースを実装や運用に割く必要があり、コストが高くなります。
なお、gRPCではREST APIのAPI Gatewayを作成できるため、クライアントとしてのみ接続するのであれば問題はありません。ただし、REST APIにすることでgRPCの良さが大きく削がれるため、メインの言語で使えないのであれば利用は避けた方が懸命です。
REST APIが必要なくライブラリのサポートが見込めるなら
まとめると、gRPCはIDLから実装を生成するため、宣言したとおりのスキーマになることが保証されます。通信のパフォーマンスもよく、導入によって大きな利点を高いレベルで得られます。
また、今回のテーマからはそれますが、ストリーミングなどWeb API以上のこともサポートしており、将来的にそのような機能が必要になったときにも簡単に導入できます。
REST APIを作る必要性がなく、かつライブラリのサポートが見込めるのであれば、検討してみる価値は高いでしょう。
一方で、良い実装がない場合は運用が困難だったり、アプリケーションによっては合わない場合があります。HTTP/2の運用経験や既存の資産の使い回しがあまり期待できないなど、利用者の立場によってかなり得られる利益が変わってくるため、現状はまだ全ての場合において勧められるわけではありません。
特に、Webがメインの場合、gRPC Webは厳密にはgRPC over HTTP/2とは違うため、相互に変換するプロキシサーバが必要になり、導入や運用コストが上がるため、注意が必要です5。
GraphQL ─ 従来のWebと異なる世界観を生かせるか
GraphQLが有効なときについて考えます。他の手法と比べたときの最大の特徴は、1リクエストで取ってくるデータをクライアント側で自由に変更可能であるところです。例えば、モバイル環境のように通信コストが高い場合、複数回のリクエストを一回にまとめられるため、通信回数の削減が見込めます。
また、取得データの変更がクライアント側のみで完結するため、サーバ側と歩調を合わせる必要がなく、クライアント側の仕様変更が激しい場合にはとても効果的です。
Facebook社やNetflix社では、iOS/Androidアプリケーションからの通信といったプライベートな用途に、GraphQLを使っています。一方で、Github社は公開APIとして採用しており、どちらの用途でも十分使えるようです。
マイクロサービスでGraphQLの良さが発揮できない場合
一方で、GraphQLはマイクロサービスとは相性が悪い部分があります。
GraphQLでは、取得するデータをクエリで表現することにより、クライアント側が自由にサーバのデータを取ることができます。そのため、大量のREST APIを抱えているサーバの場合、GraphQLにすることでクライアント側は一度のクエリでさまざまなデータを取得可能です。
しかし、マイクロサービスにおいてはモノリシックなシステムに比べて1つのサーバが提供するデータはそれほど多くなりません。そのため、個々のサービスの大きさによっては通信をまとめることができず、クエリの変更もほとんどなくなり、GraphQLとしての良さを発揮できなくなります。
ただし、これは巨大なマイクロサービスがいる場合や、後述するBFFでは効果が高いなど、状況によって活躍の度合いが変わります。
単一エンドポイントによるモニタリングやキャッシュの問題
GraphQLの思想はこれまでのWebと大きく違うため、既存のさまざまな知見や資産が有効にならず、十分な効果を得るまでのコストが高くなります。
例えば、GraphQLは単一のエンドポイントに送られたクエリを元に、処理系が全ての操作を行います。そのため、従来のモニタリング機構が想定している方法とは大きく外れており、クエリのパフォーマンスモニタリングを行うことは現状まだ難しいです6。
また、REST APIではリソースごとにHTTP層で透過的にキャッシュできますが、GraphQLでは別々のクエリで同じリソースを取っていたとしても、クエリの中身を解析するまでは分からないため、アプリケーション側でキャッシュ機構を作り込む必要があります7。
アプリやバックエンドの設計によって異なるメリット
GraphQLでは、アプリやバックエンドの性質や設計によって、享受できる利点が大きく変わります。
例えば、GraphQLではJSONをPOSTする形式が一般的なため、バイナリファイルアップロードといったJSONでの表現が難しい領域とは相性が悪くなります。
また、GraphQLではクライアント側で自由に取得するデータを変えられるため、画面ごとに必要なフィールドのデータだけを取ってくることで、通信のペイロードを減らすことができます。これは常時接続が期待できるブラウザアプリにおいては効果が高いですが、iOS/Androidアプリケーションといったオフライン機能の要望が高い場合や、モデル設計によっては効果が薄くなります。
例えば、ニュースアプリでは「記事一覧の画面に遷移したときに、記事タイトルだけではなく本文など記事に関するデータを全て取得する」ことで、オフライン状態でも記事詳細に遷移できるようになります。このような場合、GraphQLで個別にフィールドを制御する重要性は薄れます。むしろ、詳細画面の実装を一覧画面で気にする必要が出てくるため、実装としては複雑になるでしょう。
また、アプリ側がNULL安全な言語を利用している場合、NULLが混在すると別々のクラスにする必要があるため、よりフィールドごとの制御の効果が薄くなります。ただし、コンポーネントに必要な情報だけを持つクラスを定義する場合や、Viewに強く紐付いたデータ設計を行う場合は、必要なデータを必要なだけ取ってこられるため、フィールドごとの制御は非常に効果が高くなります。
設計がマッチするならGraphQLは良い開発・通信効率は優れている
まとめると、GraphQLはクエリによってクライアント側が1リクエストでデータを自由に取れるという世界観を実現するもので、これはREST APIやgRPCでは実現が困難だった概念です。そのため、「サーバ側はクエリで取れるデータの種類を増やすだけ」「クライアント側は用意されているデータから自由に取ってくるだけ」といった、他の手法では得られない開発者体験が得られますし、通信を一回にまとめられるため、通信効率も良くなります。
今回は省きましたが、GraphQLはサーバサイドプッシュの仕組みもサポートしているため、対応しているライブラリを利用すればREST API以上のことも実現可能です。
また、サーバ側はGraphQLの処理系が必須ですが、クライアント側はライブラリがなくてもクエリのデータを送信すれば利用可能であるため、gRPCと比べると導入しやすくなっています。ただし、GraphQLの処理系は複雑なため、サーバ側のライブラリが整っていないのであれば、利用は困難です。
一方で、GraphQLの良さを最大限活用するには、既存のリソース設計とは大きく違ったデータ設計をする必要があります。マイクロサービスにおいては、1つのサーバが持つデータの種類があまり大きくならないため、後述するBFFを導入しない場合は、本来のGraphQLの良さが削がれてしまうと考えられます。
また、モニタリングやHTTPキャッシュなど既存の資産との相性があまり良くないため、gRPC以上に既存の知見を生かすことが難しく、運用していく上での難易度は高いです。
GraphQLが解決しようとしている問題が効果的な場面であれば、他の手法に比べてとても良い開発者体験が得られます。しかし、個々のマイクロサービスの規模が小さい場合は効果が薄いです。データ設計の学習コストや、運用していく上での問題解決なども考慮すると、マイクロサービス同士の通信方式として採用する上では、用途に応じて享受できる利点が大きく変わるため、注意が必要です。
「複数の通信方式を組み合わせる」という選択肢も
OpenAPI(とREST API)、gRPC、GraphQLを紹介し、それぞれを比較しました。各通信方式は特徴や解決しようとしている問題が異なっており、得意不得意に差があります。
また、マイクロサービスにおいては「アプリ・サーバ間のように外部との通信なのか」「データセンター内などで完結するサーバ同士の通信なのか」によっても特性が変わります。そのため、1つの手法でマイクロサービスの通信全てをカバーするのではなく、適切に複数の手法を組み合わせるという方法もあります。
Backends For Frontends(BFF)をアプリ・サーバ間に
マイクロサービスにおいて重要な手法の1つとして、BFF(Backends For Frontends)というものがあります。BFFは、アプリからのリクエストを受け、バックエンドのサーバから必要な情報を収集・結合して、アプリの都合のいいように加工して返すサーバです。
BFFを使うことで、バックエンドは再利用しやすいプリミティブなリソース取得APIだけを用意すればよくなります。一方で、アプリは一度の通信で期待どおりに結合されたデータを取得できるようになります。BFFからバックエンドは基本的にデータセンター内のやりとりであるため、通信は安定していますし、並列で処理することでデータの取得時間の短縮化が狙えます。
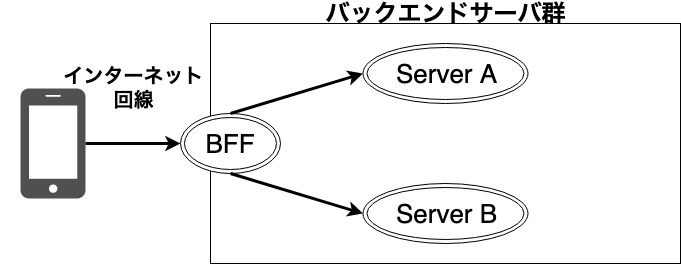
BFFを入れると、通信の種類が「アプリからBFF」「BFFからバックエンド」「バックエンド同士」の3パターンになります。それぞれの通信ごとに、複数の手法を組み合わせて利用できます。
組み合わせ1. アプリからBFFにGraphQLで通信する
例えば、アプリからBFFの問い合わせにGraphQLを使い、BFFがGraphQLを解釈して必要なデータをバックエンドに問い合わせるという形が考えられます8。
マイクロサービスにおいては、個々のサービスごとにデータが分散されるため、アプリ側はバックエンドのサービスを使い分ける必要があります。ですが、BFFがGraphQLのクエリで全てのリソースを取得可能にすることで、全てのデータを1つのクエリで取ることが可能になり、アプリからはマイクロサービスを意識しなくて良くなる利点があります。
アプリからはクエリを変えることで自由にデータを取得できますし、バックエンドは通常のREST APIで構築できるため、Webフレームワークやパフォーマンスモニタリングといった既存資産をそのまま使えます。もちろんバックエンドとの通信をgRPCで行い、通信パフォーマンスの効率化を狙うこともできます。
BFFからバックエンドの通信をRESTやgRPCで行う場合、GraphQLの利点である不要なフィールドを取得しないという機能がバックエンドへの通信では無効になりますが、多くの場合データセンター内通信なのでペイロードサイズが問題になることは少ないと思います。
さらに、GraphQLが提供する「クエリを変えれば、取るデータを自由に変えられる」という世界観をマイクロサービスにおいても最大限に生かせるため、それを補って余りある効果が期待できます。
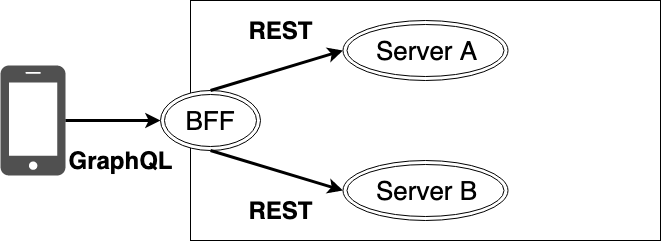
組み合わせ2. アプリからBFFにgRPCで通信する
他にも、アプリとBFF間の通信にgRPCを用いることで、通信の効率化を狙うことができます。アプリからBFFへの問い合わせは基本的にインターネット経由となるため、gRPCによる通信の効率化は魅力的です。
また、Web、iOS、Androidの全てに対応しているため、導入できればアプリ側の全てでこの仕組みを活用できます。対応している言語であれば、バックエンドへの通信をRESTからgRPCにするといった選択肢もあります。
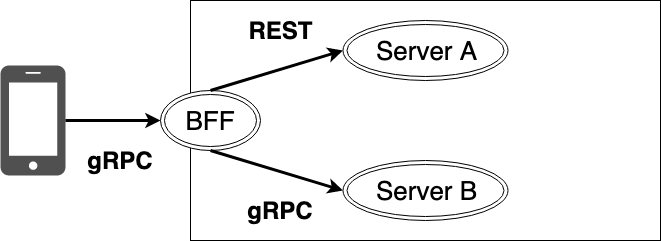
このように、マイクロサービスにおいては性質の違う通信が複数あるため、性質によって使い分けるのも1つの選択肢です。
ただし、今回紹介した手法はどれも何かしらの定義情報を書く必要があり、手法を使い分けると定義情報の使い回しができなくなるため、定義の二重管理や、相互変換可能なプログラムを使う必要が生まれます。
マイクロサービス同士の通信に何を採用するか
「マイクロサービス同士の通信に何を採用するか」にも、複数の選択肢があります。例えば、サービス間の通信は多くが同期的だったり大量だったりするため、通信効率が重要です。このような場合は、gRPCの利点がとても効いてきます9。
サービスが大量のデータを持ち、それらを複数取る場合が多いのであれば、GraphQLで取得するデータを自由に変えられるようにするのも1つの手です。マイクロサービスにおいて、個々のサービスごとに専用のエンドポイントを作る必要があるならば、クエリで自由に取れるようにすることで実装効率が良くなります。
ただし、マイクロサービス間が疎結合に保たれていれば、別のサービスの複数のデータに依存することはあまりないため、リソースをREST APIで定義すれば十分な場合もあります。BFFを導入した場合は、アプリの都合に合わせて結合するのはBFFが行ってくれるため、再利用可能なリソースを用意することが多く、バックエンド同士の通信にもそのまま利用できます。そのため、バックエンドでの通信は、方式をそろえた方が実装効率は良いです。
ただし、マイクロサービスでは複数言語を扱う場合もあるため、対応していない言語を利用した場合には、gRPCやGraphQL、REST APIなどの通信方式が入り乱れる場合があります。混乱を招かないように注意が必要です10。
おわりに ─ プラクティスや開発環境に応じて総合的に判断
ここで紹介した手法は、どれもスキーマを定義することでWeb APIの管理や開発者体験の向上が見込めます。しかし、それを実現するまでの労力は、知見の量やライブラリの状況によって大きく異なります。例えば、gRPCであれば、運用難易度はRubyでは高く、Goでは低くなります。OpenAPIであれば、定義を検証するライブラリの出来によって開発者体験は大きく変わります。
特に、gRPCやGraphQLは、これまでのHTTPの積み重ねの一部を捨てて新しい領域を作ろうとしている技術であり、アーキテクチャスタイルであるRESTとは違って、仕様や具体的な実装を含めたものです。そのため、成熟しているRESTと比べると学習コストが高く、他のシステムとの連携難易度や運用時に起きる問題の数、ベストプラクティスの量などに差があります。そのため、導入には大きなコストがかかるのが現実です。
ですが、日々新たな知見が公開されており、そういった問題も徐々に解消されつつあります。だからこそ、常に最新の情報を収集することが重要になります。例えば、Istio(+Envoy)のようなサービスメッシュを各クラウドプロバイダが提供しつつあります。これにより、gRPCの負荷分散、gRPC Webのプロキシサーバ運用のコントロールが楽になるため、gRPCの運用は以前よりも簡単になりつつあります。
GraphQLについても、AkamaiがCDNによるキャッシュに対応するなど、足りていない部分が徐々に補われつつあります。

また、OpenAPIのエコシステムも発展しており、Swaggerにのみ対応しているツールやフレームワークのOpenAPI 3対応、新たなライブラリの登場など、日々状況は変化しています。
今回の記事は、あくまでそれぞれの通信方式を選定するために必要な情報や、大まかな方向性を示すものにすぎません。そのため、自分やチームメンバーの技術に対する熟練度、使っている言語でのライブラリやフレームワークの完成度・情報量、開発のボトルネックがどこにあるか、開発や運用スケジュールなどと照らし合わせて総合的に判断してください。



【修正履歴】Schema First Developmentの綴を間違えていたのを修正しました(2019年8月22日17時)
厳密に言うと、Schema First Developmentはマイクロサービスとは関係なく、モノリシックなシステムに対しても有効な手法です。↩
Swaggerという名前はOpenAPIを利用するツールの名称として残っています。↩
フィールドマスクという似た手法がありますが、GraphQLと比べて自分で実装する部分がとても多く、別のエンドポイントのフィールドとまとめて取得できないなど、同じ目的に使うにはあまりにも使い勝手が違うため、ここでは触れません。↩
そんな中でも、クックパッドはかなり力を入れています。↩
例えば、EnvoyにはブラウザからのgRPC Webを変換してくれる機能があり、このようなミドルウェアを入れることでgRPC Webが使えるようになります。↩




