実践的インフラ監視&運用 - 4000万人以上のユーザーに快適なサービスを提供するピクシブの裏側
大規模サービスを安定運用するコツってなに?実運用に基づく知見をピクシブ株式会社のインフラエンジニア、末吉さんと小出さんに聞きました。
- ピクシブのサービスを支えるサーバーは大部分がオンプレミス
- 監視はNagiosとMuninでシンプルに
- 多数のリリースを支える独自のデプロイ手法
- 運用上のスペックは開発者との綿密なやりとりで決める
- 開発者と“温度感”を共有したい
システム運用は、生き物です。
人気が出ればリクエスト数は急上昇。経年劣化でサーバーが壊れることもある一方で、次々と新しいサービスも展開しなければなりません。規模が大きくなると、システムを障害なく運用することは至難のワザです。
大規模サービスを安定運用するコツは何か──その秘訣を探るべく、ピクシブ株式会社のインフラチームで活躍する2人に疑問をぶつけてみました。ユーザー数が4,000万人を超えた「pixiv」を、運用・監視する現場のノウハウとは。

- 末吉剛(すえよし・ごう/

- ピクシブ株式会社インフラ部所属。2018年7月入社。アプリからインフラまで、サーバーサイドを幅広く手がける。rubicure、Itamae、chatwork-rubyなど、多数のOSSを公開している。
- 小出周之(こいで・ちかし/

- ピクシブ株式会社インフラ部所属。2018年8月入社。サーバー構築・運用、システム改善など、オンプレミス環境メインで、さまざまなインフラ運用を手がける。
ピクシブのサービスを支えるサーバーは大部分がオンプレミス
──ピクシブ社と言えば、pixivをはじめBOOTHやVRoidなどさまざまな人気サービスを展開しておられます。まずは、これらのサービスを支える「インフラの全体的な構成」を簡単に教えていただけますか。
小出 フロントサーバー(ロードバランサー)、AP(アプリケーション)サーバー、DBサーバーというベーシックな3層構造が基本です。
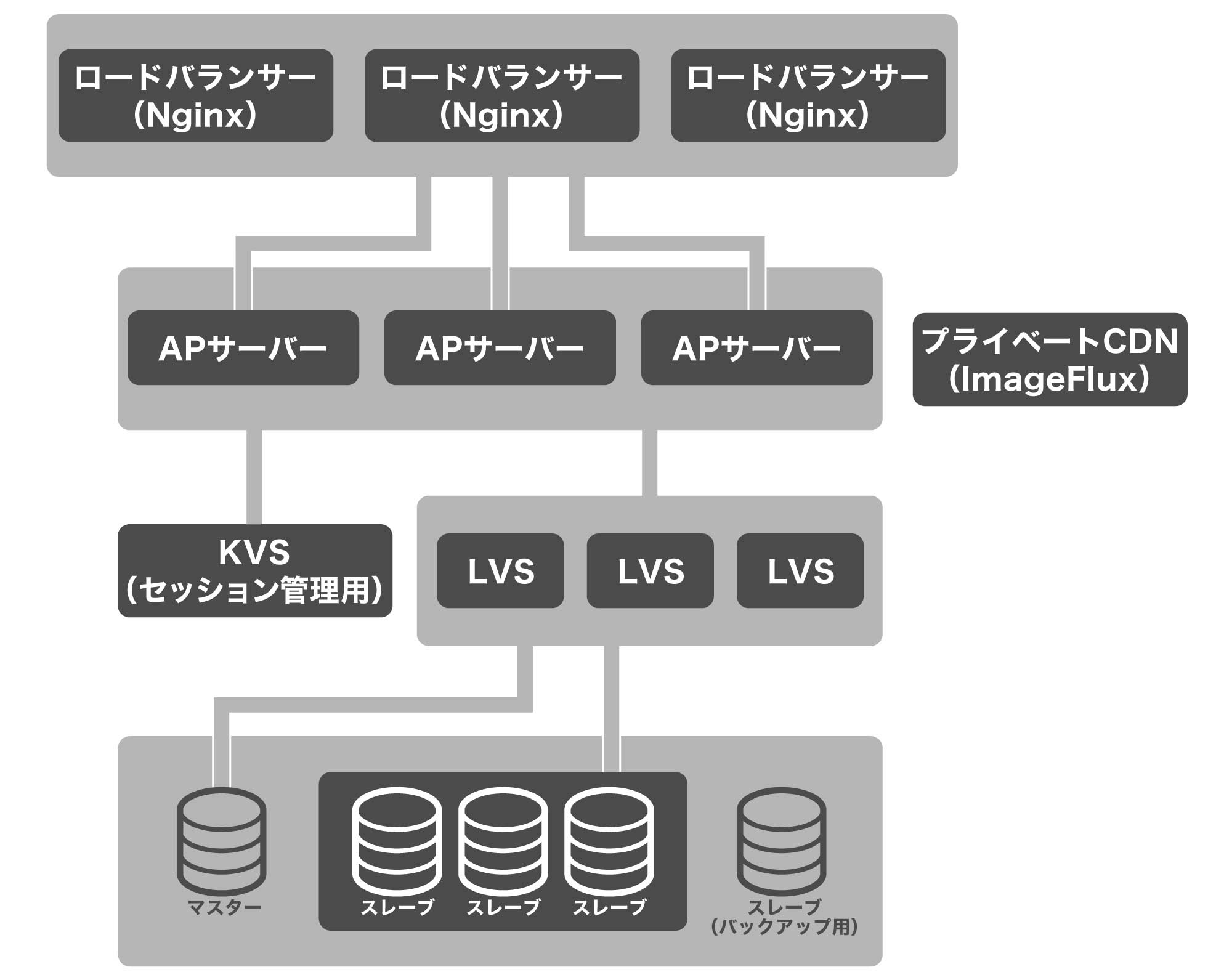
ユーザーからのリクエストは、まず、DNSラウンドロビンで、それぞれのフロントサーバーに分散され、Nginxロードバランサーで受けます。ロードバランサーには、配下のAPサーバー群がアップストリームとして定義してあり、それぞれのAPサーバーに負荷分散しています。APサーバーは、基本的に1サーバー1機能になっており、台数としては AP > フロントサーバーで構成されています。
DBサーバーはマスタースレーブ構成で、前段にLVSを配置して負荷分散しています。DBサーバーは全サーバーの中で最も台数が多く、役割に応じて細かく系統を分けて構築しています。また、DBとは別にセッション情報の管理として、KVSのRedisサーバーを使っています。
末吉 画像のキャッシュには、ピクシブとさくらインターネットさんで共同開発しているImageFluxという画像変換サービスのオンプレミス版を利用しています。これが、いわゆるプライベートCDNとして機能しています。
──サービスが大きいですから、サーバーの台数も多くなりそうですよね。運用はクラウドですか?
小出 サーバーは全部で300台ほどありますが、その9割がオンプレミスです。サービス環境ではコンテナや仮想化技術を使っておらず、まさに物理的なサーバーとして構成しています。クラウドはPawooなどの一部サービスや、短期的なイベント系など、突発的に負荷が高まるサービスや新規サービス立ち上げ時に利用しています。
──9割がオンプレミスなんですね! 運用は大変ではありませんか?
小出 大変ですね(笑)。ディスクやサーバーが故障するリスクもありますし……。もちろん故障リスクを前提にして横に並べているので、同一の系統内で数台は壊れても問題ない設計にしてあります。
なお、データセンターとはマネージド契約をしているので、故障時の対応はデータセンターに任せておける体制があります。僕らが直接ディスクを交換することはありませんし、サーバーのキッティングについても、依頼事項をまとめて申請すればデータセンター側で対応してもらえます。
末吉 そこから先は、僕らの作業です。と言っても、Ansibleを使って自動化しているので、一発でサーバーを構築できます。システムの構成変更が生じたときも、AnsibleのPlaybookを修正して適用するという流れになります。OSやミドルウェアのアップデートも同様です。

──データベースのバックアップは、どのようにされていますか?
小出 DBサーバーは、マスタースレーブによるレプリケーション構成をとっており、そのうちの1台を、ユーザーのリクエストを受け付けないスレーブサーバーとしています。このサーバーのデータを定期的にハードディスクに書き出すことでバックアップとしています。バックアップには、創業以来10年分のデータがぎっしり詰まっています。
──いままでデータベースが壊れたことはありますか?
小出 幸い、自分が入社してからはデータが壊れたことはありません。DBサーバーが落ちたということもありませんが、重いクエリが発行され詰まるということがまれにあります。しかし、仮に特定サーバーで詰まったりDBが落ちたとしても、障害が発生しているDBをLVSから切り離す独自スクリプトが動いているので、ユーザーに影響が出ることはありません。
──相当なアクセスがあると思うのですが、どれくらいの規模なのでしょう。
小出 あまり詳しくは言えませんが、DBサーバーの場合、平均すると大体秒間6万クエリで、ピーク時は秒間10万クエリ以上まで増えます。これはDBサーバー1系統分なので、システム全体で言えば、もっともっと大きな値になります。
──やはりすごい数字ですね……。安定して動かすのも大変そうです。
末吉 システムは安定していますが、Twitterなど外部でバズったりした場合ユーザーリクエストが急増しアラートが上がってくる、という全く予想がつかない局面もやはりあります。そういった場合でも迅速に対処し、そのフィードバックを随時行うことで日々運用を改善しています。
監視はNagiosとMuninでシンプルに
──300台ものサーバーを手作業で管理するのは困難だと思いますが、どのような監視ツールを使っていますか?
小出 サーバーの監視はNagios、リソースの監視はMuninを使っています。それ以外に全サーバーを統括して管理できるような自作のツールを使っています。
──既成のソフトウェアではなく、自作ツールを使われているのはなぜでしょうか?
末吉 やりたいことを全部やろうとすると、既成のツールでは実現できません。過去の経緯をすべて把握しているわけではないのですが、「ツールがないなら、自分で作ってしまえ!」という判断でしょう。昔は、OSSもありませんでしたから、自作することになったのだと思います。自作することで、自分たちの運用に合ったツールになっています。もし何か機能が足りなければ、フルスクラッチでソースを変更すればよいので使いやすいですが、社内でのメンテナンスコストの観点から一部既存のOSSやSaaSに移行しようとする流れになっています。
──異常があったことは、どのように知るのですか?
小出 SlackのIncoming Webhooksを使ってNagiosから通知が来るように設定しており、異常があった場合は、開発者が参加しているSlackの共有チャンネルにアラートが上がってきます。サーバーが落ちた場合は誰かが対応するまで1分おきに@hereでアラートが出続けるので、誰かが必ず気づけるようになっています。

──障害が発生したときは、自動復旧するようにしているのでしょうか?
小出 障害があったサーバーを切り離す、ここまでは自動です。ただ、復旧は自動ではありません。物理サーバーなのでハードウェア故障の場合もあり、完全に自動化するのは難しいですね。
──障害対策というと、情報共有も大事だと思うのですが、何か共有のための仕組みを用意していますか?
小出 各サーバーで動いているミドルウェアの情報やオペレーション手順はwikiで共有できるようにしています。それ以外に、VIP情報などを管理するネットワーク管理表や、インフラのみが知るべきアカウント情報をまとている管理表などもあります。
主要な障害フローについてもwikiに記載していますが、当然その時の障害の種類によって対応方法が異なってくるので、臨機応変な対応力が求められます。中には「この人しか分からない」ということもありますが、幸い、インフラチームのメンバーは皆意識が高く、障害時には瞬時にSlackに反応があるので、すぐに聞いて対応できる状態になっています。もっとも、これは属人的になっているため、今後、改善すべきところではあります。
──障害が発生したときのレポートは、どのように管理していますか?
小出 基本的にSlackベースで対応するので、やりとりをSlackに残すようにしています。ユーザーに影響が出る障害については、ユーザー対応が必要になるので、詳細な時系列や事象などが分かるようまとめ、全社員向けに共有しています。必要であればドキュメント化などもしています。
また外部からの攻撃などインシデントが発生したときは、セキュリティチームがいるので、そちらにエスカレーションします。
──運用にはログも大事だと思うのですが、どのように管理されていますか?
小出 まずフロントサーバーに関してですが、こちらはアクセスログとしてFluentdで一箇所に集約して管理しています。このアクセスログはBigQueryにも上げているので、必要に応じてここで集計し運用に必要なデータを作成したりしています。これ以外にも、公的機関などの要請によって過去ログが必要になるケースもあるため、別途、ハードディスクに保存して過去の全アクセスログを保管しています。
APサーバーのアプリケーションログについても同様に、Fluentdで集約して記録しています。このログについては常に監視しており、アプリケーションエラーの発生頻度に応じてSlackに通知を送るようにしており、問題が発生した場合でもすぐに気付けるようにしています。
多数のリリースを支える独自のデプロイ手法
──開発したアプリのデプロイ手順は、どのようになっていますか?
末吉 ピクシブは開発が盛んで、ほぼ毎週、何かしらの新しいリリースがあります。
各開発者が開発したら、それを開発環境にデプロイします。そして問題なければ検証環境にデプロイして確認、その後、本番環境にデプロイという流れになりますが、本番環境にはマイクロプロダクションという特殊な環境もあります。
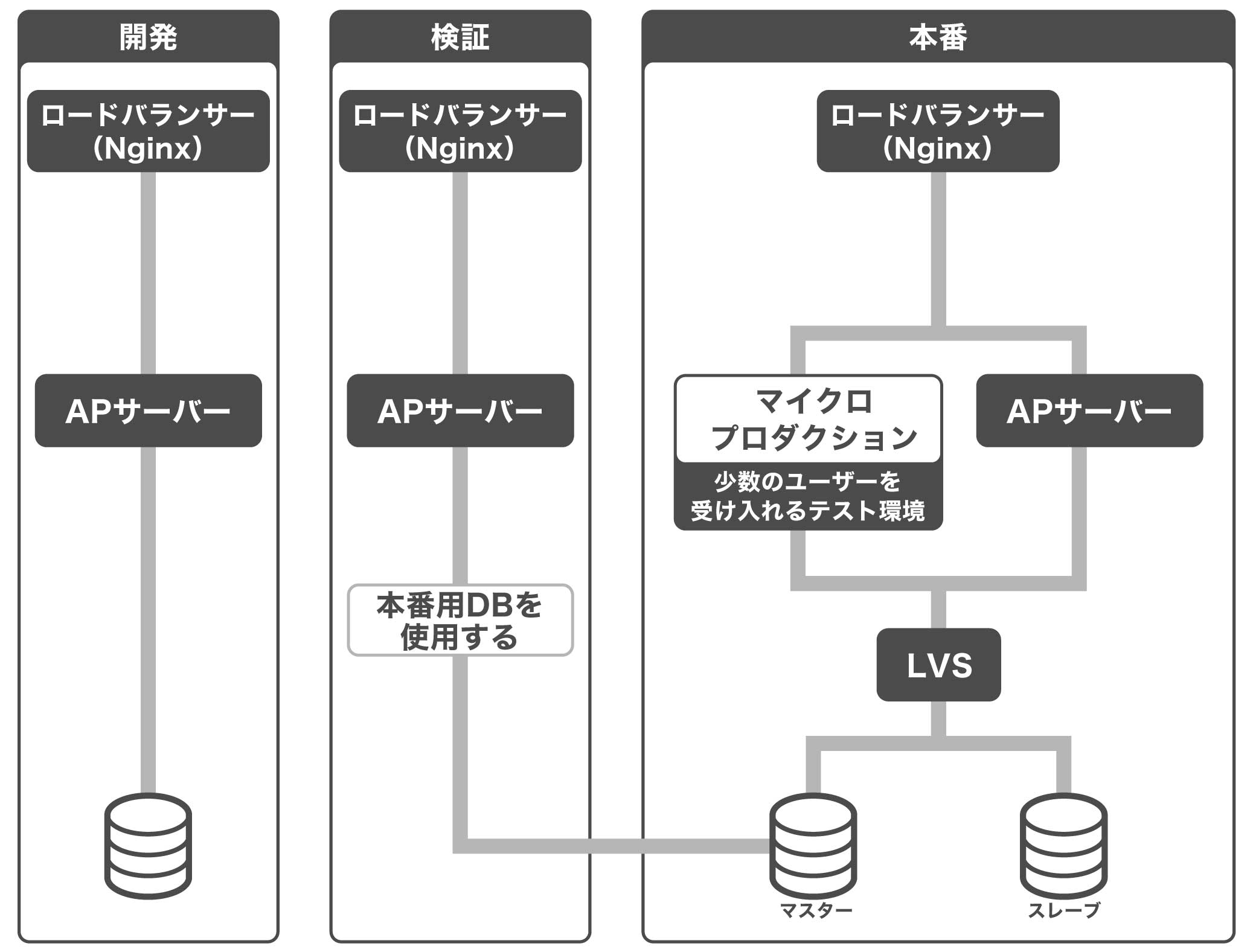
順に説明しますと、開発環境は、本番環境とは切り離された環境です。それに対して検証環境は、データベースは本番機のものを使っています。ですからここで、データに依存する不具合がないかどうかを確認できます。
──そうすると、もしデータベーススキーマに変更があるときは、検証環境でのテストの際、本番機のデータベースに手を加えなければならないということですね。
小出 そうなります。ユーザーから影響を受けないテーブルの追加などについては、この段階でデータベースを変更したうえで、検証環境でテストすることになります。
──「マイクロプロダクション」とは聞き慣れませんが、これは何でしょうか?
末吉 規模を小さくした本番環境です。Nginxのロードバランサーで、ごく少数のユーザーを、このマイクロプロダクションに振り分けるように設定してあります。つまり、全体に適用する前に、ごく少数のユーザーのアクセスを受け付けテストを実施する環境です。もし何か不具合があれば、このマイクロプロダクション環境から、エラーやワーニングが発生するので、問題が生じたことがわかります。
──デプロイは、誰でもできるのですか?
小出 はい。本番環境も含めて、全開発者が可能です。開発環境、検証環境、マイクロプロダクション、本番環境を順に確認しながら適用することで開発者自身が本番環境のデプロイまでを進めていきます。
ピクシブ社では「pploy」という自作アプリケーションを使用し、デプロイ作業をサポートする。
──開発者が本番機にデプロイできるというのは、インフラチームが知らないところでリリースされるということになりますが、困ることはありませんか?
末吉 開発環境、検証環境で開発者が確認しているので、大きな問題となることは少ないです。ただ、実施した改修によっては、いきなりAPサーバーやDBサーバーの負荷が急増することがあり、muninのリソースグラフを見て気付いたりするケースも多々あります。そういった場合はデプロイの時間と照らし合わせて特定し、関係者に肩ポンしに行ったりします(笑)。
本当は、もっと迅速にさまざまな変更ができるよう、開発者にsudo権限を付与したいと思ってはいます。しかし、インフラチームの知らない間に設定が変更され障害につながるリスクや、サーバーにある全ての情報にアクセスできるようになるので、運用・セキュリティの面で実現できていません。これも今後の大きな課題です。
運用上のスペックは開発者との綿密なやりとりで決める
──オンプレミスの場合、ハードウェアのスペックを検討する機会が多いかと思います。サーバーを構築する際、必要なスペックは、どのように決めていますか?
小出 大事なのは「ユーザーリクエストを無理なくさばき、ユーザーさんが快適に利用できる環境を維持する」ことです。なので、ユーザー数とリクエスト数をはじめ、処理時間の指標になるアップストリームからの応答時間、ネットワークのトラフィック状況などを見て、必要なサーバースペックや台数を判断しています。
特にpixivでは昼や夜の時間アクセスが集中するため、このピークタイム時のCPU負荷やトラフィック、それに加え、DBサーバーではディスクioやロック取得待ち時間、スロークエリなどを注視しています。
──試算の方法を教えてください。
小出 実際に少量リクエストをテスト的にかける、実際にクエリをかける、といった確認作業をします。一方で、蓄積されたナレッジも大事です。
まったく新規のサービスの場合は、当然事前に負荷試験を実施しますが、実際の負荷はリリースしてみるまで分かりません。ですから、クラウドで待機させた予備サーバーを用意したうえでリリースし、もしリクエストをさばききれないときは、待機しているクラウドを稼働させることもあります。
開発者との綿密なやりとりも、試算のために重要です。例えば、新規にVRoid Hubという3Dメイキングしたモデルをアップロードできるサービスを立ち上げるときは、ユーザー数の詳細な増加を、どのように見込んでいるかを開発側と密にやりとりしました。テスト、予測、開発側との連携を徹底したので、サーバーが足りないというようなことは、ほとんどありません。
──監視する場合、何を監視するのかもそうですが、どの値になったらアラートを出すのかという閾値を決めるのが難しいと思うのですが、何かコツはありますか?
末吉 例えば、CPUについては常時40%を超えた辺りから、そろそろ台数を増やさなければならないかを検討する、ネットワークについては帯域の60~70%利用ぐらいで台数を増やしてトラフィックを分散させるか、もしくは、10Gb Etherに変えるかなどを検討しています。オンプレミスなので、変更には日数を要します。ですから、先手を打てるよう、閾値は少し厳しめで運用しています。
開発者と“温度感”を共有したい
──良くない現場だと、開発者が運用に丸投げして、あとは運用でカバーというようなケースもありますよね。先ほどの話ですと、ピクシブさんの開発者とインフラチームの連携は風通しがよさそうですね。
末吉 インフラへの無理な依頼というのは、いままでありません。開発者もサーバー知識を持っている人が多く、各開発チーム側でサーバーリソースを考慮して実装しているので、ありがたいです。開発、インフラ間の垣根のなさが文化として根付いているのだと思います。とてもいいことです。

──インフラと開発者のコミュニケーションで重要なことはなんだと思いますか?
末吉 明確に指示してもらえるとうれしいですね。例えば、質問するときは、意図とゴールがあると効率的です。「これでいいですか」よりも、「こういうことをしたいが、これでいいですか」という聞き方をしてもらえると、適切な対応ができますし、こちらからよりよい提案もできるかと思います。
対応期日の明記も重要な情報です。「なるはや」とか「いつでもいい」というのは、実は判断に困ることもあります(笑)。また、提示された期日がバッファ込みなのか、本当のデッドラインなのか、など、優先度は正確に共有してもらえると助かります。
本当に必要なら、いま進めている作業を、なげうってでもやらなければなりません。それが僕たちの仕事です。だから、いま必要か今日中か、今週なのかなど、デッドというか“温度感”を伝えてくれると、お互いもっといい仕事ができるんじゃないかと思っています。
取材・執筆:大澤文孝
編集:澤田竹洋(リブロワークス)




