
低レイテンシと安定性を生むアーキテクチャ - SSPの現場に学ぶ、高可用性のつくり方
低レイテンシとは、広告配信の世界でユーザービリティ / 収益に直結する要素であることから、重要視されています。では、SSPの現場で実際に用いられるシステムはどのような構成になっているのでしょうか。fluct社の鈴木健太さんに、低レイテンシ、そして安定して稼働するシステムの基本を聞きました。
- 200msを目安にレスポンスを返す、低レスポンス設計
- オンプレミスとAWSを組み合わせてコストとスケールのバランスを保つ
- データのコピーをサーバーに入れ、独立化する
- 悪くなったところを捨てるのが、低レイテンシ・システム安定化の秘訣
- ログの集計はBigQueryで簡単に
- 悪くなったところは捨てて、全体を安定に動かす
レイテンシ(latency)とは、リクエストに対して応答を返すまでの時間のことです。レイテンシをできるだけ小さくすることは、ユーザーへのレスポンスを速める上で重要であり、Web・ネイティブアプリを問わず、ユーザーに対するスピーディなページ閲覧を実現するために不可欠な要素です。
低レイテンシが求められるシステムは多々ありますが、中でも広告配信は、低レイテンシが重要な指標とされる分野です。長年、広告事業を手がけ、さまざまな講演活動もされている株式会社fluctの鈴木健太(すずき・けんた/ 

- 鈴木健太さん
- 株式会社fluct 開発本部 本部長。大学院時代に旅のソーシャルWeb「trippiece」を開発し2012年、株式会社VOYAGE GROUPに入社。広告配信などを手がけ、2018年より現職。「次世代Webカンファレンス」のADをテーマとしたセッションでオーナーを務めるなど、Web技術に関する発表活動も精力的に行う。アウトプットの内容は自身のサイトに詳しい。
200msを目安にレスポンスを返す、低レスポンス設計
──最初に、fluct社が『広告配信』という枠組みの中で、どのような役割を担っているのか教えていただけませんか?
鈴木 一口に広告配信といっても、広告を出稿する広告主と掲載する媒体側の二者だけでなく、DSP、アドネットワークなどさまざまなプレイヤーがいます。この中で弊社は、SSP(Supply Side Platform)といって、Webサイトやネイティブアプリなどの媒体に最適な広告を自動で配信し、広告収益を最大化するためのサービスを提供しています。
──どのような仕組みで広告を配信しているのですか?
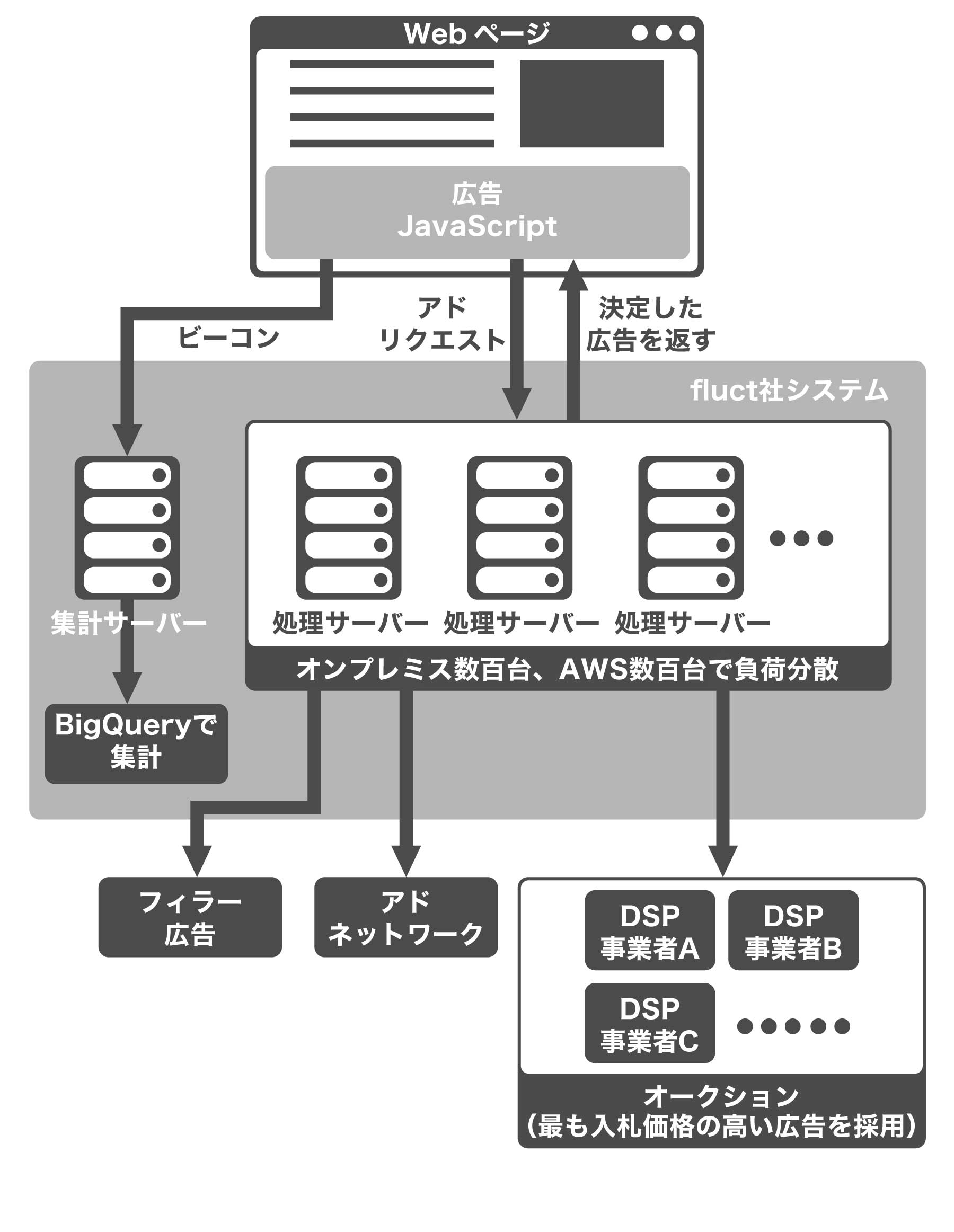
鈴木 広告を載せる媒体ページには、媒体を識別するIDを含んだJavaScriptが埋め込まれています。広告を表示するときは、このJavaScriptが、僕らSSPのサーバーに対して、アドリクエストと呼ばれるリクエストを送信します。サーバーはリクエストを受け取ったら、どのような広告を表示するのかを決定し、レスポンスとして返す──というのが基本的な流れです。
僕らのようなSSP事業者は、広告そのものは持っていません。広告はDSP(Demand Side Platform)やアドネットワークと呼ばれる広告配信事業者からもらってきて配信します。つまり、僕らのサーバーからDSPやアドネットワークにリクエストを送信して、媒体に載せる広告を決定します。
──載せる広告はどのようにして選んでいるんですか?
鈴木 複数のDSPに並列に問い合わせをして広告料金が高いものを返します。Webページにアクセスされて、表示されるまでのわずかな時間にオークションをするわけです。これが、「RTB(Real Time Bidding)」と呼ばれる仕組みです。
オークションの結果、勝者が決まらないこともあります。その場合は、アドネットワークの広告を出します。アドネットワークもないときは、純広告と呼ばれるフィラー広告が出ます。フィラー広告はCDNとして構成されています。
このように広告を配信する仕組みは多段になっていて、なんとしてでも広告を返すようになっています。
──広告は、クライアントサイドで生成されるのですか?
鈴木 そうです。サーバーから返すのは、どのような画像や動画、もしくはテキストを出すのかという情報だけで、画像や動画自体はレスポンスに含まれません。われわれは広告の動画や画像といった素材をそもそも持っていないので、それらの素材は、DSPやアドネットワークから取ってきます。
それをクライアント側のJavaScriptで、レクタングルや動画、インフィードなど、媒体に適した形の広告に生成しているんです。そしてその中に計測用のビーコンを入れ、広告がどれだけ表示されたのかを計測しています。
ときどき、インターネットを巡っていると、ページが表示されなかったり、白くなったりする現象に遭遇することがあるかもしれませんが、これは広告出力がうまくいかなかったり遅れたりするのが理由のひとつです。
──広告の遅れが、ページが正常に表示されない理由になるというのは、なかなかシビアですね。具体的に広告が表示されるまでに想定する秒数などの目標値はあるのでしょうか?
鈴木 「広告を表示するまで」については、具体的な目標値は設けていません。Wi-FiやLTEなどクライアントの回線環境に左右されてしまうからです。また媒体によっても仕様が変わってくるので、統一的な数値を作るのが難しいのです。
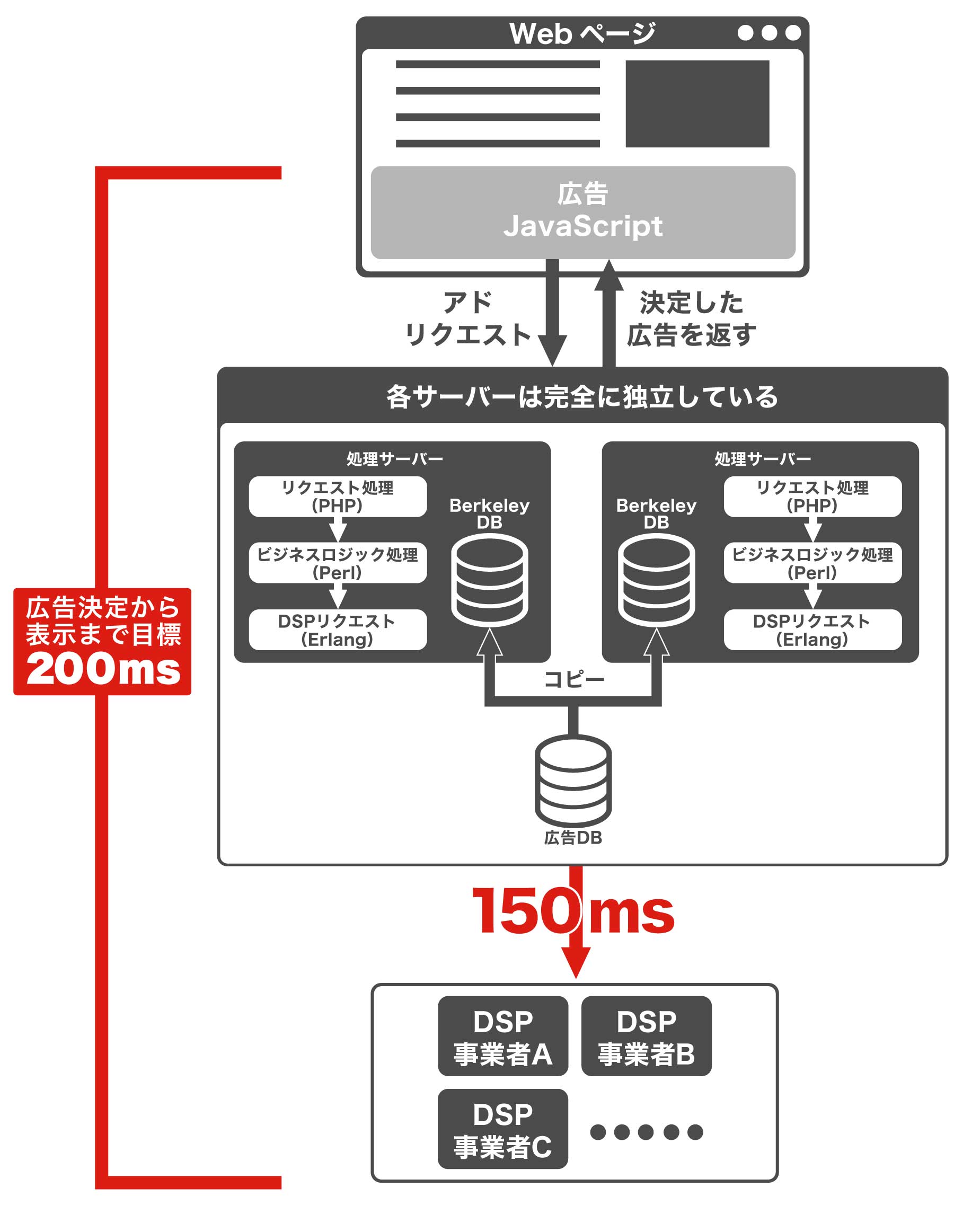
そこで代わりに、「リクエストをもらってから、レスポンスで何らかの広告を返すまでの時間」を目安として考えています。環境によっても変わるのですが、中央値として、おおむね200msです。時には1秒になることもありますが、3秒は、ちょっと長すぎるという感覚です。
オンプレミスとAWSを組み合わせてコストとスケールのバランスを保つ

──200msのレイテンシでどれくらいのリクエストを裁いているのかも気になるところです。
鈴木 おおよそ、秒間1万~2万リクエストです。ピーク時で秒間3万リクエストを想定しています。
──秒間1~2万リクエストというと、相当多いですが、負荷分散などは、どのように実装されているのでしょうか?
鈴木 ロードバランサーを用いて、オンプレミスで常時数百台程度、それに加えて、AWSが数百台稼働しています。AWSのほうはスポットインスタンスを利用しています。
──オンプレミスとAWSのハイブリッド構成なのですね。
鈴木 これはコストが大きな理由です。弊社のようなSSPでは、トラフィックは基本的に右肩上がりです。増えることはあっても減ることはないので、ミニマムで必要な処理能力が予測しやすいのです。このような場合は、オンプレミスのほうがコストを抑えらます。
一方でAWSは、いつでも追加できるので、変動的な負荷を処理するのに適します。ある程度、処理能力の増加がわかってきたところで、AWSのリソースを減らして、オンプレミスのリソースを増やすということもしています。また、AWSはすぐ使えるのが利点です。つい先日、オンプレミスで大きな障害が起きたのですが、そのときは、AWS上でサーバーを構築することで乗り切ることができました。
データのコピーをサーバーに入れ、独立化する
──オンプレミスとAWSを併用すると、機器の構成の違いなどが複雑になりそうな気がしますが、何か工夫はありますか? 特にネットワークを超えた広告データベースへのアクセスを考えると、遅延が発生しそうですが。
鈴木 オンプレミスとAWSとで、構成の違いはありません。どちらも同じ構成で、スクリプトを実行することで、すぐに起動するように作ってあります。
データベースへのアクセスに関しては、おっしゃる通りです。そのため、外部のデータベースにはアクセスはしないように設計しています。広告配信では、データベースに書き込む必要はなく、必要なのは読み込みだけです。そこで、それぞれのサーバーの中に、データベースのコピーを持たせるようにしています。このデータベースには、リレーショナルデータベースではなく、より高速にアクセスできるキーバリューストア型のBerkeley DBを使っています。
──サーバー間で通信をしていないということですか?
そうです。それぞれのサーバーは完全に独立しており、リクエストがあってから、応答を返すまで、DSPとの通信を除き、ほかのサーバーと通信することはありません。 ちなみに、現在、サーバーの中は、「リクエスト処理(PHP)」「ビジネスロジック処理(Perl)」「DSPへのリクエスト(Erlang)」の3層の構造になっています。
──それぞれの階層で言語が異なるのですね。
鈴木 これは歴史的な経緯が理由です。現状の課題のひとつでして、将来的にはGolangにまとめてしまってもよいかと考えています。
悪くなったところを捨てるのが、低レイテンシ・システム安定化の秘訣
──最初におっしゃっていたレイテンシの目安が「200ms」ということは、この、それぞれのサーバーにリクエストが来てから、レスポンスを返すまでが200msということですね。その時間を大きく超えそうなときは、どうするのですか?
鈴木 そのときはきっぱり諦めます。というよりも、システムでは、DSPへの問い合わせのタイムアウトを150msに設定し、それ以上、時間がかかるときは諦めて、DSP以外の広告──アドネットワークやフィラー広告、それもダメなら白紙の広告──を返すようにしています。
その理由は、2つあります。ひとつはできるだけ広告を迅速に返すためです。最初に説明したように、広告の表示が遅れると、ページ全体が白くなったり、不完全な状態で表示されたりする恐れがあります。そうすると、媒体に迷惑がかかってしまいます。それなら、われわれは白紙の広告であっても、短い時間で返すことを選びます。
もうひとつは、システム全体の負荷が、広告の表示遅れに引きずられて低下するのを避けたいからです。処理が終わるまで待っていると、次のリクエストを受け入れられなくなります。つまりロードバランサーのところで接続待ちのクライアントが発生し、待ち行列が発生します。待ち行列が長くなれば、どんどん負荷がかかり、ついには、システムが安定稼働しなくなる恐れもあります。
──低レイテンシを志向することが、システムの安定化にもつながるのですね。先ほど少し話にも挙がりましたが、障害も安定化のネックになりそうです。
鈴木 障害への対処はシンプルで、故障したサーバーを外してしまえばいいのです。個々のサーバーが独立して動いているので、システム全体への影響はありません。負荷が増えそうなときも、同じようにサーバーを追加すれば対処することができます。
ログの集計はBigQueryで簡単に
──システムの安定稼働にはログの集計や監視も欠かせないと思います。ログの集計は、どのようにされていますか?
鈴木 ログの集計は2つあります。ひとつは、サーバーのログで、この集計にはFluentdを使って集約しています。もうひとつは、広告の集計ログです。こちらについては、もともとは一度、それぞれのサーバーで集計して、その集計結果を拾うようにしていました。しかしいまは、BigQueryを使って集計しています。
──監視体制は、どのようにしていますか?
鈴木 New Relic APMを使ってアプリケーションのパフォーマンス監視をしています。またGrafanaを使って可視化しています。
こうした一般的なネットワークやシステムの監視ツールだけでなく、広告媒体ごとの配信ログも監視しています。広告の配信に異常があったときは、すぐに直したいと思っています。例えばある媒体で、リクエストが通常より極端に低かったりすると、広告が表示されていないといった疑いも出てきます。そういった局所的な問題についても、速やかに対応できるようにしています。
──ほかに何か異常にすぐに気付けるようにする工夫はありますか?
鈴木 ブラウザー側のJavaScriptでトレースするなど、エラーに気付けるものを仕掛けているのは、工夫として挙げられるかもしれません。
悪くなったところは捨てて、全体を安定に動かす

──最後に、低レイテンシを実現するための秘訣を教えてください。
鈴木 繰り返しになってしまいますが、確実にタイムアウトさせて終わらせることです。そして、そのときの代替方法を用意しておくことです。
例えば、サーバーの応答がないときなどに、隣のサーバーに接続するという方法も考えられます。しかしそうすると、今度は隣のサーバーの負荷が増えて、そのサーバーがまた隣のサーバーに接続し……という処理を繰り返し、全体の負荷が高まってしまいます。こうしたことがないよう、悪くなったところは切り捨てていくのが、低レイテンシを目指すために重要です。キャパシティに余裕がないときは、逃がすのではなく、諦めるのです。そのサーバーを切り捨ててでも、全体を生かすことを考えるべきです。
低レイテンシを実現することは、素早く処理できるということですから、結果的にはシステムの安定稼働にもつながると考えています。
取材・執筆:大澤文孝
編集:澤田竹洋(リブロワークス)




