SPAにおける状態管理:関数型のアプローチも取り入れるフロントエンド系アーキテクチャの変遷
関数型のアプローチも取り入れるフロントエンド系アーキテクチャの変遷について解説します。
こんにちは、小林(@koba04)です。
本記事では、シングルページアプリケーション(以下、SPA)における状態管理について解説します。
GmailやTwitterは、SPAとして構築されている代表的なWebアプリケーションであり、スムーズなページ遷移をSPAによって実現しています。またElectronやPWA(Progressive Web Apps)の登場により、複雑なアプリケーションをWebの技術を使って構築する場面も増えてきました。
これらの複雑なアプリケーションにおいては、既存のページ単位での状態管理の考え方では対応が難しくなります。
そこで今回は、具体的なフレームワークも取り上げながら、Webフロントエンドにおける状態管理のアプローチについて紹介します。
- フロントエンドでの状態管理の複雑化
- モデルとビューによる処理の分割
- 双方向データバインディングを用いた効率的なデータ更新
- Fluxによる一方向なデータの流れ
- 単一ストアと不変性による予測可能な状態管理
- ロジックから状態を切り離した世界が可能にするDX
- まとめ
フロントエンドでの状態管理の複雑化
SPA(シングルページアプリケーション)は、Wikipediaの「Single-page application」で下記のように紹介されています。
A single-page application (SPA) is a web application or web site that interacts with the user by dynamically rewriting the current page rather than loading entire new pages from a server.
つまり、新しいページに移動する際、サーバからページを再読み込みするのではなく、JavaScriptを使って動的にページを書き換えるアプリケーションを指します。
そのため、ボタンのクリックやテキスト入力などのイベントに対する部分的な画面更新だけでなく、これまでサーバーサイドが担っていたページコンテンツの生成を、JavaScript上で行う必要があります。その分、サーバー側はステートレスでシンプルになりますが、フロントエンドではさまざまな表示の更新処理を実装する必要があります。
URLの切り替えや、ページ履歴の管理については、History APIを使います。

SPAではページ遷移時にページ全体の再読み込みが発生しないため、シームレスなページ遷移が可能です。シームレスなページ遷移については、Portalsという新しいHTML要素の提案もあり、こちらも注目です。
portals/explainer.md at master · WICG/portals · GitHub
ページの単位を超えた状態の保持
SPAの場合、一度サーバからページが読み込まれた後は、JavaScriptを使って必要なデータをJSONなどの形式でサーバから取得して、表示内容を更新します。
これにより、サーバから取得したデータやユーザー入力などの状態を、ページ遷移時に破棄することなく保持できます。そのため、サーバーとやり取りするデータ量は最小限になります。また、ページ単位ではなくデータ単位でやり取りするため、Service Workersなどを使ったデータのキャッシュも考えやすくなります。
SPAでは、各ページのライフサイクルを越えて状態を保持する必要があります。通常のWebページの場合、ページ遷移すればブラウザ上の状態はリセットされますが、SPAの場合はリセットされません。そのため、状態のライフサイクルやビューのライフサイクルについて適切に管理する必要があります。
例えば、ページ切り替え時にDOMに対するイベントリスナーの解除を忘れた場合には、SPAではメモリリークの原因となります。SPAでは、ページ切り替え時にも再読み込みが行われないため、メモリリークがあると、使用メモリがどんどん増えてしまいます。そのため、ブラウザのDevToolを利用し、メモリリークが発生していないかについても注意する必要があります。
このように、SPAの登場によりJavaScript上で複雑な更新処理を行う必要が出てきたため、さまざまなアプローチでこの問題を解決しようとするライブラリが登場しました。
モデルとビューによる処理の分割
Backbone.jsは、アプリケーションを「モデル」と「ビュー」に分割する機能を提供するフレームワークです。モデルは、自身の状態が変化した場合に、変更イベントを発行します。ビューは、モデルの変更イベントを購読して、表示を更新します。
テキストの入力やボタンのクリックといったユーザーインタラクションがあると、ビューがモデルを更新します。その結果、モデルがイベントを発行し、それを購読しているビューの表示が更新されます。
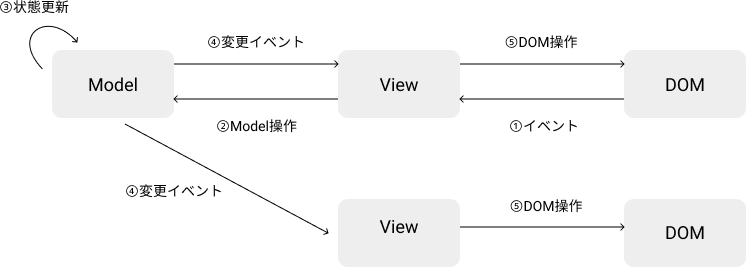
Backbone.jsの更新フロー
イベントを通じて他のオブジェクトに変更を通知するパターンは、「オブザーバーパターン」と呼ばれます。このようにオブサーバーパターンとしてイベントを通じてやりとりすることで、モデルとビューのロジックを分離できます。
その結果、モデルはビューを意識する必要がありません。ビューは、画面表示とモデルを操作するだけで、実際のデータの更新処理については知る必要がありません。これにより、モデルとビューの責務を分離できます。
Backbone.jsは、他にもコレクションやルーターといった要素を持っていますが、アプリケーションの構成として中心になるのはモデルとビューです。いわゆるMVCとして分類すると、画面表示を行うV(ビュー)とイベントを処理するC(コントローラー)の部分を、ビュー(一部ルーター)が担っています。
イベントの管理が複雑になる問題も
Backbone.jsのアプローチでは、それぞれのモデルとビューがオブザーバーパターンを使い、イベントでやりとりすると述べました。
この場合、あるモデルの状態が変わると、そのモデルの変更イベントを購読している全てのビューの更新処理が呼ばれます。そのため、ビューの数が増えて構造が複雑になると、モデルの状態が変更された時に何が起きるか(どのビューが更新されるのか)の把握が難しくなります。
加えて、モデルが別のモデルの変更イベントを購読して処理することも可能であり、その場合はそれぞれのモデルの変更イベントを購読している全てのビューが更新されるため、より把握が難しくなります。
また、関連のあるビューだけが更新されるようにするためには、ビューを細かく分割し、それぞれモデルの変更イベントを購読する処理を定義する必要があり、コード量も多くなってしまいます。
双方向データバインディングを用いた効率的なデータ更新
AngularJS1や、Vue.jsは、双方向データバインディングを特徴としたフレームワークとして登場しました。双方向データバインディングでは、データがモデルとビュー間でビューモデルとして紐付けられる形となります。
具体的には、ビューモデルが持つデータを更新すると対応するビューが更新されて、ビューの値を更新すると対応するビューモデルが更新されます。
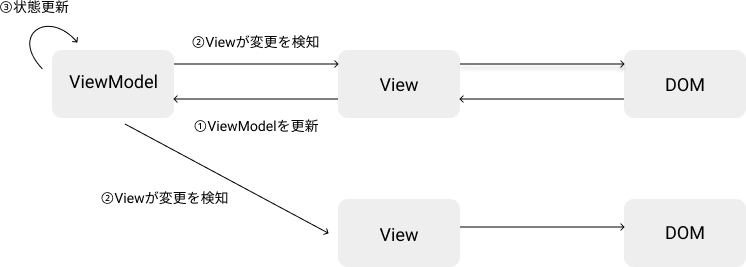
双方向データバインディングの更新フロー
双方向データバインディングを利用することで、ビューとデータを同期するためのコードを書く必要がなくなります。しかもその際、データに関連のあるビューだけが更新されるため効率的です。これは、Backbone.jsのアプローチで問題となる、細かい粒度でのビューとモデルの関連性の管理から開発者を解き放ってくれます。
双方向データバインディングは、管理画面のような入力が多いアプリケーションの開発を楽にしてくれます。その反面、暗黙的にモデルとビューが更新されるため、アプリケーションが複雑になってきた場合、「何が起きているのか」の把握が難しくなります。特に、複数のビューから参照されているモデルがあるような場合、問題があったときのデバッグは難しくなります。
このアプローチでは、アプリケーションの開発を簡単にしますが、それを提供しているフレームワークの実装は複雑でブラックボックスになりがちです。これはフレームワークが想定する一般的なユースケース以外のことをやろうとした場合や、パフォーマンスチューニングが必要になる場面では問題となることがあります。
Fluxによる一方向なデータの流れ
双方向データバインディングにより、細かい粒度でのビューとモデルの管理を、開発者自身が行う必要はなくなりました。ですが、「状態が更新された時に何が起きるのか」という点については依然明確ではありません。むしろ暗黙的になったため、より把握が難しくなります。
それを開発するアーキテクチャとして、Facebookが2014年に発表したのが、Fluxです。Fluxの特徴は下記の図にある通り、データの流れが一方向であることです。
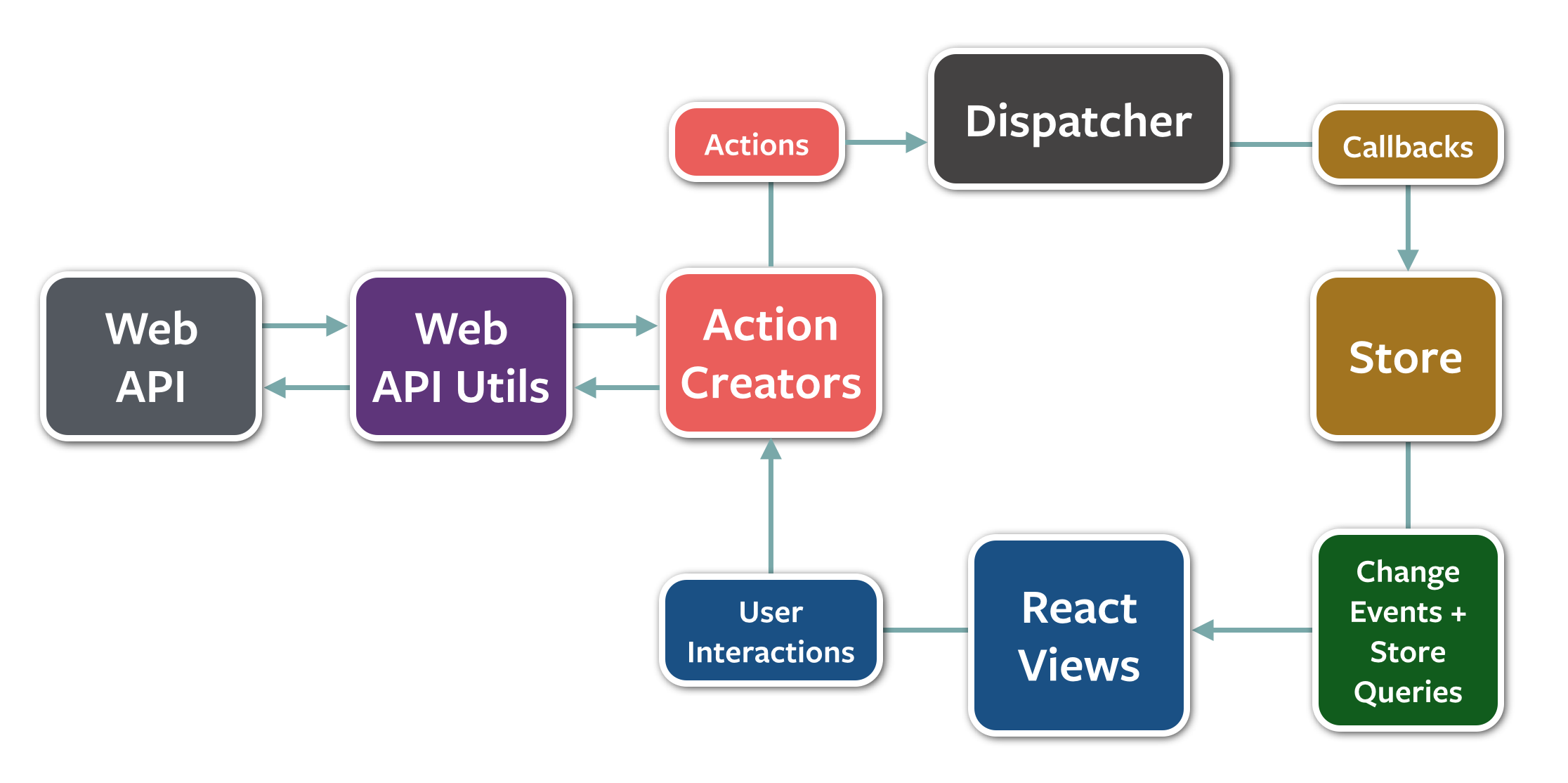
Flux: An application architecture for React utilizing a unidirectional data flow.
Fluxにおいて、更新のフローは下記の通りです。
- ビューがイベントを発行する
- アクションを発行する
- 発行されたアクションをディスパッチャーがストアに伝える
- それぞれのストアが、受け取ったアクションが関心のあるものであれば状態の更新を行う
- 状態を更新したストアは変更イベントを発行する
- ビューは関心のあるストアの更新イベントを受けて表示を更新する
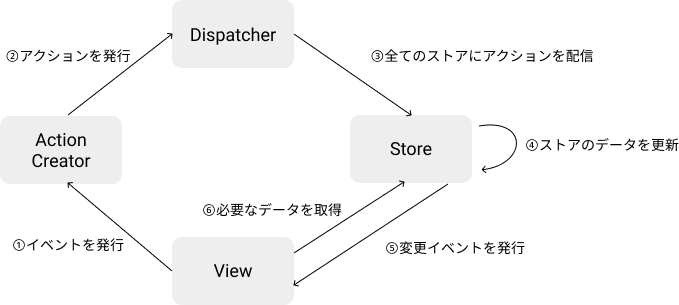
Fluxの更新フロー
これまで紹介したアプローチでは、モデルとビューの間で双方向にやりとりが行われていました。また各々のビューとモデルがそれぞれでやりとりを行うため、状態の把握が難しくなります。
Fluxではデータの流れが一方向であるため、見るべきポイントが明確になり、各構成要素の役割も明確になります。
また、全ての更新処理がアクションとして表現される点もFluxの特徴です。全てのアクションは単一のディスパッチャーを経由してストアに配信されるため、ディスパッチャーで発行されるアクションを監視すれば、アプリケーションで何が起きているのかは一目瞭然です。
これまで紹介したアプローチに比べると、要素も多く、その分書くコードの量も多くなります。これは、各要素を単純化して状態管理の流れを明確にするためのトレードオフです。コードは書くよりも、その後読まれる方が多く、楽に書けるよりも、その後把握しやすい方が重要であるという思想が背景にあります。
Fluxでは、アクションをコマンドパターンとして実装します。アクションは発行するだけであり、結果は受け取りません。結果はストアの更新イベントを受けたビューがストアから受け取ります。
つまり、アクションを発行するためのコマンド(上記の図ではActionCreator)と、結果をストアから受け取るためのクエリーの部分が独立します。そのため、コマンドとクエリーを実装する際には、それぞれの責務だけを意識すればよくなるため、複雑性を減らすことが可能です。
Reactが可能にしたこと
Fluxでは、状態の変化を一方向な流れで表現することが可能になります。しかし、これだけでは各ビューがそれぞれストアからデータを取得する形になり、コード量が増大し、複雑化してしまいます。
双方向データバインディングでは、フレームワークがデータとビューの依存関係を把握していることで、関連のあるビューだけを効率的に更新することを実現していました。
この問題に対して、Reactをはじめとした、ビューのレイヤーで差分適用を行うライブラリを用いて解決する方法があります。
Reactでは、詳細は割愛しますが、各コンポーネントをUI = Component(Data)な関数として表現できます。これらのコンポーネントを組み合わせることで、ビュー全体もUI = View(State)という巨大な関数として表現できます。
差分更新の仕組みを持たないライブラリの場合、ビュー全体を関数として扱うと、常にビュー全体のDOMが更新されてしまいます。これは、パフォーマンスやDOMの状態の保持で問題となります。
Reactは、前後のコンポーネントの状態を比較して、差分のみをDOMに適用するため、開発者は上記のようにビュー全体を1つの関数として表現できます。
したがって、FluxとReactを組み合わせることで、ビューの部分をただの関数として扱うことが可能になるため、よりアプリケーションの状態変化を単純化できます。React自体もデータを親から子に渡してイベントを子から親に伝える一方向な流れとなっており、Fluxはそれをアプリケーションレベルで適用するものと考えることもできます。
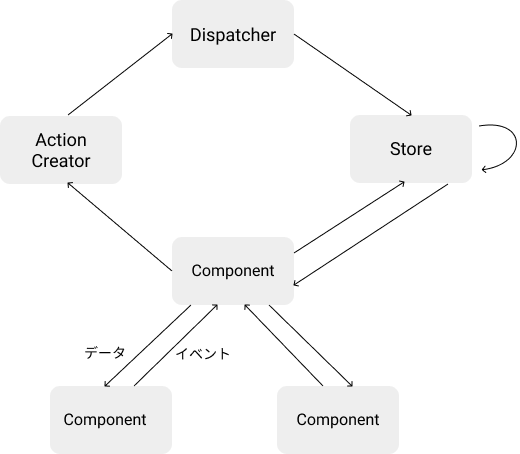
ReactとFluxの更新フロー
イベントの処理方法
アクションをストアに伝えて、ストアの変更イベントをビューに伝えるための仕組みの実装には、いくつかのパターンがあります。
最も一般的なのは、オブザーバーパターンを使い、単純なイベントとしてやりとりする方法で、この場合はNode.jsの標準ライブラリであるEventsなどで実装できます。
ブラウザ上ではイベントが非同期に連続的に発生します。そのため複数のイベントを組み合わせたり、イベントの流量を抑えたり、といった制御が必要とされる場合があります。
そこで、RxJSのようなライブラリを使い、イベントやアクションをObservableを使って制御する方法もあります。この場合もFluxの流れは変わりません。
Cycle.jsは、これをよりシンプルに、イベントとアクションをストリームとして扱っているライブラリです。
単一ストアと不変性による予測可能な状態管理
Fluxはアーキテクチャであり、Fluxを実装したフレームワークは、Fluxの発表後たくさん登場しました。その中でも現在広く使われているのは、Reduxです。
Reduxは、FluxやElmの考え方をベースにした、状態管理のためのライブラリです。
公式サイトでは「A predictable state container for JavaScript apps」と紹介されています。特徴としては「Predictable」「Centralized」「Debuggable」「Flexible」の4つが挙げられています。
他のFluxを実装したフレームワークと大きく異なる点は、ストアを1つしか持たないことです。また、サーバーサイドレンダリングにも対応できるように、リクエスト毎にストアを作成できる構造になっています。
状態を単一のJSONオブジェクトとして保持
Reduxではストアは1つであり、ストアが持つ状態は巨大なJSONオブジェクトとなります。またストアが持つ状態は、イミュータブル(不変)なデータ構造として扱います。つまり、状態を更新する際には常にオブジェクトを再作成します。
状態を単一のJSONオブジェクトとして保持するメリットは何でしょうか。
1つは、Reduxも特徴として挙げているPredictable(予測可能)であることです。状態が1つのオブジェクトに集約されているため、そのオブジェクトを見れば、アプリケーションがどんな状態なのかが分かります。
アプリケーションの状態が正しいにもかかわらず、意図しない結果が画面に表示されているとしたら、それはビューのロジックに問題であることが分かります。つまりView = Application(State)という形になります。
しかしながら、ストアが単一でアプリケーション全体を巨大なJSONオブジェクトとして表現する場合、状態の更新処理も巨大になってしまうことが予想できます。
Reduxでは 、状態をreducerと呼ばれる、アクションを受けて状態を更新する関数を組みあわせること(Composition)で、構築します。
reducerは下記のような関数です。
newState = reducer(state, action);
これは下記のように組み合わせることが可能です。
const usersReducer = (state, action) => {...};
const itemsReducer = (state, action) => {...};
// ネストさせることも可能
const settingsReducer = (state, action) => ({
shortcut: (state.shortcut, action) => {/* ... */},
language: (state.language, action) => {/* ... */}
});
const newState = (state, action) => ({
users: usersReducer(state.users, action),
items: itemsReducer(state.items, action),
settingns: settingsReducer(state.settings, action),
});
/*
newStateは下記のような構造を持ったStateになる
newState = {
users: [...],
items: [...],
settings: {
shortcut: {...},
language: {...}
}
}
*/
これにより、Fluxでストアを分割するように、更新処理を関数として分割することを可能にします。これは、Fluxでの難しさの1つであった更新時のストア間での更新順の制御を、reducerに親子関係を作ることで制御可能にします。
また、状態をイミュータブルなデータ構造として扱い、データ更新時には常に新しいオブジェクトを返すことは、Undo/Redoの実装を簡単にします。さらに「アクションでのみ状態が更新される」「イミュータブルなデータ構造」という特徴により、過去の任意の状態に戻って再開する「タイムトラベルデバッギング」が可能になります。
状態や副作用のないただの関数
Reduxは、アプリケーションの多くの部分を、状態や副作用を持たないただの関数として実装することを可能にします。状態については、巨大なJSONオブジェクトして表現すると述べました。それでは、副作用はどうすればいいのでしょうか。
これについては、Redux自体には組み込まれていないため、さまざまなアプローチがあります。
本記事ではこのようなリンクでの紹介のみとしますが、興味があればそれぞれのアプローチを確認してみてください。
Reduxでは、アプリケーションを構成する要素の多くの部分をただの関数として表現することで、予測可能(Predictable)であることを実現しています。また、ただの関数であることで、テストも簡単に書くことができます。
ロジックから状態を切り離した世界が可能にするDX
Reduxは、ブラウザのDevToolの拡張として、先ほど述べたように「任意の過去の状態に戻りそこから再開」する機能を提供しています。
また、Redux DevToolsでは、記録されたアプリケーションの状態やアクションの履歴を、JSONファイルとしてエクスポート・インポートすることも可能です。これにより、手元で不具合が発生した場合に、その時の状態を記録して、他のメンバーに共有できます。
さらに、ユーザー環境でエラーが発生した場合に、エラーが発生するまでのアクションの履歴や状態を送信し、それを使ってエラーを解析することも可能です。
下記は、エラートラッキングサービスであるSentryで紹介されている、ReduxのMiddlewareの仕組みを利用したエラー解析の方法です。
Rich Error Reports with Redux Middleware | Product Blog • Sentry
webpackのようなツールを使うことで、アプリケーションのコードをブラウザのリロードなしに反映させるHMR(ホットモジュールリプレイスメント)が可能です。HMRとタイムトラベルデバッギングを組み合わせることで、更新処理(アクションの流れ)を記録し、それをリピート再生しながらアプリケーションの更新ロジックを実装することも可能になります。
下記は、そのコンセプトを表現したPull Requestです。

このように、アプリケーションのロジックを、可能な限り状態を持たないただの関数にすることで、アプリケーションを予測可能にするだけでなく、開発を助けるさまざまなアプローチが可能になっています。
まとめ
本記事では、フロントエンドにおける状態管理の変遷について解説しました。
紹介したFluxやReduxのようなアプローチは、Vue.jsやAngularとも組み合わせられるなど、広く採用されています。
また、TypeScriptなどの静的型付けを行う言語の存在も重要なポイントです。FluxやReduxのようなアプローチでは、多くの部分がただの関数となるため、入力と出力が重要になります。その際、静的型チェックが行えることや型情報をもとにした補完が可能であることは、開発の生産性に大きく影響します。
本記事では取り上げませんでしたが、Fluxのようなコードの読みやすさを重視したアプローチとは別に、リアクティブなアプローチを採用するフレームワークも存在します。
興味のある方は、上記のフレームワークを参照してみてください。これらは、本記事で紹介した双方向データバインディングの流れをさらに進めるようなアプローチを取っています。
Webブラウザというプラットフォームの進化
SPAの登場により、Webアプリケーションでもページという制限を超えた表現や状態管理が可能になりました。
その反面、これまでは考える必要のなかった「状態」とは何かについて考える必要が出てきました。これには、URLや、ブラウザのヒストリ、スクロール位置といったこれまでブラウザに任せていたものも含まれます。
ユーザーにとって「ページ」という概念は変わらず存在します。ユーザーの期待を裏切らない形で、これらの「状態」を管理し、これまでのWebの体験を壊すことなく、リッチなユーザー体験を提供する必要があります。
このように複雑化した状態管理を行うために、関数型の考え方や単一責任の法則に沿ったアプローチがフロントエンドでも使われるようになりました。それと同時に、開発をサポートするためのアイデアや開発ツールも発展してきました。今やフレームワークが開発ツールを提供することは、当たり前のものとして認識されています。
ブラウザというプラットフォームも進化しています。Service WorkersやWebAssemblyなど、プラットフォームとしての可能性や選択肢がどんどんと広がっています。これらは設計に多様な選択肢を提供します。そのため、これからはより広い視点でフロントエンドのアーキテクチャを考える必要があるでしょう。



受託開発やゲーム開発を経て、サイボウズにてプロダクトを横断したフロントエンド開発に取り組みながら、SmartHRでフロントエンド技術顧問としての活動も行っている。React本体や関連するOSSにも積極的にコントリビュートするほか、React.js meetupを主催する。
最新版はAngular.jsではなく、Angular(https://angular.io/)です。↩




