
Python“らしさ”を支える技術。pandasコアコミッターが大事にするマージの方針
数多いPythonライブラリの中でも、データ解析の用途で大きな存在感を示すのが「pandas」です。そしてこのpandasのコミッターを務めるのが、sinhrksこと堀越真映さん。コミッターが感じるOSSのありよう、そしてPythonらしさを教えてもらいました。
データサイエンスや機械学習の流行に伴い、業務でPythonが使用されるケースが増えてきました。Pythonが選ばれる理由はさまざまですが、「データサイエンスや機械学習に適したライブラリが数多くある」という特性は、この言語が重宝される理由のひとつでしょう。
たとえば、データ分析のための高速で使いやすいデータ構造を提供するpandas。NumPyやpandasのAPIを利用して並列計算・分散処理を行えるDask。こうした海外で開発が主導されたライブラリが、Pythonの隆盛に貢献してきましたが、日本にもpandas、Daskのコミッターがいるのです。データサイエンティストの堀越真映(ほりこし・まさあき/ 
堀越さんは何をきっかけに、OSSコミッターとなったのでしょうか。そして、彼の考える「データサイエンティストとして成長するために必要な要素」とは? 本稿では、彼のたどった道筋をふり返っていただきました。
- キャリアのスタートは、エンジニアでもデータサイエンティストでもなかった
- その変更は、Pythonの流儀に沿っているか?
- 思い出に残る、データ結合処理のバグ修正
- データサイエンティストを形作るもの
- 「継続しよう」と考えずに「今日だけやろう」と考える
キャリアのスタートは、エンジニアでもデータサイエンティストでもなかった
──堀越さんは、やはりデータ分析に関連した業務からキャリアをスタートしたのでしょうか?
堀越 いえ、実はキャリアの始まりはエンジニアでもデータサイエンティストでもありませんでした。大学が情報系なので、学生時代にプログラミング言語に触れてはいたものの、新卒入社した会社で配属されたのは海外向けの技術サポートや技術営業などを担当する事業部でした。最初はプログラムを書く仕事をメインではやってはいなかったですね。
──そこから、データ分析に携わるようになったのはどうしてですか?
堀越 自分の担当業務を改善するためにデータを見始めたのが、データサイエンティストとしての出発点です。仕事でプログラムを書くようになったのもそこからでした。
分析業務に携わるならプログラミングのスキルをもっと上げなければダメだと思い、業務外の時間を使って勉強することにしたんです。「何をして勉強すべきだろう」と検討した結果、自分が普段使っているライブラリの中身を解読するのが、スキルを上げるには効率がよいだろうと考えたのです。

堀越真映さん:2008年に大学卒業後、メーカー系企業に就職し、サポートエンジニアとしてキャリアをスタート。その後、同企業内でデータ分析の業務に従事するようになる。2016年に外資コンサルティング企業に移籍し、籍はそのままに、現職のARISE analyticsに参加。データ分析技術のスペシャリストとして活躍する他、現在では後進のデータサイエンティストの育成も担当する。
──なるほど。それでPythonライブラリのソースコードを読むようになったわけですね。
堀越 そうです。だから、OSSコミッターになろうとかそういうマインドで始めたわけではありませんでした。でも中身が理解できてくると、徐々に「こんな機能を足してみよう」とか「機能の不整合が目につくから直していこう」と、気になるところがたくさん出るようになって(笑)。そして、徐々にOSS開発にコミットするようになっていきました。
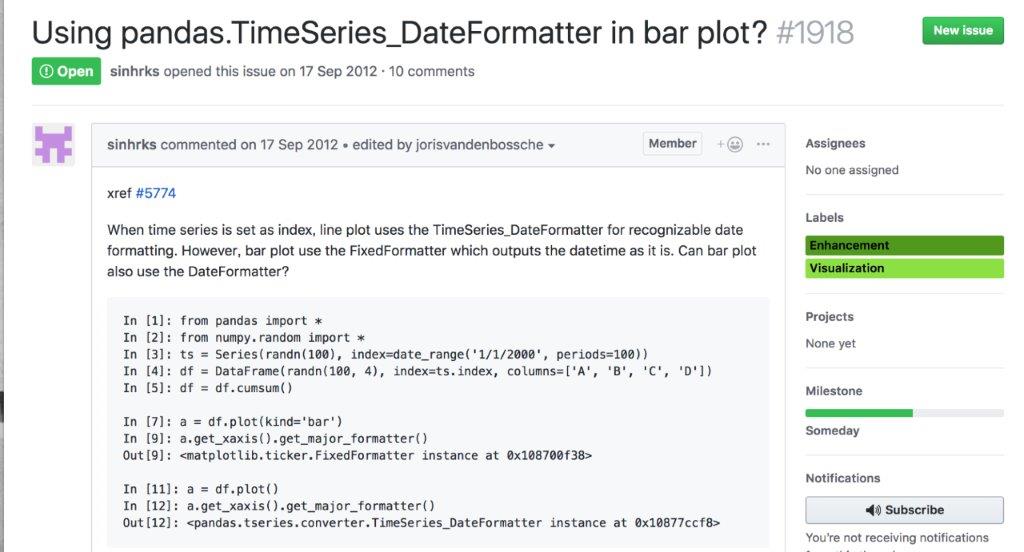
▲堀越さんが最初に起票したチケット1は「棒グラフで日付をラベルにした際のフォーマットをより良いものにしたい」という趣旨のIssueだったという。
その変更は、Pythonの流儀に沿っているか?
──pandasの各メソッドは、非常に直感的に使える分かりやすいAPI設計になっています。良質な設計を守るために、コミッターの方々はどのようなことを意識してライブラリをメンテナンスしているのでしょうか?
堀越 メンテナンス以前の根本的な部分をお話すると、pandasの設計が優れているのは、そもそも制作者であるWes McKinney( 

それから、「表形式のデータを扱う」という意味では、すでにリレーショナルデータベースという優れた仕組みが存在しています。RDBの仕組みを先行情報として参考にできるので、pandasでは予想外の機能が出てきにくいという側面もあるでしょう。
──いわば、pandasの場合は同じ種類の問題を解いている先駆者がすでにいたわけですね。では、機能を追加する際には、どのような基準で「入れる」「入れない」を取捨選択していくのでしょうか?
堀越 バグ修正は当然ながらマージされます。機能追加の場合はケースバイケースですが、例えば「現状のライブラリのままでは不便なことがある」「いまのAPIの互換性を壊さずに簡単に解決できる方法がある」「それをリーズナブルな手段で実現できている」などの条件を満たしている変更ならば、マージされることが多いです。
それから、メンテナンスする人々の負荷を無駄に増やさないのも大事な方針です。例えば、世界の中でも珍しい、特定の分野だけで使われているファイルフォーマットがあり、「その種類のファイルのI/Oを追加してほしい」というPull Requestが出されたとします。これをマージしたとすれば、将来的に誰もメンテナンスできなくなる可能性が高いですよね。そういうものは取りこまれないことが多いです。
それから先ほどの質問でも少し出ましたが、「処理が直感的にわかりやすいかどうか」はレビューでも重視されています。例を挙げると……
- 不要なオプションを足さない
- 単純な関数の直感的な組み合わせで実現できることを、あえて1つの関数にまとめない
- 1つの処理はなるべく1つのことだけをやる
こうした要素は、コミッターたちが確認している重要な点ですね。
──それらの方針は、pandasのみならず他のライブラリの設計においても重要なことですね。
堀越 また、「便利だけどPythonの思想に合わないからあえて外す」というケースもあります。これは、Rと比較した方がよさそうですね。ちょっと簡単なコードを以下に示します。
Pythonの場合
df[df['month'] == 12].groupby('day')['visitor'].sum()
Rの場合 df %>% filter(month == 12) %>% group_by(day) %>% summarize(sum(visitor))
Pythonで何かの処理を行う場合には、「インスタンス.メソッド」のような書式でメソッドを呼び出します。
一方でRの場合は、ロードされたパッケージの関数はグローバルの領域に置かれているので、関数名をパイプオペレータ%>%で連結する記法がよく使われます。例えば「df(データフレーム)」という変数に表形式のデータが格納されていて、そこから「month列の値が12のもの」を抽出するとしたら、df %>% filter(month == 12)のように記述するイメージです。
Pythonで同様の処理を書くならばdf[df.month == 112]のような形式になります。dfが冗長になってしまうため、長い変数名だと読みにくくなってしまいます。こういったケースにおいて、「よりシンプルに書けるように、条件式中での元データの参照を簡潔にするための特別な名前(X)を追加できないだろうか」という課題提起をするIssueが、pandasで起票されたことがありました。
▲こちらがそのIssue「API: port the magic X from pandas_ply/dplython to pandas proper?」。
確かに便利な場面はありそうですですが、「今ある方法にさらに別のやり方を足すのはPython的ではない」という結論になり、取り下げられることになりました。
──「Pythonのスタイルに沿っているか」は、他のPython系ライブラリでも重視されている方針なのでしょうか?
堀越 Pythonとしての「ふるまいの一貫性」は大事にされていると感じます。
例えば、数値を合計する処理を例に挙げると、Pythonの標準ライブラリにはsum関数があり、pandasにもNumPyにも同様に合計を取る関数があります。それらが「同じようにユーザーの期待する動作をするか」は守るようにしているんです。
他の関数でも、Pythonの標準ライブラリで似た処理をするものがあるならば、それとなるべく同じようなふるまいになるように気をつけていますね。

思い出に残る、データ結合処理のバグ修正
──コミッターたちが大事にする「方針」がよく分かります。では、これまで携わってきたなかで、印象に残っているIssueやPull Requestはありますか?
堀越 自分が担当したものの中では「BUG: concat/append misc fixes」というPull Requestが印象に残っています。これはデータ結合処理のバグを修正するものでした。異なるデータ型同士を結合する際に、本来あるべき結果にならない不具合があったんです。
異なるデータ型同士の演算では、「どんな結果を返すべきか」を定義するのがなかなか難しいんです。例えば、int型の列にfloat型の列を追加する場合はどんな結果になるのか、int型にdatetime型を追加する場合はどうか、1つひとつ考慮しなければいけません。
細かい話をすると、pandasはdatetime型を内部的にはint型として扱っていて、ユーザーの目に見せるときだけintの値を日付時刻表示に変換しています。だからint型にdatetime型を追加すると、datetime型がint型に変換されてしまう、といった事象が起きたりしました。
ユーザーの視点から見ると、int型の列にdatetime型の列を追加したならば、int型とdatetime型の2オブジェクトが格納された配列(object型の配列)ができるのが自然な挙動だと思います。そういった細かい不具合を少しずつ解消していきました。
でも、データ型まわりの処理は整合性をとるのが大変なんです。ある部分を直したら別の部分でマイナーバグが出て、それを直したら別のマイナーバグが出て……という感じで修正は本当に苦労しました。すべての作業を終えて、テストがきちんと通ったときは嬉しかったですね。
──苦労した修正だからこそ、喜びもひとしおですね。
堀越 こういった課題は、場当たり的に直そうとすると、各モジュールに似たようなソースコードが散在してしまったり、仕様の不整合が残ったりします。それを防ぐには、コミュニティ内できちんとコンセンサスを取った上でプロジェクトを進めるのが大事になります。そのプロセスは大変だけれど、非常に刺激的です。
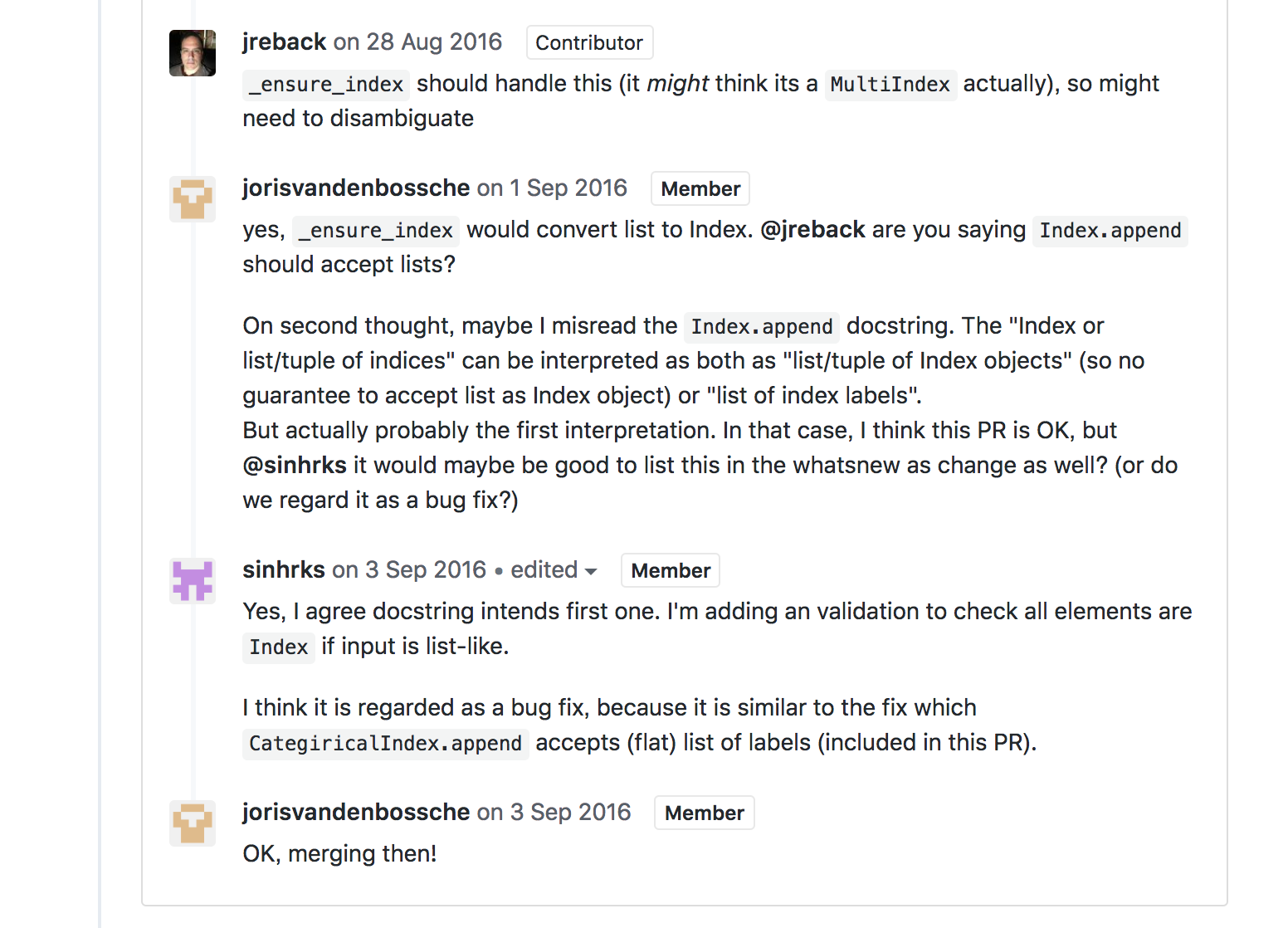
▲堀越さんの言葉どおり、本修正でもレビュアーとの密なやりとりが行われている。
──多くの人が関係するOSS開発において、プロジェクトを円滑に進めるために工夫していることはありますか?
堀越 チケットに処理結果の実例を書くことですね。私は母国語が英語ではないので、GitHub上で海外の方々とやりとりをする場合、自分の意図と異なる形で情報が伝わらないように気をつけています。他のコントリビューターの方々からコメントをもらうときでも、サンプルコードがあると本当にありがたく感じますね。
データサイエンティストを形作るもの

──堀越さんにとってOSS開発に取り組むことは、データサイエンティストとして成長するための方法のひとつだったわけですね。ではデータサイエンティストを目指す上で「このスキルを磨いておいた方がいい」と思うものはありますか?
堀越 データサイエンティストと一言でいっても幅広くて。例えば、特定の事業部と並走しながら部署の課題を解決するタイプの方々と、画像認識などを用いて新しいサービスをつくるタイプの方々とでは、そもそも求められる特性が違うと思うんですね。
その前提でお話しますが、私が勤めるARISE analyticsでよくいわれているのは、コンサルティングスキルとデータ分析知識(機械学習、統計など)、プログラミングスキルの3つが非常に重要だということです。コンサルティングにおいては、お客様や自社の課題をきちんと理解し、ビジネスとして何を実現すべきなのかを俯瞰できるスキルが求められます。ただ、これは実務を経験しなければ鍛えるのが難しい側面があるので、個人で勉強するならばデータ分析とプログラミングの2つでしょう。
機械学習と統計は密接に関係しており、明確な境界はないと思います。すぐに実戦投入したいというニーズがあるのならば、統計をすっ飛ばして機械学習ライブラリの使い方を学び、実装した結果を誰かがレビューするのが近道だとは思います。
ですが、機械学習の手法を正しく活用するには統計の知識が必要になるので、基礎の部分を鍛えるならば統計は身につけておくことをおすすめします。統計をやっておくことで、データについての根本的な考え方や、データリテラシー的な部分が身につくという側面もあります。
基本的なスキルを持った上で新しい知識をキャッチアップし続けられる好奇心のある方なら、それはデータサイエンティストに限らず、何をやったとしても成功できるのではないでしょうか。
「継続しよう」と考えずに「今日だけやろう」と考える

──OSSにコントリビューションすることに心理的なハードルを感じる方もいると思います。どうすれば、そのハードルを乗り越えられるでしょうか?
堀越 「継続しよう」と考えずに「今日だけやろう」と考えるのが重要だと思います。コントリビュートし続けなければ、と意気込んでしまうと、後々つらくなってくると思うんです。
そうではなく「今日は2~3時間くらい空いたから、少しだけリポジトリを見てみようかな」とか「ユーザーイベントがあるから1度だけ参加してみようかな」という感じで取り組んでみて、楽しかったら続けるくらいの気持ちで十分です。私も最近は活動の頻度が落ちていますが、できる時に少しずつ作業をしよう、という気持ちで臨んでいます。
それから私がおすすめするのは、最初からバグ修正のような難易度の高いことをやるのではなく、ドキュメントやエラーメッセージの文言修正など処理そのものに影響の出ない部分から始めることです。コミッターの立場からすると、そういった軽微な修正でもPull Requestを投げてくれると本当に嬉しいんです。
特にドキュメントに関しては、実装を知っている人が書いているがゆえに、かえって利用者にとって必要な情報が抜け落ちてしまうケースもあります。わかりやすいドキュメントに変えてもらえると、非常に助かります。
また、コーディング規約に沿って記法を直すような修正もいいと思います。どんなライブラリでも、大量のファイルのなかにはコーディング規約が守れていないものもあるので、それを整形してもらえるだけでも十分嬉しいコントリビュートなんです。pandasでは、コーディング規約にそった書き換えを行いつつ、CIで規約のチェックを行うといったPull Requestもマージされていますね。
──気負わずに、自分のできる範囲から始めればよいのですね。最後に、OSS活動を行うことにどのようなメリットがあるか、堀越さんの考えを聞かせてください。
堀越 まず、技術力の向上につながるのは間違いないです。世界中にいるスキルの高いエンジニアから、自分にない視点、社内ルールでは得られない視点でのソースコードレビューを受けられます。レビューのプロセスを通じて、プログラミングのスキルをかなり磨くことができます。
業務のなかで、なにかしらのライブラリを使う際、裏側でどんな処理が走っているかをイメージできるようになるので、より効率的なソースコードの書き方ができるようになります。
──実務上のメリットも大きいのですね。
堀越 もうひとつ、コミュニティのなかで自分の存在を認知してもらえることによって、知り合いが増えたり、イベントなどで声をかけてもらえるのは非常にありがたいことだと思っています。
最近それを実感したのは、海外のイベントに行ったときです。2017年にPyConというPythonの科学計算系イベントが開催されたのですが、そこでpandasをはじめ、有名OSSのコミッターの方々と直接お会いしたり、会場の方々と意見交換をすることができました。そういったときには、「OSSの活動をやっていてよかった」と強く思いますね。
取材・執筆:中薗昴
【修正履歴】
- 本文中の誤字をご指摘により修正しました。〔2019年1月30日〕
2019年1月現在も修正中。↩




