
自然言語処理をサービスで活用しよう! Sansanに学ぶ「多種多様なテキスト」からのデータ分析
自然言語処理をサービスに投入し、“できること”とは?名刺管理サービス「Sansan」を提供するSansan社では、名刺に記載された情報のデータ化において、自然言語処理を徹底的に活用しています。同社のデータ統括部門DSOCで日夜研究を続ける奥田裕樹さんと高橋寛治さんの2人に、サービスの裏で動く、自然言語処理のユースケースを語っていただきました。
名前や企業名、電話番号、メールアドレス──。名刺のなかには、重要な個人情報がテキストの形で記載されています。
そういった情報や企業のWebページ情報などを解析し、ユーザーに有効活用してもらうべく研究開発を続けているのが、法人向けクラウド名刺管理サービス「Sansan」や個人向け名刺アプリ「Eight」を提供するSansan株式会社です。同社はいわば、日本でも有数の自然言語処理に注力する企業なのですが、どのような手段でサービスに自然言語処理を組み込もうとしているのでしょうか?
Sansanのデータ統括部門であるDSOC(Data Strategy & Operation Center)で自然言語処理の研究に携わる奥田裕樹さんと高橋寛治さんに、これまで取り組んできたプロジェクトや、用いてきた手法について徹底解説してもらいました。

- 奥田 裕樹(おくだ・ゆうき/写真左)Sansan株式会社 DSOC(Data Strategy & Operation Center)、R&D Group 研究員
- 奈良先端科学技術大学院大学修士課程修了。大学院ではバイオインフォマティクス領域にて遺伝子の発現解析などを研究し、前職では機械学習や自然言語処理を用いた企画・開発に従事。現在は、研究分野にとらわれず、さまざまな機械学習の技術をプロダクトに活用する道を模索している。
- 高橋 寛治(たかはし・かんじ/写真右)Sansan株式会社 DSOC(Data Strategy & Operation Center)、R&D Group 研究員
- 長岡技術科学大学大学院工学研究科 修士課程 電気電子情報工学専攻修了。在学中は、解析ツールの研究開発や機械翻訳の評価手法の考案など、自然言語処理の研究開発に取り組む。現在は、キーワード抽出など自然言語処理に関連する研究開発に従事。
- どの企業に関する記事か? を自動的に判別する
- 名字と名前をニューラルネットによって分割する
- 特徴語抽出により、自社社員の強みをキーワード化する
- 自然言語処理を学ぶ、効果的なインプット方法
- Sansanのデータ分析は、総合格闘技だ
どの企業に関する記事か? を自動的に判別する
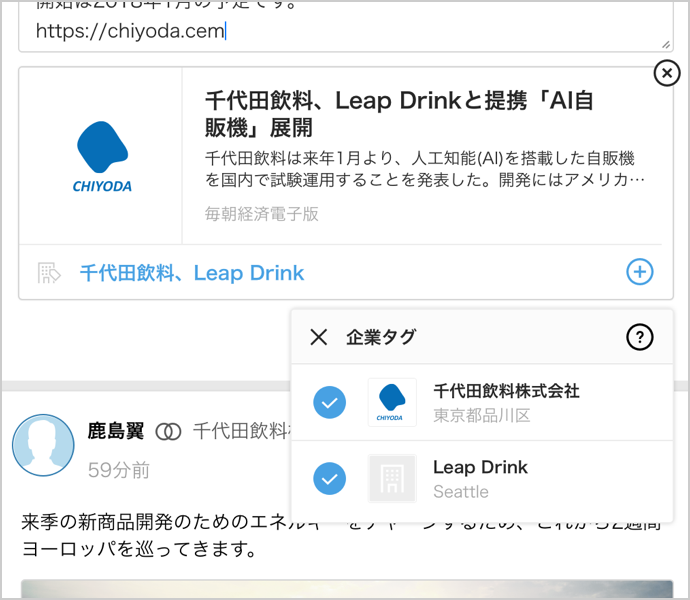
個人向け名刺アプリEightでは、過去に名刺を交換した人の近況や企業ニュースをフィード機能で知ることができる。ユーザーが関連企業ニュースを投稿する際、企業とニュースを紐付ける企業名の抽出に、自然言語処理が用いられている。
──フィード機能を実現するために、どのような手順を踏んでいるのでしょうか?
高橋 フィードの機能は、大きく次の3つのステップに分かれています。
- 投稿された記事のURL情報をもとにページのHTML情報を取得する
- HTML情報からタイトルと本文を抽出する
- 本文から企業名を取り出す
現在、3.を実現するための開発を続けています。いま動作しているものは、企業名の辞書登録やブラックリストの作成、省略語辞書といった素朴なルールを用いて対応しています。
──実装にあたり、苦労した部分はありますか?
高橋 いくつかありますが、まずは2.で適切に本文を抽出する処理です。後々のメンテナンスを考えなければ、各サイトの仕様に合わせて「○○のタグがあった場合には△△の中身を抽出する」といったような条件分岐をひたすら書いていけばいいでしょう。
ですが、その実装方法ではページ構造が変わった場合のメンテナンスがさすがに大変です。可能な限りメンテナンスの手間を省力化できる実装方法を検討しました。

──どのような方法が候補に挙がったのでしょうか?
高橋 最初は、機械学習を用いて系列ラベリングによってタグ付けをしていく方法も候補に挙がりました。ですが、サイボウズ・ラボの中谷秀洋さんが行っていた「CRFを使ったWeb本文抽出」という先行研究を発見したため、採用を断念したんです。


この研究では、系列ラベリングを解く手法であるCRFではあまり精度が出ず、うまくいかないと記載されていました。その代わり、HTMLタグの入れ子具合を数値化して、その閾値によって文字列を取得する・しないを決める手法は精度もパフォーマンスもよく、さらに中谷さんはExtractContentという本文抽出用のRubyモジュールも実装・公開されていました。
そこで、中谷さんが検証された内容を参考に、HTMLタグの入れ子具合をもとに判定する手法をとりました。私の作業は大きく2つで、既存スクリプト†のPython 3対応と、パラメーターの調整です。
† 高橋さんが研究を開始した時点で、ExtractContentをPython用に書き直したpython-extracontentが既に存在していた。高橋さんはそれを修正し、次のリポジトリで公開している。

GitHub - kanjirz50/python-extractcontent3: HTMLから本文抽出を行うextractcontent.rb の Python3版
──他に、より良いサービスにするために工夫した点はありますか?
高橋 大きく分けて2つの工夫をしています。まず、2~3文字の企業の場合、すべての企業を辞書登録するのではなくて、ある程度規模の大きな企業だけに絞ることです。要するに、「流通している名刺ということは、人がある程度多い企業である」という仮定を置いて、まずは大部分の企業をキャッチアップできる方向性にしました。
それから、フィード機能のインターフェースを工夫しました。候補となる企業を1つだけではなく、関連している可能性が高い企業をいくつか出して、ユーザー側で選択してもらう仕様にしたんです。これにより、精度が上がらない場合でも、ユーザーに問題なく使ってもらえるようになりました。
判定の精度を上げることは大事ですが、限られた時間やリソースのなかでは、高精度に持っていくことが難しいケースもあります。その場合でも、現状の精度をふまえた上で、どんな落とし所にすればサービスが実用可能なものになるかを考えることが大事だと思っています。
──3.は、どのような手段を用いて実現しようとしているのでしょうか?
高橋 固有表現抽出を使って、その系列の中で候補の文字列が企業名らしいかどうかをラベリングするという、よくある固有表現抽出の問題として解こうとしています。現在は学習データの作成に取り組んでいます。
名字と名前をニューラルネットによって分割する
名刺の姓名分割プロジェクトは、与えられた文字列がどのような構造を持つかを推定するタスクである。名字と名前が連結した「奥田裕樹」のような文字列に対し、どこが名字でどこが名前であるかを正確に分割する試みだ。
資料は「文字のゆらぎをどう扱うか? - Sansanにおける自然言語処理の活用」より
──奥田さんはなぜ名刺の姓名分割プロジェクトに取り組むようになったのでしょうか?
奥田 Sansanが現在行っている名刺データ化のプロセスでは、人の目によるチェックを途中で介しているため、名字と名前が誤って分割されてしまう問題は発生しません。名字と名前がつながっている文字列をどう分割するか、人間が考えればいいからです。
ですが、もしも名刺データ化を完全自動化していく方針になったならば、人の目を介さずに名字と名前を分割する方法を考える必要があります。この問題を事前にクリアしておくために、プロジェクトがスタートしました。
この問題は、実は以前にも社内で取り組まれていました。その頃に使われていた手法は非常にシンプルで、頻度をもとに名字と名前を分割する手法でした。例えば、奥田という名字は非常にありふれているので、「奥田」という文字列が含まれているならばそれを名字と判定する、というものです。この手法の精度はかなり高く、よくある名字と名前であれば99%以上の正答率でした。
──それほどの精度があれば十分に思えますが、何か欠点はあったのでしょうか?
奥田 珍しい名前や過去とは違った系統の名前が出てきたときに、精度を担保できなかったんです。例えば、「奥」という名字の方もいるからです。そういった名字や名前が一意に決まらないケースでは誤判定する場合があり、異なる手法を用いる必要が出てきました。

──最終的にはどのような手法を採用したのですか?
奥田 Bidirectional LSTMという、系列を扱うニューラルネットのモデルを使う手法です。
自然言語処理においては、ニューラルネットをベースにしたモデルを用いることで、さまざまな分野で判定精度が高くなるといった先行事例が多数あり、この分野では主流となっています。これを姓名分割においても適用してみようと考えました。
- Google翻訳の事例
-


- 自然言語処理とニューラルネットにまつわる講演
-

具体的には、名字と名前が連結した文字列に対して、ありとあらゆる「区切るパターン」を用意し、正解の情報とセットで学習させることで、名字と名前を区別させるという試みをしています。
資料は「文字のゆらぎをどう扱うか? - Sansanにおける自然言語処理の活用」より
この手法ではいくつかの点を工夫しました。例えば、名前には長いものも短いものもあるので、さまざまな長さの名前に対応できるように、リカレントニューラルネットワークによって文字の系列を扱うような構造になっています。
さらにBidirectional LSTMでは、文字列を前から順に読み込ませる方法と後ろから順に読み込ませる方法を2つ組み合わせています。こうすることで、片方だけから読み込むよりも精度を向上させられると考えられるためです。
──なるほど。文字どおりに「双方向(bidirectional)」なのですね。
奥田 さらに亜種として、複数系統の入力を持つBidirectional LSTMも試しています。これは、名字と名前を扱うユニットを別々に用意し、各出力を統合したニューラルネットワークを構築することで、判定の精度を上げるという手法です。

名字と名前では使われる漢字が異なるので、人間はどちらか片方を見るだけで、名字か名前かを判定できます。ならば、「より人間の思考に近づけたモデルにした方が、精度は向上するのではないか」という仮説を立てて、名字と名前を別々に入力するモデルを試したんです。
結果的には、両者ともかなり良い精度に到達させることができました。今後どちらを使っていくかは、解くべき問題の種類に応じてケースバイケースかなと思います。
特徴語抽出により、自社社員の強みをキーワード化する
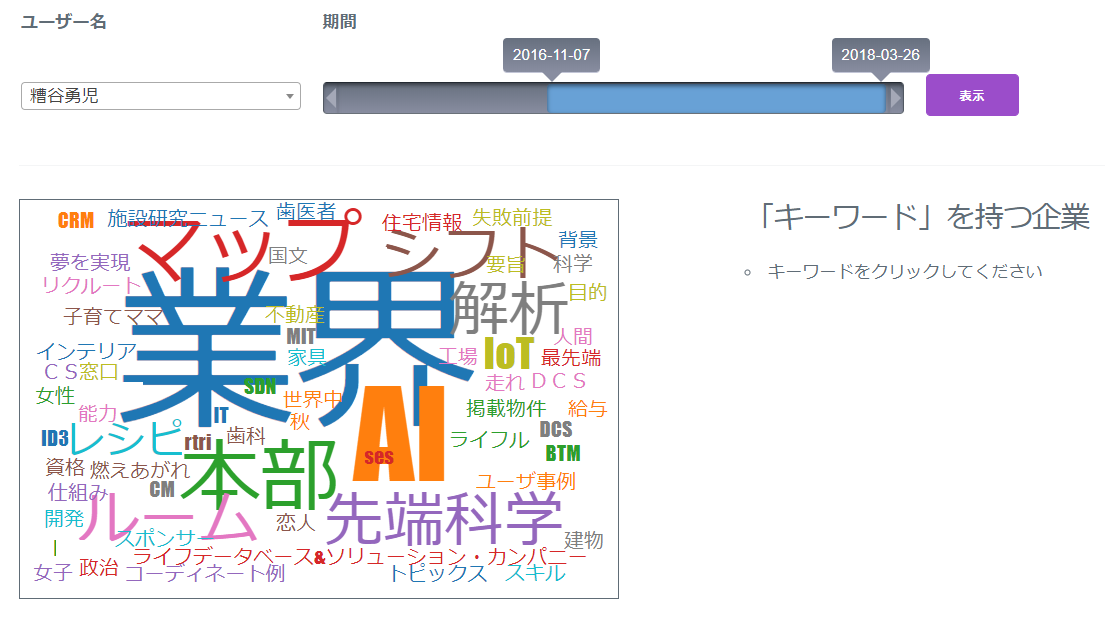
自社社員の強みをキーワード化する機能では、名刺に記載されているURLから企業のWebページを取得し、特徴語をルールベースで抽出する。β版として「Sansan Labs」で提供されていたが、正式にSansanのサービスに組み込まれる形となった。
──自社社員の強みをキーワード化のプロジェクトは、検討段階でかなりの苦労があったと聞きました。
高橋 そうですね、特徴語の抽出には難航しました。なぜなら、「何を正解と定義するか?」の方針を決めるのが非常に難しかったからです。例えばSansanの場合、特徴語として「名刺管理サービス」「名刺」「クラウドサービス」「渋谷」「ベンチャー」などのタグを付与できる可能性があります。
ですが、どのタグが正解かは、「そもそもサービスの利用者はどんな情報を求めているか?」に応じて変わってきます。その策定には時間がかかりました。
初期フェーズでは、キーワードを手作業で数百社に対してタグ付けし、その情報を学習させてキーワード抽出するような系列ラベリングのモデルを作ったんですが、うまくいきませんでした。キーワードが複合名詞のこともあるので、スパースなデータになってしまうからです。一方で、頻度ベースの手法を用いたとしても、同様に実用化は難しかったです。
最終的には、キーワードになりやすい要素を事前に列挙しておき、それが他企業のWebページと比べて相対的な登場頻度にどれほど差があるのかを見る、というシンプルな方法に落とし込みました。
Sansanのオペレーターさんの力を借りて人力で特徴語のタグを振ってもらう部分と、そのアルゴリズムでキャッチアップする部分とを組み合わせることで、1つの機能として着地させました。
自然言語処理を学ぶ、効果的なインプット方法
──自然言語処理についての知見を深めるために、どんなインプットをしていますか?
高橋 Twitterをかなり有効的に活用していますね。自然言語処理や機械学習などの有益な情報を発信しているアカウントは、教授・学生・企業を問わずフォローしています。
奥田 私もTwitterはかなり活用しています。最近では研究者やエンジニアが、読んだ論文の感想をTwitter上で公開する文化があり、各人が積極的に投稿しています。それから、国際学会などで投稿されている論文のなかから、自分の研究に活用できそうなものを探してくるケースも多いです。
──論文を読める、おすすめのサイトはありますか?
高橋 Computational Linguistics系の国際会議のポータルサイトであるACL Anthologyがおすすめです。主要なトップカンファレンスの論文などを、すべて閲覧できます。


本を読んで勉強することも多いです。自然言語処理に関するものだと、『入門 自然言語処理』や自然言語処理シリーズの『言語処理のための機械学習入門』などを読むのがいいと思います。
それ以外にも、機械学習の各ライブラリについて知るために『Pythonではじめる機械学習』や『scikit-learnとTensorFlowによる実践機械学習』を読んだり、スクレイピングを学ぶために『Pythonクローリング&スクレイピング -データ収集・解析のための実践開発ガイド』を読んだりもしました。
昨年に出版された『前処理大全』もいい本でした。自然言語処理についての記述はそれほど多くありませんが、前処理全般についての知識を得ることができました。最近では、社内の勉強会で『ゼロから作るDeep Learning 2 ―自然言語処理編』を輪読しています。
それからSansanでは、情報共有にSlackが有効活用されています。チャンネルの作り方に工夫があって、他のメンバーに質問ができるQ&Aチャンネルと、各々が自分の好きなテーマを投稿できる個人チャンネルが用意されているんです。Q&Aチャンネルでは、実装の不明点などを質問すると、誰かが答えてくれます。
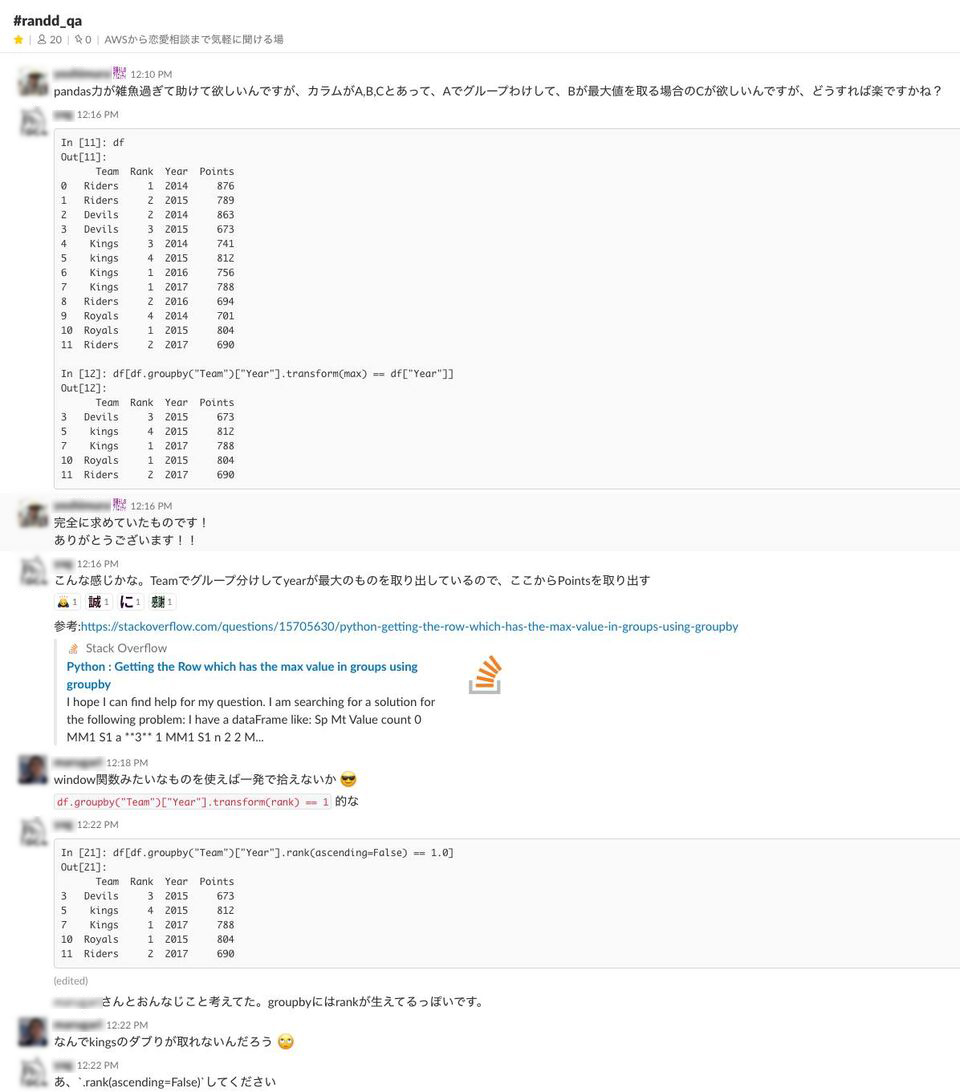
▲Q&Aチャンネルでの議論の様子
後者のチャンネルには各自が自由なテーマで独り言のように投稿してよくて、投稿内容は他のメンバーも閲覧できます。以前、エンジニアHubに登場していた高際さんなどはすごくて、「そんなレアなネタ、どうやって手に入れたんだ!?」と思うくらいニッチな情報をよく書き込んでいます(笑)。
▲技術やデザイン、プロダクトマネジメントのアウトプットとしてブログも開設している
──個人用のチャンネルがあると投稿のハードルがぐっと低くなって、情報共有が活発になりそうですね。
Sansanのデータ分析は、総合格闘技だ

──最後に、Sansanでデータ分析に携わる醍醐味(だいごみ)について教えてください!
奥田 Sansanには、「扱うデータの種類が多種多様である」という特徴があります。例えば、スキャナーやスマートフォンから名刺を取り込む段階では、データの形式は画像です。その後、テキストデータに変換されます。
私はいま自然言語処理にも機械学習にも携わっているんですが、サービスの価値を高めるためには、さまざまな領域の知識を習得して活用していく必要があります。そのプロセスを通じて、自分自身の技術の幅が広がっていきます。いわば総合格闘技のような面白さがあるわけです。研究者として非常にやりがいが大きいですね。
加えて、私たちが取り組んでいる課題は「人間が担っていたタスクを、コンピューターができるようにしていく」という、難易度が高くチャレンジングな領域です。だからこそ、非常に価値がありますし、挑みがいのある仕事だと思っています。
高橋 Sansanでは、名刺交換という実際の「企業や人」「人と人」の出会いの軌跡をデータとしてお預かりしています。それらのデータと多種多様な技術を組み合わせながら「ユーザーに対してどんな価値を提供できるか?」を考えるプロセスそのものが、本当に面白いです。
私たちがサービスを提供することで人々に付加価値の高い情報が届きやすくなれば、社会はより便利になっていくはずなんですよ。そのミッションと向き合うのは、Sansanで働くからこそできる、価値のあるチャレンジだと思いますね。
──日夜研究を続けるお2人の言葉、とても勉強になるものばかりでした。貴重なお話をありがとうございました!
取材・執筆:中薗昴 写真:漆原未代




