
「GraphQL」徹底入門 ─ RESTとの比較、API・フロント双方の実装から学ぶ
Web APIの新しい規格「GraphQL」の設計と実装について、藤吾郎(gfx)さんによる寄稿です。
この記事では、Web APIの規格のひとつであるGraphQL(グラフキューエル)について解説します。筆者(gfx)は2017年からGraphQL APIをプロダクションで運用しており、GraphQLのDX(Developer Experience) に大きな魅力を感じているソフトウェアエンジニアです。
GraphQLは、RESTful Web API(REST)の持つ問題を解決するために開発された規格です。そこで、この記事の前半では、RESTと比較しつつ、GraphQLの利点や欠点、そしてその機能の詳細を見ていきます。そして記事の後半では、筆者が使っているGraphQL Ruby(graphql-ruby)を題材に、RailsアプリにGraphQL APIを実装してみます。
- GraphQLとは何か
- GraphQLを触ってみる
- GraphQLのコンポーネント
- スキーマ言語 - GraphQLのコンポーネント その1
- クエリ言語 - GraphQLのコンポーネント その2
- GraphQL APIを実装してみる
- GraphQLを使うフロントエンドアプリを実装してみる
- まとめ
※この記事はGraphQL仕様のバージョンJune 2018を元にしています。
GraphQLとは何か
まずGraphQLとは何でしょうか。GraphQLは、Facebookが開発しているWeb APIのための規格で、「クエリ言語」と「スキーマ言語」からなります。

クエリ言語は、GraphQL APIのリクエストのための言語で、これはさらにデータ取得系のquery、データ更新系のmutation、サーバーサイドからのイベントの通知であるsubscriptionの3種類があります。なお、この記事では、総称としてのクエリ言語は「クエリ言語」と書き、クエリの3種のひとつであるqueryは「query」と書くことにします。
スキーマ言語は、GraphQL APIの仕様を記述するための言語です。リクエストされたクエリは、スキーマ言語で記述したスキーマに従ってGraphQL処理系により実行されて、レスポンスを生成します。
GraphQLは、クエリがレスポンスデータの構造と似ていて情報量が多いこと、そしてスキーマによる型付けにより型安全な運用ができることが特徴となっています。
GraphQLのシンプルな例
ひとつ、GraphQLのスキーマとクエリのシンプルな例を挙げてみます。例えば、次のようなスキーマがあるとします。
type Query {
currentUser: User!
}
type User {
id: ID!
name: String!
}
type Queryはqueryのための予約されたルートの型名で、ただひとつのフィールドcurrentUserを持ち、User!は「nullにならないUser型」という意味になります。また、type UserはnullにならないID型であるidフィールドと、nullにならないString型であるnameフィールドを持ちます。
実装はここでは触れませんが、ひとつひとつのフィールドはリゾルバ(resolver)と呼ばれる関数がマッピングされます。リゾルバは、オブジェクト(例えばUserのインスタンス)を引数として受け取り、そのオブジェクトのプロパティ(例えばUser#name)を返すシンプルな関数です。
このスキーマに対して発行するクエリは、例えば次のようになります。
query GetCurrentUser {
currentUser {
id
name
}
}
これは「このクエリの名前はGetCurrentUserでクエリのタイプはquery(=データ取得系)でcurrentUserのidとnameを取得する」という意味です。これに対応するレスポンスは、例えば次のようなJSONデータになるでしょう。
{ "data": { "currentUser": { "id": "dXNlci80Mgo=", "name": "foo", } } }
レスポンスとしては、スキーマに定義したフィールドのうち、クエリに指定したフィールドのみが返ってきています。また、クエリの構造とレスポンスデータの構造もよく似ています。このように、レスポンスに含まれるデータの指定が必須であること、クエリとレスポンスの構造がよく似ていることは、GraphQLの大きな特徴です。
この特徴により、GraphQLは優れたDXを持ち、ひいては生産性やクライアントコードの品質にもいい影響を与えます。例えば、クエリからレスポンスの構造を予測できるため、Web APIに対する深い知識がなくても、GraphQLのクエリであればある程度は読み書きができます。また、スキーマの情報を利用してクエリを書くためのサポートを行うクエリエディタが存在します。これにより、ことクエリの読み書きという点でいえば、学習コストも非常に少なくなっています。
GraphQLの起源とこれから
GrpahQLの詳細に入るまえに、その起源とこれからについて少しだけ触れておきます。
GraphQLは、もともとFacebookが開発したもので、2015年に仕様と参照実装がOSSになりました。GraphQLを開発する以前、FacebookはWeb APIとしてRESTful APIとFQL(Facebook Query Language)を運用していました。RESTful APIは現在も“Graph API”としてFacebookのソーシャルグラフへアクセスするための公開APIとして提供されています。しかし、SQL風の構文であるFQLはその後廃止されました。FQLはおそらくGraphQLに完全に置き換えられたのでしょう。
Facebookによれば、GraphQL開発の動機は、モバイルアプリケーションで利用するオブジェクトグラフとAPIのレスポンスの構造に乖離(かいり)があり、これを改善するためだったということです{$annotation_1}。GraphQLの特徴である「クエリの構造とレスポンスの構造がよく似ている」というのは、まさにGraphQLの開発の動機だったということになります。
そして2018年11月にGraphQL Foundationが設立されました。これまでFacebookで開発・運用されてきたGraphQLの規格そのものや、参照実装やエディタなどのツールチェインは、これからはGraphQL Foundationによりメンテナンスされていくことになります。今後についてはこれから決まっていく段階でしょうが、より安定して開発されることが期待できるのではないでしょうか。

なぜGraphQLの採用が増えているのか
GraphQLが公開されて2018年で3年経ちました。いまやFacebook以外にも、GitHub、Airbnb、New York Times、Shopify、Atlassian、Netflixなど多くの企業が導入して、ツールチェインの開発や知見の公開をしてきました。特に、GitHubが2017年に公開した“GitHub API v4”がGraphQLを採用していたことで、国内でも急速に注目を集めはじめたという印象があります。
筆者がGraphQLに興味を持ったのもこのタイミングでした。筆者はGraphQL APIをKibelaというプロダクトに導入したのですが、このプロダクトで利用しているgrphql-rubyというライブラリは、まさにGitHubによって開発されているGraphQL処理系です。
ここでは、GraphQLの採用が増えている理由として利点を挙げていきます。また、欠点も同時に見ていきます。
GraphQLの利点
GraphQLがここまで急速に広まったのは、3つの理由があると考えています。ひとつはクエリとレスポンスの構造に対応関係があること、次にスキーマとその一部である型システムによりエディタにおける補完や型チェックなどのツールによる開発サポートが受けられること、そしてクエリの学習コストが低いことです。
クエリとレスポンスにおける構造の対応関係
まず第一に、クエリとレスポンスの構造に対応関係については前述のとおりです。これはクエリからレスポンスの構造を推測できるということでもありますし、逆にいえば求めるレスポンスに応じてクエリを書いていけるということです。GaphQLのリクエストは一見するとRESTful APIと比べて冗長になりますが、実際に開発で使ってみると情報量の多さはむしろ利点であると感じられます。
例えば、クライアントサイドのviewを作るときは、そのviewで必要な値をGraphQLのクエリの中にリストするだけで過不足なくリソースをリクエストできます。また、コードリーディングの際にWeb APIの詳細を知らなくても、ある程度クライアントサイドのコードを読み進められます。クエリとレスポンスの構造に対応関係があるというのは、これだけでGraphQLを採用したくなるほど強力な利点であるといえるでしょう。
スキーマとそれを利用するツールによる開発サポート
GraphQLはスキーマのあるWeb API規格です。このスキーマは、クエリやレスポンスの構造に加えて各々のフィールドの型を定義しています。これにより、スキーマ駆動開発{$annotation_2}が可能になり、またスキーマを利用したツールのサポートを受けられます。
例えば、GraphQL Foundationが提供する公式のツールに“GraphiQL”(グラフィクル)というIDEがあります。これはGraphQLに対してクエリを発行してレスポンスを閲覧するためのツール、つまりAPIコンソールです。しかし、ただクエリを発行するのみならず、スキーマを通じてクエリの補完やAPIリファレンスとの統合などの機能があるためIDE(統合開発環境)と呼ばれています。そしてその補完などの機能は、GraphiQLがスキーマの情報を利用することで実現しています。
このようなコンピューター言語に対するツールサポートは、language serviceと呼ばれます。GraphQLのlanguage serviceであるgraphql-language-serviceはGraphQL Foundationがメンテナンスしています。
クエリの学習コストが小さいこと
クエリの学習コストが非常に小さいことも、GraphQLの特筆すべき利点です。クエリのツールサポートも相まって、「必要なデータを取得する」というタスクがここまで簡単にできるものなのかと驚くほどです。このためGraphQLクライアントがなくてもHTTPリクエストさえできればWeb APIを使うのは簡単ですし、クライアントを自作するとしてもそれほど難しくありません。
実際、筆者のプロダクトでも、最初のGraphQLエンドポイントの追加から1年近くたってようやく専用クライアントのApolloを導入したのでした。それまでは、単にJSONをPOSTしてJSON responseを受け取るAPI endpointがひとつ増えただけという運用でした。
スキーマ言語については、ほとんどのコンポーネントがオブジェクト指向プログラミング言語と概念を共有している上、仕様自体も小さいため学習はそれほど難しくはないでしょう。
GraphQL API自体の実装コストは、GraphQL処理系ライブラリに依存する部分も大きいのですが、N+1問題の解決などの最適化などを後回しにするのであれば、それほど大きくもありません。むしろ、スキーマ言語というレールがあることにより、RESTよりも設計は簡単です。
ただし、GraphQLの処理系から作るのはかなり難しく、このことはGraphQLの欠点のひとつです。とはいえ、多くの言語ではすでにGraphQL処理系のライブラリがあるため、それらを使えば現実的なコストで開発・運用できるでしょう。
GraphQLの欠点
GraphQLの欠点もいくつかあります。いずれもブロッカーではないものの、解決の難しい問題ではあります。
パフォーマンスの分析が難しい
GraphQL APIのHTTPエンドポイントはひとつだけです。例えばNew RelicなどのAPM(Application Performance Management)でパフォーマンスの記録や分析などを行うときはエンドポイントごとに情報を収集するのが普通です。しかし、エンドポイントがひとつだけのGraphQLは全てのデータがまとめられてしまい、分析が困難です。
パフォーマンスの分析が難しいということは、現在のところ運用においては一番頭を悩ませている課題で、まだ解決していません。とはいえ、すでにプロダクションに導入しているサービスが多数あることから分かるとおり、ブロッカーというほどの問題でもありません。
もっとも、このことは、RESTful APIのようにひとつのURLをひとつのAPIに対応させたWeb APIが、現在のAPMの想定するWeb APIモデルと異なるからです。つまり、ツールの対応が追いついていないだけといえます。実際、プロプライエタリのPaaSであるApollo Platoformは、GraphQLのクエリを分析するApollo Engineというミドルウェアを提供しているようです。
GraphQL処理系を実装するのが難しい
GraphQLのクライアントをフルスクラッチで実装するのはそれほど難しくないのですが、GraphQLの処理系の実装コストはかなり大きなものです。したがって、多くのケースでは既存のライブラリを使うことになりますし、その場合はGraphQL APIの開発と運用コストはその採用したライブラリに大きく依存することになります。そのライブラリで未実装の機能は簡単には使えないという問題もあります。
採用するGraphQL処理系はOSSであれば、足りない機能のパッチを作ることもできます。しかし、この処理系を実装するのが難しいという問題は、シンプルなRESTful APIと比べて懸念点となることは否めません。
画像や動画などの大容量バイナリの扱いが難しい
大容量バイナリの送信(アップロード)も、GraphQLが苦手とするものです。
GraphQL自体はリクエストやレスポンスのシリアライズ方法は規定していないものの、多くのケースではJSONです。JSONはバイナリのシリアライズが苦手で、比較的エンコードサイズが軽量なBase64でもデータ量が1.3倍ほどになってしまいます。また、サーバーサイドのJSONでシリアライザは基本的にオンメモリなので、メモリに乗り切らないほど大きなデータはそもそも処理できません。
シリアライザをMessagePackなどバイナリシリアライザにして大容量バイナリをシリアライズ時にファイルに退避するなどの工夫は可能です。しかし、まさにその挙動がデフォルトであるHTTPのmultipart/form-dataと比較すると一手間かかってしまいます。
GraphQLを触ってみる
GraphQLの特徴の説明はこのくらいにして、実際にGraphQLを触ってみましょう。GitHubのアカウントがあればGitHub API v4を試すのが一番簡単です。
GitHub API v4について
GitHub API v4は、GitHubの公開Web APIです。
次のURLでAPIコンソール(GitHubは“API Explorer”と呼称)にアクセスできます。
ここで操作するデータはGitHubの本番のデータなので、更新系のAPIを使うときは十分に気をつけてください。特に、他人のリポジトリにゴミデータを送信するようなことは絶対にしないように注意してください。
The GraphiQL IDEについて
GitHubのAPIコンソールはGraphiQLです。GraphiQLはGraphQLのための開発環境(IDE)で、補完やリアルタイム構文チェックなどを備えたエディタとスキーマから生成されたAPIリファレンスなどからなります。
例えば、GitHub API v4のGraphiQLは次のような外観です。
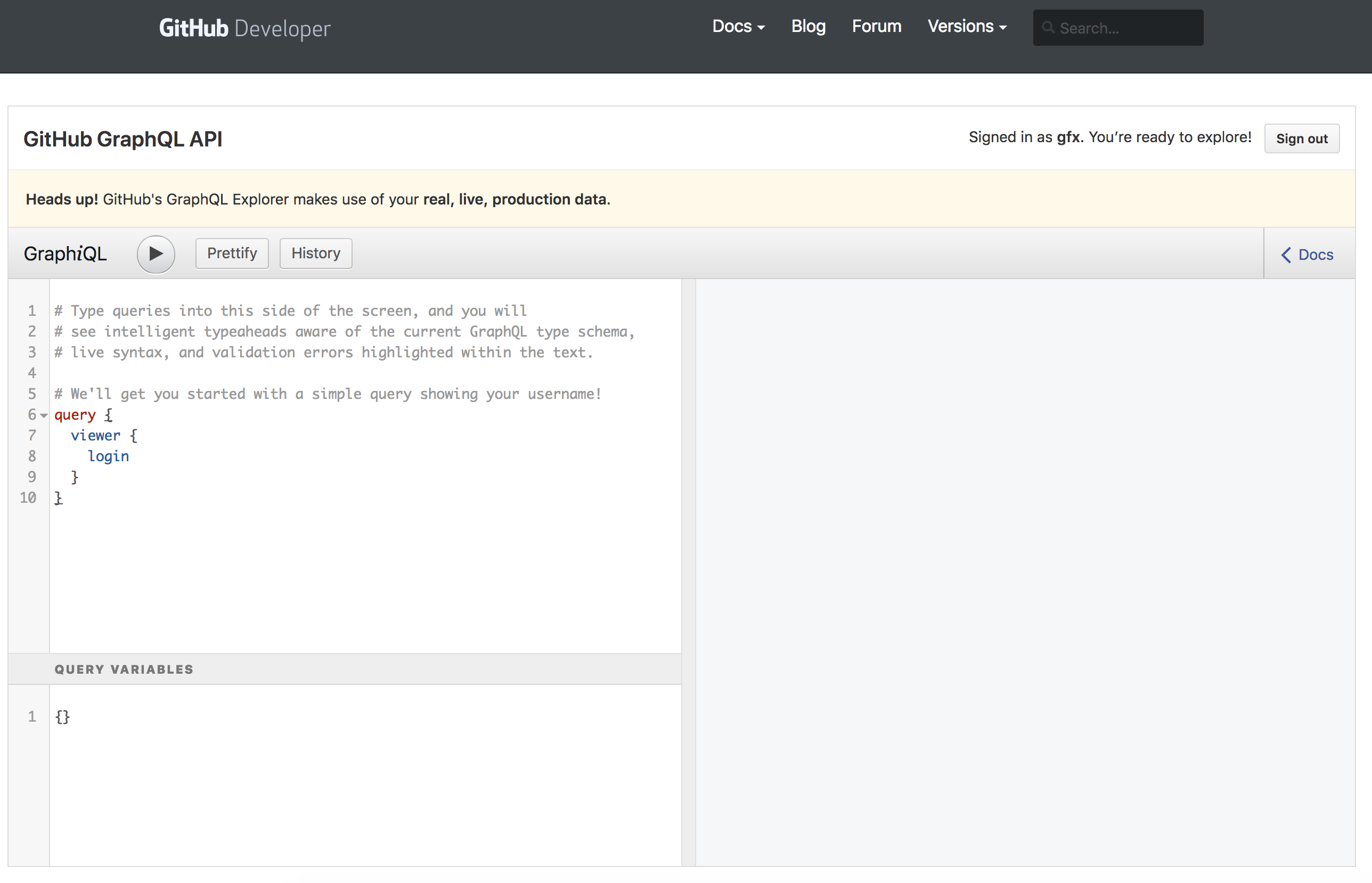
GraphQLではエディタ上でcontrol+enter(macOSの場合はcommand+enterでも可能)でクエリを実行し、その結果が右ペインに表示されます。また、エディタ上でcontrol+spaceを押すと、カーソル位置に応じて補完が出ます。
GitHub API v4のコンソールにはデフォルトで次のようなクエリが入力されているので、それを実行してみてください。
query {
viewer {
login
}
}
すると、右のレスポンスペインにログインユーザ名を含む次のようなJSONが表示されるはずです。
{ "data": { "viewer": { "login": "gfx" } } }
また「Docs」はインクリメンタルサーチ付きのAPIリファレンスです。このAPIリファレンスはGraphQLスキーマから自動生成されたもので、ちょっとしたことを調べるにはこれで十分です。
GraphQLのコンポーネント
それでは、GraphQLのコンポーネントを見ていきましょう。GraphQLのコンポーネントは、スキーマ言語とクエリ言語からなります。
スキーマ言語は、リソース{$annotation_3}の単位であるtypeとその構成要素であるfieldが基本的な要素です。また、typeのバリエーションとして、interfaceとunion typeとenumがあります。また全体に関わる要素としてdirectiveとdescriptionがあります。
そしてクエリ言語は、query、mutation、subscriptionという3種類があり、それぞれデータ取得、データ更新、サーバーサイドイベントの購読となっています。
クエリは常にスキーマに対応するため、まずスキーマを見ていきます。
スキーマ言語 - GraphQLのコンポーネント その1
GraphQLのスキーマ言語は、Web APIの仕様を記述するための言語です。型システムを内包しており、クエリやレスポンスのバリデーションやリゾルバの適用のために使われます。
実際に設計する際は、GitHub API v4のリファレンスが参考になるでしょう。
Type
まずはtype、つまり型です。これはプログラミング言語における型やクラスに似ており、複数のfieldからなるリソースです。
ただし、プログラミング言語の型と違って実装はスキーマにはありません。typeはあくまでもリソースに対するインターフェイスを記述するだけです{$annotation_4}。
型はnull可能性の区別があり、デフォルトではnull可能性のある“nullable”で、typeのあとに!をつけるとnull可能性のない“non-nullable”になります。
また、型名を[]で囲むと配列になり、これもデフォルトはnullableで、!でnon-nullableになります。連想配列は組み込みでは用意されていません。
null可能性や配列について、まとめると次のようになります。
| 表示 | 説明 |
|---|---|
String |
nullableなString型 |
String! |
non-nullableなString型 |
[String] |
nullableなString型のnullableな配列型 |
[String!]! |
non-nullableなString型のnon-nullableな配列型 |
Field
次にfield(フィールド)です。それぞれのfieldは「名前: 型名」という構文で、必ず型を指定します。
最初に紹介したシンプルな例をもう一度見てみます。
type Query {
currentUser: User!
}
type User {
id: ID!
name: String!
}
このスキーマは、currentUserというfieldを持つQueryというtypeと、id、nameというfieldを持つUserというtypeがあります。全ての型はnon-nullで、IDとStringは組み込み型です。
Queryはデータ取得系のクエリであるqueryのために予約されたtypeで、全てのqueryのルートとなるtypeです。
なお、fieldはさらに引数を設定できます。例えば、Relay Connectionというリスト型は、ページ送りのための引数を受け取ります。また、IDからリソースを取得するフィールドも引数を受け取ります。
例えば、IDからUserを取得するフィールドは次のようになるでしょう。これは、idに対応したUserを取得し、その型はnullableなので、おそらく対応するUserが存在しなければnullを返すのでしょう。
type Query {
user(id: ID!): User
}
Interface
interface(インターフェイス)はtype同様に型の一種ですが、対応する具体的なリソースを持たない抽象型です。複数のtypeに共通フィールドをinterfaceとして抽出し、typeはinterfaceを“実装”できます。“実装”とはいうものの、typeそれ自体はスキーマとして実装を持つことはありません。
例えば、あとで紹介するRelay Server Specificationは次のようなinterfaceを持ち、これを実装した型であればIDから取得できるとしています。
interface Node {
id: ID!
}
また、GitHub API v4では、「スターをつけられるリソース」としてStarrableというinterfaceを定義しています。
interfaceは複数のtypeの共通fieldがあるときには便利ですが、本来共通fieldのないtypeを無理にひとつのinterfaceにまとめる必要はありません。関連性のないtypeをまとめた抽象型が欲しいときは、次に紹介するunion型を使います。
Union
union(ユニオン)は「指定された複数の型のうち、いずれかの型」を示す抽象型です。例えば、union StringOrInt = String | Intというスキーマは「StringまたはIntのうち、いずれかの型」という意味のStringOrIntというunion型を定義します。
なお、複数のtypeのunion型をクエリで取得するときに必ずそれぞれの具象型ごとにconditional fragmentで書き分けて取得する必要があります。
例えば、次のようなスキーマがあるとします{$annotation_5}。
type Entry {
id: ID!
title: String!
content: String!
}
type Comment {
id: ID!
content: String!
}
union SearchResult = Entry | Comment;
typ Query {
search(q: String!): [SearchResult!]!
}
ここからは次のような仕様を読み取れます
- queryとしてはsearchという文字列を引数にするfieldがあり、それはSearchResultというunion型の配列を返す
- SearchResultはEntryとCommentというtypeのうちいずれかである
このsearch fiieldを使って検索結果を取得するときは、次のようにな ... on Type という構文でconditional fragmentを使い、EntryとCommentでそれぞれの型ごとにクエリを書きます。
query {
# 文字列 "foo" で検索する
search(q: "foo") {
__typename # 全ての型にデフォルトで提供されるメタデータ。ここでは "Entry" または "Comment"
# Entryの場合
... on Entry {
id
title
content
}
# Commentの場合
... on Comment {
id
content
}
}
}
これは一見すると冗長です。しかし実際のアプリケーションでは、view componentにデータを渡すときにはリソースの型(__typename)に応じてview componentを分けることになるでしょう。そのようなケースでは、クエリの段階で分岐しておくのはいいプラクティスであるといえます。
ここでは詳細には触れませんが、上記の例はinterfaceでも実現はできます。しかし、unionのほうがクエリの型ごとの分岐が明示的であるため後からでも読みやすく、またfragmentによってクエリを分割定義できるためメンテナンスはしやすいという感覚があります。
Scalar
scalar(スカラ)は、ただひとつの値からなる型です。組み込みのscalar型としては、次の表のものがあります。
| 型名 | 説明 |
|---|---|
| Int | 符号付き整数(32bit) |
| Float | 浮動小数点数(64bit) |
| String | 文字列(UTF-8) |
| Boolean | 真偽値 |
| ID | 一意なID / 値としてはStringと同じ |
scalar型を新しく定義するためにはscalarキーワードを使います。例えば、Date型を新しく定義するには次のようにします。
scalar Date
スキーマではこれだけですが、実際に使う際はGraphQL処理系に対してさらにシリアライズとデシリアライズを定義することになります。
GraphQL組み込みのscalar型は先にあげたものだけなので、例えばバイナリ、日付と時刻、HTML/XML、BigIntなどを必要に応じて追加することになるでしょう。ただしその場合、サーバーサイドとクライアントサイドでシリアライズ・デシリアライズの実装を一致させる必要があります。
Enum
enum(イナム)はscalar型の一種で、特定の値のみを持つ型です。例えば、組み込みscalar型であるBooleanをenumで宣言すると次のようになるでしょう。
enum Boolean {
true
false
}
ところで、enumで異なる構造を持つリソースをまとめるための「種類」を定義しないようにしてください。例えば、次のようなenumがあるとします。
enum DocumentType {
ENTRY
COMMENT
}
type Document {
documentType: DocumentType!
# COMMENTはtitleがないのでnullable
title: String
# ENTRYもCOMMENTもcontentは必ず存在するのでnon-nullable
content: String!
}
これは、unionを自前で実装しているようなものです。そうではなく、次の例のようにそれぞれに応じたtypeとunionを用意するほうが、複数のtypeのインターフェイスを無理に一致させる必要がないため、適切にtypeを定義できます。unionをqueryで取り出すときには組み込みのfieldである__typenameが使えます。
type Entry {
# ...
}
type Comment {
# ...
}
union Document = Entry | Comment
Directive
directive(ディレクティブ)は、スキーマやクエリに対してメタデータを与えるための宣言です。directiveは処理系やツールによって解釈され、さまざまな効果を持ちます。directiveはスキーマ用のものとクエリ用のものがありますが、宣言方法は同じでターゲットを変えるだけです。
例えば、@deprecatedは、fieldが非奨励であることを示すための組み込みdirectiveで、次のように使います。
type T {
newName: String!
oldField: String! @deprecated(reason: "Use `newField` instead.")
}
この@deprecated directiveをつけられたfieldを使うことはできますが、GraphiQLのエディタで警告が出たり、GraphiQLのリファレンスマニュアルで表示されなかったりするなど、ツールが解釈して該当fieldを使わないように促してくれます。
この@deprecatedは次のように宣言されているのと等価です。実際には、組み込みなので宣言は不要ですが。
directive @deprecated( reason: String = "No longer supported" ) on FIELD_DEFINITION | ENUM_VALUE
なお、directiveのサポート状況はライブラリによって差があります。例えばgraphql-rubyは組み込みdirectiveのみサポートしていて、カスタムdirectiveはサポートしていません。活用すればロールベースの権限管理などに使えて便利なはずですが、ライブラリのサポートがなければ使うことは難しいので、筆者の環境では使っていません。
Description
descriptin(デスクリプション)は、typeやfieldなどに対する「説明」で、ツールから利用できるドキュメントです。例えば、GraphiQLが生成するリファレンスマニュアルにはこのdescriptionが表示されます。
descriptionはtypeやfieldの前に文字列リテラルとして書きます。また、descriptionの中身はmarkdown(CommonMark)を書けます。
"""
コメント型。必ずいずれかのEntry型に所属する。
"""
type Comment {
"コメントの本文。フォーマットは[CommonMark](https://commonmark.org/)。"
content: String!
"コメントの本文。CommonMarkをHTMLに変換したもの。"
contentHtml: String!
}
クエリ言語 - GraphQLのコンポーネント その2
GraphQLのクエリ言語は、Web APIリクエストにおいてどのようなデータを取得するかを表現したものです。データ取得系のquery、データ更新系のmutation、pub/subモデルでサーバーサイドのイベントを受け取るsubscriptionの3種類があり、これを「オペレーション型」といいます。
それぞれのオペレーション型ごとにルート型が必要で、このルート型はリソースを表現したものではなく名前空間として使われます。また、オペレーションごとのクエリ言語の構文は同じで、オペレーションの振る舞いによって名前空間を分けているだけといえます。
なお、subscriptionは最近GraphQLの仕様に追加されたものですが、仕様も実装も複雑でユースケースも限られるため、この記事では扱いません。GitHub API v4もsubscriptionは提供していないようです(2018年11月現在)。
Query
queryはデータ取得系のクエリで、ルート型はQueryです。RESTful APIのGETに相当します。
最初に出したスキーマとクエリの例に解説のコメントを足して再掲します。スキーマが読めればクエリもそのまま読めるのではないでしょうか。
スキーマ:
# queryのルートオペレーション型であるQueryを定義する
type Query {
# フィールドとしてはnon-nullableなUser型であるcurrentUserを持つ
currentUser: User!
}
# User型のfieldはidとname
type User {
id: ID!
name: String!
}
クエリ:
# クエリの種類は`query`で、この操作全体にはGetCurrentUserという名前をつける
query GetCurrentUser {
# ここに型(ここではQuery)から取得したいfieldのリストを書く
# なおクエリに書くfieldは "selection" という
# queryのルート型QueryのフィールドcurrentUser: User! を要求する
currentUser {
# ここには User type のselectionを必要なだけ書く
id # idはID!型 (ID型の実体は文字列)
name # nameはString!型
}
}
レスポンス:
{ "data": { "currentUser": { "id": "dXNlci80Mgo=", "name": "foo", } } }
このqueryに対してはGetCurrentUserというオペレーション名をつけています。このオペレーション名は省略可能で、さらにqueryに限っては最初のqueryキーワードも省略できます。つまり、最小のqueryクエリは次のようになります。
{
currentUser {
id
name
}
}
ただし、プロダクションコードの場合は常に一意なオペレーション名をつけてqueryキーワードも省略しないほうがいいでしょう。オペレーション名はコードリーディングやデバッグに役立ちます。関数に分かりやすい名前をつけるというプラクティスと同じことです。
ところで、クエリのselection set(fieldのリスト)にカンマがないことに違和感を覚えるかもしれません。対応するレスポンスのJSONはカンマが必須であるにもかかわらずです。実はGraphQLの仕様的にはカンマはスペースと同じ扱いで、任意の場所につけることができます。しかしカンマなしのスタイルが標準ですし、慣れるとまったく気にならなくなるので、標準スタイルに慣れるほうがいいでしょう。
Queryの命名
queryの命名としては、名詞またはデータ取得を示す動詞であることが多いようです。例えば、GitHub API v4ではQuery.repositories(名詞)やQuery.search(動詞)があります。引数をとるfieldはメソッドのようにも見えますが、単にデータ取得であればgetやfindなどはつけずに名詞そのままにするのがGraphQL流といえます。
これはQuery type直下でないリソースに対応するtypeのfieldも同様です。
オブジェクトグラフの表現
先のcurrentUserの例は非常にシンプルですが、現実のアプリケーションはもうすこし複雑です。つまり、複数のオブジェクトが所有(has-a)や所属(belongs-to)などによって関連しているオブジェクトグラフを扱う必要があります。
例えば、GitHub API v4で次のようなリクエストをしたいとします。
- ログインユーザの所有リポジトリの、それぞれのリポジトリのフルネームとスター数
JavaScriptで書くと次のようになります。
currentUser.ownedRepositories.forEach(({ nameWithOwner, stars }) => { console.log(`リポジトリ: ${nameWithOwner}, スター数: ${stars.totalCount}`); });
GraphQLクエリにするとこんな感じでしょうか。
query GetStargazersCount {
# viewerは現在ログイン中のユーザ(`User!`型)
viewer {
# repositoriesはログイン中のユーザがコミットしたリポジトリのリスト(`RepositoryConnection!`型)
repositories(
ownerAffiliations: OWNER, # ログインユーザがownerのリポジトリに限る
first: 2, # 最初から数えて2つだけ取得(長いので2つだけ)
orderBy: { field: STARGAZERS, direction: DESC }, # スターの数で降順
) {
edges {
node {
nameWithOwner # "$name/$owner"
stargazers { # 星をつけたユーザーのリスト(`StargazerConnection!`)
totalCount # リストアイテムの総数
}
}
}
}
}
}
なお、このくらいのクエリであれば、GitHubに関するドメイン知識とGraphQLとRelay Server Specificationの知識さえあればGraphiQLエディタの補完だけで書けます。スキーマとツールを連携させるlanguage serviceの恩恵ですね。
このクエリに対する次のレスポンス次のようになります。この例は、筆者のアカウント(gfx)でGitHub API explorerにログインして実際にリクエストを行った結果です。
{ "data": { "viewer": { "repositories": { "edges": [ { "node": { "nameWithOwner": "gfx/Swift-PureJsonSerializer", "stargazers": { "totalCount": 115 } } }, { "node": { "nameWithOwner": "gfx/cpp-TimSort", "stargazers": { "totalCount": 96 } } } ] } } } }
User、Reposiotory、Stargazerなどのオブジェクトグラフをそのままにクエリとして表現できています。
ところで、ここに出てきたedgesやnodeを持つconnectionというリストのような型は、あとで紹介するRelay Server Specificatoinの一部のConnectionという型です。これはページング可能なリスト型で、構造としてはGraphQLの配列をラップしてカーソルなどのメタデータを入れられるようにしたものです。
余談ですが、GraphQLの仕様としてはfieldに対する引数リストのカンマも省略できます。しかしGraphQLの公式ドキュメントや仕様書をみる限り、引数リストにはカンマをつけるのが標準スタイルのようです。
Mutation
mutationはデータ更新系のクエリです。ルートのオペレーション型はMutationで、スキーマ上は「Mutation typeのfield」として定義されます。mutationクエリを示すキーワードはmutationです。
例えば、GitHub API v4において、あるリポジトリにstarをつけるmutationクエリは次のようになります。
mutation {
# starrableIdに有効なIDを与えると本当にstarをつけてしまうので、無効なIDにしている
addStar(input: { starrableId: "foo" }) {
# 構文上は戻り値の指定が必須なので、不要なときは`clientMutationId`と書く
clientMutationId
}
}
クエリの構文はほとんどqueryと同じです。単に「mutationは更新系である」という規約のもとに設計するだけともいえます。ただし、mutationは必ずMutation typeのフィールドとして表現しなければならないという制約があります。
addStarの引数は、ひとつのinputという引数に対してmutationごとに定義したinput objectを与えるようになっています。これはGraphQLそのものではなく、後述するRelay Server Specificationの規約で、ほかのmutationも同様にinputという引数をひとつ受け取るようになっています。
mutationクエリには戻り値( selection set )の指定も必須で、たとえ戻り値を想定しないmutationでも必ず何かを書く必要があります。その場合、idやclientMutationIdを指定して、呼び出し元では単に無視するということになるでしょう。なお、このclientMutationIdもGraphQLではなくRelay Server Specificaionの仕様です。
Mutationの命名
mutationの命名は更新を示す動詞にするのがいいでしょう。選べる動詞は、RESTful APIのGET・POST・PUT・PATCH・DELETEに関係しなくてもかまいません。
例えばGitHub API v4のMutation.addStarは、RESTであればPOST /startsとなり、Railsだとstarts#createと表現するところです。しかし、GitHubはcreateStarではなくaddStarと命名しています。
ところで、mutationはQueryと違いMutation type直下に定義したものが全てで、typeのfieldとしてmutationを定義することはできず、ネストはありません。したがって、単体で意味の通る名前をつけることになるでしょう。
Mutationにおける部分更新
mutationそれ自体は部分更新、つまりRESTful APIでいうところのPATCHに相当する仕様はありません。ひとつのmutationはスキーマ上では単にMutation typeのfieldであり、対応するリゾルバ関数がひとつあるだけです。つまり、mutationはシンプルなRPC(Remote Procedure Call)なのです。
もし部分更新を提供するのであれば、独立したひとつのmutationを定義することになります。例えば、記事(article)のタイトル(title)だけを更新するmutationは、updateArticleTitleのようにするでしょう。
Variables
GraphQLリクエストでは、クエリとは別にパラメータを渡すことができます。それが、variablesです。variablesはJSONないしJSONと相互運用可能なシリアライザが想定されています。
variablesをクエリから参照するときは、クエリのオペレーション名のあとにパラメータリストを宣言します。
例えばGitHub API v4でorganizationの情報を得るときに、login(organization名; e.g. github)をパラメータにするときは、次のようにします。
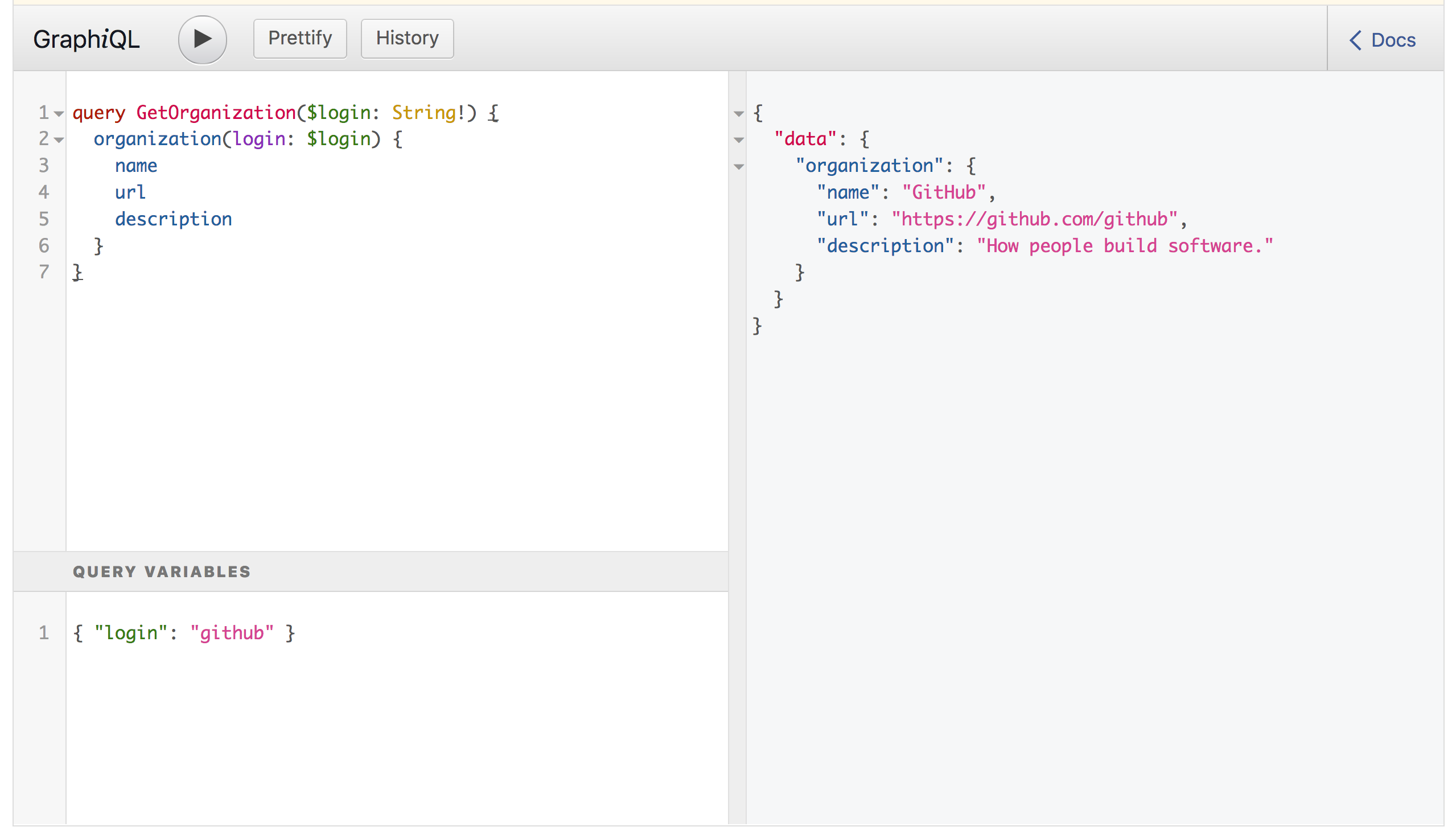
query GetOrganization($login: String!) {
organization(login: $login) {
name
url
description
}
}
これに対してvariablesを次のように与えます。GraphiQLだとクエリエディタの下にvariablesペインがあります。
{ "login": "github" }
レスポンスは次のようになるでしょう。
{ "data": { "organization": { "name": "GitHub", "url": "https://github.com/github", "description": "How people build software." } } }
GraphiQL上だとこのようになります。
variablesは型が厳密に一致していなければいけません。nullableか否かも厳密にチェックされます。
Fragment
fragmentはクエリを分割して定義し、再利用しやすくするための機能です。
GraphQLのクエリは、プロダクションコードでは長大になりがちで、単体では100行を超えることもあります。また、Reactのようなview componentのためにクエリを構築するときは、componentとクエリを対応させるため、この2つをなるべく近くに書きたいところです*6。
fragmentはfragment fragment名 on 型 { フィールドのリスト }という構文で使って定義して、...fragment名という構文で展開します。
例えば、GitHub API v4の次のようなクエリがあるとします。
query GetOrganization($login: String!) {
organization(login: $login) {
name
url
description
}
}
これを、organization fieldをfragmentとして分割すると、例えば次のようになります。
query GetOrganization($login: String!) {
organization(login: $login) {
...OrgFragment
}
}
fragment OrgFragment on Organization {
# Organization type のfieldを並べる
name
url
description
}
JavaScriptのクライアントコードだと、実用的には次のようになるでしょう。
// Apolloの `graphql-tag` packageを使う場合 import gql from "graphql-tag"; const ORG_FRAGMENT_NAME = "OrgFragment"; const ORG_FRAGMENT = gql` fragment ${ORG_FRAGMENT_NAME} on Organization { # Organization type のfieldを並べる name url description } `; const GET_ORGANIZATION = gql` query GetOrganization($login: String!) { organization(login: $login) { ...${ORG_FRAGMENT_NAME} } } ${ORG_FRAGMENT} `;
なお、JavaScriptライブラリであるgraphql-tagのgqlタグは、クエリをパースしてASTを返します。これは文字列化(graphql.print())するにあたってfragmentの重複を取り除いて正規化するなどしてくれます。また、Apolloクライアントはリクエストに際してクエリに__typename fieldを足すなどのAST改編もするようです。
Relay Server Specification
Relay Server Specificationは、GraphQLの拡張仕様です。RelayはFacebookが開発しているGraphQLをReactで使うためのライブラリで、Relay Server SpecificationはRelayがGraphQL APIに求める規約という位置づけです。
Relay Server SpecificationはFacebookが定めたものであることから、デファクトスタンダードな拡張仕様と考えていいでしょう。graphql-rubyが標準でサポートしていますし、GitHub API v4もRelay Server Specificationを満たしています。
Relay Server Specificationは次の3つの仕様を定めています。
Relay Node
Relay Nodeは、リソースの再取得を統一的に行うための規約で、Node interfaceとQuery.node()からなります。スキーマで表現すると次のようになります。
interface Node {
id: ID!
}
type Query {
node(id: ID!): Node
}
このとき、idは全てtypeのリソースにおいて一意であることが求められます。GitHub API v4のidが一見ランダムな文字列なのもRelay Nodeの仕様を満たすためで、実用的にはbase64encode("$tableName/$databaseId")のような文字列を使うことが多いようです。
Relay Connection
Relay Connectionはページング可能なリスト型に関する規約です。ページングはカーソルベースで行います。メタデータやリソースから独立した拡張データを入れるために、edgeとnodeという二重のラッパーtypeを要求します。
例えばUser typeのConnectionであるUserConnectionの最小限のスキーマは次のようになります。
type User {
id: ID!
# 他のfieldは省略
}
type UserConnection {
edges: [UserEdge]
pageInfo: PageInfo!
}
type UserEdge {
node: User!
cursor: String!
}
type PageInfo {
hasNextPage: Boolean!
hasPreviousPage: Boolean!
startCursor: String
endCursor: String
}
なお、Connection型はともかくEdge型に関してはラッパーが煩雑なため賛否両論あるようで、例えばgraphql-rubyはEdgeを省略したUserConnection.nodes: [User]を自動的に生成します。これに関しては判断が難しいところですが、筆者の環境では厳密にRelay Connectionとして運用することにして、JavaScript側に次のようなユーティリティを用意して配列とConnectionの相互変換を簡単にできるようにしています。
// relay.ts (compatible with TypeScript v3.1) export interface Edge<T> { readonly node: T; } export interface Connection<T> { readonly edges: ReadonlyArray<Edge<T>>; } export function connectionFromArray<T>(array: ReadonlyArray<T>): Connection<T> { return { edges: array.map((node) => ({ node })), }; } export function arrayFromConnection<T>(connection: Connection<T>): ReadonlyArray<T> { return connection.edges.map((edge) => edge.node); }
Relay Mutation
Relay Mutationは、mutationの引数と戻り値型に関する規約です。次の3つの規約からなっています。
- 入力は
inputという引数名とし、その入力のためのtypeの接尾辞はInputとすること - 戻り値型はリソース型そのままではなくラッパー型をつくり、そのtypeの接尾辞は
Payloadとすること - input型とpayload型は
clientMutationId: Stringを含むこと
例えば、GitHub API v4のMutation.addStar()を単純化すると次のようなスキーマになるでしょう。
type Mutation {
addStar(input: AddStarInput!): AddStarPaload!
}
type AddStarInput {
starrableId: ID!
clientMutationId: String
}
type AddStarPayload {
starrable: Starrable!
clientMutationId: String
}
type Starrable {
id: ID!
# 他のfieldは省略
}
input型をtypeとしてまとめているのは、次のように単一の$inputで入力パラメータ全体を渡すためです。
mutation AddStar($input: AddStarInput!) {
addStar(input: $input) {
clientMutationId
}
}
addStarの場合はパラメータがstarrableIdのひとつしかないためinput型は冗長にみえますが、パラメータが多いケースだとひとつひとつ渡すと煩雑なため、ひとつのオブジェクトとして渡すほうがシンプルになります。
また、戻り値もリソース型そのままではなくpayload型をラッパーとすることで、将来拡張することになっても互換性を壊さずに済みます。
Relay Server SpecificationはFacebookのように変化しつづける複雑なシステムの運用におけるベストプラクティスです。EdgeやInput、Payloadなどのラッパー型を大量に用意することを要求するので、小さなシステムでは煩雑かもしれませんが、そのシステムが変化しないという確信でもない限りは従っておくのが無難でしょう。
GraphQL APIを実装してみる
ここからは、GraphQL Ruby(graphql-ruby)を使って実際にGraphQL APIを実装していきます。対象となるWebアプリケーションはRuby on Rails製です。
grpahql-rubyはGitHubのエンジニアが開発したgemで、GitHub API v4でも使われています。RubyでGraphQL APIを実装するにあたってのデファクトスタンダードといっていいでしょう。
graphql-rubyの特徴
このgraphql-rubyですが、大きな特徴として、GraphQLのスキーマを直接は書かないという点があります。そのかわり、Rubyコードでスキーマと実装を定義していく方式を採用しています。GraphQLスキーマは、もし必要であればgraphql-rubyの機能で生成できますが、Web APIの開発中にスキーマ言語を触ることはありません。
この方式は、GraphQLスキーマとWeb APIの実装を別に管理する方法と比べると、スキーマと実装が同期していることが保証されるという利点があります。一方で、ほかの言語の実装の多くはGraphQLスキーマを手で書くため、それらと比べると開発スタイルは大きく異なります。
サンプルアプリケーション: graphql-blog
それでは、Ruby on Railsで実装するウェブアプリにGraphQL APIを実装していきます。サンプルとなるウェブアプリは次のURLにあり、この記事のセクションごとにタグを打ってあります。

最初のタグはrails_blog_spaで、名前と本文を入力して投稿するとそれが表示されるというシンプルなウェブアプリです。ただし、viewは全てReact+TypeScriptで実装されています。サーバーとはRESTful Web APIで通信しており、記事データ(articles)の取得と更新は次のAPIで行っています。
https://github.com/gfx/graphql-blog/tree/rails_blog_spa
以下、簡潔ですがウェブアプリの仕様です。
-
/(root)はReact component用のコンテナ要素を返すだけのHTMLページ - フロントエンドのエントリポイントは
frontend/App.ts - フロントエンドは次の2つのWeb APIを利用する
-
GET /articles- articleのリストを返す
- アクションは
articles#index
-
POST /articles- articleを生成し、生成したarticleをJSONで返す
- アクションは
articles#create
-
- フロントエンドはfluxアーキテクチャを採用
- ただしfluxライブラリは使わない(vanilla flux)
db/schema.rbは次のとおりで、articlesが唯一のtableとして存在します。
ActiveRecord::Schema.define(version: 2018_11_28_144307) do create_table "articles", force: :cascade do |t| t.text "name", null: false t.text "content", null: false t.datetime "created_at", null: false t.datetime "updated_at", null: false end end
このウェブアプリを起動するには、bundle installしたあとにbundle exec guardというコマンドを実行してください。webpack-dev-serverの起動が必要なので、rails serverではなくguardを使っています。
ウェブアプリが起動したらhttp://localhost:3000/にアクセスし、動作確認ついでにいくつかarticleを投稿してサンプルデータも作っておくといいでしょう。
インストール
graphql-rubyはgraphqlというgemとして提供されます。そこでまず、gem "graphql"をGemfileに足します。
$ echo 'gem "graphql"' >> Gemfile && bundle install
そしてrails generate graphql:installを実行すると、次のようにいくつかのファイルが生成されて、routes.rbにGraphQLとGraphiQLのエンドポイントが追加されます。
$ bin/rails g graphql:install
create app/graphql/types
create app/graphql/types/.keep
create app/graphql/graphql_blog_schema.rb
create app/graphql/types/base_object.rb
create app/graphql/types/base_enum.rb
create app/graphql/types/base_input_object.rb
create app/graphql/types/base_interface.rb
create app/graphql/types/base_scalar.rb
create app/graphql/types/base_union.rb
create app/graphql/types/query_type.rb
add_root_type query
create app/graphql/mutations
create app/graphql/mutations/.keep
create app/graphql/types/mutation_type.rb
add_root_type mutation
create app/controllers/graphql_controller.rb
route post "/graphql", to: "graphql#execute"
gemfile graphiql-rails
route graphiql-rails
Gemfile has been modified, make sure you `bundle install`
$ bundle install
ここまでの差分は次のとおりです。 
生成されたファイルのうち、特に重要なのは次の4つのファイルです。
- app/graphql/graphql_blog_schema.rb
- スキーマの定義であり、GraphQL処理系へのインターフェイスでもある
- app/graphql/types/query_type.rb
- GraphQLスキーマの
type Queryに相当するtypeの定義ファイル - app/graphql/types/mutation_type.rb
- GraphQLスキーマの
type Mutationに相当するtypeの定義ファイル - app/controllers/graphql_controller.rb
- GraphQL APIのエンドポイントである
graphql#executeの定義ファイル
GraphiQLで確認する
まだrails generate:installをした直後ですが、実はこの時点ですでにGraphQL APIが動きます。つまり、bin/rails serverでアプリケーションサーバを起動するとすぐに試せます。
初期状態ではGraphQL APIのエンドポイントはPOST /graphqlで、APIコンソールであるGraphiQLはGET /graphiqlです。GraphiQLの完全なURLは次のとおりです。
http://localhost:3000/graphiql
この時点で存在するのはテスト用のtestFieldだけです。クエリエディタに次のようなクエリを書くと実行できるはずです。
query {
testField
}
レスポンスは次のようになります。
{ "data": { "testField": "Hello World!" } }
Railsアプリの実装1 - GET /articlesをGraphQLのqueryとして移植
それでは、このRailsアプリのWeb APIをRESTful APIからGraphQLに置き換えていきます。
まず、GET /articlesをGraphQL APIに移植します。これは、Articleデータ構造のリストをJSONで返すRESTful APIで、次のようなコードです。
def index articles = Article.recent render json: { data: articles.map do |article| { id: article.id, name: article.name, content: article.content, createdAt: article.created_at, } end, } end
クエリの設計
実装する前にまずGraphQLのスキーマを書いてクエリの構造を考えます。
GET /articlesが返すのは、要素がarticleのリストでした。ということは、まずQuery.articlesがあるはずです。ここで型を仮にArticleListとします。
type Query {
articles: ArticleList
}
実際の型を考えましょう。GraphQLには型Tの配列型である[T]がありますが、配列型には全体の一部分のみを取得するためのページング機能はなく、全件のカウントなどのメタデータの差し込みなどの拡張もできません。今回のような個数の上限の決まっていないリソースはRelay Connectionのほうが適しています。つまり、このArticleListは、Relay Connectionに準拠したArticleConnection typeが最適です。
ArticleConnectionの要素であるArticle typeも考えます。これには、RubyのArticleクラスのうち、公開可能なフィールドをリストしていきます。今回はArticleクラスとほとんど同じインターフェイスでいいので、次のようにします。
type Article {
id: ID!
name: String!
content: String!
createdAt: String!
}
クエリの設計はここまでです。
クエリの実装
次に、Query.articlesクエリの実装をしていきます。まずArticle typeを定義するために、次のコマンドでapp/graphql/types/article_type.rbを生成します。
$ bin/rails generate graphql:object ArticleType
これにより生成されるtypes/article_type.rbは次のとおりです。
module Types class ArticleType < Types::BaseObject end end
ここに、先ほど考えたスキーマのとおりにフィールドを宣言していきます。なお、fieldの名前はgraphql-rubyがsnake_caseからcamelCaseに変換するため、Railsの標準的なスタイルであるsnake_caseのままにします。こんな感じでしょうか。
module Types
class ArticleType < Types::BaseObject
+ field :id, ID, null: false
+ field :name, String, null: false
+ field :content, String, null: false
+ field :created_at, GraphQL::Types::ISO8601DateTime, null: false
end
end
field 名前, 型, null: true or falseというのが基本的なフィールドの宣言方法です。
ところでGraphQLのフィールドに対する実装はリゾルバというものを提供するはずです。実はgraphql-rubyはデフォルトのリゾルバを提供しています。オブジェクトに対しては、フィールド名と同じ名前のメソッド呼び出しがデフォルトのリゾルバの振る舞いです。
もしArticleTypeに明示的にリゾルバを与えるとしたら、次のようになるでしょう。
module Types class ArticleType < Types::BaseObject field :id, ID, null: false, resolve: -> (article, _args, _context) { article.id } field :name, String, null: false, resolve: -> (article, _args, _context) { article.name } # ほかは省略 end end
次は、Query.articlesを定義して、クエリからTypes::ArticleTypeにアクセスできるようにします。Types::QueryTypeにarticles fieldを足しましょう。もともとあったtestFieldは消してかまいません。
module Types
class QueryType < Types::BaseObject
+ field :articles, Types::ArticleType.connection_type, null: false, resolve: -> (_object, _args, _context) do
+ Article.order(id: :desc)
+ end
end
end
Types::ArticleType.connection_typeは、graphql-rubyが生成するArticleConnection typeです。つまり、ArticleTypeを要素に持つRelay Connectionに準拠したtypeです。
リゾルバではArticleを新着順にソートして返します。ActiveRecord::RelationとRelay Connectionの間も、graphql-rubyがいい感じに変換を行ってくれます。
この時点でクエリを実行できるようになったはずです。しかしその前に、GraphQLのスキーマを出力してみましょう。
次のコマンドで標準出力にスキーマが表示されます。ほぼ設計したとおりのクエリがあるはずです。
$ bin/rails runner 'puts GraphqlBlogSchema.to_definition'
無事に実行できたら、GraphiQLでクエリを実行しましょう。だいたいこんな感じでしょうか。articlesはRelay Connectionなのでedgesとnodeという2つのラッパー型でネストが深くなっています。
query {
articles {
edges {
node {
id
name
content
createdAt
}
}
}
}
レスポンスはDBのデータに依存しますが、例えばこんな感じになります。
{ "data": { "articles": { "edges": [ { "node": { "id": "12", "name": "gfx", "content": "こんにちは!", "createdAt": "2018-12-02T11:42:22Z" } }, { "node": { "id": "11", "name": "mfx", "content": "バブー!", "createdAt": "2018-12-02T11:31:03Z" } } ] } } }
Relay Connectionのedgesとnodeは最初はちょっと使いづらいかもしれませんが、こういうものだと思うとすぐ慣れます。
これでGET /articlesのGraphQLは完了です。 
Railsアプリの実装2 - POST /articlesをGraphQLのmutationとして移植
次はPOST /articles(articles#create)をGraphQLにmutationとして移植します。
mutationは全てMutation typeのfieldとして定義するため、queryよりもずっとシンプルです。また、graphql-rubyでmutationを作るとデフォルトでRelay Mutationに準拠したmutationになるため、Relay Mutationもそれほど意識しません。
それでは、次のコマンドでapp/graphql/mutations/create_article.rbを作成します。
$ rails generate graphql:mutation CreateArticle
こんな感じのファイルです。コメントで、戻り値と引数とリゾルバを定義するように書いてあります。
module Mutations class CreateArticle < GraphQL::Schema::RelayClassicMutation # TODO: define return fields # field :post, Types::PostType, null: false # TODO: define arguments # argument :name, String, required: true # TODO: define resolve method # def resolve(name:) # { post: ... } # end end end
また、queryと異なり、Types::Mutationにもfieldが追加されます。mutation fieldに関する全ての情報はmutationクラスにあるため、Types::MutationTypeには宣言だけあれば十分なのです。
module Types
class MutationType < Types::BaseObject
+ field :createArticle, mutation: Mutations::CreateArticle
# ...
さて、移植元のarticles#createアクションはこのようなコードです。
def create article = Article.new(params[:article].permit(:name, :content)) article.save! render json: { data: { id: article.id, name: article.name, content: article.content, createdAt: article.created_at, }, } end
これをそのままCreateMutationに移植するとこうなります。
module Mutations class CreateArticle < GraphQL::Schema::RelayClassicMutation argument :name, String, required: true argument :content, String, required: true field :article, Types::ArticleType, null: false def resolve(name:, content:) article = Article.new(name: name, content: content) article.save! { article: article } end end end
queryとだいぶ書き方が違いますが、これはmutationの実体が、Mutation typeのfieldだからです。実際にMutations::CreateArticleで定義しているtypeは、Mitation.createArticleの引数であるCreateArticleInput typeと、戻り値であるCreateArticlePayload typeです。
正しく定義できたか確認するために次のコマンドでスキーマを出力して、エラーなく実行できることを確認してください。
$ bin/rails runner 'puts GraphqlBlogSchema.to_definition'
問題がなければ、GraphiQLのクエリエディタに次のクエリを入力して実行してみてください。
mutation {
createArticle(input: { name: "hello from graphql api", content:"yey!"}) {
article {
id
name
content
createdAt
}
}
}
問題なく実行され、http://localhost:3000でもarticleが追加されていれば成功です。
mutationの実装はこれで完了です。 
GraphQLを使うフロントエンドアプリを実装してみる
最後に、ウェブアプリのフロントエンドを書き換えます。これは一気にやってしまいましょう。
RESTful APIとの違いを明確にするために、ライブラリはまったく使わずにfetchそのままでリクエストします。import ... from "relay"は、先に掲載したrelay.tsです。
では、少し長いですが差分を掲載します。
--- a/frontend/App.tsx +++ b/frontend/App.tsx @@ -7,6 +7,7 @@ import { ArticleType } from "./Article"; import { Footer } from "./Footer"; import { Header } from "./Header"; import { request } from "./client"; +import { Connection, arrayFromConnection } from "./relay"; const mainStyle = { margin: 40, @@ -24,23 +25,54 @@ export class App extends React.Component<Props, State> { }; async componentDidMount() { - const result = await request<ReadonlyArray<ArticleType>>({ - method: "GET", - url: "/articles", + const query = ` + query GetArticles { + articles { + edges { + node { + id + name + content + createdAt + } + } + } + } + `; + + const result = await request<{ articles: Connection<ArticleType> }>({ + query, }); - this.setState({ articles: result.data }); + this.setState({ articles: arrayFromConnection(result.data.articles) }); } @autobind async handleArticleSubmit(article: ArticleType) { - const result = await request<ArticleType>({ - method: "POST", - url: "/articles", - body: { article }, + const query = ` + mutation CreateArticle($input: CreateArticleInput!) { + createArticle(input: $input) { + article { + id + name + content + createdAt + } + } + } + `; + type CreateArticlePayload = { article: ArticleType }; + const result = await request<{ createArticle: CreateArticlePayload }>({ + query, + variables: { + input: { + name: article.name, + content: article.content, + }, + }, }); this.setState({ - articles: [result.data, ...this.state.articles], + articles: [result.data.createArticle.article, ...this.state.articles], }); } diff --git a/frontend/client.tsx b/frontend/client.tsx index 64b1f14..32810e4 100644 --- a/frontend/client.tsx +++ b/frontend/client.tsx @@ -1,27 +1,26 @@ interface RequestOptions { - method: "GET" | "POST"; - url: string; - body?: object; + query: string; + variables?: object; } interface Response<T> { data: T; } -export async function request<T>({ method, url, body }: RequestOptions): Promise<Response<T>> { +export async function request<T>({ query, variables }: RequestOptions): Promise<Response<T>> { const fetchOptions: RequestInit = { - method, + method: "POST", headers: { "X-Requested-With": "xhr", + "Content-Type": "application/json", }, + body: JSON.stringify({ + query, + variables, + }), }; - if (body) { - fetchOptions.headers!["Content-Type"] = "application/json"; - fetchOptions.body = JSON.stringify(body); - } - - const response = await fetch(url, fetchOptions); + const response = await fetch("/graphql", fetchOptions); const json = await response.json(); if (json.data) { return Promise.resolve(json);
2つあるリクエストはいずれも行数が増えています。しかし情報量は増えているので、読みやすくなっているのではないでしょうか。
GraphQL APIをプロダクションで使うときはApolloなどのクライアントライブラリを使うことが多いと思います。しかし、GraphQL APIは本質的に、クエリ文字列とパラメータをJSONで送ってJSONでレスポンスを受け取るだけのシンプルなWeb APIなのです。
以上でフロントエンドも完了です。 
まとめ
この記事の前半ではGraphQLそのものの概要を解説しました。後半では、Rubyのライブラリであるgraphql-rubyを使って、Ruby on Rails製のウェブアプリのRESTful APIをGraphQL APIに移植するまでをハンズオン形式で解説しました。
この記事でGraphQLに興味を持っていただければ幸いです。



株式会社ディー・エヌ・エーやクックパッド株式会社でのエンジニア経験を経て、2016年8月よりビットジャーニーに入社。 ウェブやモバイル技術のエコシステムに関心がある。近年はAndroid関連でツールやライブラリをOSSとして多数公開し、DroidKaigiの運営スタッフも務める。
ブログ:Islands in the byte stream
ブログ:Islands in the byte stream
【修正履歴】
編集協力:薄井千春(ZINE)
*1:Facebook, September 2015, https://graphql.org/blog/graphql-a-query-language/
*2:スキーマ開発駆動について詳細には立ち入りませんが、ここではサーバーサイドとクライアントサイドのチームが分かれているとき、スキーマをチーム間のコミュニケーションツールとして使っていく開発手法です。
*3:この記事では単に「サーバーから取得するべきデータの集合」くらいの意味で「リソース」という言葉を使っています。
*4:なお、ここでいう「インターフェイス」というのはGraphQLスキーマの一部であるinterfaceとは異なり、文字どおりのインターフェイスです
*5:プロダクションでは生の配列を使うことは少なく、ほとんどのケースではRelay Connectionを使うでしょう。しかしここでは例示のためシンプルな生の配列を使ってます。
*6:詳細には立ち入りませんが、Facebookの開発するRelayはまさに「componentとクエリをなるべく近くに定義する」という設計です。 https://facebook.github.io/relay/




