
DBの寿命はアプリより長い! 長生きするDBに必要な設計とリファクタリングを実践から学ぶ
アプリケーションの寿命よりも長く、データの追加やテーブルの変更で成長し続ける「データベース」と、どのように付き合っていけばよいのでしょうか? 曽根壮大(soudai)さんによる寄稿です。
こんにちは。そーだい(@soudai1025)です。
新しいサービスを始めるとき、必ずと言っていいほどデータベースは利用されています。また今稼働しているサービスの多くでも、RDBMSをはじめ、いろいろなデータベースが利用されています。そんなに広く利用されているデータベースだからこそ、多くの問題の元になるのもまた事実です。
そこで今回は、Webサービスを中心にデータベースの選び方、設計についてお話していきたいと思います。そして私もまさに今、2011年から続くWebサービス「オミカレ」のRDBMSのリファクタリングに携わっており、その経験も余すことなくお伝えします。
DBの寿命はアプリケーションより長い
一番最初にお伝えすべきことは、データベースの寿命はアプリケーションよりも長いということです。これはどういうことでしょうか?
想像してみてください。例えば、新しくSNSのサービスをリリースしたとします。このSNSは1年、2年と順調にユーザー数を増やしていきます。そして、獲得したユーザーをより活用するため、新たにECサービスをローンチしたとしましょう。
このECサービスがリリースされた瞬間から、SNSの会員データはECサービスと共有されることになります。
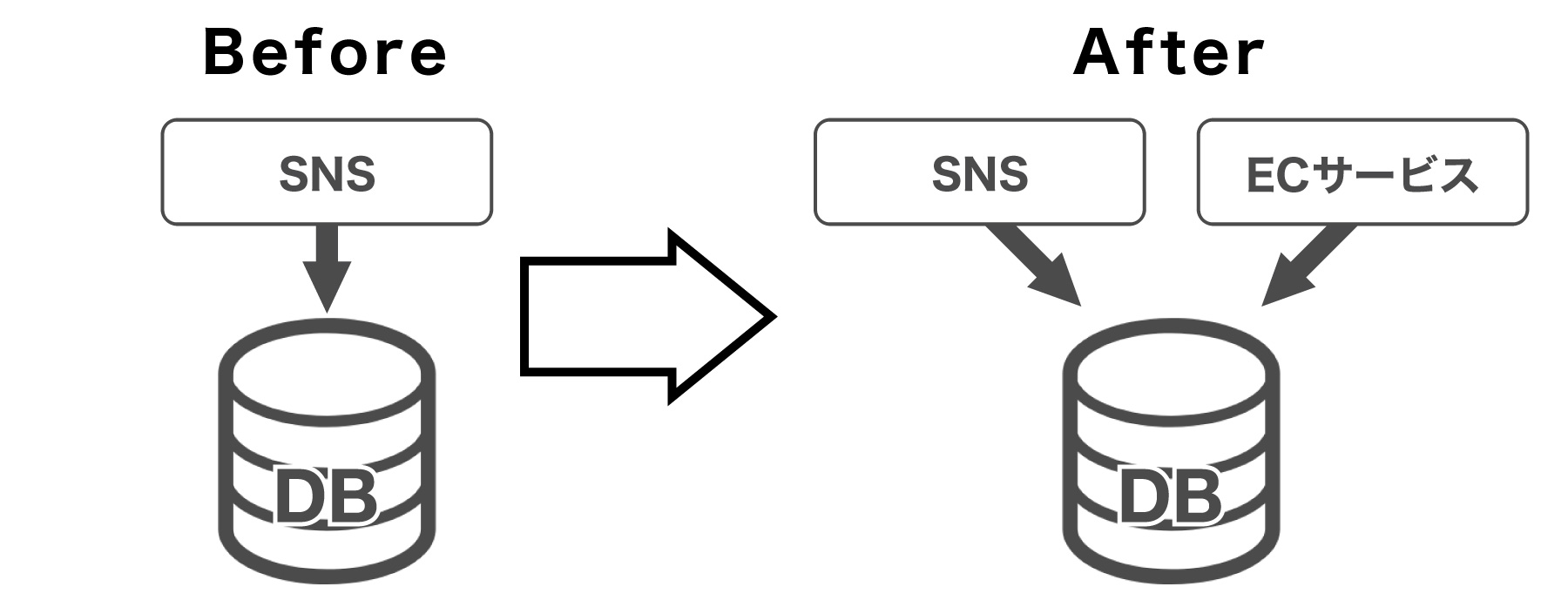
このように同じデータベースを複数のアプリケーションから参照することは一般的ですし、例えばRDBMSを利用していればトランザクションを備えていますし、適切なユースケースと言えるでしょう。
さて、ECサービスが順調に拡大してきたころ、流行(はや)り廃りもあってSNSを閉じることになりました。そうなるとデータベースはどうでしょうか? 共に生まれ育ったSNSが閉じても、ECサービスから会員情報を参照されているため、閉じることはありません。
このように複数のアプリケーションから参照されることも、そしてアプリケーションよりもデータベースの寿命が長いことも、一般的なことなのです。
アプリケーションのリプレースとDBのリプレース
データベースの寿命を考えるには、もう1つ良い例があります。
ECサービスをリプレースしたいと考えたとき、アプリケーションコードを捨てて、全て新しく実装することはあり得るでしょう。しかし、データベースはどうでしょうか? 中身のデータを全て捨てて、新しく作り直すことはまずないでしょう。
ハードウェアであれば故障や定期交換で新しくなることがありますし、OSやプログラミング言語はバージョンアップが定期的に行われます。特にプログラミング言語のバージョンアップの際には、合わせてリファクタリングを行うこともあるでしょう。
では、データベースはどうでしょうか? ミドルウェアのバージョンアップをすることはあっても、リファクタリングまでされた経験がある方は、読者の方の中でも少ないのではないでしょうか。もちろんデータを捨てて、新しいデータベースを構築することはまずありません。
このように、データベースは寿命が長いからこそ巨大になりやすく、また変化に対する恐れが生まれやすいのが特徴です。
複数のアプリケーションから参照される場合
先程、SNSとECサービスを例に挙げましたが、複数のアプリケーションから参照されるケースは他にもあります。
例えば、SaaSやPaaSとの連携です。あなたが使うサービスが、スマホのプッシュ通知をSaaSを使って実装していた場合、プッシュのリストを連携する必要があります。
また、サーバレスアーキテクチャやマイクロサービス化していけば、その傾向はより顕著になることでしょう。インターフェイスとしてREST APIがあったり、各々のデータストアはあるとしても、共通のデータストアは必要だからです。そして、その多くの共通のデータストアの中に、RDBMSをはじめとするデータベースがあることでしょう。
その他、データ分析基盤にも昨今はSaaSを利用することが一般化していますし、複数のアプリケーションでデータを共有する仕組みは、いろいろな場所で発生します。
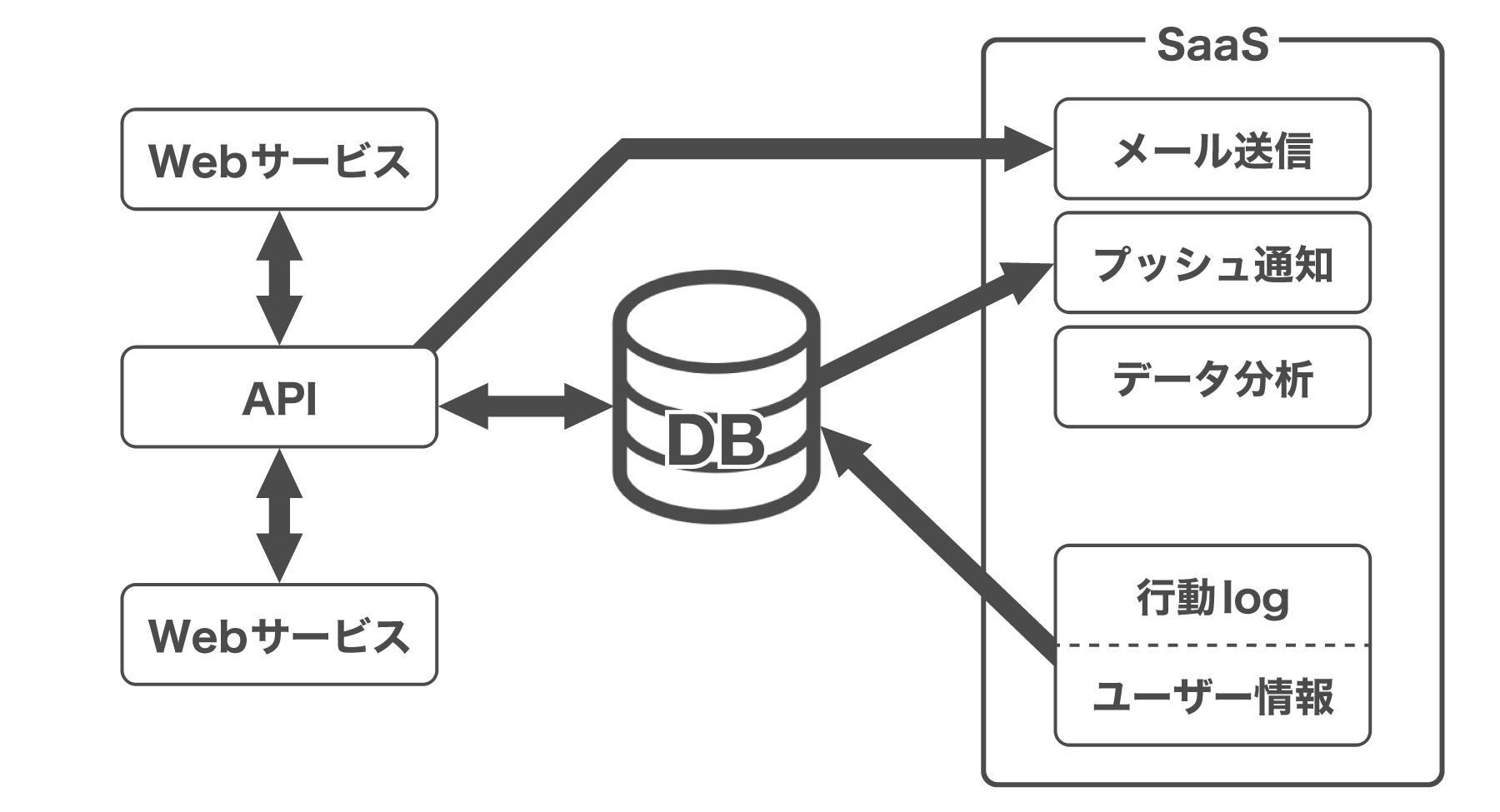
0から1にするときのDB設計
このように、データベースはさまざまなところで使われるため重要な存在ですし、だからこそデータベースの問題が多くのサービスに影響します。みなさんも、パフォーマンスチューニングなどで困った記憶があるのではないでしょうか。では、どうしてそのような状態になるでしょうか?
その理由は、データベースの特性にあります。基本的にデータベースにはデータが追加されていきますし、データの状態を変える作業の多くも、テーブルやカラムの追加です。もちろん更新や削除もありますが、参照を除くデータベースの状態の変化の多くは追加で行われるため、まさにデータベースが成長していくのです。
そして5年、10年という長いデータベースの寿命とその特性が噛み合って、巨大なデータベースが生まれるのです。
仕様追加に強い設計
それでは、どうすれば仕様の追加に強いデータベースを作ることができるのでしょうか?
データベースの設計は積み木に例えられます。例えば次の図のように、最初の設計から正しく設計されていたなら、次に行われる仕様の追加もしやすくなります。このように正しく設計していけば、追加はそれほど難しいことではありません。
builderscon 2017登壇資料「rdb antipattern refactoring」25ページより
しかし、次のような形になっていたときはどうでしょう? 次に乗せる仕様が難しいことは、一見してわかりますね。
同じく「rdb antipattern refactoring」27ページより
さらに、この上に丸を乗せる天才が現れた日には、後のメンテナンスが地獄絵図になることは容易に想像できます。しかし、このような状態は残念ながら散見され、アンチパターンと呼ばれたり、悪い設計として存在しています。
それでは、正しく設計し、積み木を載せていくにはどうすればよいのでしょうか?
データと情報の違い
正しい設計の答えは、残念ながらありません。しかし、正しい答えに近づくための手法はいくつかあります。その上で重要なことは、まずデータと情報の違いを知ることです。
データは、ありのままの事実です。そして情報は、表示したい内容に合わせてデータを加工した結果です。
例えば、ユーザー情報の中に「生年月日」があったとします。これはありのままの事実、データです。それでは、ユーザープロフィールに「年齢」を表示したい場合はどうでしょうか? 皆さんのお気づきの通り、年齢は生年月日を加工した情報なのです。
年齢も事実だと思われるかもしれませんが、毎年カウントアップされ、変化します。それに対して、生年月日は変化しません。これが、データと情報の大きな違いの1つです。
名著『SQLアンチパターン』日本語版(オライリージャパン、2013年)のまえがきでも、監訳者の和田省二さんが次のように書いています。
さて、皆さんは「情報」と「データ」の違いをご存知でしょうか。この二者の関係は「多くの情報を秘めた貴重なデータ」という表現で言い尽くせます。いつでも我々が欲しいのは、意味のある(目的を持った)正しい情報なのです。一方、データは単なる各種の事実の値(何らかの、名称とか日付とか金額とか)であってそれ自体に目的はありません。
みなさんにも、この違いが見えてきたと思います。 つまり、データベースに保存するべきなのはまさにデータ、事実を保存することが重要なのです。
データモデリングを最初にする
それでは、データをどのように保存していくか? そのためには、まずデータモデリングすることが大事です。
データモデリングの主な目的は、データの定義し、フォーマットを決めることです。データモデルには、3つの段階があります。
- 概念スキーマ
- 事業ルールや業務データなどを抽象化して、エンティティとして定義する
- 論理スキーマ
- テーブルおよびカラムの場合はER図、オブジェクト指向クラスなどの場合はUML図などで表現して定義する
- 物理スキーマ
- 実際に利用するミドルウェアなどに合わせて定義する
冒頭でデータモデリングしましょうと説明しましたが、まずは概念スキーマの部分から始めます。データモデリングでは、現実世界のデータをエンティティに分けていくことで、どのように関連付けていくか整理することができます。
それによって、RDBMSならリレーショナルモデルにそって論理スキーマを設計し、正規化していくことになりますし、リレーショナルモデルが難しいデータモデル、例えばツリーやグラフなどは、RDBMS以外のデータストアを検討することになります。
このようにデータモデリングすることで、どのデータを、どこに、どのように保存していくかということがハッキリします。
このとき、情報を保存してしまったり、リレーショナルモデルが苦手なデータモデルをRDBMSに保存したり、逆にリレーショナルモデルにすべきところを疎かにしてしまうと、後々に響く設計になってしまいます。
この話は、今年のbuildersconでさせていただきました。
RDB THE Right Way ~壮大なるRDBリファクタリング物語~ - builderscon tokyo 2018
RDBMSとNoSQLの使い分け
NoSQLは「Not only SQL」のことで、RDBMS以外の全てを指しますので、対象はとても広い範囲に及びます。それを踏まえた上で、RDBMSとNoSQLをどのように使い分けると良いのでしょうか。
まず、忘れてはいけないこととして、RDBMSとNoSQLは排他ではなく、共存できる存在です。ですので、どのミドルウェアを使うかはケースバイケースです。
それはもちろんRDBMSの種類によっても違います。大規模なリードレプリカが必要なケースなど、MySQLが良い場面もあります。業務フローが複雑で制約が欲しいときにはPostgreSQLを使うこともあるでしょう。大規模なECサイトや決済システムはOracle DBの主戦場です。
このようにRDBMSだけでも使い分けがありますが、NoSQLはこれらRDBMSの苦手なところを埋めてくれる存在です。つまり、RDBMSが苦手なことをNoSQLにやらせるべき、というのが使い分けのコツです。
そこで、先程のデータモデリングが重要になります。ツリーやグラフなどリレーショナルモデル以外のデータモデルは、RDBMSが苦手としていますから、NoSQLを検討しても良いでしょう。
さらに論理設計・物理設計と落とし込んだとき、RDBMSのトランザクションが不要だったり、参照や更新がヘビーだったりするなら、別のデータストアを検討したくなります。大規模な更新をさばくような環境では、次のようなアーキテクチャの例があります。
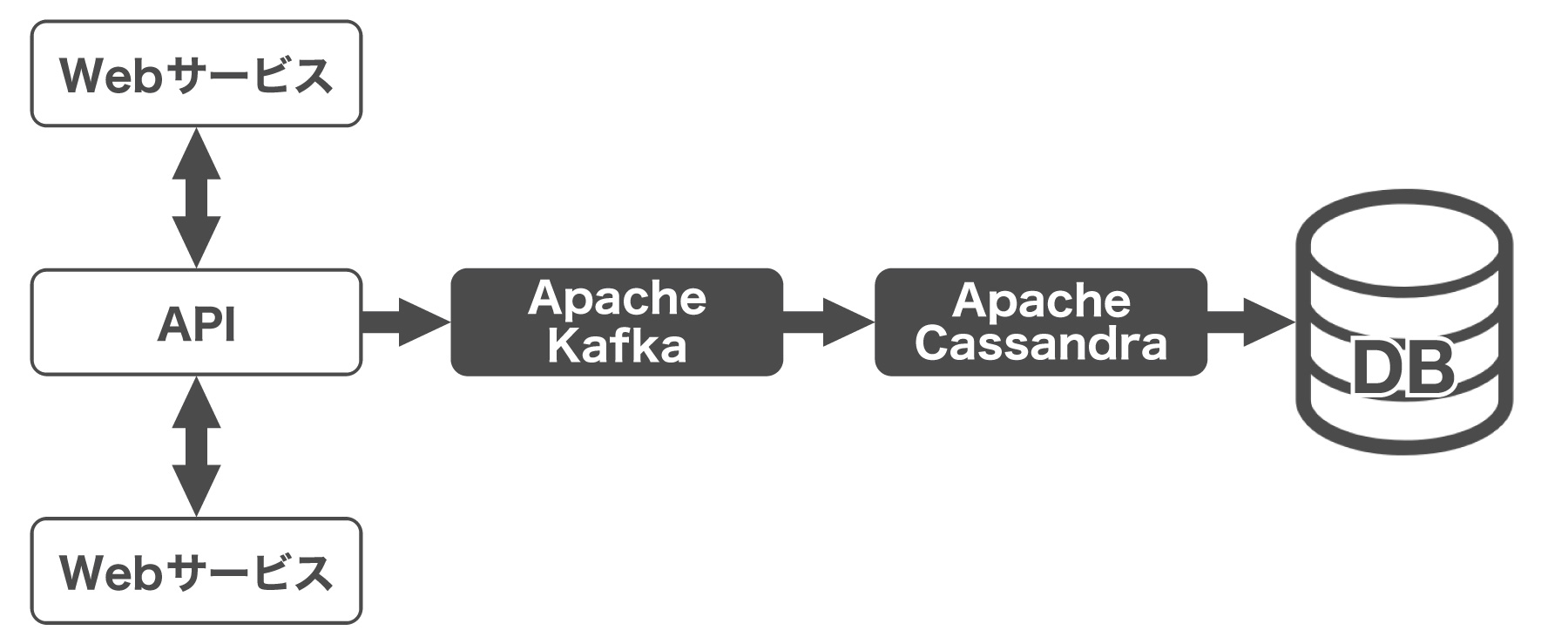
このようにRDBMSとNoSQLが共存して、お互いに得意なところを生かすことが大切です。
最初からNoSQLを使うべきか
これは先程の例の通りケースバイケースですが、積極的に採用すべきか? というと悩ましいところです。
利用するデータストアの種類が増えれば増えるほどシステムは複雑になりますし、開発環境の用意が大変になります。これは、スタートアップのスピード感を殺してしまう原因に十分なります。ローンチして当たるかどうかもわからないWebサービスでは、最初から重厚なデータストア層を作っても無駄になるかもしれません。
そこで論理設計時にそれも踏まえた上で、RDBMSにやらせる判断もアリです。そういうときに効いてくるのが、JSON型やCTE(再帰クエリ)といったRDBMSの機能です。NoSQLが使いたいとき、RDBMSの機能で十分な対応ができないか、一度は検討してみてください。
ただし注意が必要なことですが、RDBMSで表現できたとしても、苦手なことは変わりません。リレーショナルモデルの設計のレールを踏み外していることを意識するようにしましょう。その上で、小規模なところなどでまずRDBMSの機能を使って実装することは、ビジネス判断としてよくある話です。
このように多くのシステムでRDBMSが採用される理由の1つは、トランザクション以外にもRDBMSだけで多くのシステムを構築することができるからです。この特性を生かして、素早くサービスを構築していきましょう。
ローンチは長いDBの旅の始まり
ここまで理論と理想の話をしてきましたが、実際の現場では簡単なことではないとおっしゃる方もいるでしょう。実際に、妥協点をどこに置くかの判断は非常に難しく、正解はありません。
RDBMSに関するまとめとしては、以下の4点を必ず守ってください。その方が良い結果になります。
- データモデリングをしっかりと、最初に行う
- 正規化を行う
- 制約を活用する
- RDBMSの飛び道具にいきなり頼らない
冒頭にも述べたとおり、初期設計はその後のサービスの改善に大きな影響を与えます。そのためにも、これらの点を常に意識するようにしましょう。
1から100に成長した今、戦っていること
初期設計がうまくいっても、その後の積み重ねがうまくいくとは限りません。また最初はスピードを優先して作った設計が後々に課題、いわゆる技術的負債になることもあります。
サービスがある程度成長してくると、このような課題に対して向き合う必要があります。その際に必要なことがデータベースリファクタリングです。2017年のbuildersconでも、データベースのリファクタリングについて登壇しました。
RDBアンチパターン リファクタリング - builderscon tokyo 2017
ここでは実際に上記を踏まえた上で、今まさに私が行っているデータベースリファクタリングについてご紹介します。
データベースの不吉な匂い
データベースのリファクタリングの対象を見極める必要があります。例えば、名著『データベースリファクタリング』(Addison-Wesley Professional、2006、日本語版は絶版)では、次のような項目はリファクタリングの対象と記載されています。
- 複数の目的に使われるカラム
- レコードの属性に合わせて値の意味が変わるカラム
- 会員だと入会日、スタッフだと入社日とするなど
- 複数の目的に使われるテーブル
- カラムの場合と同様に1つのテーブルが複数の意味を持つ
- Usersテーブルに会員、管理者、事業者などが混在しているなど
- 冗長なデータ
- 非正規化など
- 生年月日と年齢カラムがあった場合、1年経ったときに年齢カラムが事実からずれてデータの整合性が取れなくなる。
- カラムの多すぎるテーブル
- memo1、memo2、memo3...memo99 など
- 複数のエンティティの責務を束ねている可能性がある
- 行の多すぎるテーブル
- データを削除しないテーブル
- 削除が怖いために論理削除で対応するなど
- 本当にデータの行数が大きくなるテーブルならパーティションなどを検討する
- 「スマート」カラム
- データの中にビジネスロジックなど、データ以上の意味を持っているもの
- 9から始まるidは管理者、1から始まるidはユーザーなど
- 変更の恐怖
- データベースの変更やデータの更新によって、アプリケーションが壊れるのでは? という恐怖があって手を付けれない状態
これらの箇所を見つけたとき、重要なのは技術的負債を回収する必要はあるか? を確認することです。
技術的負債には、ビジネス的な価値のあるチーズと、完全なる負債の腐った牛乳があります。どちらも異臭を放っていたとしても、それに対するアプローチは大きく変わります。
データベースリファクタリングは手間も時間もかかるため、だからこそ見つけた際には次の点を検討しましょう。
- リファクタリングの意味はあるか?
- 作業に応じたの効果はあるか?
- 今やるべきか?
例えば、カラムの名前が不適切だったとします。名前を正しくしたいが、多くのアプリケーションコードを修正する必要があるときに費用対効果がある場面は少ないでしょう。
それに対してデータの不整合が頻発し、問い合わせ対応に追われている状況なら、データの制約の追加などは工数が掛かっても取り組むべき課題です。このように不吉な匂いを嗅ぎ分け、適切な優先順位をつけていくことが大切です。
リファクタリングのための準備
データベースリファクタリングをやると決めた場合、戦う前の準備が必要です。
まずリファクタリングの方向性を決める必要があります。自分がやりたいリファクタリングは何なのか? をしっかり決めましょう。主なデータベースリファクタリングの分類は次のとおりです。
- 構造 …… テーブルやViewの定義
- データ品質 …… データの値
- 参照整合性 …… テーブルの関連性
- メソッド …… ストアドプロシージャー
- 変更 …… テーブルやカラムの追加
- アーキテクチャ …… アプリとのインターフェイス
分類がはっきりし、対象を選定して移行期間が決まれば、次に必要なタスクは実際にリファクタリングするための準備で、大きく2つあります。
- テストとモニタリングを揃える
- リリース戦略を決める
特にテストやモニタリングが不十分では、リファクタリング中に発生した問題に対応していくとき、無策で戦うことになります。データベース障害は即サービス障害ですから、事前に準備をしっかり整えておきましょう。
準備が整えば、あとは粛々と小さくリファクタリングを繰り返していくのみです。時間はかかりますが、結果は必ずついてきます。
細かい点は、前述したbuilderscon 2017の登壇内容で説明していますので、ぜひ見ていただければと思います。
壮大なるデータベースリファクタリング
ここまで読んだ読書の皆さんは「実際のデータベースリファクタリングしている話が知りたい」と感じていると思います。そこで、私が実際にデータベースリファクタリングを行っている内容を、前述の話を踏まえて説明していきます。
現状を把握する
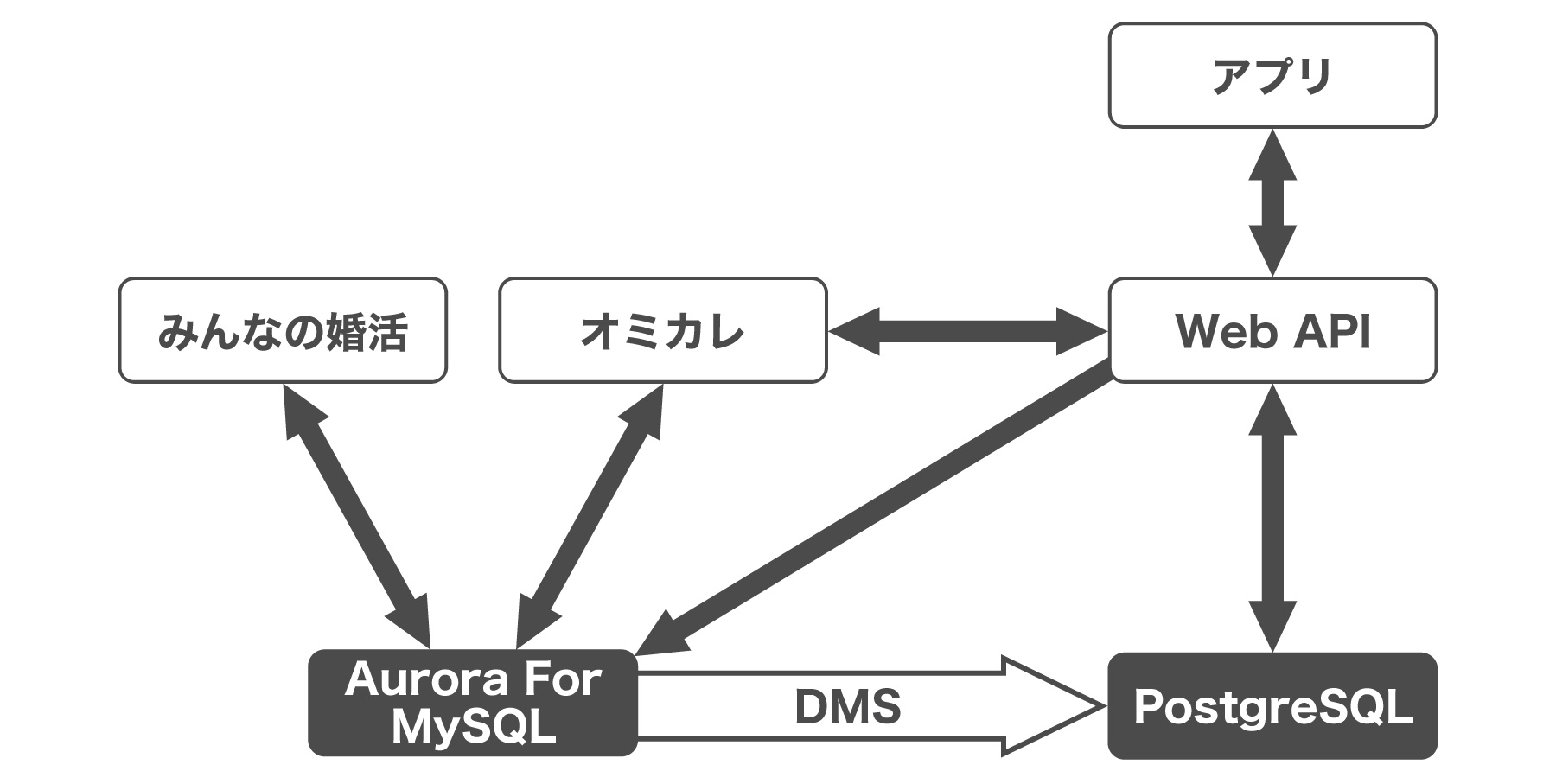
オミカレのデータベースは、2011年にサービスがローンチされて以来、例に漏れず追加追加で成長してきました。また、兄弟サービスの「みんなの婚活」などからも参照されており、まさにマルチアプリケーションの状態です。
しかし、ところどころで制約が不十分だったり、パフォーマンスの都合で非正規化されていたりで、データの不整合に悩まされていました。特に、婚活パーティをつかさどるpartyテーブルが肥大化しており、多くの場所に依存し、そしてパフォーマンスのボトルネックになっていました。
これは完全にデータベースの不吉な匂いを放っています。そこで、データベースリファクタリングを行っていくことを決めました。
方針を決める
実際にデータベースをリファクタリングする際の方針はいくつか考えられますが、今回は2つの方針を検討しました。
- 特定のタイミングでリファクタリング後の状態に切り替える
- リファクタリング後の状態と前の状態を作り、両方に更新を行う
1は、移行計画をしっかり組めばウォーターフォール型で進めることができるので効率的ですし、対応が一度で完了します。しかし、オミカレ以外のサービスでもDBを参照していますし、オミカレの新規開発を止めることはできません。
そこで、今回は2の方針を選択し、時間はかかるが確実に進めていくことにしました。データベースリファクタリングは小さいスコープで進めていくことが成功の秘訣だからです。
データベースリファクタリングの手法
手法としては、下記の図のようにデータベースをコピーし、コピー先でテーブルを適切に再設計したテーブル構造に割り振るようにしました。これにより、既存のシステムは全く影響を受けません。
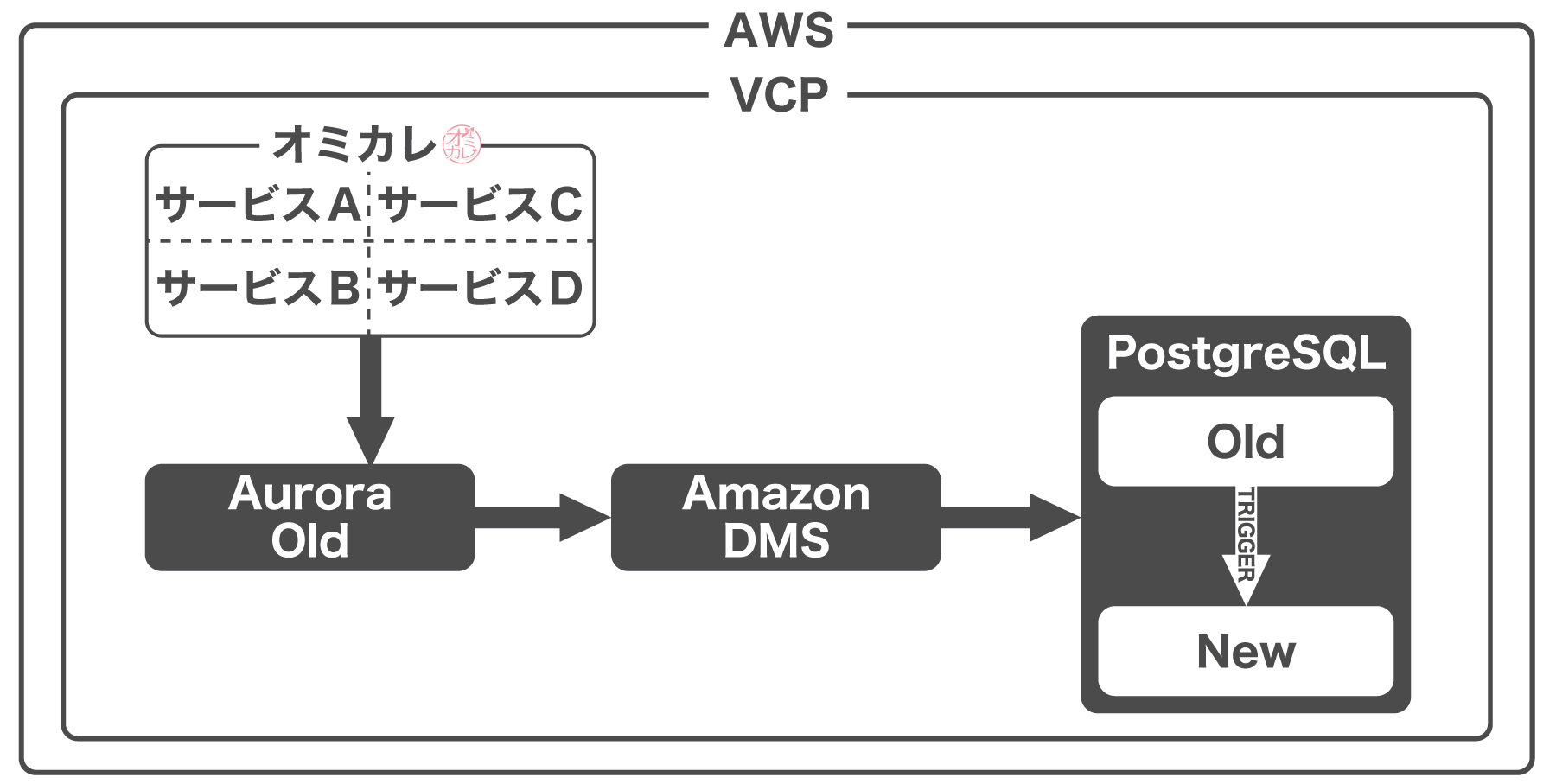
そして、切り替え方は、参照を抽象化するためREST APIを用意し、参照・更新をAPI経由にすることで、モデル層のリファクタリングとDB移行を段階的に行うことにしました。
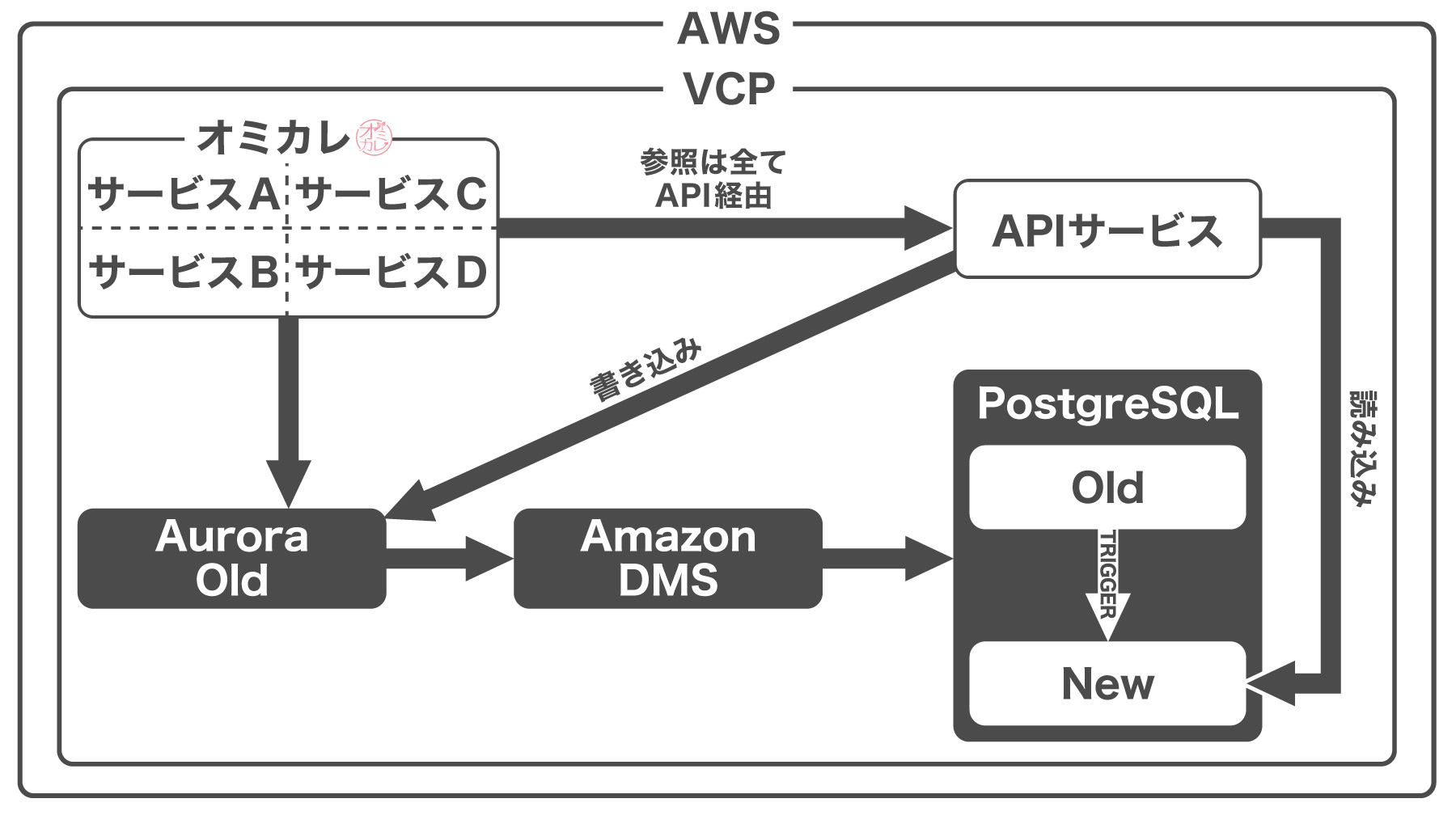
ここで重要な判断は、移行先のRDBMSとして元のAmazon AuroraのベースであるMySQLではなく、PostgreSQLを採用したことです。理由は2つあります。
1つ目は、古いデータ構造から新しいデータ構造に変更する部分を、トリガーが担っていることです。Aurora 1系のベースになっているMySQL 5.6は、1つのテーブルの1つのイベントに1つのトリガーしか設定できません。通常の範囲であればそれで必要十分といえるのですが、今回はかなりの大規模なリファクタリングになりました。
実際にpartyテーブルは、1つのテーブルから5個以上に分割しています。そうなると、1つのトリガーで全て対応するには責務が大きすぎます。
MySQL 5.7やMySQL 8、Aurora 2系も検討しましたが、トリガーの柔軟性ではPostgreSQLが優れていたため、個数に制限のないPostgreSQLを採用しました。
しかし、現状はAuroraを使っているため、PostgreSQLには異種DB間の移行が必要になります。異種DB間移行ツールをいくつか検討した結果、AWS Database Migration Service(以下、DMS)を採用しました。
DMSでは、異種DB間でもリアルタイムに、まるで非同期レプリケーションしているかのように連携できるため、サービスを止めることなく移行が可能になります。また、コスト面でもDMSで利用するインスタンスサイズのみと、他のツールより圧倒的にメリットがありました。
以上の結果から、現在は次のような構成になっています。
もう1つの理由は、慣れているプログラミング言語でストアドファンクションを書けるという点で、次のブログ記事でも説明しているようにpl/v8(JavaScript)を採用しています。


この状態で、APIを作るところまでは既存のサービスは全く影響を受けません。ある程度APIを作って、APIの結果と既存の結果のdiffを見ることで、振る舞いのテストをすることもできます。参照の切り替えもAPI単位で行うことができ、ロールバックも簡単に行うことができるため、小さく始めることに適しています。
異種DB間移行については、実担当の

データベースリファクタリングの進捗
実際に上記の方法で準備を始めて、現在7カ月が経っています。メリットである既存サービスに影響を与えないこと、API化することでデータストア層を抽象化できることが功を奏して、順調に移行しています。
もっとも現状のスケジュールでは、完全に移行できるのは2019年4月を目処にしていますので、1年計画となります。また、移行して終わりではなく、移行後も新たなデータベースリファクタリングは始まります。なぜなら、データは移行中も移行後も成長し続けるからです。
これからも戦い続けるエンジニアへ
ここまで読んでいただきましたが、いかがでしたか? データベースリファクタリングは、その影響範囲の広さから苦労も多く、その割にはビジネス的なメリットが少ないと言われることが多いところです。新機能の追加の優先順位を高くすることで、どうしても後回しにされがちなタスクですが、いつかは向き合う必要があります。
データベースの問題は、時間が経てば経つほどデータベース自体の成長とともに大きくなっていきます。だからこそ、誰かが覚悟を持って取り組んで行く必要があります。そして、その誰かはそのサービスに触れているあなた自身です。
私の尊敬するエンジニアの言葉を引用します。
手を動かしたものだけが世界を変える by
id:onishi 
この言葉は真理だと思っています。あなたのサービスを育て、変えていくのはあなたのその手に委ねられているのです。この記事を見た皆さんも、これを機に自分たちのデータベースをぜひ見直してみてください。
曽根 壮大(そね・たけとも) 


株式会社オミカレ副社長兼CTO。数々の業務システム、Webサービスなどの開発・運用を担当し、2017年に株式会社はてなでサービス監視サービス「Mackerel」のCRE(Customer Reliability Engineer)を経て現職。コミュニティでは、Microsoft MVPをはじめ、日本PostgreSQLユーザー会の理事として勉強会の開催を担当し、各地で登壇している。builderscon 2017、YAPC::Kansaiなどのイベントでベストスピーカーを受賞し、分かりやすく実践的な内容のトークに定評がある。他に、岡山Python勉強会を主催し、オープンラボ備後にも所属。『Software Design』誌で、データベースに関する連載「RDBアンチパターン」などを執筆。
ブログ:そーだいなるらくがき帳
ブログ:そーだいなるらくがき帳




