
自然言語処理ってなに?課題は? 研究者に聞く、エンジニアが学術論文を読み解くための技術
多くのサービスに実装される自然言語処理ですが、そもそも一体どのような技術なのでしょうか?東京工業大学で研究にあたる、西川 仁助教に自然言語処理の歴史と現在。そしてどのような課題があるかをうかがい、さらにエンジニアが学術論文を読み解き、役立つ情報を手にするための手法も聞きました。
技術に関する最新の情報を得るための手段は様々ですが、“学術論文を読む”とは、その有力な手段の一つでしょう。しかし、数多くある論文から、自分の目的とする情報をいかに探し出し、いかに読むのが効率的なのでしょうか。そして、日頃から論文にふれる機会の多い研究者の方はどのように論文から情報収集を読み解いているのでしょうか。
今回お話をうかがったのは、自然言語処理研究のフロントランナーとして、東京工業大学に所属し、自動要約の研究をされている西川仁助教。かな漢字変換をはじめ、トレンド分析や機械翻訳など多くのサービスに使われている自然言語処理。昨今ではスマートスピーカーも登場し、さらなる進化を遂げると予想される同技術の現在と未来を伺うと同時に、Webエンジニア向けの学術論文の読み解き方を教えていただきました。皆さんの“少し未来の”業務に使えるかもしれない、技術情報をどうぞ。
西川 仁(にしかわ・ひとし)さん:慶應義塾大学 政策・メディア研究科で修士過程を修了後、大手通信系企業に研究員として入社。その後、奈良先端科学技術大学院大学 情報科学研究科 博士後期を修了。2015年より東京工業大学 大学院情報理工学研究科 助教に就任した。
- 自然言語処理技術ってなに?
- 自然言語処理が進化した3つのターニングポイント
- 自然言語処理研究の課題はマシンスペックと大量データ取得
- 今後の進歩:スマートスピーカーによる自然言語処理のさらなる工夫と処理精度の向上
- 自然言語処理分野でオススメの論文
- 学術論文は量が大切。メリハリをつけて目を通そう
- まとめ
自然言語処理技術ってなに?
——まずは自然言語処理がどんな技術かをうかがっていきます。そもそもどういったプロセスでテキストを解析しているのですか?
西川 日本語や中国語、英語といった言語は、人間の歴史の中で自然に発生してきました。このような人間が日常的なコミュニケーションに使う言語を、「自然言語」と呼びます。対して、C言語やJavaといったプログラミング言語は「人工言語」です。「自然言語処理」は文字通り、前者の人間が普段使っている自然言語を処理する技術です。
次に自然言語処理の流れをお伝えしましょう。まずはテキストを単語、もしくはもう少し小さい単位(形態素)に分割する形態素解析という処理をします。有名なツールのMeCabもこのフェーズで使われます。次に文を構文解析し、係り受けなどの構文構造を明らかにします。構文解析のあと、誰が何をどうした、といった5W1Hを明らかにする意味解析を経て、文を越えた文と文の間の関係を明らかにする談話構造解析の処理をします。
談話構造解析では「そして」や「しかし」といった接続詞によって示されるテキストの論理的な構造を明らかにします。ここまでの各プロセスが自然言語処理の基礎技術ですが、それぞれの分野を専門とする研究者がおり、基礎技術といえど分野の幅は広いです。
一方、機械翻訳や評判分析(ある人が評価対象を肯定的に評価しているか、否定的に評価しているか、といった情報をテキストから分析する技術)、文章の自動要約や校正など、基礎技術を実用化したものは応用技術と呼ばれます。私の専門の自動要約は応用技術にあたります。
——応用技術はWebサービスはもちろん、多くのソフトウェアで使われていますよね。
西川 変換結果を予測して候補に挙げるかな漢字変換をはじめ、現代の日本で自然言語処理を全く使ったことがない、という人は珍しいんじゃないでしょうか。Webサービスでも、ページにキーワードへのリンクを付与したり、重要な単語を検出したりするのはみなさんご存じでしょう。
特に検索機能は自然言語処理技術の宝庫です。入力された検索クエリに対して、どういった情報が含まれていて、いかに検索者のニーズにマッチした形で返すかという技術ですから。クエリが商品名だと認識して、商品を売っているECサイトを検索結果に出すのは形態素解析や固有表現抽出の技術を使っています。
自然言語処理が進化した3つのターニングポイント
——自然言語処理が実用化して、ここまで普及するようになるきっかけになった技術がいくつかあるのだと思います。現在までどんな歴史をたどっていったのでしょうか?
西川 言語処理の歴史は古く、コンピュータが誕生したほぼ直後ぐらいから自然言語処理という発想は存在します。
はじめに自然言語処理の中心となったアプリケーションは機械翻訳です。「どのように機械翻訳をするか?」が非常に重要な自然言語処理のテーマでした。
機械翻訳の研究が始まった当初は、人間が単語ごとに規則を書いて機械翻訳をしていました。「英語のeatという動詞は、日本語では“食べる”と翻訳する」という規則を大量に書いて、この規則をもとに処理していました。 この段階から現在に至るまで、およそ10年間隔で3つのターニングポイントがありました。 最初のターニングポイントは、1990年代に機械学習の技術が自然言語処理に導入されたことです。すべての規則を人間が書くのではなく、機械が自動的に正解データから規則を学習できるようになったことで、より頑健な自然言語処理システムが実現できるようになりました。
次のターニングポイントは2000年ごろ、インターネットの普及です。これまで自然言語処理は、電子化された新聞記事などを相手にしていましたが、いかんせん現在から比べると小規模なものでした。インターネットの普及後は、ネットワーク上に大量のテキストが溢れるようになり、大規模なテキストデータを扱えるようになりました。
次に自然言語処理が大きく進化を遂げたのは深層学習、いわゆるディープラーニングが登場してからです。

自然言語処理研究の課題はマシンスペックと大量データ取得
——これらの技術で翻訳精度が高まったとはいえ、日本語の自然言語処理における課題はまだあるとうかがっています。
西川 日本語だと係り受け解析以上の深い処理の精度が不十分です。
日本語は主語や目的語の省略が頻繁に発生します。例えば以下の2つの文を読んでみてください。
- 【文1】大岡山商店街に新しいお店がオープンしたよ
- 【文2】カフェがオープンしたって
文2では「大岡山商店街にオープンした」という部分が省略されているわけですよね。こうした省略された主語や目的語を見つけるのは現在でも非常に難しいタスクです。
また、学習をするためのマシンやデータの問題もあります。自然言語処理の精度を高め、進化させていくには技術進歩とデータの確保の両者が欠かせません。
深層学習の研究には、高性能なGPUを持つ高価な計算機が必要です。東工大はTSUBAME{$annotation_1}があるので、その点では非常に恵まれているといえるでしょう。
「大学にいればたくさん計算機が使える」イメージを持たれる方もいるかもしれませんが、大学でも大規模な計算機を調達するのは簡単ではないのです。
——データ量を確保するという点で企業と大学が異なる点は何でしょうか?
西川 研究室でのアカデミックな研究と、実際のWebサービスだとだいぶ雰囲気が違ってきます。
実際のWebサービスですと、機械が文章を解析したあとにユーザーさんからフィードバックを得られます。例えば文章の自動分類で、異なるジャンルにカテゴライズされてアプリ上に表示されたときに「間違ってますよ」というユーザーフィードバックがあれば、おのずと正解データが集められます。
このようにアカデミックな研究課題としてデータを作るときとは異なる方法で、正解データを集められるのは企業の強みでしょう。
一方、大学では人手で正解データを作るコストが非常に高いので、学習用のデータを大量に用意するのは容易ではありません。十分なデータ量がないと機械がちゃんと学習できないため、データをしっかり整備するという課題が残っているとは思います。
——Webサービスを運営している企業のほうがデータが集めやすい、ということですね。
西川 データ量が多くなると、応用研究はぐっと進むと考えています。Amazonのようなプラットフォーマーにはデータ量では太刀打ちできません。ただ、基礎技術の研究に時間を割けるのは大学ならではだと思います。
一方で、データ収集においては、プライバシーや権利関係の問題も見逃せません。
人間が普段しゃべっているような対話やテキストが自由に手に入ると、自然言語処理の精度向上に大いに役立つでしょう。しかしユーザーの話している内容を収集するとなると、プライバシーの侵害に繋がります。以前、スマートスピーカーが勝手にユーザーの対話を収集していたという問題がありましたが、まさに典型的な事例でしょう。
匿名化してデータを使える方法にする、プライバシーに関わる情報をデータから除去した上で使う、という方法もあり、今後考えられていくトピックであると思います。
今後の進歩:スマートスピーカーによる自然言語処理のさらなる工夫と処理精度の向上
——これから自然言語処理はどのように進歩していくとお考えですか。
西川 自然言語処理の研究課題は既に個別に確立されており、それぞれの分野において着実に精度の向上がなされていくでしょう。例えば、誰がどこで何をしたというようなことを処理する述語項構造解析という課題があります。この課題に対して、研究者が地道にいろいろな手法を考えて精度の向上に取り組んでいます。
述語項構造解析(predicate argument structure)
述語(predicate)が記述する事態に欠かせない要素を項(argument)と呼び、述語と項の関係を述語項構造と呼ぶ。
述語項構造解析は、述語と項の関係を解析し、日本語においてはガ格(主語)とヲ格(直接目的語)とニ格(間接目的語)を項として特定する。例えば「太郎は花子に本を渡した」という文の述語は「渡した」という動詞、ガ格は「太郎」、ヲ格は「本」、ニ格は「花子」となる。日本語の場合、これらの項が頻繁に省略されるため、省略された項の補完が難しい課題となっている。
実用の分野ではAmazon EchoやGoogle Homeといったスマートスピーカー、Siriなどの音声対話エージェントのタスク処理で自然言語処理がより多くの人に使われるようになっています。今後も「人間が話した言葉を機械が理解し、何らかのタスクをこなしてもらう」ために、自然言語処理がさらに使われていくという大きな流れが確実にあると思います。
このように、自然言語処理が突然別の方向に行くということはなく、解析技術が今後もいろいろな新しい機械学習の技術を取り入れていき、さらなるデータの整備なども含め、処理精度の向上が続けられると考えています。
自然言語処理分野でオススメの論文
——研究室での基礎研究があるからこそ、企業で実運用ができるものですよね。自然言語処理分野で、エンジニアにオススメの論文を教えていただけますか?
西川 自然言語処理というより、現在の深層学習を使ったシステムの課題全般に関わる問題ではありますが、興味深いので紹介します。2016年の論文です。

Rationalizing Neural Predictions
この論文で提案されたモデルは、機械の判断の過程を示すことができると述べられています。ブラックボックス化している機械学習のシステムの中を見えるようにし、システムが判断した根拠が分かるようになる手法を提案しているのです。
人間が「A案とB案どっちがいいですか?」と問われたときは、根拠を示して説明することが重要ですよね。しかし現在のAIは判断の根拠を語るのが苦手です。
人間の目から「なぜこの結果が出てきたのか?」が見えなければ、重大な判断をさせづらいと思うのは自然な気持ちです。非常に重要なタスクにAIや自然言語処理を適用していくためには、機械の判断過程が外から見え、かつ解釈可能であることが必要になるはずです。
つまり、「なぜその判断に至ったか」が可視化されれば、人間がこれまで以上に重要な決定を機械に任せることができるようになると考えています。
まだまだ、人間にとって分かりやすく根拠を説明をするというような状況には達していませんが、判断の可視化される最初の一歩になるような論文だと感じます。
——なぜ判断の過程がブラックボックスになってしまったのでしょう?
西川 ブラックボックスになるのは深層学習のアーキテクチャに依存する部分が大きいと思います。深層学習のネットワークを構成する人工ニューロン単体では単純な判断しかできないものの、複数の人工ニューロンを大量に組み合せることで非常に複雑な判断をさせるのが深層学習です。
この判断の単位は、人間から見ると何をしているのかよく分かりません。なぜなら、人間が判断するときの判断基準と、機械が判断するときの判断基準が同じとは限らないからです。
機械が人間に寄せた考え方をしているのではなくて、機械が得意な考え方をしているというと分かりやすいでしょうか。コンピュータは2進数を扱うのが得意ですが、人間は10進数で考えたほうがわかりやすいというのに似ているかもしれません。
ブラックボックス化しはじめたのは、深層学習が発展した2010年代に入ってからです。それまでは、人間が書いた規則で処理するといった「見える」処理が多かったからです。
——どのような形で「可視化」をするのでしょうか。
西川 論文にある、ビールのレビューを例にしましょう。
ビールを飲んだ人が書いた、レビューの文章を機械が読み込みます。ここまでお話したとおり、深層学習のシステムは「香りの評価は星○つ」いう結果を出すのは簡単ですが、根拠を示すことができません。
この論文で提案されたシステムは、「文章のこの部分に『いい香りのビールです』と書いてあるから、このビールは香りは星4つだろうと判断しました」と、判断した根拠を示してくれます。
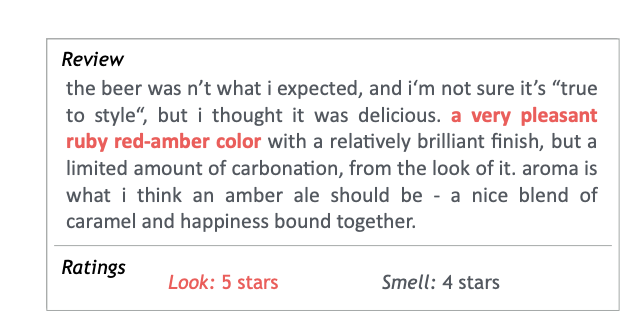
Lookは見た目、Smellは香りを示す。”レビューで「a very pleasant ruby red-amber-color」と色に関してポジティブな評価がされていることを根拠に、見た目が星5点と判断しました”と機械がアウトプットする
システムには「香りが星4つのテキスト」などを正解データとしてインプットさせます。学習器は大量のレビューから「この記述を使って判断すると当たりやすい/間違いやすい」ということを繰り返し学習し、試行錯誤する仕組みが入っています。
モデルで使われている個別のモジュールやアルゴリズム自体は目新しいものではないですが、組み合わせた結果は非常に斬新です。
——実用化されると、さまざまなものが変わってきそうですね。
西川 試験の採点、特に機械で小論文を自動で評価するという研究分野はすでにあります。学生が書いた小論文を入れて単純に○点、と評価するのではなくて、「この記述が良くないから減点」などと分かるようになれば、より信頼性が高いシステムということになりますよね。
学術論文は量が大切。メリハリをつけて目を通そう
——このように研究成果を論文から読み解き、応用研究ひいては実用化というプロセスをたどると思います。現場のいちWebエンジニアが論文を読むメリットはありますか?
西川 論文を探すのは「巨人の肩に乗る」ことだと思います。
私自身、以前は企業に勤めていて研究開発をしていました。仕事上でクリアしないといけない課題に直面したとき、自分一人で悩むのではなく、先に他の人が解決のヒントを持っていないか探るというのは有効なアプローチです。
論文に、解決策そのものが丸ごと見つかる、ということは多くありません。私自身、ある問題を解決するための材料AとBを論文から見つけてきて、足りない部分を自分の考えであるCで補い、AとBとCで解決した、という経験のほうが多いです。
「いい論文」を探すには、まず自分が直面している問題を具体的かつ明確なものにするということが重要だと思います。論文を探すうえでは、なぜ論文を探すのかという「Why」が重要です。探す理由が明確であれば、検索もしやすいでしょう。
自然言語処理では以下のサイトを活用してみてください。
ACL Anthology
自然言語処理の分野の論文がたくさん集まっています。紹介した論文もこのサイトから入手できますし、他にも自然言語処理の分野で出版されている有名な論文が入手できます。

言語処理学会
日本の自然言語処理の研究者たちが所属している学会が言語処理学会です。言語処理学会のWebサイトに、言語処理学会の年次大会で発表された論文が全部載っていますし、ジャーナルとして投稿されたものも読めます。

——学術論文を読み解くコツがありましたら、ぜひ教えてください。
西川 エンジニアのみなさんは「何かしらの課題を解決するための仕組み」を作るのが仕事になると思います。論文も同じように、課題・問題から始まります。
1本の論文の流れは以下のとおりです。
問題意識
どういう問題に取り組むか
過去の経緯
問題に対して過去にどういうようなアプローチ、ソリューション、解決策が提案されてきたかを紹介
方法の説明
経緯を踏まえて、より良いと思われる方法が提案される。ここで新しさがないと論文の存在価値がなくなってしまう
実験結果
実験をして、実際に改良されることが証明される。「成果が出なかった方法」を紹介する論文もある。他の人が同じ轍を踏まないための貴重な情報である
このように、論文はフォーマットが統一されています。まずフォーマットがあるということを意識して読むのが良いでしょう。
——重要な論文をひとつ読んだ後は、どのように深掘っていくのがよいでしょうか?
西川 論文は読んだ量が重要です。「1本読んで終わり」ではなく、参照元や関連する論文も目を通すとよいでしょう。
とはいえ、論文はたくさんあるので、全部の論文を細部まで読むことは困難です。そこで、濃淡をつけて読む、というのを意識してみてください。

——「濃淡」とはどのようなものでしょうか?
西川 論文の最初にある概要だけ読んで、自分と問題意識が合致しそうだとなれば、全体をざっと斜め読みする。さらに深掘りして少し細かく細部まで読む、自分で実装できるぐらいまで読む、と段階を踏んでいくのがよいでしょう。全ての論文を細部まで読むのではなく、論文に合わせて読む深さを変える、ということです。
識別的半マルコフモデルによるテキスト結束性を考慮した単一文書要約
西川 仁
論文抄録
本論文では,隠れ半マルコフモデルによる単一文書要約手法を提案する.我々は,単一文書要約を,長さに関する制約の下で,所与の目的関数を最大化する文の系列を,入力文書から得た文集合から探索する問題と見なす.提案する手法は文を選択する際に文間の結束性を考慮することができ,さらに文短縮を組み込むこともできる.~.
西川 仁,他『識別的半マルコフモデルによるテキスト結束性を考慮した単一文書要約』より
西川 このように、論文の冒頭には内容のサマリーである「概要(Abstract)」が記されています。まずはこの部分に目を通し、自身の課題との関連性を判断するのが効率的です。
論文を読むことに慣れていない方は、最初は日本語で4ページぐらいのものから始めると抵抗が少ないと思います。しかし、研究の世界は英語が公用語です。徐々に慣れていきましょう(笑)。カタカナ語として日本に入ってきている専門用語もあるので、意外と単語レベルで戸惑うことはないかもしれません。
まとめ
自然言語処理技術の現在と未来
- 登場時から現在まで一貫して、自然言語処理分野のメインテーマは「自然言語解析」と「機械翻訳」である
- ディープラーニングやスマートスピーカーの登場により、さらなる精度の向上と実社会への応用が期待されている
- 2018年現在の課題として、計算資源の整備、学習用のデータの整備、収集されたデータのプライバシーの問題などが挙げられる
論文の読み解き方
- 論文には「課題の提示・解決方法の説明・結果」というフォーマットがある
- 読み手にとっての「いい論文」を探すには、読み手自身が直面している課題の具体化が必要である
- 論文1本を単に丸ごと読むのではなく、自らの課題に合わせて読みの深度を調整する
取材:村山早央里(ZINE) 編集:薄井千春(ZINE)
*1:東京工業大学学術国際情報センターが2006年から運用するクラスタ型スーパーコンピュータ。2017年から運用しているTSUBAME 3.0は「ビッグデータスパコン」として、AI処理において国内トップクラスの計算性能を持つ




