
機械学習入門 - 基本のPythonライブラリ、9つを触って学ぶ
機械学習を学ぶために、まず知っておきたいPythonライブラリを、機械学習エンジニアの「ばんくし」こと河合俊典さんに厳選し、そのエッセンスをつづってもらいました。機械学習入門に向けたスタートアップガイドです!
こんにちは。機械学習エンジニアの「ばんくし」こと河合俊典(かわい・しゅんすけ/ 
近年の機械学習関連の開発では、多くの場合Pythonが用いられます。 本記事は、「機械学習をこれから初めてみたいけど何から始めればいいか分からない」「基本のキから学びたい」という方に向けて執筆しました。プログラミング言語「Python」の中でも、特に機械学習における使用頻度の高いライブラリを厳選し、その解説を目的としています。
「この記事の内容に沿ってPythonを学習すれば、機械学習エンジニアとして入門に必要な知識を備えられる」というレベルを目標に、機械学習モデリングを本格的に行う一歩手前まで、スムーズに学べるようかいつまんで進めます。
本記事では、Pythonの環境が既に整っている(コンソールにてpython hoge.pyでスクリプトを動かせる)状態を前提としています。PythonのインストールはPython.jpの環境構築ガイドがそれぞれOSごとにサポートしてくれていますので、そちらを参考にインストールを行った上で、本記事を読み進めていただければ幸いです。
選定基準
本記事で取り上げるPythonのライブラリは以下目次の通りです。
これらのライブラリは、数多くある機械学習ライブラリの中の一部です。本記事では、機械学習業務を進めていく上で、最も使用頻度が高く、基本となるライブラリを「数値」「テキスト」「画像」の3つの視点から厳選しました。幅広い範囲におけるデファクトスタンダードを学ぶことに重きを置いています。
読者の皆さんが、本稿を読んだ次のステップとして、Deep Learningライブラリや音声認識、強化学習など、さまざまな分野を学び始める礎の一部となるよう、身に付けておいて損のない利用方法に絞ってお伝えしていきます。
機械学習におけるデータの取扱
NumPy

NumPyとは、数値計算を行うためのライブラリの1つです。機械学習業務において最も利用する機会の多いライブラリで、現在NumPyを意識せずPythonで機械学習プログラミングを行うことは、非常に困難と言ってもよいでしょう。
Pythonのライブラリはpipと呼ばれるパッケージ管理ソフトによって、インストールを行います。 コンソールより以下のコマンドを実行し、NumPyをインストールします。
pip install numpy
次に以下のようなスクリプト(sample.py)を作成します。
import numpy as np x = np.array([1, 2, 3]) print(x.shape) print(x) print(x[0], x[1], x[2]) x[1]=0 print(x)
NumPyをnpという名称でimportし、1次元の配列を作成、配列の情報や中身の変更を行う簡単なスクリプトです。
コンソールでpython sample.pyと入力し実行します。 結果は以下のようになります。
(3,) [1 2 3] 1 2 3 [1 0 3]
配列のshapeを表示した後、中身の変更に成功していることが分かります。
NumPyの大きな機能の一つがこのnumpy.ndarrayです。 Pythonにおける配列といえば、組み込みのlistやset等のクラスによって実現することが可能ですが、ndarrayは行列計算に特化されたクラスです。 内部の実装にC、Fortranが使われていることに加え、線形演算はBLASやLAPACKによって実装されており、高速な行列演算を実現しています。
機械学習の多くのアルゴリズムは、行列演算によって、高速かつ効率的に実現されています。それゆえ、機械学習ライブラリをPythonで扱う場合、ndarrayを入出力として扱う場面が非常に多くなってきます。
最低限の知識としてndarrayを利用して、2次元以上の行列を取り扱う方法を学んでおきましょう。
以下のようなスクリプト(sample2.py)を作成します。
import numpy as np
x = [[1,2],
[3,4]]
y = [[5,6],
[7,8]]
x_array = np.array(x)
y_array = np.array(y)
print(x_array)
print(y_array)
print(np.dot(x, y))
こちらはPython組み込みのリストを2つ作成、ndarrayに変換し、内積(ドット積)するスクリプトです。
コンソールでpython sample2.pyと入力し実行します。結果は以下のようにx_array、y_arrayの中身に加え、それらを内積した結果が表示されます。
[[1 2] [3 4]] [[5 6] [7 8]] [[19 22] [43 50]]
機械学習業務において、多くの処理はライブラリ内で行われるため、このように内積を意識してスクリプトを作成する機会は非常に少なくなっています。しかし、前述の通りライブラリ内では多くの行列演算が行われているため、ライブラリへの入力としてNumPyを利用するのが一般的です。このことからPython組み込みのリストからndarray変換する処理は知っておくべきでしょう。
Pandas
Pandasは、数表および時系列データなどの「テーブルデータ」を取り扱うためのライブラリです。 機械学習業務においては、多くの数値やテキスト情報を扱う場面が頻繁に登場します。そうした場面において、Pandasは機械学習業界のデファクトスタンダードになりつつあるライブラリです。 一般的な表計算から、統計量の算出、データ整形、csv等のさまざまなフォーマットでの入出力といった、テーブルデータを扱う上での重要な機能が多く備わっています。
NumPyと同様にコンソールより以下のコマンドを実行しインストールします。
pip install pandas
Pandasを利用してテーブルデータを閲覧するスクリプト(sample3_1.py)を以下に示します。
import pandas as pd
x = [('Gauss', 1777),
('Pascal', 1623),
('Turing', 1912),
('Bernoulli', 1700),
('Fourier', 1768),
('Maxwell', 1831)]
df = pd.DataFrame(data=x, columns=['Name', 'BirthYear'])
print(df)
コンソールでpython sample3_1.pyと入力し実行します。出力は以下のようになります。
Name BirthYear 0 Gauss 1777 1 Pascal 1623 2 Turing 1912 3 Bernoulli 1700 4 Fourier 1768 5 Maxwell 1831
Pythonのリスト時点と違う点として、index idが振られていること、指定したcolumn名が振られていることが確認できると思います。この状態は、DataFrameと呼ばれるクラスに該当します。
このDataFrameを使ってさまざまな値を算出するスクリプトを前述のsample3_1.pyに追記してみます(sample3_2.py)。
print(df['BirthYear'].sum())
print(df['BirthYear'].mean())
print(df.query("BirthYear < 1800"))
上2行では、DataFrame内のBirthYear columnの合計値、平均値をprintしています。3行目では「BirthYearが1800より小さい行」という条件をqueryとして適応し、DataFrame全体から一部のDataFrameを抽出しています。
コンソールでpython sample3_2.pyと入力し実行します。こちらの結果は以下のようになります。
10611
1768.5
Name BirthYear
0 Gauss 1777
1 Pascal 1623
3 Bernoulli 1700
4 Fourier 1768
合計や平均以外にも、分散や標準偏差など機械学習において必須となる統計量を簡単に算出することが可能です。また、機械学習では度々行われる特定の条件のデータを間引く処理(サンプリング)等においても、SQLを書くように素早く記述できます。
他にもソート、欠損値の補完、グラフの描画等、テーブルデータを取り扱う上で必須のメソッドを多く備えています。
PandasはNumPyに比べると、他ライブラリの入出力で多く利用されている機会こそ少ないものの、入出力の前後における前処理、後処理の場面で利用されています。 機械学習業務等においても、Pandasで書かれた前処理のスクリプトを渡される機会は多々あります。1つでも多くの機能の使い方を、実際に触って知っておくことをお勧めします。
Matplotlib

Matplotlibは、グラフ描画のためのライブラリです。機械学習においては、統計量の可視化や学習経過のグラフ化、画像の出力等の機能が多く利用されています。
NumPyやPandasと同様に、コンソールより以下のコマンドを実行しインストールします。
pip install matplotlib
少し複雑になりますが、NumPyを利用してsin関数を生成し、グラフに描画、保存するスクリプト(sample4.py)を以下に示します。
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(0, 10, 0.1)
y = np.sin(x)
fig, ax = plt.subplots()
ax.plot(x, y)
plt.savefig('./output.jpg')
arangeは、一定の間隔で数値を刻むndarrayを生成します。 上記のスクリプトの場合は、0から10まで0.1刻みのndarrayを変数xに代入しています。さらに、変数xを入力とし、sin関数のy軸の値を生成し変数yに代入しています。
subplotは画像を制御するクラスと画像内のグラフを制御するクラスを返します。 画像1枚に対して複数のグラフを記載する場合があるため、それぞれ管理が分かれているという認識で大丈夫です。グラフaxに対して先程生成したndarrayをプロットし、jpg画像として保存しています。
コンソールでpython sample4.pyと入力し実行します。すると、実行した場所と同じ階層に、以下のようなoutput.jpgが生成されます。
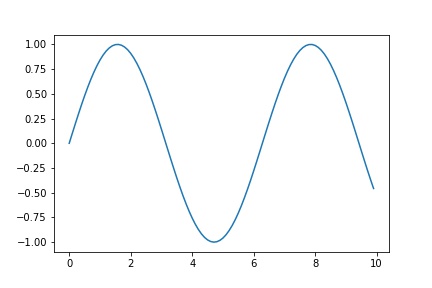
上記では、プロットの例を示しましたが、ヒストグラムや散布図を描いたり、JavaScriptを利用してインタラクティブなグラフを生成することも可能です。機械学習においても、NumPyやPandasと組み合わせて、分析対象のデータにどんな傾向があるのか可視化したり、スコアの変化を描画する等、さまざまな場面で利用されるため、覚えておいて損はないでしょう。
テーブルデータに対する機械学習
scikit-learn

scikit-learn(以下、sklearn)とは、多くの機械学習アルゴリズムを含む巨大なライブラリです。Pythonにおいて、最も一般的に知られている機械学習ライブラリでしょう。
機械学習業務においても登場機会は多く、一般的な機械学習モデルの多くがsklearnに実装されていることから、プロジェクトの最初から最後まで幅広く利用されるライブラリです。本記事では、簡単な機械学習モデルの実行を試します。
まず、機械学習に用いるためにデータセットを用意する必要があります。sklearnには、小規模ですがサンプルとなるデータセットが同梱されています。サンプルの1つであるdigitsと呼ばれる手書き数字画像のデータセットを呼び出すスクリプト(sample5_1.py)を以下に示します。
from sklearn import datasets
import matplotlib.pyplot as plt
digits = datasets.load_digits()
print(digits.keys())
print(digits.target[10])
plt.imshow(digits.images[10], cmap=plt.cm.gray_r, interpolation='nearest')
plt.savefig('./output_digit.jpg')
データセットをロードし、データセット内のキーを表示しています。また、10番目のラベル情報(target)と対応する画像を出力しています。
コンソールでpython sample5_1.pyと入力し実行すると、以下のような結果が出力されます。
dict_keys(['data', 'target', 'target_names', 'images', 'DESCR']) 0
データセットは手書き数字画像の数値情報(data)やラベル(target)を持っています。 targetの10番目を見ると、どうやら10番目には手書き数字0の画像情報が入っていることが分かります。先ほどのスクリプトで出力した、10番目の画像と照らし合わせて見てみます。
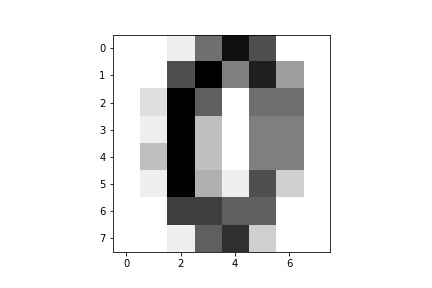
データセットの中は、それぞれリストになっており、対応する順番で並べられています。このようなセットから、機械学習を行うのはそれほど難しくはありません。
以下にdigitデータセットをSupport Vector Machine(以下、SVM)という機械学習モデルで学習するスクリプト(sample5_2.py)を示します。
from sklearn import datasets
from sklearn import svm
import matplotlib.pyplot as plt
digits = datasets.load_digits()
model = svm.SVC(gamma=0.001, C=100.)
model.fit(digits.data[3:], digits.target[3:])
print(model.predict(digits.data[:3]))
print(digits.target[:3])
plt.imshow(digits.images[2], cmap=plt.cm.gray_r, interpolation='nearest')
plt.savefig('./output_digit2.jpg')
svm.SVCではSVMクラスを初期化しています。gammaとCという引数を使っていますが、こちらはハイパーパラメータと呼ばれる値です。このハイパーパラメータのコントロールは、機械学習エンジニアのアルゴリズムに対する知識であったり、経験的な調整によって、より精度が高くなるよう設定されます。
今回は、gamma=0.001、C=100というパラメータを利用していますが、学習データやモデルによってパラメータはさまざまです。
model.fitにてSVMを学習させています。ここではdigits.data[3:]のように記述されていますが、これは3番目以降のデータを表しています。
このような表記方法をスライスと言います。一般的な機械学習では、「学習に使用したデータ」を「評価用データ」と混ぜて扱うことはタブーとされています。そのため、今回3番目より後ろのデータで学習しています。その後predictで評価用データとしている3番目以前のデータを評価しています。加えて2番目以前のラベル、及び2番目の画像についてもアウトプットしています。
コンソールでpython sample5_2.pyと入力し実行します。コンソールへの出力の結果は以下のようになります。
[0 1 2] [0 1 2]
digitの0番目、1番目、2番目の画像は、[0,1,2]と並んでいるようです。SVMの予測値もそれらを全て正しく予測しています。
また、試しにラベル2であり予測値も2となった2番目の画像を見てみます。
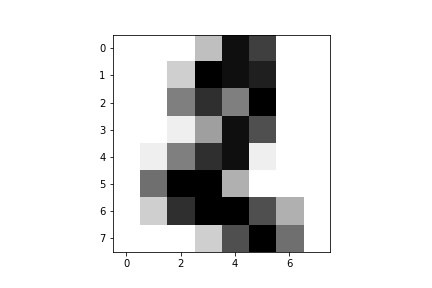
どうやら正解のようです。
上記は、digitがかなり簡単なデータで、かつ適切なハイパーパラメータを設定したため短い時間で正しい分類に成功しています。(こちらのパラメータはsklearnの公式チュートリアルより引用しています)
機械学習の難しさや奥深さを知りたい場合は、試しにgammaとCの値を自由に触ってみてください。digit程の小さなデータセットでも、正答できるモデルを作るためのハイパーパラメータはそう多くはありません。
余談ですが、gridsearch等、機械的に最良のハイパーパラメータを探索する方法もsklearnから利用する事が可能です。
sklearnには、このような機械学習アルゴリズムや学習用のメソッド、データ整形処理の手法が多く実装されています。sklearnの公式チュートリアルを進めることで、機械学習業務においても相当な範囲をカバーできる知識と技術が身に付きますので、ぜひ挑戦してみることをお薦めします。
また、今回はSVMを利用していますが、機械学習アルゴリズムの選択に迷った時は、公式のフローチャートが非常に参考になります。
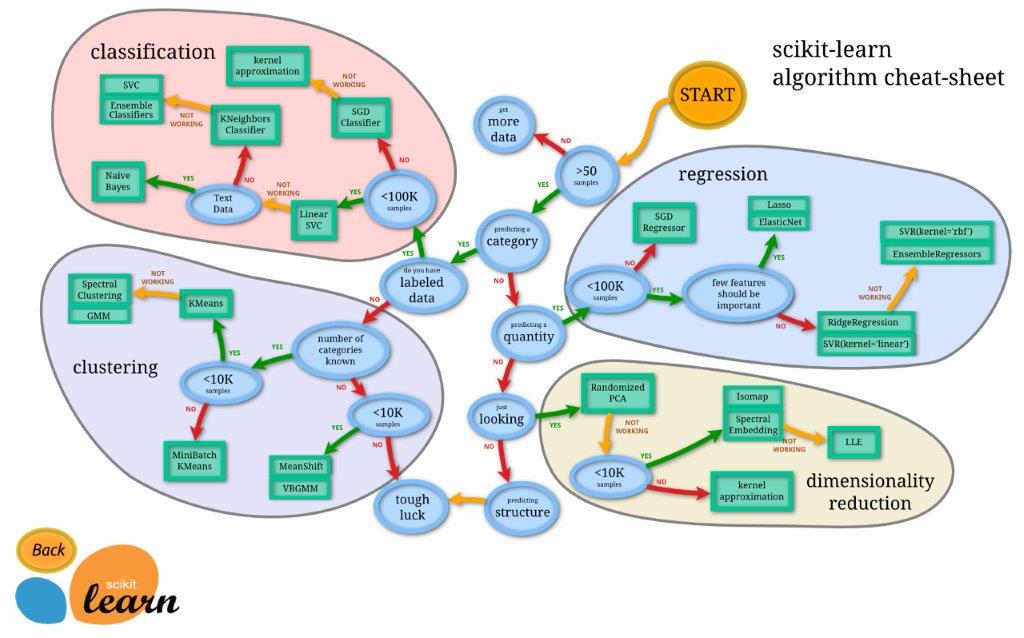
画像はscikit-learn.orgより。
全てのアルゴリズムを覚えるまでは時間がかかりますが、与えられるデータに対して、最良のモデルや整形処理、ハイパーパラメータを適切に選択できることは、機械学習業務において非常に重要です。少しずつ少しずつ身体に慣らしておきましょう。
テキストデータに対する機械学習
mecab-python

mecab-pythonとは、日本語向け形態素解析ライブラリMeCabのPython wrapperです。
英語の場合、単語と単語の間はスペースが挿入されており、単語を機械的に切り分けることは難しくありません。しかし、単語間にスペースが存在しない日本語において、単語ごとに文章を切り分ける作業は容易ではありません。この単語の切り分け作業を「わかち書き」、文章の構造解析の手法を「形態素解析」と呼びます。
わかち書きによって得られた単語を機械学習モデルにかけるというのは、テキストデータにおいてはメジャーな手法で、MeCabは古くから形態素解析ライブラリとして機械学習分野に大きく貢献しています。
wrapperであるmecab-pythonをインストールする前に、本体であるMeCabをインストールする必要があります。MeCabのインストールは、利用するOSによって変わってきますので、それぞれ以下に記載します。
仮にMacOSを利用している場合、brewと呼ばれるパッケージ管理ソフトウェアの導入が必要です。brewのインストールは以下brew公式ページにおける、インストールコマンドを実際に入力してください。

# Mac brew install mecab brew install mecab-ipadic pip install mecab-python3 # Linux sudo apt-get install libmecab-dev sudo apt-get install mecab mecab-ipadic-utf8 pip install mecab-python3 # Windows pip install mecab-python-windows
実際に日本語のテキストを単語単位にわかち書きするスクリプト(sample6.py)を以下に示します。
import MeCab
tagger = MeCab.Tagger("-O wakati")
text = '日本語のテキストを解析して分割します'
tagger.parse(text)
わかち書きを行う設定でMeCabを呼び出し、parseによって指定したテキストを分割しています。
コンソールでpython sample6.pyと入力し実行します。コンソールへの出力の結果は以下のようになります。
日本語 の テキスト を 解析 し て 分割 し ます \n
これら分割した単語は、前述したskleanライブラリのOneHotEncoderやTF-IDFにかけられ、テキストの分類や解析に用いられます。また、後述するGensimを利用して、分散表現として扱う手法も一般的です。
形態素解析ライブラリでは、その内部の単語辞書も重要です。単語が未知であれば、それらを分割することはできません。辞書においては、新語を多く収録しているipadic-neologd等が広く利用されています。
また、MeCabの他にもCaboChaやJUMANといったライブラリが広く知られています。さらに、2018年にはSudachiPyという複数の辞書を比較したりアドオンによって機能拡張が可能なライブラリも登場しています。日本語テキストを機械学習モデルの入力として使いたい場合、さまざまな選択肢があることを頭に入れておくと良いでしょう。
Gensim

Gensimとは、テキストデータ等に対して用いられる場合の多いtopic modelingに特化した機械学習ライブラリです。実装されている手法はsklearn程ではありませんが、近年テキストデータにおいて大きな成果を残している分散表現モデル(word2vecやfasttextなど)が利用でき、機械学習業務においても多く利用されます。
他ライブラリと同様に、以下のコマンドを実行しインストールします。
pip install gensim
分散表現のチュートリアルとして、Wikipediaを学習済みのword2vecモデルを読み込んで、実行するスクリプト(sample7.py)を示します。学習済みモデルは、東北大学 乾・岡崎研究室が公開しているモデルを利用します。
以下リンクより、「20170201.tar.bz2」をダウンロード、解凍します。entity_vectorというフォルダが作成されますので、スクリプトと同じ場所に設置してください。

from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format('./entity_vector/entity_vector.model.bin', binary=True)
results = model.most_similar('Twitter')
for result in results:
print(result)
Wikipediaのモデルを利用し、「Twitter」という単語と似た使われ方をしている単語をmost_similarによって出力するスクリプトです。
コンソールでpython sample7.pyと入力し実行します。 結果は以下のようになります。
('twitter', 0.9171890020370483)
('ツイッター', 0.9162642955780029)
('[twitter]', 0.8979461193084717)
('[Twitter]', 0.8913152813911438)
('[ツイッター]', 0.8797802329063416)
('ブログ', 0.8746308088302612)
('Facebook', 0.8576517105102539)
('フェイスブック', 0.8430535793304443)
('公式ブログ', 0.8427780866622925)
('[ブログ]', 0.820915162563324)
これらは、あくまで文章内での単語の位置情報を元に、似ている単語を出力しているにすぎません。most_similarの結果だけで単語の意味を判断することは一般的に行いませんが、それでも「Facebook」や「ブログ」といった、「Twitter」という単語と属性の近い単語が得られていることは分ります。
これらを利用して似た単語の辞書を作成したり、単語や文章を数値に変換したりすることができるのが分散表現モデルです。もちろん、Wikipedia以外の文章を収集し学習させることで、単語空間の拡張や修正を行うことも可能です。
Gensimは分散表現だけでなく、古くから文章の分類や内容推定に使われるモデルを含んでいます。テキストを処理する際は、一度Gensimの中の機械学習モデルに目を通しておくと良いでしょう。
画像データに対する機械学習
Pillow, scikit-image, OpenCV-Python



Pillow、scikit-image(以下、skimage)、OpenCV-Pythonは、Pythonで画像処理を行うためのライブラリです。それぞれpipを利用してインストールすることができます。
pip install pillow pip install scikit-image pip install opencv-python
画像処理という同一の目的であれば、どれか1つについて記載すれば事足りるのですが、機械学習の世界でもメジャーなライブラリとして1つを選ぶのが難しく、その上それぞれに違いがあるため記載しています。
データをndarrayで保持するかオリジナルのクラスで保持するか、RGBの配列の順番等が違っており、それぞれの変換も多く発生します。あるライブラリで保持していた画像を他の形式に変換する際、RGBの順番が変化して画像認識システム全体の精度が悪かった等という事案も少なくありません。
「画像の取り扱いだけであればPillowで管理しておくに越したことはない」と筆者は考えていますが、OpenCV-Pythonには高級な画像処理アルゴリズムや一部Deep Learningを利用した機械学習モデルも実装されており、シームレスに高度な処理に接続できます。
skimageもまた、OpenCV-Python程ではありませんが高級な画像処理アルゴリズムを備えており、「毎回自前で実装してしまう」ようなアルゴリズムはskimageの中に大抵の場合存在します。
ここでは、それぞれ複雑なスクリプトを示しませんが、それぞれ画像を保持する形式が違う事を確認するスクリプト(sample8.py)を以下に示します。
import cv2
from PIL import Image
from skimage import data
cv2_img = cv2.imread('./output_digit.jpg', cv2.IMREAD_GRAYSCALE)
pil_img = Image.open('./output_digit.jpg')
sk_img = data.imread('./output_digit.jpg')
print(type(cv2_img))
print(type(pil_img))
print(type(sk_img))
print(cv2_img.shape)
print(sk_img.shape)
それぞれのパッケージでsklearnの項で作成した画像を読み込み、そのtypeと大きさを表示しています。
コンソールでpython sample8.pyと入力し実行します。結果は以下のようになります。
<class 'numpy.ndarray'> <class 'PIL.JpegImagePlugin.JpegImageFile'> <class 'numpy.ndarray'> (246, 246) (246, 246, 3)
1つ目のOpenCV-Pythonと3つ目のskimageは、それぞれndarrayで画像を保持していることが分ります。対してPillowはオリジナルのクラスです。また、ndarrayで保持される2つの画像のshapeを見てみるとOpenCV-Pythonは1つ軸が少なくなっていることが分かります。
これは、読み込み時にcv2.IMREAD_GRAYSCALEを指定しているため、グレースケール画像として読み込んでいるのが理由です。skimageでグレースケール画像に変換するには、rgb2grayというメソッドを利用することで実現できますが、OpenCV-Pythonは読み込み時に変換の有無を指定できます。
このように、それぞれのライブラリで機能が異なるため、処理プロセスの後段にあたる機械学習ライブラリが推奨する画像処理ライブラリを選択する必要があります。また、画像における機械学習は、統一複合された機械学習ライブラリというものが少なく、目的や用途によって機械学習ライブラリも選択する必要があります。
画像分類や画像内からの物体検出、画像検索など、自身が行いたい目的からトップダウン方式で使用すべきライブラリは決定されると理解しておくと良いと思います。
おわりに
本記事では、機械学習分野において多く使われるライブラリを厳選し、サンプルを動かしながら解説しました。かなり駆け足でしたが、参考になったでしょうか。
筆者は、機械学習分野はまだまだ発展途上だと認識しています。本記事内では、文量の制約もあり近年急速に発展するTensorFlow、Keras、Chainer、PyTorchなどのDeep Learningライブラリについては紹介できていません。
しかし、今回ご紹介したテーブルデータ、テキストデータ、画像データ以外にも、音声から拡張現実など多くの分野で機械学習アルゴリズムの研究、社会実装が日夜進んでいるところです。機械学習アルゴリズムの多くは社会への適応範囲も広く、インターネットによってビッグデータが行き交う時代において、大きな貢献を担える技術でもあるとも思っています。
また、発展のスピードに比例するように、内部のアルゴリズムの数理的解釈だけでなく、ソフトウェア面から見る技術情報、ライブラリの使い方、概念の解説まで、入り口となり得る裾野も大きく広がっている分野です。本記事が、皆さんが機械学習への道を踏み出す一歩目の機会になれれば幸いです。
ご一読いただきありがとうございました。
河合俊典(かわい・しゅんすけ)


大学院まで、機械学習の理論研究を行った後、ベンチャー企業のR&D部門に勤務。現在はヤフー株式会社にて機械学習モデリングチームのリーダーとして日々開発に従事する。業務の傍ら、機械学習勉強会の主催や登壇を行い、機械学習関連技術の研鑽と発信に努める。
編集:中薗 昴




