
20年の機械学習・ニューラルネットワーク研究から見えた、人工知能の歴史と未来
人工知能はどのような技術によって進歩し、どのような未来に向かってかじをきっているのでしょうか。今回は20年近く人工知能の研究をしてきた人工知能分野のフロントランナーの方々にインタビューしました。
人工知能ブームを再燃させたディープラーニング。このブレイクをきっかけに、世の中にはさまざまな人工知能関連の情報があふれています。多くのディープラーニングフレームワークに採用されているPythonが盛り上がりを見せ、機械学習やディープラーニングの関連書籍がエンジニア界隈を賑わせました。
そもそも、人工知能はどのような技術によって進歩し、どのような未来に向かってかじをきっているのでしょうか。今回は20年近く人工知能の研究をしてきた方々にインタビューしました。筑波大学で人工知能研究室の室長を務め、同大で「人工知能特論」の講義も務める鈴木健嗣教授と、人工知能研究室で研究員を務めていたJayatilake Mudiyanselage Prabhath Dushyantha Jayatilake博士に、人工知能を発展させた技術や、Webエンジニアはいかに向き合うべきかを伺いました。
鈴木健嗣(すずき・けんじ)
Jayatilake Mudiyanselage Prabhath Dushyantha Jayatilake(ジャヤティラカ・ムディヤンセラーゲー・プラバーット・ドゥシヤンタ・ジャヤティラカ)
以下、ニックネームのDushyan(ドゥシャン)とする。
1975年生まれ。筑波大学システム情報系・教授、サイバニクス研究センター長、人工知能研究室長を務める。2018年4月、研究成果を社会に還元するために大学発のスタートアップ企業、PLIMES株式会社を立ち上げ、代表取締役CEOを兼務。博士(工学)。
Jayatilake Mudiyanselage Prabhath Dushyantha Jayatilake(ジャヤティラカ・ムディヤンセラーゲー・プラバーット・ドゥシヤンタ・ジャヤティラカ)
以下、ニックネームのDushyan(ドゥシャン)とする。
スリランカ・Peradeniya大卒(機械工学、流体力学)、筑波大学大学院修了。筑波大学研究員を経て、2018年4月にPLIMES株式会社を立ち上げる。現在同社の取締役CTO。博士(工学)。
- AIは「生物を模す」ものだった
- パーセプトロン:ニューラルネットワークモデルの礎
- 誤差逆伝播:成功までの距離に基づき学ぶ
- ディープラーニング:教師あり学習と教師なし学習の「いいとこどり」で認識精度が向上
- ディープラーニングの登場
- 最新の研究トピックス
- 今後人工知能はどう進化していくのか
AIは「生物を模す」ものだった
──お二人とも「機械学習やニューラルネットワークを研究されて20年」ということですが、今のような人工知能ブームは過去にもあったのでしょうか?
鈴木 人工知能はコンピュータの発展と歴史をともにしています。そもそも、コンピュータは「計算機の枠組みを超えて、ロジックをもって問題を解決してほしい」というニーズから生まれ、現在のように発展していきました。つまり、コンピュータが生まれたときから人工知能の歴史は始まっているといえます。
2018年の今も「世代を越えてはやっている」という点においては、人工知能ブームだと呼べるのかもしれません。
Dushyan 最近は、単純に解を出すだけではなくて、人間のコンディションに近くなってきているように感じます。人間と同じように画像が判断できて、人間と同じようなやり方で判断しているような。
──機械が人間と同じように判断する、とは?
鈴木 工学では、生物をヒントにしてうまくいったパターンとそうでないパターンがあります。「人工知能」という言葉もあくまで「人間の知能を参考にしよう」というところからスタートし、生物の認知や問題解決のプロセスをヒントに開発されてきました。
AIに限らず、工学では「生物を模す」アプローチがされています。例えば飛行機。「空を飛びたい」と考えたときにはじめに参考にしたのは大空を舞う鳥。鳥に倣ってレオナルド・ダ・ヴィンチも羽ばたき機(Flying Machine)を考え、羽を羽ばたかせた。でもその試みはうまくいかず、いま普及しているのはライト兄弟が選んだ「羽ばたかせないで飛ぶ」方法です。
AIという言葉が生まれたばかりの頃も、生き物をヒントに発達させようとしています。しかし当時はうまくいなかった。そうしたら「方向性を変えたほうがいいんじゃないか……?」と考える人々が増えて、発想が生物から離れていきました。今のコンピュータの形であるノイマン型コンピュータをはじめ、並列コンピュータやスーパーコンピュータは、人間の姿や性質とはほど遠いですよね。
- ノイマン型コンピュータ
-
- 記憶部に計算手続きのプログラムが内蔵されている
- メモリに命令(プログラム)とデータを格納
- 命令を解釈して、指定された動作を逐次実行する
このように、コンピュータは優れた計算機として発達していったけれど、再び「生物を模す」考えに立ち返ったのがニューラルネットワークです。
Dushyanは「人間のコンディションに近くなっている」と言っていたけれど、ディープニューラルネットワークはまさに「生物を模す」という考えに立ち返った結果、生まれた発想だったのだと思います。
人間を参考にすることが良いかどうかは分からない。ただ、人が参考にできるのって人しかないと思うので、そこに近付いているんじゃないかな。
パーセプトロン:ニューラルネットワークモデルの礎
――では人工知能の歴史の中で、キーとなった技術を伺っていきます。そもそも「人間を模した」知能、という考え方はいつから提唱されていたのですか?
Dushyan 過去をさかのぼれば、200年以上前から「人間の思考プロセスは機械で再現できる」と言われています。現代で言うAIの歴史は、1950年代に生まれたパーセプトロンから始まるでしょうね。
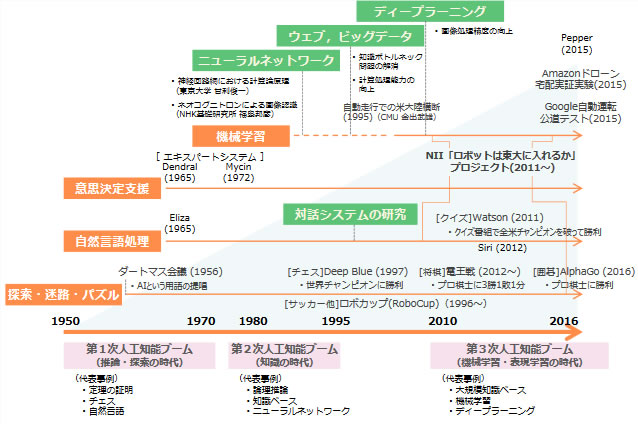
第1部 第2章 超スマート社会の実現に向けた我が国の取組(Society 5.0)の方向性:文部科学省より
- パーセプトロンモデル
-
- 人間の脳にあるニューロンという神経細胞を参考に作られたモデル
- ニューロンは閾値(しきいち)を超えると活性化する。ニューロン自身はあまり学習をせず、かわりにニューロンとニューロンをつなぐ線(コネクトビリティ)が学習をする。太い線は情報が通りやすく、細い線は通りにくい
識別面をどう作るか?
鈴木 先にパーセプトロンが生まれたきっかけになった「認識」の話をしましょうか。認識する人が「対象がどんなものか?」を知らないことには判断ができません。
たとえば講義で学生に「ガムランって楽器を知っている?」って質問をしたとしましょう。そうしたら誰も手を挙げなかった。だからといって、学生たちが「ガムランが嫌い」だとはいえない。そもそも自分が知らない物に対して好き・嫌いの判断はできないので、困ってしまうはずです。
認識を英語でいうと”recognize”、これは、re-cognize、既に知っているものを認識する(cognize)という意味です。つまり、対象について教える元データ(学習データ)が必要になります。これは人間だけでなく、機械での認識も同じです。
――機械も、自分自身が知らないものはうまく認識できないということですね。
鈴木 もう一歩踏み込むと、認識はすべて分類という問題に帰着します。有名になったイヌネコ問題も「ネコとイヌの間に存在する、見えない識別面を見つける」、もっと言うとネコとイヌを区別させる境界線を与えることで、はじめて認識ができるようになるのです。
しかしこの境界線も、簡単な問題ならすぐに与えられますが、ちょっと複雑になってくると難しい。そこで「学習によって、機械みずからが識別面を得てくれたらいいのでは?」という考えが生まれてきます。この思想に基づいて生まれたのがニューラルネットワーク、そしてパーセプトロンです。
ヘッブの法則~入力情報が多いほど情報を伝える幹が強くなる
鈴木 ニューロンは入力された情報量が、閾値をこえると「発火」して活性化します。しかしニューロンそのものは多少の変化はあれどもあまり学習をせず、実際に学習をしているのはニューロン同士をつなぐ線です。
この、ニューロン同士をつなぐ線が太いほど情報が通りやすく、逆に細い線だと情報が通りにくい。ニューロンが繰り返し発火することで、線が増強され、伝わる情報量も増えていく「ヘッブの法則」1と呼ばれています。
今あるニューラルネットワークも、基本的にはこのアイデアを踏襲しています。
誤差逆伝播:成功までの距離に基づき学ぶ
鈴木 パーセプトロンが生まれてからも、数多くのニューラルネットワークのモデルが発案されてきました。パーセプトロンはいうなれば「分類器」で、決められたルールのとおり分類しているだけです。
その発展系として生まれたのが、試行を通じ、失敗(もしくは成功)から学ばせるアルゴリズムの誤差逆伝播(ごさぎゃくでんぱ)。これは何かしらの形で成功事例と実際の解との距離を表現し、「成功からの距離に基づき学ぶ」モデルです。
- 誤差逆伝播(誤差逆伝播法/Back propagation)
-
- 正解データとの誤差の傾斜を計測するアルゴリズム
- 連鎖律と最急降下法(勾配法)が根幹をなす
――成功が1で失敗が0、というようなデジタルな考え方もありますが、「失敗は成功のもと」というように失敗、もしくは成功をきちんと言語化するということなんですね。
鈴木 トランプの神経衰弱を例に考えてみます。
ゲームが始まってから1回目のターンで、裏返しになっている多くのカードから同じ柄のカードを2枚引き当てる確率は高くありません。しかし次に自分のターンが来たら、同じことはしないはず。1ターン目と違って「この2枚はそれぞれ違う柄のカード」という情報があり、この情報こそが同じカードを引き当てる確率を上げているのです。つまり、1ターン目では成功までの距離をつかむ情報を手に入れているといえます。
しかしターンが終わるたびにカードをシャッフルしていたら、プレイヤーの情報は増えません。ターンを重ねても、同じ柄のカードを引き当てる確率は変わらないでしょう。なぜなら失敗(情報)から学べないからです。
この「失敗から学ぶ」ことを可能にしたのが誤差逆伝播です。
Dushyan パーセプトロンは画期的だったけど、「現実的な問題解決には適さない」と下火になった頃は、「ニューラルネットワークは終わりだ」と考える人も多かった。誤差逆伝播によって分類の精度が高まってからは、再びニューラルネットワークが盛り上がりました。
――今後のAI技術の発展につながるという意味でも、画期的なアルゴリズムだったのですね。
鈴木 誤差逆伝播法が登場した頃は、声まねに使った人がいて大フィーバーしたんです。まるで子どもの喃語(なんご)にように喋ったんですよ。ニュースの音声を聞かせたらウニャニャ……と言い始める。
しかし、現実の問題に対していかに活用できるか? は見いだされず、識別器としての実用には至りませんでした。

ディープラーニング:教師あり学習と教師なし学習の「いいとこどり」で認識精度が向上
鈴木 静止画と違い、音や動画といった連続性のあるコンテンツでは時系列が必ず登場します。この時系列情報を解くために考えられたのが、リカレント型ネットワークです。
しかしリカレントネットワークにも課題がありました。データ量の不足と、アルゴリズムの弱点です。
リカレントネットワークの課題
鈴木 ニューラルネットワークは「教師あり学習」と「教師なし学習」の大きく2つに分かれることができます。パーセプトロンモデルと誤差逆伝播法は、いずれも問題とその解の組み合わせ(以下、教師データ)を与えられているので「教師あり学習」です。そのため、機械に学習をさせ、精度を高めるには大量の教師データが必要だったのです。
当時は「顔写真から画像認識をする」という研究のために、空港にカメラを置いて600人分の画像を集めた研究者もいたと聞いています。しかしこうしたコストや時間をかけられる研究者はごく一部でした。
では、解が与えられない「教師なし学習」では分類ができないのか? というと、そんなことはありません。複数の解が似ている・似ていないといった相互の関係性から、似ているもの同士をクラスタリングすることが可能です。教師データやはっきりした区分・境界線を持たずにカテゴライズするという点は、むしろ私たち人間の分類方法に近いといえるでしょう。
ただ、カテゴライズの基準を学べる教師あり学習に比べて、分類の精度は落ちてしまいます。教師あり学習・教師なし学習いずれか単体で解くには、難しい問題も多くありました。
ディープラーニングの登場
鈴木 そこで「教師あり学習」と「教師なし学習」を合わせる試みが始まりました。インターネットの登場と発展によって大量の画像データが手に入れられるようになり、日の目をみたのがディープラーニングです。ディープラーニングのアイデア自体は90年代からありました。
ディープラーニングは、まずは教師なし学習で学習して、対象を見分けるパターンを見いだします。作ったパターンをもとに対象を教師あり学習にあてはめ、対象がA・Bどちらのパターンになるのか解を返してもらい、チューニングしていきます。
これまでの識別器との大きな違いはランダムなデータから機械が特徴量を見いだす能力と、見いだされた特徴量に基づき人間が判別する能力とを両方生かしていること。通常の教師あり学習では、人間がラベル付けしたあとに教師データを入力します。しかしこの方法では、データを人間が判別しているので、「人間が判別できる区分」しか分類できません。人間の目に見えるもの以外にも、画像には多くの情報が含まれています。
そのためディープラーニングでは機械なりに「カテゴライズの基準」を増やした上で、人間の認識とすりあわせて対象を分類することができます。
この方法で大きく成果を挙げたのが、Cats or and Dogs、イヌネコ問題でした。
Dushyan ディープラーニングを使った画像分析は、他の方法に比べ分析精度が70%も上がっています。
Using this large-scale neural network, we also significantly improved the state of the art on a standard image classification test―in fact, we saw a 70 percent relative improvement in accuracy. We achieved that by taking advantage of the vast amounts of unlabeled data available on the web, and using it to augment a much more limited set of labeled data. This is something we’re really focused on―how to develop machine learning systems that scale well, so that we can take advantage of vast sets of unlabeled training data.
引用:Official Blog Insights from Googlers into our products, technology, and the Google culture
※イヌネコ問題についてはこちらの記事でも触れています
ディープラーニングは特徴量を抽出するという問題を1つ解決した、という点では大きな成果を挙げているでしょう。おおむね認識・分類に対する問題は解決したでしょうが、人工知能としては難しい問題をひとつ解決しただけにしかすぎない、とも思います。

オートエンコーダ:ディープラーニングを可能にした圧縮技術
Dushyan ディープラーニングには、1.機械が自ら特徴量を見いだす、2.人間の判別基準を元に対象を識別する、の2つのフェーズがありますが、このうち前者を可能にしたのが、オートエンコーダというアルゴリズムです。
- オートエンコーダ(autoencoder)
-
- ニューラルネットワークの一種
- 入力したデータと出力データを一致させるようトレーニングするアルゴリズム
- 特徴量を圧縮して隠れ層に情報を伝える
この圧縮技術によって大量のデータを使ってトレーニングできるようになり、ディープラーニングが発展していきました。
──ディープラーニングはどこへ進むのですか?
鈴木 僕は、ディープラーニング(教師なし学習と教師あり学習の組み合わせによる解決モデル)は、エンコーディングとデコーディングに帰着すると思います。
エンコードは世の中を量子化するという意味です。量子化した後もう一回世の中に答えとして返すのがデコードです。従来、世の中はエンコードもデコードもいい加減にしてきました。しかし適当なエンコードで頑張って学習しても駄目なんです。
情報学は何が重要か重要でないか、という価値観を無視して量を捉えることで進んできました。例えば情報が起きる頻度を情報量として分析します。頻度の多寡で情報量の高低を決めても、価値とはほぼ関係ありませんよね。
僕から見ると、人工知能のロジックは「人が情報に対して価値を与えるメカニズム」を学習によって計算機にやらせようとしているように見えます。計算機のメカニズムには価値・思想・理想というものはありません。あるように見えたら、その価値を与えた誰かがいます。
機械学習が人種差別をする、というニュースがありました。マイノリティの表情が分かりづらくて、白人のほうが分かりやすい。よって人種差別だと。
しかし機械自らが「差別しよう」という意志を持つことはありません。差別をするとしたら、元の学習データに原因があります。学習データセットを操作すれば機械学習はそのように学習します。機械学習というのは、与えられた情報の中から解を見つけるものにすぎないからです。
最新の研究トピックス
位置関係を記録する「カプセルネットワーク」
――ここまで人工知能の歴史とキーになった技術について触れていただいたのですが、直近ではどのような研究が進んでいるのでしょうか。
鈴木 2017年11月にGoogleの研究者ジェフリー・ヒントンが発表したカプセルネットワークが話題になりました。
今主流になっているニューラルネットワークは、人のニューロンをモデルにして各種情報(信号)を送っています。ニューロンそのものは信号が入って、出力するだけの単純なモデルですが、カプセルネットワークはニューラルネットワークに空間情報を加え、画像を構成するパーツの位置関係に注目しています。
例えば表情が変われば目、鼻、口といった顔のパーツは動きますが、位置関係そのものは変わりません。パーツごとの特徴に加えて個々のパーツをベクトル化すると、位置関係のパターンが覚えられます。ニューロンに対してSOM(Self-organizing maps,自己組織化マップ)を持っている、という言い方もできます。
人間のニューロンとは違う進化をしているのは面白いですが、ブレイクスルーにはなり得ないのでは、というのが今の僕の考えです。
教師データが少なくても、期待する回答を導けるのか?
――他にはどのような研究が進んでいるのでしょう。
鈴木 学習用のデータを工夫できないか、と考えているのが理化学研究所の革新知能統合研究センター 、杉山将先生のグループです。
さきほど、インターネットが出現するまで大量の画像データを集めるのは難しかった、という話をしましたが、ましてや現実の問題では教師データを大量に集めることは非常に難しい。
例えば「ツールの使い方を覚える」といっても、使い方を1から10まで全部聞いて初めて理解できる人と、2と8だけを聞いて飲み込める人がいます。後者なら必要なデータも少なく、実用性が高いといえますね。
不完全情報学習チームでは、学習のデータやパターンを変えることで、より少ないパターンから本当の解を探し出せないか、という研究に取り組まれています。
――鈴木教授は、どのような研究グループに属されているのですか?
鈴木 ざっくりとしていますが、人工知能を使って現実の問題を解く、というグループです。母集団としては先の2つの例よりこちらの方が多いのではないでしょうか。人工知能そのものの基礎研究に目が行きがちですが、もっと多くの人がこちらのグループにいてもいいのでは、と僕は思います。
今後人工知能はどう進化していくのか
AIは因果を無視する存在
──ヒトの脳組織をもとにしたニューロンが、人間とは違った進化を遂げた、というのは興味深かったです。今後、AIは人間ができないことを成し遂げるようになるのですか?
鈴木 現状のAI、ディープラーニングは識別機です。パターン化できる確率が高い問題はAIの得意分野ともいえます。しかし、識別機は識別すること自体が大事なのであって、識別する先の意図や何があるのかを気にしていません。
だから答えのない問題をAIに任せるのは論外です。実際に、電卓の時代から答えのない問題を機械に託すようなことはしていないでしょう。みんな電卓の能力を正しく理解しているからです。でも、世の中はAIの能力を正しく理解していないのか、AIがなんでも解決してくれるように言いますね。しかし、AIは答えのない問題は解けないのです。
例えば自然数XとYからなる連立方程式[X+Y=5]の解は、X=1から5です。しかし、『ミカンが1つあります、リンゴはいくつですか』という問題は解けるでしょうか。特定の値が導けないので「分からない」というのが正しい答えです。
0は答えではありません。0だと解の存在が証明できていない。0というのは0であることを100%正しいと思って言った場合を除けば0ではない。解の存在証明ができれば人工知能は解けますけども、その解が最適であるとは限らない。
分からないとは解が不定という意味。解が不定では、あらゆる他の状況を知らない限り答えが出ないんですよね。人工知能は知っていることだけしか答えない。これは人間が知らないことを「知らない」というのとは異なります。「分からない」という答えは本当に深遠なのです。

鈴木 同様に、AlphaGoが囲碁の世界チャンピオンを下したからといって、「AIが勝って、ヒト以上の知能を持った」とはいえない。AIが理解しているのはこの程度のことなのです。
AlphaGoの理解していること
- 人間界で”囲碁”と呼ばれるものを、人間に知られている言語を使って「やり始めよ」と言われたので始めます
- AIはそもそも自ら囲碁をしない
- 盤上では自分の石で囲んだ領域の方が、相手のそれよりも広いのでどうやら「勝ち」というらしい
- 勝った・負けたがそもそもどういう概念なのかを理解していない
確実なのは「AlphaGoを開発したチームがソフトを使って、囲碁の世界チャンピオンに勝った」ということだけ。囲碁の素人がAIの力を借りればチャンピオンに勝てる時代になったとはいえますが、AIには囲碁がなにかを理解できず、かつ囲碁をしようという意志もない。そのため「AIが囲碁で勝った」とはいえないでしょう。
――というと、今後は人工知能も人間のように意志を持つことはないのでしょうか。
鈴木 人工知能の話をするときに、よく僕が題材に出すのは電卓。電卓の計算能力はすでに人間を超えていますが、人間の脅威にはなっていない。単に生活が少し便利になるだけです。Google検索も、よりスムーズに情報を探すためのツールにしかすぎません。
そもそも、電卓は意思を持つでしょうか? 今の単語をAIに置き換えると、AIは意思を持つでしょうか?
Dushyan それは知能(characteristic of intelligence)と言えるんでしょうか。
鈴木 答えを出す機械はインテリジェンスです。一方、はっきりした答えがないものに答える力を知性(ability of intelligence)と言います。
知性とは、自分が知ってるか知らないかではありません。本やWeb、どこかに答えがある問題は絶対に解けます。
知性は、答えのない問題に対して問い続ける力です。倫理学の思考実験でよく使われる「ある人を助けるために他の人を犠牲にするのは許されるか?」という問いには解はありません。そんな道徳的ジレンマに答えも解もない。そういった問題に対して、われわれ人間は答えを出していません。
思考実験の例
- 両手に自分の子どもが1人ずつ、どちらかの手を離さなければいけない。どちらの子を選ぶべきか
- 1人を犠牲にして5人を救うことは正義か(トロッコ問題)
AI技術を通じて人を助けたい
――今後は人間の知覚に近づくよう、人工知能とセンサーが発達していくと伺っています。センサーが発達していくことで、できることの幅も広がっていくのでしょうか?
鈴木 センサーを小型化するなど、応用工学でできることはどんどん増えていきます。
Dushyan 私たちがこの春、研究成果を社会に還元するため創業したPLIMES株式会社では、「GOKURI」というメディカルデバイスを作っています。これは、首に巻く小さな音センサーを使っていますが、ここにもディープラーニングを使っています。
参照:http://www.ai.iit.tsukuba.ac.jp/gokuri/
日本人の死因の第3位が肺炎。実に11人に1人の方が肺炎で亡くなっている状況ですが、なかでも無視できないのが誤嚥(ごえん)性肺炎です。本来なら食べ物は口から食道に運ばれますが、正しく食べ物の飲み込みができず、気管支に入り細菌が炎症を起こしてしまいます。
そこでGOKURIを装着することで、高齢者が正しい嚥下(えんげ)ができているかを検出しやすくします。この嚥下を認識するのに、ディープラーニングを利用しています。嚥下の能力を測る「嚥下計」を実現することで、誤嚥を予防できると考えています。
――なぜ嚥下や、ヘルスケアの分野を選ばれたのですか?
鈴木 僕が人工知能を研究する理由は「人を助けたいから」です。学問を志したとき、問題を解くときには必ず本質的な理解が必要になると叩きこまれました。どういうふうに助けるかではなく、人そのものの理解を進めないと人を助けることは難しい。だからこそ、人を理解するために人工知能の研究をはじめました。
僕にとっての人工知能研究は「知能がどういう働きをしているのか、知能をどこまで機械で代替・支援・拡張できるか」を明らかにすることです。
昔から人は知・情・意(知識・情動・意思)によって動いていると言われます。僕の研究室では、人間のどこまでが知で支えられて、情動と人の意思がどう関わっているのかを理解する研究を行なっています。機械を高性能的につくることも、人を測定することも検証の一部なのです。
一般にあまり理解してもらえないのですが、人工知能研究と人工知能技術は違うものです。ディープラーニングは人工知能技術ですが、人工知能の研究そのものではないと思っています。人工知能研究というのは、知能とは何かという答えのない問題に対して問い続ける知性のある人々がやることだと思っているんです。
GOKURIが「人工知能技術」の結晶だと評価してもらえるのなら、ディープラーニングの技術ではなくて、われわれサイエンティストが人を理解しようとしてきた営みの上に成り立っている「人工知能」に焦点を当ててほしいです。
エンジニアが追い求めるべきは「実社会がもっとよくなる解決法」
――最後に伺いたいのが、こうしたAI技術にエンジニアはどう関わっていくべきか、ということです。いずれプログラミングもAIによってなされ「職を失う」という噂もありますが、どうすれば価値を出し続けられるのでしょうか?
鈴木 エンジニア(engineer)の語源に立ち返ってみると、「アイデアを出す人たち」です。エンジニアのジニアはジーニアス(genius)のジニアであって、エンジネというのはラテン語ではものをつくる人でもあるんですけど、大意はアイデアを出す人をさします。
アイデアを出すためにはものの本質を理解することが必要です。
エンジニアがAIを使うために「自分が今使おうとしているAIは果たして何か」を知識ベースで理解し、あわせてAIそのものへの正しい理解が必要です。AIの特性や本質を知った上で、できることやできないことは何かを考えてみてください。
とはいえAIを作る専門家ではないので、AIへの理解は基礎程度で良い。研究者も自然現象の定理や真理を探る基礎研究が1割で、残りの9割が、基礎研究をさらに深化させながら現実の問題を解決していく応用研究。エンジニアの皆さんにも、実社会でAIをどう生かすと幸せになれるか、を考えてほしいのです。
Dushyan 今はUdacityなどの良質な学習コンテンツがたくさんありますし、ディープラーニングのフレームワークも充実しています。自分でライブラリを作る、というところまではいかなくても、まずは触ってみた方がいいと思います。
「Webエンジニアだから」といって、AI技術に全く触れないでいるのはもったいないです。
鈴木 自分たちが解きたい問題を明確にできればできるほど、求めている解に近づく。問題を解くときに重要なのは、問題の解き方ではなくて、その問題が何かを理解することが重要になります。問題がしっかり理解できていれば、その解の見つけ方はおのずと分かるものです。
取材・執筆:薄井千春(ZINE)/写真:渡辺健一郎
心理学者ドナルド・ヘッブにより提案されたこの理論は、「Neurons that fire together, wire together」と表現されている↩




