
Pythonを使ってみよう~Webスクレイピングに挑戦し初歩を学ぶ~
話題のPythonを使って学んでみましょう! 今回はWebスクレイピングにトライし、その初歩を学びます。
Pythonの最初のバージョン(0.9)は、1991年に登場しました。C#の登場が2000年なので、Pythonの歴史は意外に古い印象です。本稿を執筆している2018年3月時点でのPythonのバージョンは3で、バージョン2とは、かなり仕様が異なります。本稿では、Python3を使用します。
さて、Pythonの特長は、簡潔な言語仕様と、学習のしやすさです。筆者は、これまでC++など、多くのコンピュータ言語を使用してきました。C++などに比べて、Pythonは同じことをするにも、少ないコード量で済み、また学習する時間も節約できます。何らかのコンピュータ言語をすでに使える人であれば、1日勉強すれば、ある程度、Pythonでプログラミングできるのでは、と感じています。今回の記事を制作するに当たって、編集の方からPython学習のコツについて聞かれましたが、とくに思い浮かばなかったほどです。
- なぜ、PythonでWebスクレイピングするのか
- Pythonのインストール
- Pythonの基本的なプログラム
- Webスクレイピングその1:Webページのソースの取得
- Webスクレイピングその2:Webページの解析とCSV出力
- まとめ
- 執筆者プロフィール
- 参考資料
なぜ、PythonでWebスクレイピングするのか
Pythonには、Webスクレイピングをするのに便利なライブラリが、多くあります。また、言語仕様が簡潔なので、短いコード量で、目的とするWebスクレイピングのプログラムを作成できます。本稿では、実際に簡単なWebスクレイピングのプログラムを作成し、Pythonの便利さを紹介したいと思います。
さて、Webスクレイピングとは、コンピュータのプログラムでWebサイトにアクセスして、必要な情報を選別して取得することです。Webサイトから、何らかの目的に適した情報だけ取り出して、表にまとめておくようなことも可能です。
ただし、Webサイトは、ユーザーがブラウザを使って手動でアクセスすることを前提に作られています。そのため、Webスクレイピングを行う場合、次の点に注意しルールを遵守する必要があります。
■注意事項
1. 各Webサイトには、多くの場合利用規約が掲載されています。利用規約でWebスクレイピングが禁止されている場合、行わないでください。また、APIがある場合は、APIを利用するべきです。
2. Webサイトのルート直下に、robots.txtというファイルがある場合、その記述内容に従う必要があります。robots.txtには、検索エンジンなどが機械的にWebサイトにアクセスする際の制限事項が記載されています。robots.txt内の、Disallow項目には、機械的にアクセスしてほしくないパスが記載されています。例えば、エンジニアHubのrobots.txtは、次のようになっています。
4. 原則的に、取得したデータは、Webサイトの所有会社(または所有者)の著作物です。Webスクレイピングで取得したデータは、著作権法に違反しない範囲内で利用しなくてはなりません。
Pythonのインストール
Python3のインストーラは、次のWebサイトから入手可能です。
このページにアクセスし、下の方にスクロールすると、Downloadsの項目があります。この中から、自環境のOSを選択して、ダウンロードします。筆者の環境である、64bitのWindows環境を例に手順をご説明します。
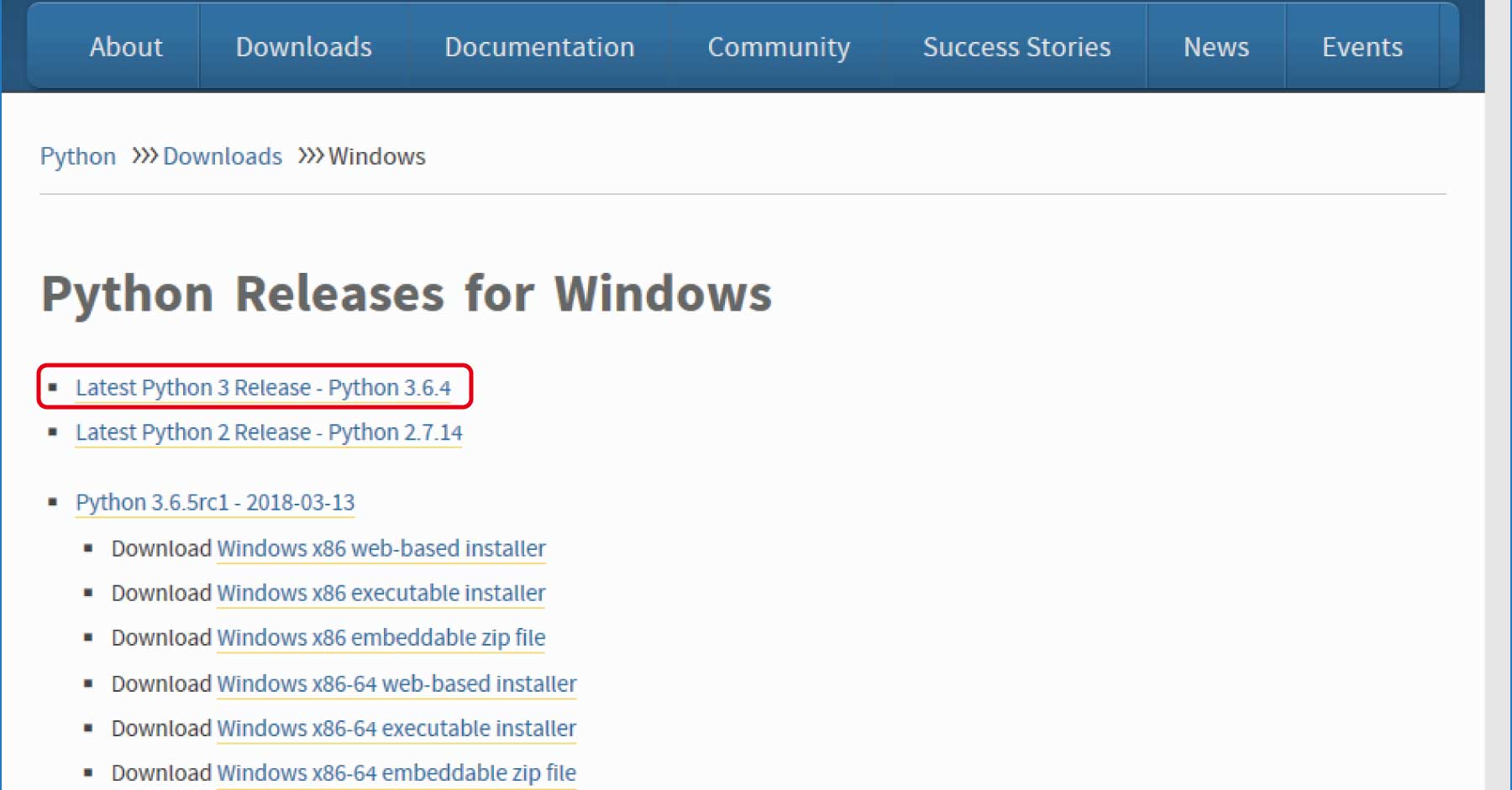
(1)Downloads項目内のWindowsをクリックします。

(2) Python Releases for Windows」のページで、「Latest Python 3 Release - Python 3.6.4」をクリックします (2018年3月の執筆時点での最新版は3.6.4です。最新のPython3を選択してください)。
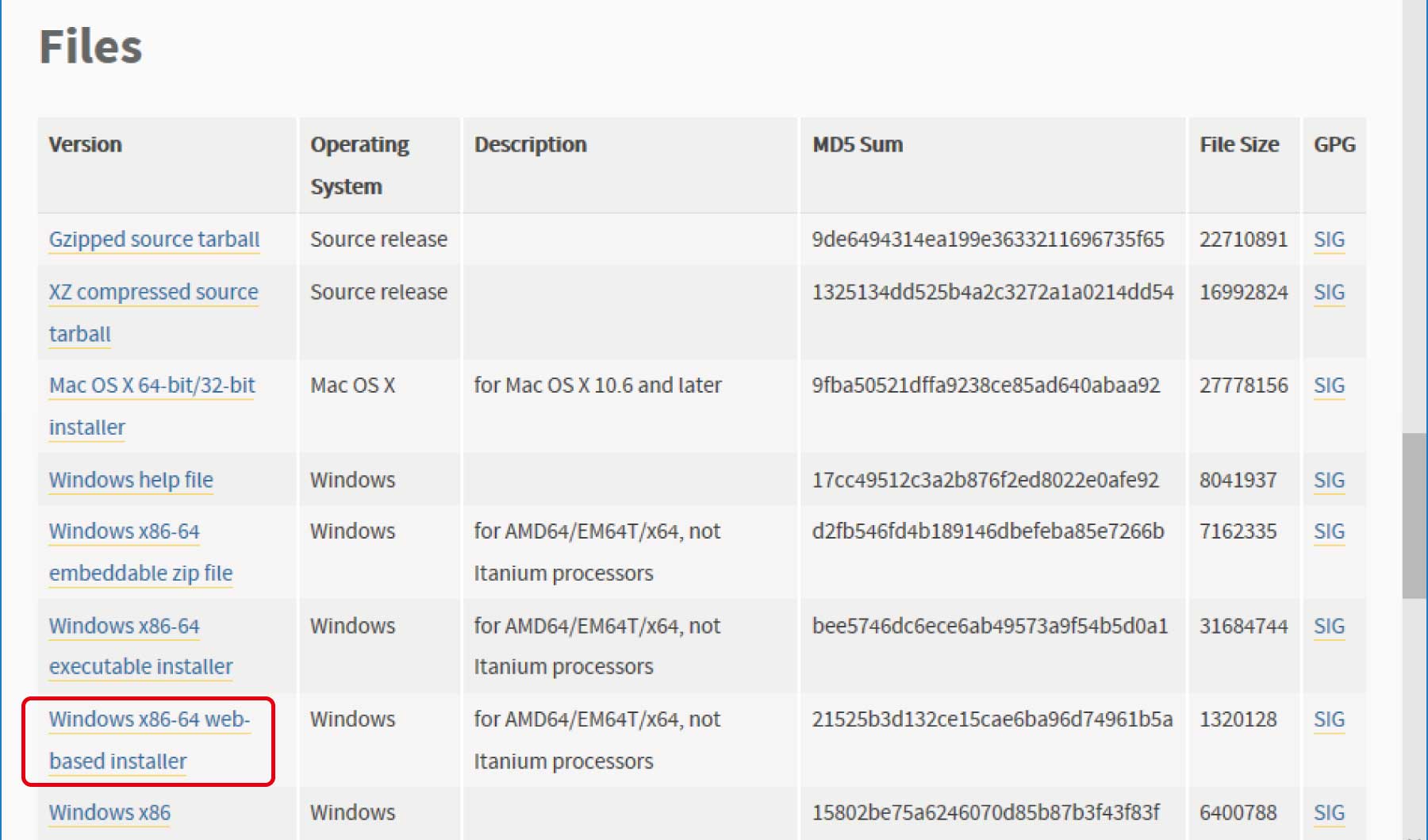
(3)「Python 3.6.4」のページのFiles欄で、「Windows x86-64 web-based installer」をクリックして、ダウンロードしてください。
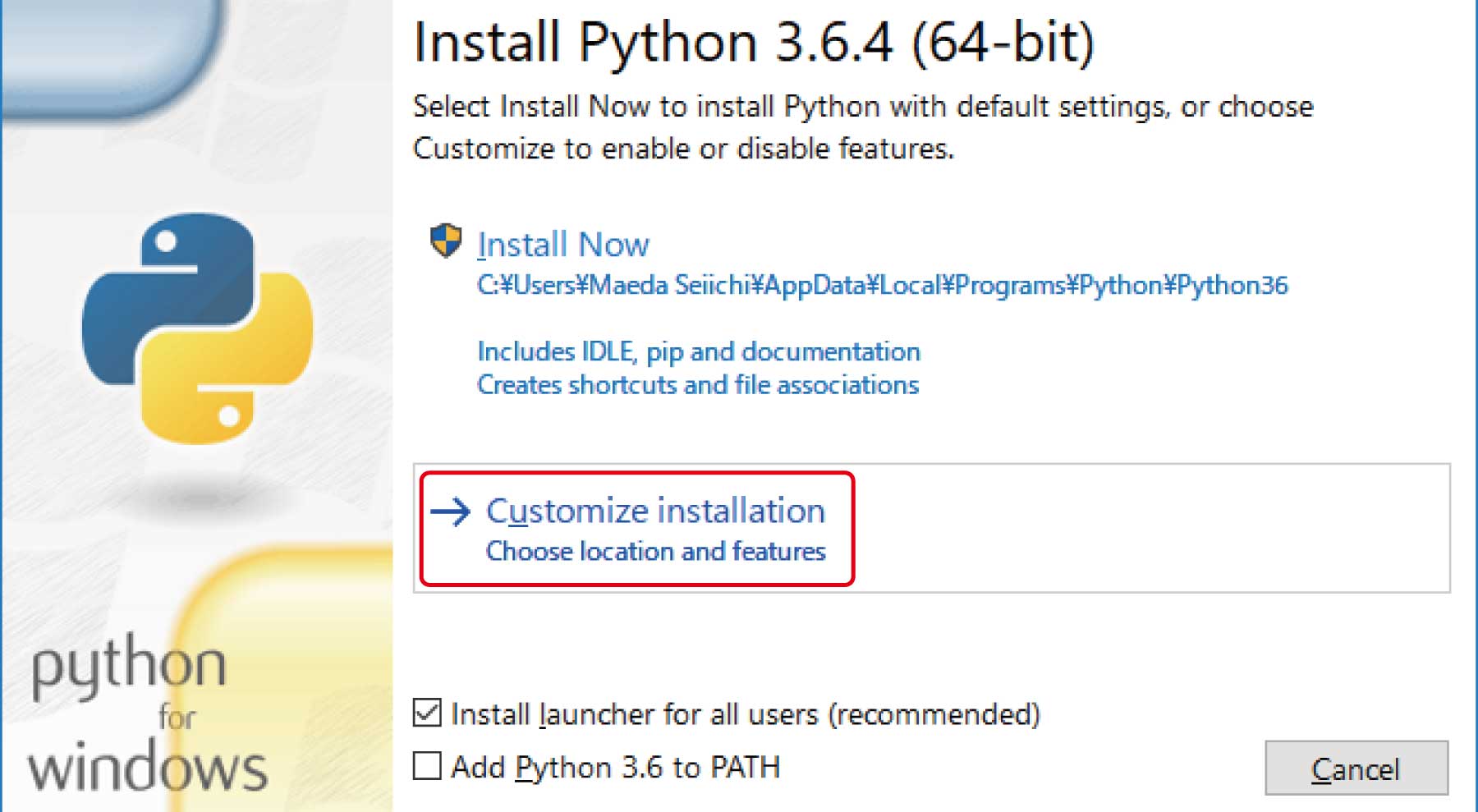
(4)ダウンロードしたインストーラを実行し、最初の画面で「Customize installation」を選択してください。
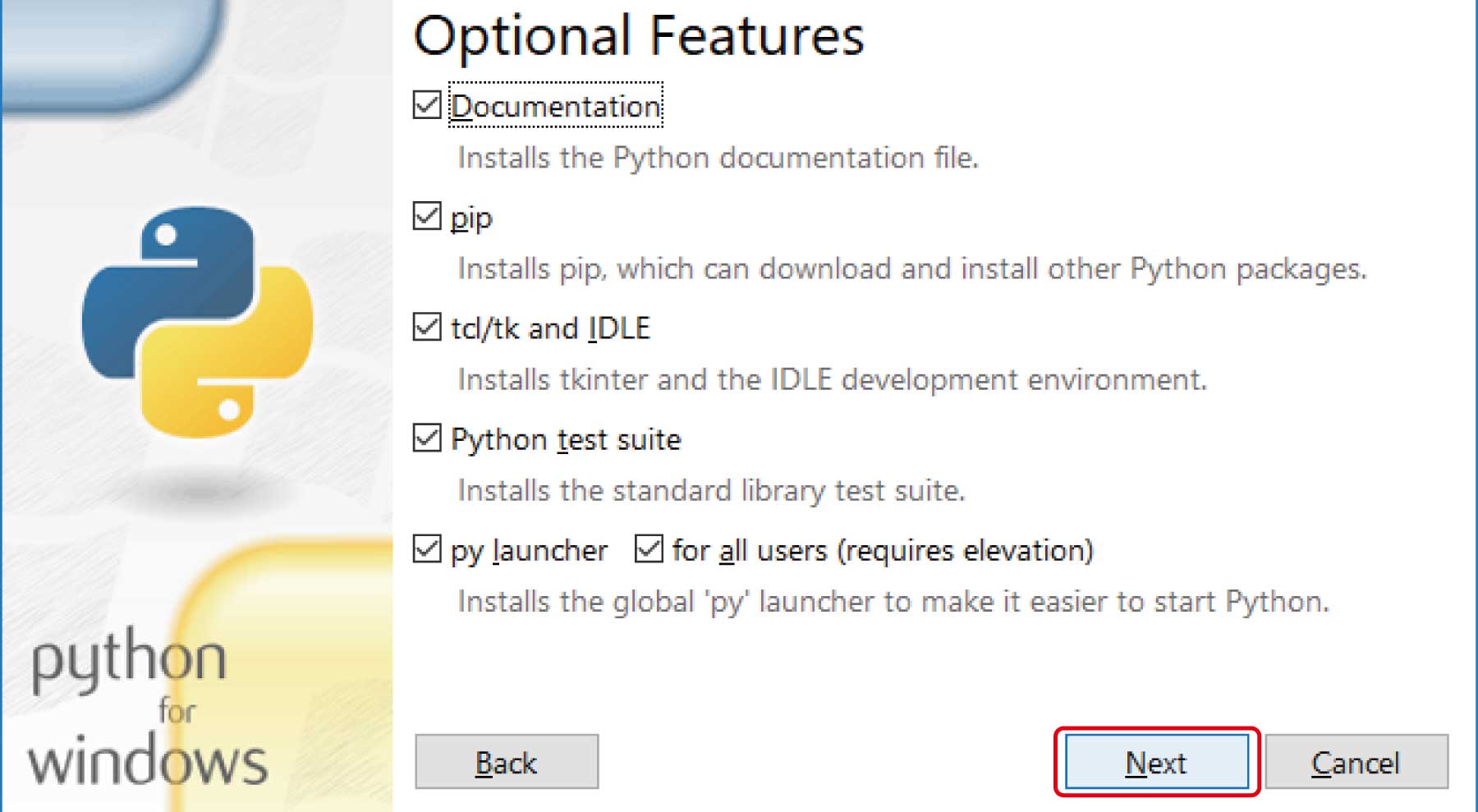
(5)「Optional Features」では、そのまま「Next」ボタンを押します。
(6)「Advanced Options」で、次の項目にチェックを入れます。また、インストール先のパスを指定してください。ここでは、C:\Program Files\Python36にします。
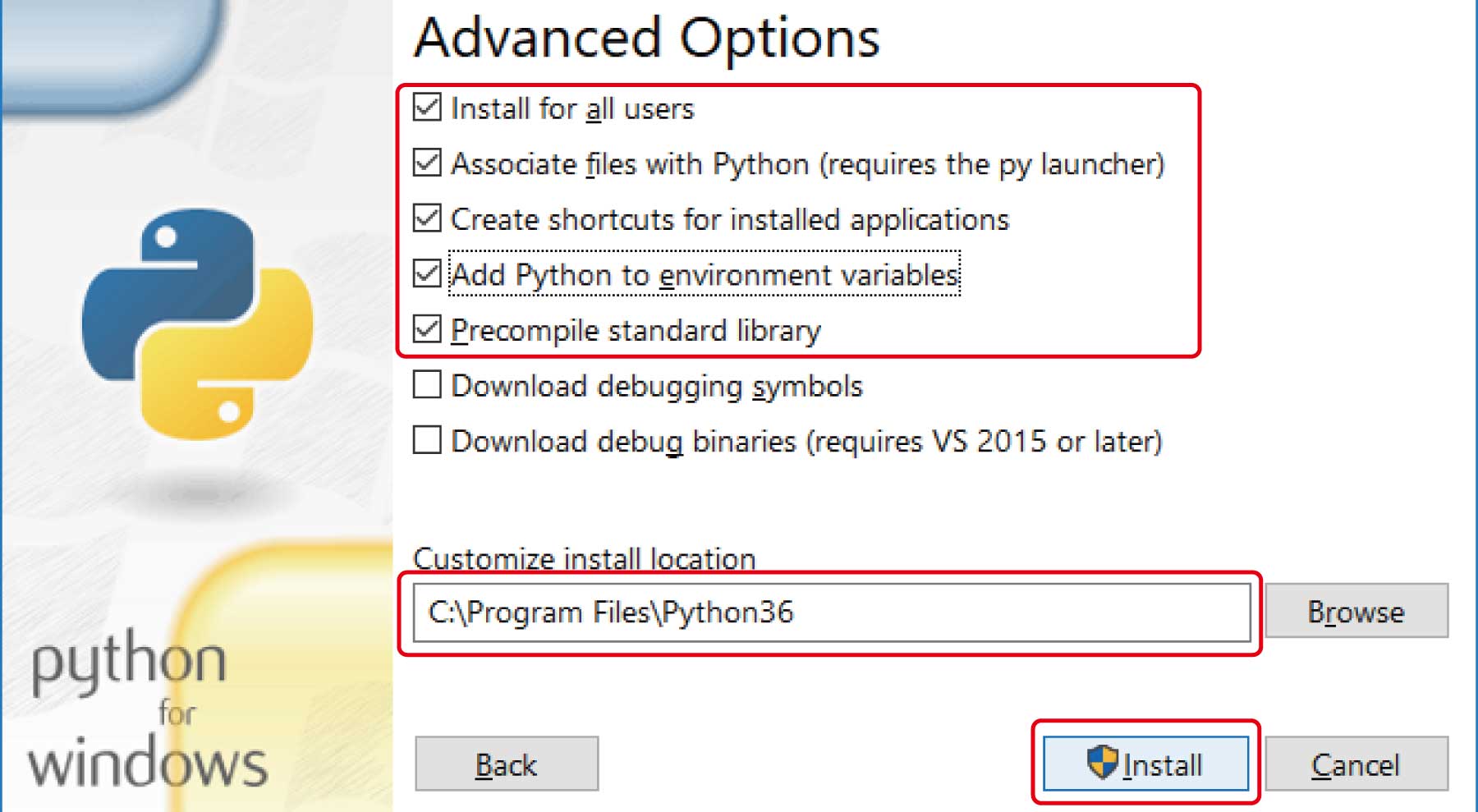
「Precompile standard library」は、「Install for all users」をオンにすると自動的にオンになります。
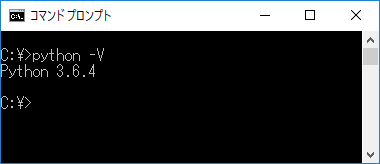
(7)インストール完了後、コマンドラインでpython ―Vを実行して、「Python 3.6.4」と表示されれば、インストール成功です。
Pythonの基本的なプログラム
実際にWebスクレイピングのプログラムを作成する前に、Pythonの基本的な書き方を、まとめて紹介します。次のプログラムを見てください。関数、リスト、辞書、for文といったPythonプログラミングの基本要素を含んでいます。このプログラムは、2018/5/1 2018/6/1 2018/7/1という3つの日にちの曜日を、日本語と英語で表示します。

上記プログラムのテキスト情報は記事末尾の「参考資料1」をご覧ください。
このプログラムを、テキストエディタで入力し、拡張子.pyで保存してください(文字コードはUTF-8)。Windows環境で、このPythonプログラムを実行するには、次のようにします。ここでは仮に、c:\pythonディレクトリ(フォルダ)に、ファイル名sample1.pyで保存したとすると、コマンドラインで次のように入力することで、保存したsample1.pyを実行できます。

実行結果は、次のとおりです。
2018年5月1日 火曜 Tuesday 2018年6月1日 金曜 Friday 2018年7月1日 日曜 Sunday
このプログラムでは、2つの関数getWeekDayとtoEngWeekを定義しています。メイン部分では、for文を使って、この2つの関数をそれぞれ3回呼び出しています。
(1)関数
Pythonでは、関数を次のように定義します。

頭が混乱しそうなので、ひとまず、getWeekDay関数の詳しい処理内容については後回しにして、関数の定義方法だけ解説します。
Pythonでは、同じ文字数だけインデント(字下げ)した部分が、1つのブロックになります。インデントの量は、半角スペース1文字でも、タブでも構いません。しかし、推奨されているのは、半角スペース4文字です。関数の処理内容も、このブロックで記述します。
{ }や、begin endでブロックの範囲を指定しないので、最初は気持ち悪いかもしれません。しかし、すぐに慣れるでしょう。インデントが強制されるので、誰が読んでも読みやすいコードになります。
改行が、文の区切りです。ただし、( )、{ }、[ ]の中での改行は、許されています。文の途中で改行したい場合は、行末に\を記述します。
Pythonでは、値を返す/返さないで、関数とサブルーチンに分けるということをしません。全て関数です。
引数や戻り値(返り値)の型は、指定しません。Pythonでは、引数に限らず、全ての変数について、型を指定することはありません。Pythonが、代入される値をみて、自動的に型を判断するのです。
引数と値を返す処理(return文)は、省略可能です。
(2)リスト
さて、getWeekDay関数の処理内容を見ていきます。次の部分は、リストの定義です。リストは、他の言語の配列に似ていて、複数のデータをまとめて扱えます。ここでは、月曜~日曜の文字列をyoubi_listに格納しています。
youbi_list = ['月曜', '火曜', '水曜',
'木曜', '金曜', '土曜', '日曜']
リストは、一般的な配列とは異なり、データを追加すると、サイズが自動的に拡張されるので、便利です。
また、リストの各要素にアクセスしたいときは、youbi_list[0]のように記述します。youbi_list[0]にアクセスすると、月曜という文字列を取得できます。
getWeekDay関数の残りの処理
getWeekDay関数は、引数で年月日の数値を受け取ると、その日付のdatetimeオブジェクトを作成し、曜日の情報を取得しています。

d.weekday()の返す数値が、例えば2であれば、youbi_list[d.weekday()]は、水曜になり、この関数は水曜という文字列を返します。
(3)辞書
辞書もリストと同じように複数のデータをまとめて取り扱えます。リストとの違いは、各要素が、キーと値のペアになっている点です。
toEngWeek関数では、キーが日曜、値がSundayというような、日本語と英語の曜日名の組み合わせを辞書で定義しています。これにより、例えばyoubi_dic['日曜']でアクセスすると、Sundayという文字列を取得できるのです。

toEngWeek関数は、日本語の曜日文字列(月曜~日曜)を受け取ると、辞書を使って、英語の曜日文字列を取得して、返しています。
(4)for文
for文の使い方は、他の言語とあまり変わりません。今回のサンプルから離れますが、多くの場合、次のようにリストなどから値を一つひとつ取り出すのに使います。

今回のサンプルでは、プログラムのメイン部分に、次のfor文があります。Pythonでは、任意の回数だけ処理を繰り返したい場合、このようにfor文とrange関数を組み合わせます。

range()の開始値と増加量は、省略できます。終端値の手前の値までの数値が生成されます。
例えば、range(5)であれば、0~4の値が生成されます。今回のサンプルでは、5~7の値が生成されていて、getWeekDay関数の引数に渡されています。
Webスクレイピングその1:Webページのソースの取得
Pythonの基礎について、なんとなく理解できたのではないかと思います。まずは「なんとなく」で十分です。さて、ここからはPythonを使って、Webスクレイピングのプログラムを作成してみましょう。
Pythonには、Webスクレイピングで役立つモジュールがいくつかあります。今回は、RequestsとBeautiful Soupという2つのモジュールを使用します。Requestsは、http(s)通信を行うためのモジュールです。また、Beautiful Soupは、HTMLデータから特定の情報を抽出するためのモジュールです。これらのモジュールは、あらかじめインストールしておく必要があります。Windows環境の場合、コマンドラインで次の2つを実行してください。
C:\Users\xxx> pip install requests C:\Users\xxx> pip install beautifulsoup4
最初に、Webページのソース(HTMLの文字列)を取得して、ファイルに書き出すプログラムを作成してみます。
スクレイピング対象とするページは、「はてなブックマーク」です。エンジニアHubの共同編集部がある「株式会社はてな」が運営するサービスですが、作業の前に、まずは同サイトの利用規約を確認してみましょう。
この中の「過剰アクセスに関する注意事項」というページでは、「コンテンツを自動巡回ツール、ダウンロードツールなどで取得することはお控えください」とあります。また、「はてなブックマーク」には、APIも存在しています。
そのため、本来であれば、「はてなブックマーク」をWebスクレイピングすることは、控えなければいけません。ただ、今回は記事執筆のため、特別な許可を得て、Webスクレイピングを行います。
上記を踏まえ、同サイトのrobots.txtを確認してみましょう。
User-agent: Yeti/1.0 (NHN Corp.; http://help.naver.com/robots/) Crawl-Delay: 3 Disallow: /search Allow: /search/tag Allow: /search/text Allow: /search.touch User-agent: * Disallow: /search : Allow: /search/tag Allow: /search/text :
上記のrobots.txtは抜粋ですが、ユーザーエージェントが *(特記されている以外の全てのソフトウェア)について、パス/searchはDisallowで禁止になっています。ただし、パス/search/textについては、Allowで許可されています。今回はパス/search/textにアクセスするので、robots.txtの表記上では、問題ないようです。
それでは、ここから任意のキーワードで検索をした結果から、さらに特定の情報を抽出するプログラムを作ってみます。ここでは、「Python」をキーワードにし、さらに1,000人以上がブックマークしているページを検索して、結果のソースを取得し、タイトルとURLの情報を抽出します。なお、執筆時点(2018年3月)で、7件の検索結果がありました。
上記プログラムのテキスト情報は記事末尾の「参考資料2」をご覧ください。
このプログラムでは、カレントディレクトリのsample.htmというファイルに、取得したWebページのHTML文字列が書き込まれます。
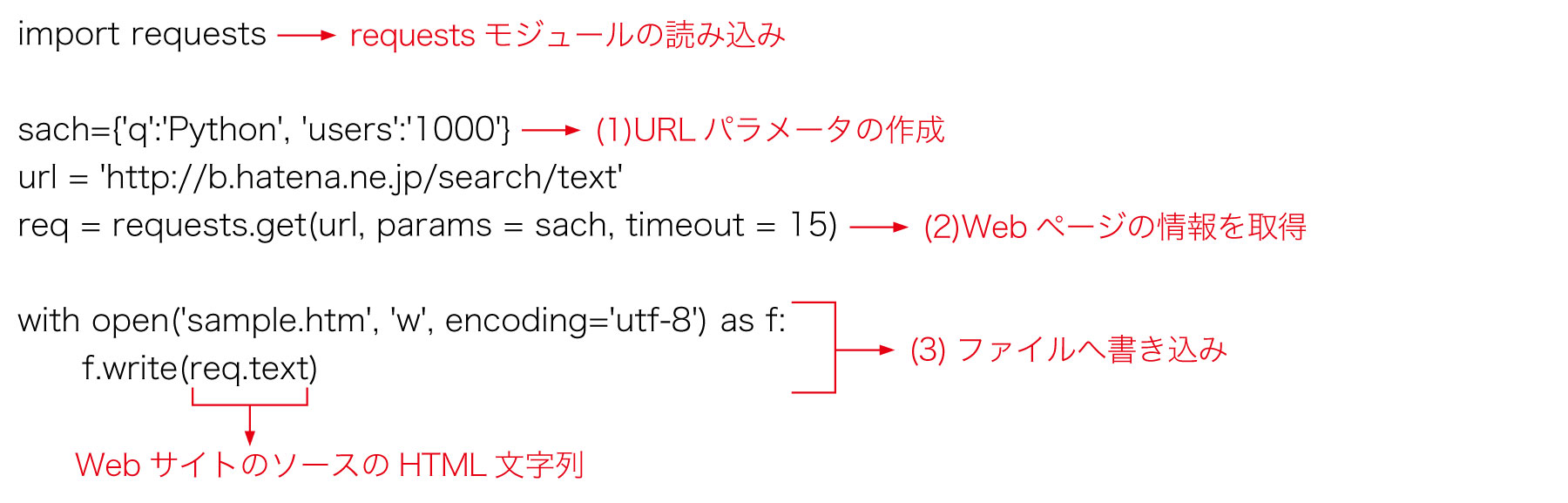
(1)URLパラメータの作成
今回、requestsモジュールのget関数を使って、Webページの情報を取得しますが、その際に使用するURLパラメータを、辞書の形式で作成します。「はてなブックマーク」のサイトでは、キーワードを使って検索を行う場合、キーワードを「q=キーワード文字列」というパラメータ形式で指定します。また、ブックマークのユーザー数を「users=人数」のように指定します。次のように、パラメータと設定値が、ペアになるように辞書を作成してください。
sach={'q':'Python', 'users':'1000'}
(2)Webページの情報を取得
requestsモジュールのget関数を使って、Webページの情報を取得します。URL文字列、パラメータ(辞書)、タイムアウト値(秒)を、次のように指定します。URLエンコードは、get関数が自動的に行ってくれます。
req = requests.get(url, params = sach, timeout = 15)
Webページの取得に成功すると、ソース(HTML文字列)は、req.textに入ります。
(3)ファイルへの書き込み
req.textに入っているWebページのソースを、ファイルに書き込みましょう。open関数でファイルをオープンし、write関数で書き込みますwith構文でファイルをオープンすると、自動的にclose()処理が行われるので、便利です。
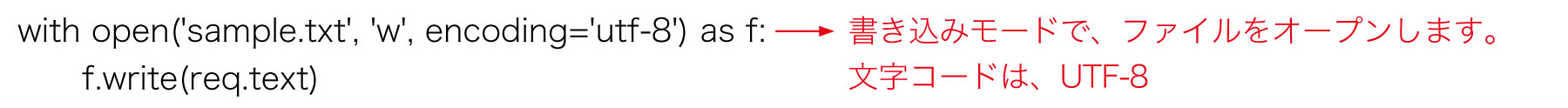
Webスクレイピングその2:Webページの解析とCSV出力
さて、Webページのソースを取得できたので、次の段階に進みましょう。
書き込んだファイルsample.txtを開くと、次のようになっています。この内容から、ページタイトルとURLの情報を抽出して、CSVファイルを作成してみましょう。なお、以下のsample.htmは本稿に必要な要素を抜粋したものです。

検索結果の情報は、ブックマークごとに、class属性のない<h3>要素内にあるのが分かります。ちなみに、class属性がfeature-hint-popup-titleの<h3>が別にあるので、注意してください。また、タイトルは、<a>タグのhref属性内です。URLは、<a>タグのtitle属性内にあります。
これらの情報をもとに、タイトルとURLの情報を抽出し、CSVファイルを作成するプログラムは、次のようになります。先ほどのサンプルをベースにしていますが、Webサイトのソースをファイルに書き出す部分は、削除しました。

上記プログラムのテキスト情報は記事末尾の「参考資料3」をご覧ください。
(1) Webサイトの解析
BeautifulSoup 4モジュールのBeautifulSoupクラスを使って、Webサイトの情報を解析しています。
(2) タイトル、URLの情報を取得
検索結果のブックマークは、複数あることが予想されます。BeautifulSoupオブジェクトのfindAll関数を使って、それらの情報を全て取得します。findAll関数は、HTMLデータの中から、特定のタグや属性を持つ要素を抽出して、リスト形式で結果を返します。
class属性のない<h3>要素の情報をfor文で、順次取得しています。
for b in soup.findAll('h3', {'class':''}):
タイトルの情報は、取得した<h3>要素内に登場します。<a>要素内のtitle属性の値を取得します。
title = b.find('a').get('title')
同様に、URL情報は、<a>要素内のhref属性の値から取得します。
url = b.find('a').get('href')
(3) CSVファイルに書き出し
取得したタイトルとURLのリストを、CSVファイルに書き出します(Shift-JIS形式)。
with open(bookmarks.csv', 'w', encoding='shift-jis') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(bookmarks)
書き出されたcsvファイルを、Excelなどで開くと、次のようなリストが表示されます。
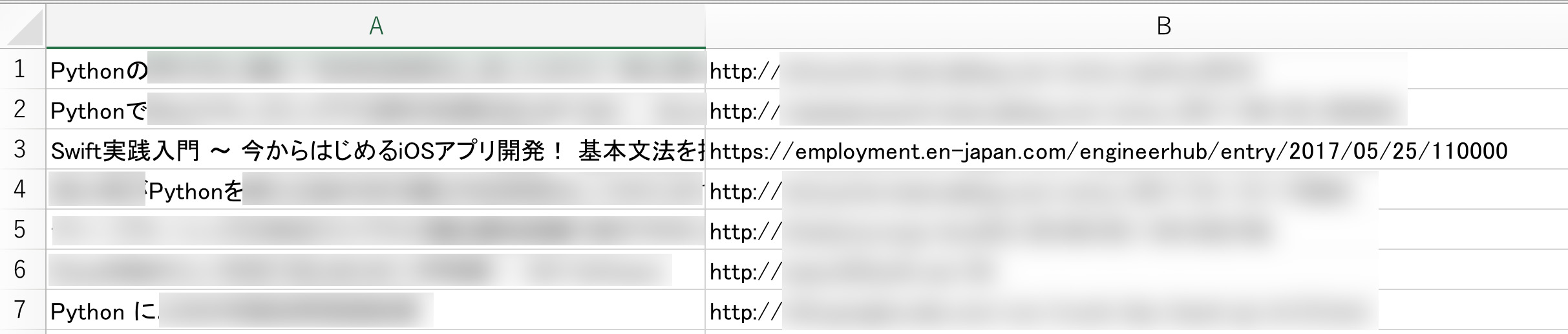
このように、任意の情報を抽出することに成功しました。例えば、定期的に情報を取得していけば、興味を持たれている最新のPython情報を知ることができます。動的な情報を定期的にストックすることで、ある人にとって価値のある情報を生み出すことができます。そのための手段として、スクレイピングは非常に効果的です。
もっとも、はてなブックマークにはRSSフィードがあるので、今回のような情報取得を目的とするのであれば、RSSフィードを使う方が早いのですが、今回はスクレイピングのセオリーをハンズオンで学ぶことが目的ですので、一例としてご紹介しました。
まとめ
このように、Pythonを使ったWebスクレイピングは、シンプルなものであればとても簡単です。C、C++、Javaといった言語を使ってきた人が、一度Pythonを使うと、その簡潔な構文や充実したライブラリに魅せられて、一気にPythonファンになってしまうことも多いようです。マナーと法律の範囲内で、ぜひPythonを使ってWebスクレイピングを試し、楽しくPythonのエッセンスを学んでください。
執筆者プロフィール
前田整一 (まえだ・せいいち 株式会社アンク)
(株)アンク は、ソフトウェアの開発、Webシステムの構築、書籍執筆などを幅広く行う会社。 今回執筆の前田は、普段学校向けソフトウェアの開発・販売を行っているが、ときどき書籍の執筆に関わる。関わった書籍は、『C++の絵本』、『C#の絵本』、『Pythonの絵本』(全て翔泳社刊)など。
参考資料
参考資料1
import datetime
def getWeekDay(year, month, day):
youbi_list = ['月曜', '火曜', '水曜',
'木曜', '金曜', '土曜', '日曜']
d = datetime.datetime(year, month, day)
return youbi_list[d.weekday()]
def toEngWeek(strYoubi):
youbi_dic = {'月曜':'Monday', '火曜':'Tuesday',
'水曜':'Wednesday', '木曜':'Thursday',
'金曜':'Friday', '土曜':'Saturday', '日曜':'Sunday'}
return youbi_dic[strYoubi]
for m in range(5, 8 ,1):
youbi = getWeekDay(2018, m, 1)
print('2018年%d月1日' % m)
print(youbi)
print(toEngWeek(youbi) + '\n')
参考資料2
import requests
sach={'q':'Python', 'users':'1000'}
url = 'http://b.hatena.ne.jp/search/text'
req = requests.get(url, params = sach, timeout = 15)
with open('sample.htm', 'w', encoding='utf-8') as f:
f.write(req.text)
参考資料3
import requests
import bs4
import csv
sach={'q':'Python', 'users':'1000'}
url = 'http://b.hatena.ne.jp/search/text'
req = requests.get(url, params = sach, timeout = 15)
soup = bs4.BeautifulSoup(req.text, 'html.parser')
bookmarks = []
for b in soup.findAll('h3', {'class':''}):
title = b.find('a').get('title')
url = b.find('a').get('href')
bookmarks.append([title, url])
with open('bookmarks.csv', 'w', encoding='shift-jis') as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(bookmarks)




