
データベース運用改善のヒント!コア開発者直伝のPostgreSQL 10の7つの新機能
全国のPostgreSQL使いエンジニアが待ちに待った、バージョン10。新機能の中から、特に“運用”に役立つ7の新機能を、PostgreSQLの専門家、そして開発者である澤田雅彦さんにピックアップして解説してもらいました。
2017年10月5日、全国のPostgreSQL使いエンジニアが待ちに待った、バージョン10(安定版)がリリースされました。「今後、自分の開発業務に導入していきたい」と考えている方も多いでしょう。
今回は、PostgreSQLの専門家、そして開発者である澤田雅彦さんに、新機能の中でも特に“運用”に役立つ7の新機能をピックアップして解説してもらいました。これを読めば、現場ですぐに役立つPostgreSQL 10(以下、バージョン10)の知識が身につきます!
<
- 澤田雅彦(さわだ・まさひこ)
- 2012年、NTTデータに入社。以降、PostgreSQLに関する業務に従事し、主にPostgreSQLの本体開発、技術支援および、国内外問わずさまざまなカンファレンスでの講演活動などを行っている。2016年より、NTT OSSセンタに勤務。PostgreSQLコミュニティでは、Contributorとしてレプリケーション、VACUUM、分散トランザクション機能の開発やバグ修正を通してコア開発に貢献。
- (1)テーブルパーティショニング
- (2)論理レプリケーション
- (3)パラレルクエリ
- (4)待機イベントのカテゴリが細分化
- (5)Quorum-based 同期レプリケーション
- (6)デフォルトロールにモニタリング・監視用の権限が追加された
- (7)旧バージョンと非互換の機能
(1)テーブルパーティショニング
──まずは、テーブルパーティショニングについてお聞きします。従来のPostgreSQLには、テーブルパーティショニング専用の機能はありませんでした。しかし、バージョン10では、いよいよその機能が搭載されたそうですね。
澤田 はい。これは、ある列の値を元に、テーブルをパーティショニングできる機能です。パーティショニングの方法には2種類があり、ひとつは列の値を「最小値から100」「100から200」というようにレンジで区切り、分割する方法(レンジ・パーティション)。もうひとつは、列の値をリストで区切り、分割する方法(リスト・パーティション)で、これはブログのカテゴリを保持するテーブルを「ミュージックカテゴリ」と「スポーツカテゴリ」でパーティショニングする、というイメージです。サンプルSQLは、以下のようになります。
【サンプルSQL:レンジ・パーティション】
--idをパーティションキーにして、1階層のパーティションテーブルを作成し、データを投入。usersテーブルにINSERTしたデータがちゃんと振り分けられている事を確認する。 -- 1. ユーザIDをパーティションキーにして親テーブルを作成 CREATE TABLE users (id int, name text) PARTITION BY RANGE (id); -- 2. 各子テーブルを作成 CREATE TABLE users_100 PARTITION OF users FOR VALUES FROM (minvalue) TO (100); CREATE TABLE users_200 PARTITION OF users FOR VALUES FROM (100) TO (200); -- 3. ユーザテーブルにデータを挿入 INSERT INTO users VALUES (10, 'Alice'), (50, 'Bob'), (140, 'Carol'); -- 4. テーブルの中身を全て取得 SELECT * FROM users; id | name -----+------- 10 | Alice 50 | Bob 140 | Carol (3 rows) -- 5. 各子テーブルを指定して取得。ユーザIDを元に振り分けられていることがわかる SELECT * FROM users_100; id | name ----+------- 10 | Alice 50 | Bob (2 rows) SELECT * FROM users_200 ; id | name -----+------- 140 | Carol (1 row) -- 6. 対応する子テーブルがないとエラー INSERT INTO users VALUES (250, 'Dave'); ERROR: no partition of relation "users" found for row DETAIL: Partition key of the failing row contains (id) = (250).
【サンプルSQL:リスト・パーティション】
--レンジパーティションと同様の事をするSQLです。
-- 1. ユーザIDをパーティションキーにして親テーブルを作成
CREATE TABLE blogs (id int, category text, content text) PARTITION BY LIST (category);
-- 2. 各子テーブルを作成
CREATE TABLE blogs_music_art PARTITION OF blogs FOR VALUES IN ('music', 'art');
CREATE TABLE blogs_cooking_sports PARTITION OF blogs FOR VALUES IN ('cooking', 'sports');
-- 3. ユーザテーブルにデータを挿入
INSERT INTO blogs VALUES (1, 'music', 'xxxxx'), (2, 'cooking', 'yyyyy'), (3, 'sports', 'zzzzz');
-- 4. 親テーブル経由、各子テーブル経由でテーブル内容を確認する
SELECT * FROM blogs;
id | category | content
----+----------+---------
1 | music | xxxxx
2 | cooking | yyyyy
3 | sports | zzzzz
(3 rows)
SELECT * FROM blogs_cooking_sports;
id | category | content
----+----------+---------
2 | cooking | yyyyy
3 | sports | zzzzz
(2 rows)
SELECT * FROM blogs_music_art ;
id | category | content
----+----------+---------
1 | music | xxxxx
(1 row)
──「サンプルSQL:レンジ・パーティション」の「6. 対応する子テーブルがないとエラー」でINSERTがエラーになっていますが、これはどうしてですか?
澤田 親テーブルに対しデータをインサートする際、そのデータが格納されるべき適切な子テーブルが存在していなければエラーになってしまうからです。この点は、運用時に注意してください。テーブルに格納するデータがレンジの上限値に達する前に子テーブルを作成する、などの作業を必ず運用フローに組みこむ必要があります。
──どのような用途の場合、テーブルパーティショニングは効果的に機能しますか?
澤田 例えば、100GB以上のデータ量があるような大きなテーブルを分割して、アクセス速度の改善や運用の効率化をするという用途で有効です。それから、日付のレンジパーティショニングで年月ごとに子テーブルを作成し、その年月のテーブルが不要になったらDROPして削除する、といった用途などにも向いていると思います。
──特定のテーブルに全ての年月のデータを入れておき、不要になったデータだけ順次DELETEしていく、という運用ではいけないのでしょうか?
澤田 PostgreSQLって、DELETEしたデータのゴミがずっと残ってしまうので、運用を続けるごとにテーブルがどんどん重くなってしまうんです。年月ごとにテーブルをパーティショニングしておけば、不要になったらDROPできるためゴミデータによるパフォーマンス劣化を防ぐことができます。

(2)論理レプリケーション
澤田 PostgreSQLには物理レプリケーション機能はありましたが、論理レプリケーション(データの変更情報を論理的な形式で送るレプリケーション)機能はありませんでした。しかし、バージョン10ではいよいよ論理レプリケーションが実装されたんです。
従来のPostgreSQLが持っていたレプリケーションでは、1つのマスターが持つ情報を複数のスタンバイに対してコピーすること(1対多)しかできなかったんですが、論理レプリケーションによって、逆に複数のデータベース(またはテーブル)が持つデータを1つのデータベース(またはテーブル)にコピーすること(多対1)も可能になります。
これにより、複数システムのバックアップを1つのデータベースに集約しておく、といった運用ができるようになるんです。
──マスターとスタンバイのテーブルスキーマ情報は、完全に一致していなければいけないですか?
澤田 実は、完全に一致していなくても大丈夫です。例えば、マスターのテーブルがid、nameという2つの列を持っており、スタンバイのテーブルがid、name、birthdayという3つの列(2つはマスターの列と一致)を持っている場合、レプリケーション可能です。birthdayの値は列のデフォルト値になります。
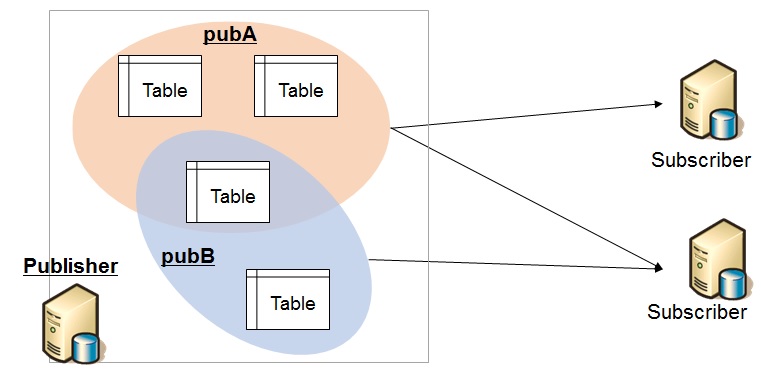
論理レプリケーションを使用する際には、データを送信するPublisherと受信するSubscriberを用意します。CREATE SUBSCRIPTIONコマンドを実行した時点でレプリケーションが開始され、そのタイミングで初期データコピーが行われるんです。DDL文はレプリケートされないなど、さまざまな制約があるので、使用する際にはそれらの制約も調べておくといいと思います。
【サンプルSQL:PublisherとSubscriberを用意し、論理レプリケーションを使用】
-- 1. Publisher側でテーブルを作成し、PUBLICATION(test_pub)に登録。 CREATE TABLE tbl (k int, value text); CREATE PUBLICATION test_pub FOR TABLE tbl; INSERT INTO tbl VALUES (1, 'abc'), (2, 'def'), (3, 'ghi'); -- 2. Subscriber側でもテーブルを作成し、SUBSCRIPTIONを作成。CREATE SUBSCRIPTIONコマンドを実行時にレプリケーションが開始される CREATE TABLE tbl (k int, value text); CREATE SUBSCRIPTION test_sub CONNECTION 'port=5432 dbname=postgres host=pgserver' PUBLICATION test_pub; -- 3. 論理レプリケーション開始時には初期データのコピーが行われる SELECT * FROM tbl; k | value ---+------- 1 | abc 2 | def 3 | ghi
{$image_4}
PublisherとSubscriberの対応関係。
(3)パラレルクエリ
──パラレルクエリとはどういった機能ですか?
澤田 これは、処理速度をより速くするために、複数のCPUを活用してクエリを実行するというものです。パラレルクエリ自体はバージョン9.6から導入されていたのですが、バージョン10ではパラレルクエリに対応するスキャン・ジョイン方式が増えています。
──SQLのスキャン方式には、インデックススキャンやインデックスオンリースキャン、ビットマップインデックススキャンなど、さまざまなものがあります。その中で「特にこのスキャン方式は、パラレルクエリを用いることで処理が高速化する」というものはありますか?
澤田 パラレルクエリが最も効果を発揮するのは、一定量以上のデータを検索するとき。例えば、バージョン9.6でパラレルクエリが適応されたシーケンシャルスキャンや、バージョン10でパラレルクエリが適応されたビットマップインデックススキャンです。
社員情報を保持するテーブルで、テーブル全体を取得する場合や、複数部署のメンバーを検索をする際に部署名でOR検索をかける場合のように、テーブルの多くの部分、ないしはテーブル全体のデータを取得するケースが、パラレルクエリを使うには効果的だと思います。
{$image_5}
(4)待機イベントのカテゴリが細分化
──バージョン9.6で導入された待機イベントが、バージョン10ではさらに進化したそうですね。
澤田 バージョン9.6の段階では、以下の4つのカテゴリがありました。
LWLockNamed LWLockTranche Lock BufferPin
しかし、バージョン10ではこのカテゴリが以下のようにさらに細分化されたんです。
LWLock Lock BufferPin Activity Extension Client IPC Timeout IO
バージョン9.6で確認できるのは、ほとんどがロック関連の待機イベントです。そのため、PostgreSQL内部のロックが原因で処理が遅延している場合は調査可能だったんですが、ディスクの読み書きで遅いとか、外部との通信で遅いといったPostgreSQL“外”で起きていることは、OS側から見るしかありませんでした(iostatなどのコマンドを用いて推測する、perfなどのプロファイラを利用するなど)。
でも、バージョン10の場合は待機イベントが詳細にわかるようになったため、何が原因で待ちが発生しているのかが把握しやすくなりました。
──この機能が入ることで、リサーチにかかる時間的コストがかなり削減されそうですね。
澤田 はい。さらに、待機イベントの詳細情報がPostgreSQLから参照できると、Amazon RDSのようにOSにログインできない環境でも調査が容易になるんです。オンプレではなくクラウドが増えている現代のインフラ事情にマッチしている機能だと思います。
【サンプルSQL:待機イベントの表示例】
SELECT query, wait_event_type, wait_event FROM pg_stat_activity LIMIT 15;
query | wait_event_type | wait_event
------------------------------------------------------------------+-----------------+---------------------
| Activity | AutoVacuumMain
| Activity | LogicalLauncherMain
SELECT query, wait_event_type, wait_event FROM pg_stat_activity; | |
SELECT abalance FROM pgbench_accounts WHERE aid = 613233; | LWLock | buffer_mapping
SELECT abalance FROM pgbench_accounts WHERE aid = 2914418; | IO | DataFileRead
SELECT abalance FROM pgbench_accounts WHERE aid = 995494; | LWLock | buffer_mapping
SELECT abalance FROM pgbench_accounts WHERE aid = 1662121; | LWLock | buffer_mapping
SELECT abalance FROM pgbench_accounts WHERE aid = 2824052; | |
SELECT abalance FROM pgbench_accounts WHERE aid = 1345424; | Client | ClientRead
SELECT abalance FROM pgbench_accounts WHERE aid = 1276373; | LWLock | buffer_mapping
SELECT abalance FROM pgbench_accounts WHERE aid = 604526; | LWLock | buffer_mapping
SELECT abalance FROM pgbench_accounts WHERE aid = 2326450; | LWLock | buffer_mapping
SELECT abalance FROM pgbench_accounts WHERE aid = 1333845; | LWLock | buffer_mapping
SELECT abalance FROM pgbench_accounts WHERE aid = 2662576; | IO | DataFileRead
SELECT abalance FROM pgbench_accounts WHERE aid = 2211156; | LWLock | buffer_mapping
(5)Quorum-based 同期レプリケーション
──レプリケーションに関しては、他にも目玉機能が追加されたそうですね。
澤田 データベースの可用性をより高めるために、Quorum-based同期レプリケーション機能が追加されました。
レプリケーションには大きく分けて非同期モードと同期モードの2つがあります。同期モードとは、マスターが変更情報を送った後、スタンバイが変更情報を書き込むのを待ってから、クライアントへ応答を返すモードです。そのため、レプリケーションのためのオーバヘッドはかかりますが、信頼性が向上します。一方、非同期モードではスタンバイでの書き込みを待たずに、非同期的にデータの複製を行います。基本的に、DBの信頼性を向上させるには、同期モードでレプリケートすることが望ましいです。
バージョン9.6では、仮に1台のマスターと5台のスタンバイ(それぞれA、B、C、D、Eとする)がある場合に、AとBのみ同期モードにするという設定ができました。しかし、このモードには課題があって、同期モードであるAとBの両方からの応答が返ってこないと、マスターでの処理が止まってしまいます*1。
その課題を解決するために生まれたのがQuorum-based同期レプリケーションです。これは、先ほどの例に当てはめると、5台のスタンバイの中から、生きているどれか2台のサーバからの応答を待つレプリケーション方式。つまり、仮にAとBからの応答が返ってこなくても、他のスタンバイの内どれか2台からの応答が返ってくる限り、マスターは処理を続けることができます。これにより、同期モードの際の障害点が分散され、より可用性の高い 運用が可能になります。
(6)デフォルトロールにモニタリング・監視用の権限が追加された
澤田 バージョン10からは、デフォルトロールとして以下の4種が導入されました。
| ロール | 権限 |
|---|---|
| pg_read_all_settings | PostgreSQLパラメータのうち、通常はスーパーユーザでないと参照できない情報を含め、全てのパラメータを参照可能にする。 |
| pg_read_all_stats | pg_stat_* ビューのうち、通常はスーパーユーザでないと参照できない情報を含め、全ての情報を参照可能にする。 |
| pg_stat_scan_tables | 統計情報に関するSQL関数のうち、通常はスーパーユーザでないと実行できない関数を含め、全ての関数を実行可能にする。 |
| pg_monitor | 上記の3つを足した権限を持つ。 |
pg_monitorは他3つを足したものと同義です。pg_monitorロールを持つユーザはスーパーユーザでなくても、全ての統計情報やGUCパラメータへのアクセス権を持ちます。
これまでは、スーパーユーザのみがそれらの参照権限を持っていたため、モニタリングや運用だけを担当するユーザにもスーパーユーザ権限を付与する必要がありました。ですが、その運用方法は非常にリスクが高い。これらのデフォルトロールが追加されたことで、モニタリングや解析だけ担当するユーザに最小限の権限だけを付与すればよくなり、より安全に運用できるようになったんです。
【サンプルSQL:一般ユーザとpg_monitorユーザが参照できる情報の違い】
CREATE USER monitor_user; CREATE USER normal_user; GRANT pg_monitor TO monitor_user; -- normal_userで接続。権限が無いためクエリが見えない SELECT pid, query FROM pg_stat_activity ; pid | query -------+------------------------------------------- 76125 | <insufficient privilege> 76123 | <insufficient privilege> 76722 | SELECT pid, query FROM pg_stat_activity ; 76121 | <insufficient privilege> 76120 | <insufficient privilege> 76122 | <insufficient privilege> -- monitor_userで接続 SELECT pid, query FROM pg_stat_activity ; pid | query -------+------------------------------------------- 76125 | SELECT * FROM test; 76123 | UPDATE test SET c = c + 1 WHERE c = 10; 76802 | SELECT pid, query FROM pg_stat_activity ; 76121 | 76120 | SELECT count(*) FROM test; 76122 |
(7)旧バージョンと非互換の機能
──そもそも、旧バージョンと非互換の機能はありますか?
澤田 いくつかディレクトリや関数の名称変更がありました。具体的には、トランザクションログが格納されているpg_xlogがpg_walに、コミットログが格納されているpg_clogがpg_xactにリネームされたんです。
──それはなぜ?
澤田 logという名前がついていると、誤って中のファイルを削除してしまう人がいるんですよ。これらはシステムの仕様上必須のファイルなので、どちらも絶対に消してはいけません。そのため、運用トラブルを防ぐ目的からlogという名称を使わないようにしたんです。同様の理由で、xlogが含まれる関数の名称もwalに変更されました。また、xlog ⇒ walに加えて、関連する関数はlocation ⇒ lsnにリネームされています。
例:pg_current_xlog_location ⇒ pg_current_wal_lsn
他に非互換となった機能としては、シーケンスのメタデータがpg_sequenceシステムビューに移動しました。
運用ツールやバックアップツールなどで、これらのディレクトリやシーケンス情報を参照していたならば、バージョン10に移行するにあたって参照先を変更する必要があります。
他にもたくさん新機能がありますが、今回は代表的なものをピックアップして解説しました。ぜひ、これらの新機能を業務で活用してもらえれば嬉しいです。
──大規模サービスの運用に携わるデータベースエンジニアにとっては、特に役立つ機能ばかりでしたね。参考になりました。どうもありがとうございました!
取材:中薗昴(サムライト)/写真:鈴木香那枝
スタンバイがダウンしマスターとの通信が切断された場合は、他のスタンバイが同期モードに切り替わることが可能です。↩




