
RDBとNoSQLにみるDB近現代史 データベースに破壊的イノベーションは二度起きるか?
データベースのスタンダートとなっている「リレーショナルデータベース」がどのような背景から登場し、現在の地位を確立したのか、そしてどのような課題・限界に直面しているのか、さらにNoSQLのアプローチについて、『達人に学ぶ SQL徹底指南書』などの著書もあるDBエンジニアのミックさんが解説します。
皆さんこんにちは、DBエンジニアのミック(@copinemickmack)といいます。普段は主に、データベースのパフォーマンス設計やチューニングなどの仕事を行っています。
本稿は、データベースに関する二つのテーマを扱った記事です。一つ目のテーマは、リレーショナルデータベース(RDB、Relational Database)の誕生から成長の歴史を振り返り、現在主流となったこの技術がどのような背景から登場し、なぜデータベースのスタンダードの地位を確立したのかという理由を明らかにすることです。個別の製品の発展史というよりも、RDBという総体としての技術の歴史を取り上げることで、この問題を分析してみたいと思います。
二つ目のテーマは、時代の移り変わりとともに生じた新たな課題に対して、RDBがどのような限界に突き当たっているか。そして、NoSQLに代表される新技術がどのようなアプローチを試みているか、という現在から将来にかけての展望を考えてみることです。
RDBおよびNoSQLの概要については本稿の中で説明するため、前提知識は特に必要としませんが、RDBおよびNoSQLの製品をいくつか使用した経験があると、具体的なイメージをもって読むことができるでしょう。
それではまず、第一のテーマから見ていきたいと思います。
リレーショナルデータベースの歴史
現在、リレーショナルデータベース、およびその操作言語であるSQLは、用途を問わずほぼすべてのシステムにおいて何らかの形で使われていると言って過言ではありません。B to CやC to CのようなWebサービス、企業や官公庁の基幹系システム、BI/DWHと呼ばれるアナリティスク系のシステムなど、あらゆるシステムでRDBは利用されています。この汎用性の高さがRDBの大きな特徴で、私たちエンジニアにとっては、今や空気や水のように当たり前のインフラになっていると言えます。
空気のような存在について、それが「なかった」時代を想像することは、簡単なことではありません。しかし、その背景を理解することが、現在のデータベースの置かれている状況を把握するうえで大きな鍵になります。本稿の結論を先取りして言うならば、RDBの登場が「破壊的イノベーション」という、データベースの世界のパラダイムを一新する大変革であったのに対し、NoSQLは――少なくとも現在のところ――RDBを置き換える第二の破壊的イノベーションとは呼べず、RDBと補完的関係にあることが分かるからです。
RDB以前
リレーショナルデータベースが登場する以前のデータベース市場では、階層型と呼ばれるモデルに基づいた製品が主流でした。名前のとおり、データの間にある関係を階層関係として表し、データの位置をプログラムで特定してデータを取得するというモデルです。会社や学校などの組織や機械を構成する部品など、世の中の「データ」は何らかの階層関係を持っていることが多いため、その関係を軸にデータを表現しよう、という洞察に基づいたデータベースです。
代表的な製品はIBMのIMS(Information Management System)で、非常に高い信頼性や性能を兼ね備えた製品であることから、政府や金融機関をはじめとする重要な社会インフラを担う大規模システムに利用されていました。IMSが使われた最も有名なシステムが、1961年から始まったNASAのアポロ計画です。最終製品を構成する部品の階層関係を表したリストをBOM(Bill of Materials)と呼び、製造業ではどのような製品を作るかを問わず、このBOMが設計図と並ぶ重要な情報です(BOMは日本語では「部品表」と呼びます)。IMSはロケットの膨大な部品群を管理するという難解な課題に優れた解を与えたデータベースでした。「でした」と過去形で呼ぶのは不正確で、IMSは、現在においてもなお現役で、世界中で利用されています。
静かな始動
階層型DBがデファクトスタンダートになっていたデータベース界に異変が起きたのは、1968年のことです。最初それは、誰もその後の大変化を予想できないような、ささやかな形であらわれました。きっかけは、IBM の社内報に掲載された一本の論文です。E.F.コッドという40代半ばのエンジニアが書いた「大容量データバンクのための関係モデル」という素っ気無いタイトルの論文は、特に社内で注目を集めることはありませんでした。翌1969年、彼は、社外の学術雑誌に少し書き換えた版を投稿します。この論文に興味を持った外部のエンジニアたちによって、リレーショナルデータベースの「革命」は始まることになります。
まず初期の反応として、1973年、カリフォルニア大学のマイケル・ストーンブレーカーらがIngresの開発に着手します。ストーンブレーカーは、現在ではPostgreSQLの前身となったPostgresの開発者として知られていますが、Postgresは「Post(後の)」+「Ingres」から付けられた名称です。
同じころ、やはりコッドの論文に触発されたラリー・エリソンらがOracleの開発に着手し、1979年に最初のリリースを世に送り出します。また、Ingresの開発に参加していたロバート・エプスタインらが、1984年にSybaseを設立。同社はIngresチームやIBMと人的交流を行うことで、RDBの技術的発展に貢献します。また、Sybaseは1988年から1993年までマイクロソフト社と技術提携を行い、同社のSQL Serverの開発にも寄与しました。その後ものちにIBM社に買収されるInformix、DWH向けデータベースの代表的製品として今も知られるTeradataなどが80年代に登場し、90年代にはRDBは百花繚乱の活況を呈することになります。
リレーショナルデータベースの時代
こうしたRDBの発展の歴史を振り返ると、現在のRDB市場における主要プレイヤーたちは、ほぼ1970年代から80年代に登場していることが分かります。RDBの開発はその後も活発に続けられ、現在でも次々に新しい製品が登場してきていますが、基本的なコンセプトは、現在にいたるまで変更されていません。唯一の例外は90年代に最初のリリースが行われたMySQLで、いかに同製品が短期間で市場を獲得したかが分かります。
| DB | 主要な開発元 | 最初のリリース |
|---|---|---|
| Ingres | カリフォルニア大学 | 1974年 |
| Oracle Database | Oracle | 1979年 |
| DB2*1 | IBM | 1983年 |
| Sybase SQL Server | Sybase | 1987年 |
| MS SQL Server | Microsoft | 1989年 |
| PostgreSQL | カリフォルニア大学 | 1989年 |
| MySQL | MySQL AB*2 | 1995年 |
「ユーザー目線」のシステムを目指して
RDBが従来の階層型DBに比べて優れていた点はいくつか挙げることができますが、シェアを伸ばすうえで最も大きな影響は、ユーザーが使いやすいデータ構造とインタフェースにこだわったことです。すなわち、「テーブル」と「SQL」の発明です。
RDBでは、すべてのデータを「テーブル」というただ一つのデータ形式によって表現します。テーブルは、見た目が「二次元表」に似ているため*3、Microsoft ExcelやGoogle ドキュメントなどのスプレッドシートを使い慣れた人が見ると、データを格納する方法が直観的にイメージしやすいという利点があります。実際、こうした二次元表によるデータ管理は、Excelなどのソフトウェアが登場する前から一般的な方法だったため、RDBが登場した当時の人々にとっても受け入れやすいものでした。
テーブルが画期的だった点は、もう一つあります。実はこちらの方が重要なのですが、それはテーブルにおけるデータの表現において、「データの位置」という概念を一切排除したことです。そのため、テーブルにおいては、あるデータが何行目であるとか何列目であるということは一切意味を持ちません。これもRDB以前のデータベースやスプレッドシートとは大きく異なる点です。これによって、アドレスやポインタといった扱いの難しい位置表現を使わなくてもデータを操作できるようになったのです。
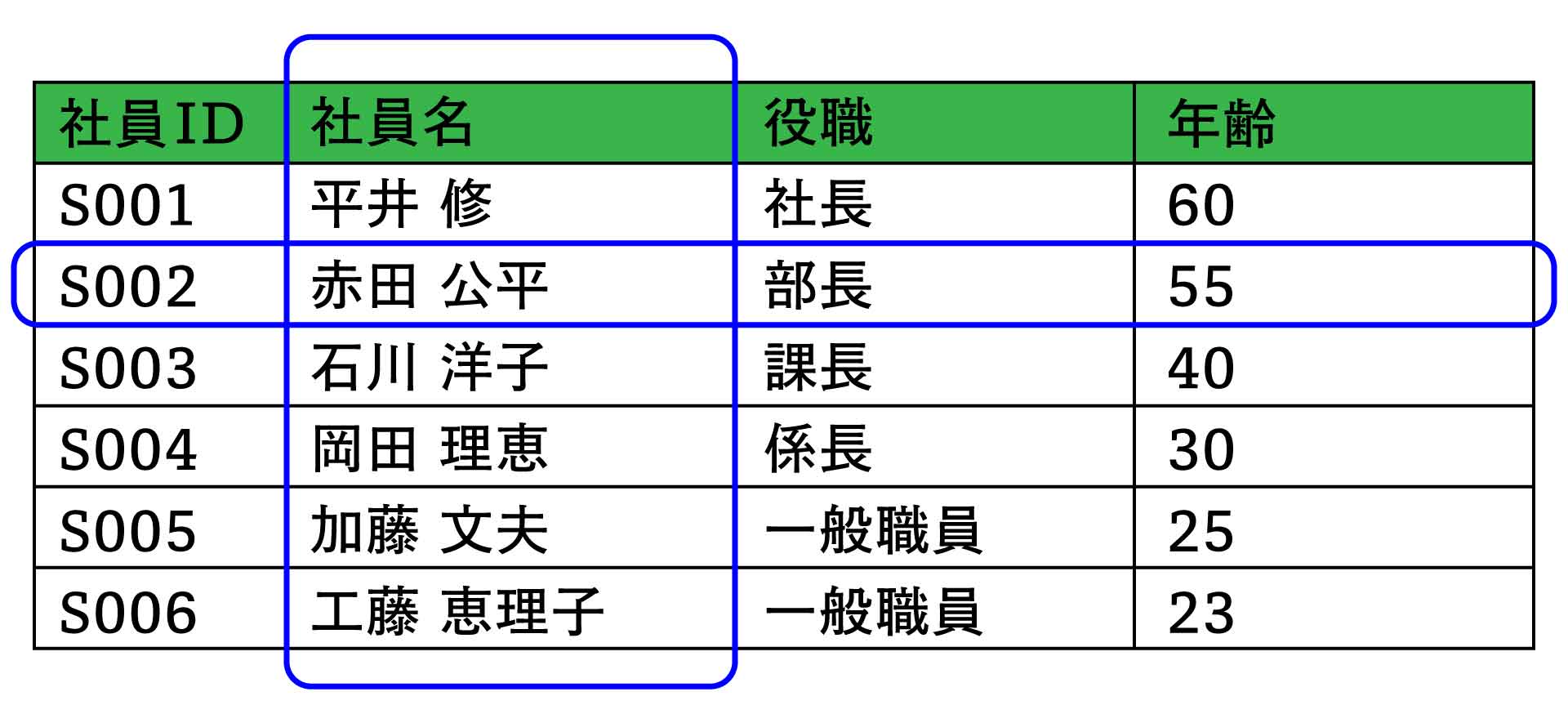
行と列の二次元でデータを表現するが、「~行目」、「~列目」という位置表現は持たない
SQLは、RDBにおいてデータを操作する専用の言語ですが、ユーザーの利便性を特に重視して作られました。SQLは英語に似せた構文を持っているため、特に英語を母国語とする人々にとっては、日常言語でデータを操作できるような感覚を持ちます。
SELECT 社員名 FROM 社員 WHERE 年齢 < 30;
年齢が30歳未満の社員を選択するSQL文。「加藤」さんと「工藤」さんが選択される。
もともとプログラミング言語は、英語圏で発展してきたこともあり、そのボキャブラリは英語由来のものが多くあります。分岐を表す「if」や、ループを表す「for」や「while」といったキーワードは、ほぼすべてのプログラミング言語が共通で持っています。
しかしコッドは、それでもまだユーザーが使うには負担が大きいと考えました。プログラミング言語を使ってデータを操作できるのは、専門の教育を受けたプログラマだけで、エンドユーザーには難しすぎる、というのが彼の洞察でした。特に彼がSQLの原型となる言語を考えたときに腐心したのが、ループをなくすことでした。コッドはRDB考案の功績によって1981年にチューリング賞を受賞するのですが、その記念講演ではっきり「ループをなくすのがRDBを考えた主目的だった」と言っています*4。
“Relational processing entails treating whole relations as operands. Its primary purpose is loop-avoidance, an absolute requirement for end users to be productive at all, and a clear productivity booster for application programmers.”
※強調は引用者
“リレーショナルな処理は関係全体を操作対象とする。その主要な目的は、ループを なくすことである。これはエンドユーザーの生産性を高めるためには必須の要件であった。 そして、これがアプリケーションプログラマの生産性向上にも寄与することは明らかである。”
※筆者訳
事実、プログラミングの経験がある人はご存知だと思いますが、データのアドレスをポインタや配列の添え字で操作したり、ループ処理を記述することは、バグを引き起こしやすいポイントです。前者は不正なアドレス参照による例外をたびたび引き起こしますし、後者は、ループの終了条件を間違えることで無限ループを発生させたり、ループの入れ子を不用意に深くしてしまうことで、全体の見通しが悪くなるといった弊害が、しばしば起こります。こうした問題は、職業プログラマの間でも徐々に認識されるようになり、「きれいなコードを書くための方法論」も発達するようになりますが、RDBは一足飛びに「そもそもそのような問題が原理的に発生しないシステム」を作ることを目指したのです。そして、その試みが大きな成功を収めたことは、2017年の現在、データベースといえばそれは暗黙のうちにRDBを指すというほどに普及したことからも明らかです。
破壊的イノベーションとしてのRDB
上記のようなRDBの発展史を振り返ると、これがパラダイムシフトの一つの類型――破壊的イノベーションであることが分かります。
破壊的イノベーションおよびそれを引き起こす破壊的技術は、ハーバード・ビジネス・スクールの教授クレイトン・クリステンセンの著書『イノベーションのジレンマ』で有名になった経営学の概念で*5、技術的製品の市場におけるパラダイムシフトを引き起こす要因を説明するために使われます。破壊的技術とは、従来の市場における評価基準(多くは信頼性や性能)では劣った評価を与えられるものの、別の評価基準では既存製品より優れているところ(使い勝手、便利さなど)があるため、先進的ユーザー(アーリー・アダプタ)にアピールすることで小規模の市場を獲得するような特徴を持った技術・製品のことです。具体例としては、小型HDD、デジタルカメラ、スマートフォンなどが知られています。
当初は「おもちゃ」、「安かろう悪かろう」という低評価に甘んじていた新技術が徐々に品質改良されることで、既存の主流製品を従来の評価基準でも上回った瞬間に、劇的な市場シェアの逆転が起きるタイミングが訪れます。これが破壊的イノベーションと呼ばれる現象で、圧倒的シェアを持つ優良企業とその主力製品がなぜ新興企業とその(最初は)粗悪品にしか見えない製品に打ち負かされるのか、という理由を説明する有力な理論とみなされています。
RDBの登場とその後の発展を振り返ると、まさに破壊的イノベーションのプロセスを地で行っていることが分かります。ストーンブレーカーらが最初にIngresを開発したときが典型的ですが、彼らは当時としてはローエンドのUNIXマシン上で動くRDBを作りました。性能や信頼性という点では、すでに大規模な社会インフラを支えるメインフレーム上で稼働していた階層型DBとは、信頼性も性能も比べるべくもありません。現在でこそRDBは「高信頼・安定稼働」の代名詞のようになっていますが、初期のRDB製品は不安定で性能も低く、とてもミッションクリティカルな要件にたえる品質は望めませんでした。
こうした従来の評価基準から見れば初期RDBは、アイデアは面白いが実用にはたえない「おもちゃ」でしかありません。しかしRDBには、階層型データベースにはない新しい利点を備えていました。それが、前述の「ユーザーフレンドリ」の精神です。RDBの発展が、Oracle、Ingres(PostgreSQL)、SQL Server、MySQLといった新興の製品と企業によって担われることになったのは、「イノベーションのジレンマ」の構図に照らして考えれば、むしろ納得のいく話です*6。
破壊的イノベーションは繰り返すか
RDBはテーブルというシンプルで直観的なデータモデルと、SQLというユーザーが使いやすいインタフェース言語を武器にデータベースのメインストリームの座を手に入れました。しかしそれは、RDBが万能ということを意味するわけではありません。
1990年代後半から2000年代にかけて、インターネットの発展を主なトリガーとして、システムは多種多様な用途に使われるようになりました。それによって、それまであまり意識されなかったRDBの不便さ、強い言葉を使うならば「限界」が見えてくるようになりました。ここから先は、RDBが抱えるようになった課題と、それに対してどのような解決のアプローチがとられているかを述べたいと思います。これは現在に至るまで地続きのテーマであり、その意味でデータベースの「現代史」にあたります。
課題1 性能と信頼性のトレードオフ
近年、クローズアップされているRDBの大きな問題が、パフォーマンスです。パフォーマンスを構成する要素もいくつかありますが、ここでは簡単に「システムとしての処理速度」と考えてもらってかまいません。データベースは昔から大量のデータを格納していましたが、近年は増大の一途をたどり、RDBはシステムにおいて最もボトルネックになりやすいポイントになっています。
RDBがボトルネックになりやすい原因は主に二つあります。一つが、データを一元管理し、厳密なトランザクション管理をするためにストレージを共有する構成を取る必要があり、ストレージがシングル・ボトルネックポイントになってしまうからです。「スケールアウトができない」と言い換えてもよいでしょう。
もう一つが、SQLの表現力が強力で柔軟であるため、かえって複雑な処理を実行できてしまうことです。特に結合やサブクエリといった複雑な処理を大規模なデータに実行することで大規模なスローダウンを引き起こすことがあります。
課題2 データモデルの限界
RDBがテーブルという二次元表でデータを表すようにしたことは、先述のとおりです。これは現実世界の多くのデータをシンプルに表せる強力な手段なのですが、実は表現することが苦手なデータの種類がいくつかあります。代表的なものは、グラフと非構造化データです。
グラフは数学の用語ですが、定義より具体例を見ればイメージがつかめます。一般的には組織図のような木構造のグラフと、SNSのユーザー間の関係を表すネットワーク構造のグラフに分かれます。前者を非循環グラフ、後者を循環グラフと呼びます。木構造のグラフはまさにRDBが主流の座を奪った階層型DBのデータモデルですが、皮肉なことにRDBはこれを表すのが苦手なのです。
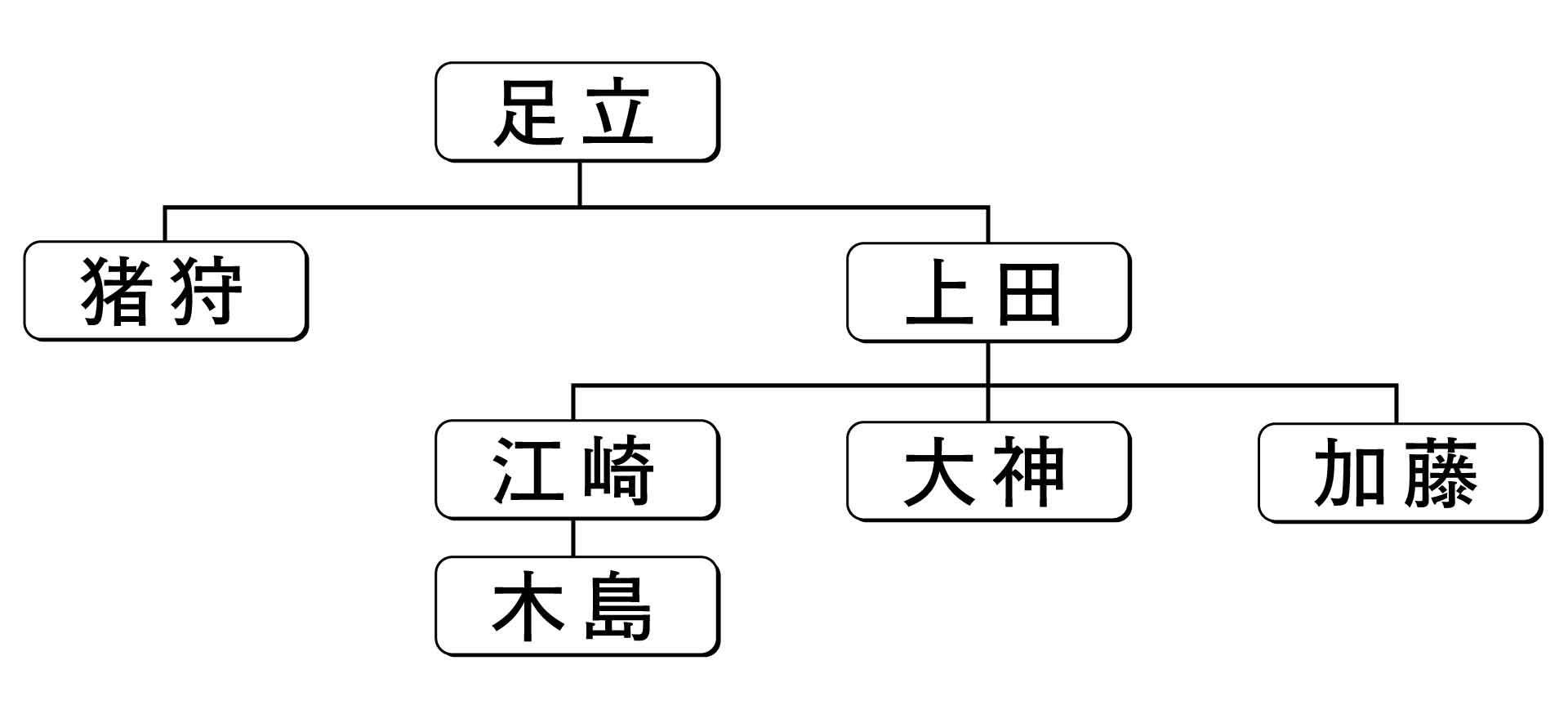
非循環グラフの一種である組織図
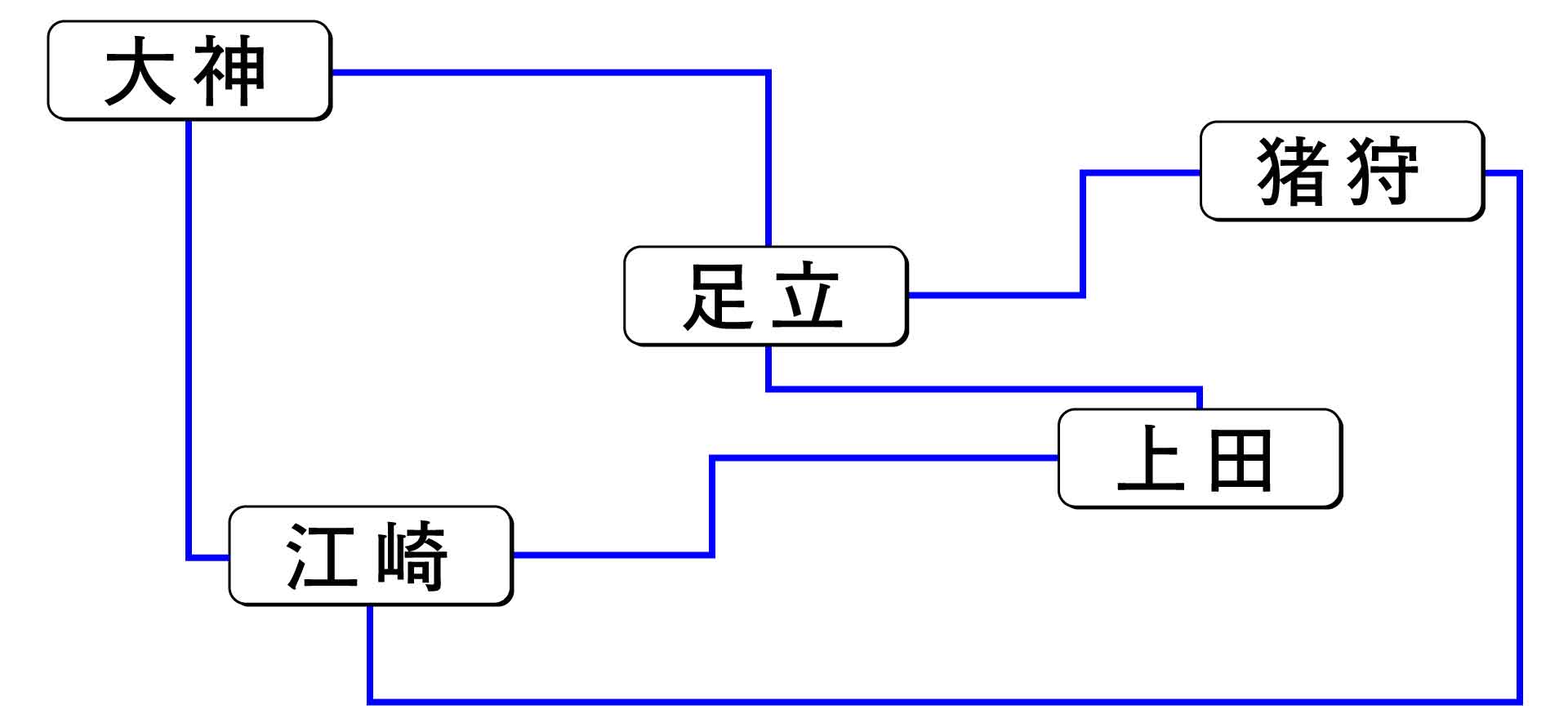
循環グラフの一種であるSNSの人間関係
テーブルは先に見たように、二次元の形をしていますが、階層構造は再帰的な構造を持っています。フラットな二次元表では、この再帰的構造を表すことが非常に難しいのです(できない、というわけではないのですが、かなり難しい。RDBで階層構造を表す方法論については、参考文献を参照してください)。
一方の非構造化データも、定義よりも具体例を見る方が早いでしょう。というのもこの言葉は、RDBのテーブルに格納しやすいデータ(CSVなど)を最初に「構造化データ」と呼んでいたのに対して、テーブルでは扱いにくいデータをひとまとめに「非構造化データ」と呼ぶようになったところがあるからです。
非構造化データの代表例は、XMLやJSONです*7。どちらもインターネット上でデータをやりとりするフォーマットとして頻繁に利用されますが、これらは何のタグがどういう情報を表すかという規則は定まっているものの、個別のドキュメントがどういうタグを何個含み、一つのタグがどれだけのサイズの情報を持つか、ということは決める必要がありません(もちろん、個別のビジネスルールとしてそこまで決めることもありますが、一般性はありません)。こうしたデータは、手続き型のプログラミング言語でループと分岐を使って扱うにはそれほど苦労しませんが、事前に列の意味と数を決める必要があるテーブルとは相性が悪くなります。一般に、RDBにおけるテーブルの構造はある程度静的で、システムを運用する中で動的に変更することは想定していないからです。テーブル定義やテーブル間の関連を変えるというのは、かなり大規模な改修になることを意味するため、経験豊富なエンジニアほど身構えるものです。
{
"名前": "山田 太郎",
"住所": "北区赤羽",
"趣味": ["野球", "山登り", "自転車"]
}
JSONのサンプル。「名前」、「住所」、「趣味」という三つの要素(オブジェクト)が記述されている
趣味が複数あることを配列で表現している
これ以外の要素を記述することや、配列の要素数も増減可能で、自由度が高い
これら二つのRDBの抱える課題に対して、対処は二通りに分かれます。一つはRDBの機能を高度化することで対応する方法。もう一つがRDB以外のデータベースを利用することです。前者も色々と興味深いテーマがあるのですが、本稿では主に後者のアプローチについて取り上げます。すなわち、一般にNoSQLと呼ばれる製品群についてです。
NoSQLの種類と解決策
NoSQLという技術や製品の名称は定着した感がありますが、実はあまり明確な定義がありません。当初はNoRelという言葉も提唱されましたが、これが端的に表すように「RDBとは異なるアーキテクチャやデータモデルに基づくデータベース」という程度の緩い定義です。しかし、いずれも基本的には先に挙げたパフォーマンスとデータモデルの問題に対処することを目的にしています。
パフォーマンス問題の解決
RDBのパフォーマンスの問題を解決する手段として考えられた方針は、大きく以下の二つです。
- データモデルを単純化し、複雑なデータ操作を制限する
- シングル・ボトルネックポイントをなくしてスケールアウト可能にする
これらは、「厳密なトランザクション制御によるデータ整合性」と「SQLで実現していた高度なデータ操作」というRDBが持つ利点をある程度諦める代わりにパフォーマンスを追求するというトレードオフ(交換条件)を許容するアプローチです。
前者の方針を実現したNoSQLの典型が、KVS(Key-Value Store)と呼ばれるものです。KVSも、データモデルとしてはテーブルの一種とみなせなくもないのですが、「キー」とそれによって一意に決まる「値」という、非常にシンプルな構造しか持たず、それゆえ一意キーによる高速な検索性能を実現することを目的としています(代わりに結合など高度な処理はできません)。プログラミングに慣れた人から見れば、連想配列を基本構造とするデータベースに見えるでしょう。連想配列は配列の添え字に数字以外(文字列など)を使う配列です。
| eng | ja |
|---|---|
| orange | みかん |
| strawberry | いちご |
| watermelon | すいか |
| lemon | レモン |
| grape | ぶどう |
| banana | バナナ |
連想配列FruitsFruits['orange'] = 'みかん'のように、数値以外を配列の添え字に利用する
これはまさにテーブルにおけるキーによる値の検索と同じ
Redisやmemcachedなどの製品がKVSの機能を備えています。こうした単純化したデータ構造を、さらにオンメモリ化するなど、パフォーマンスを向上させるオプションを用意している製品もあります。
また、KVSを含むNoSQLの製品の多くは、複数のデータベースのインスタンスでクラスタを構成し、スケールアウトを可能にすることでパフォーマンス向上を図っています。
非構造化データに対する解決
二つ目の非構造化データの扱いに対する解決策として登場したNoSQLの一つが、ドキュメント指向型DBと呼ばれるタイプです。JSONやXMLのような自由度の高いドキュメントを、RDBのテーブルに変換することなくネイティブに扱う機能を持ちます。製品としては、MongoDB、CouchDBなどが該当します。また、先にRDBが扱いにくいデータモデルとしてグラフがあるという話をしましたが、これを扱うことに重点をおいたグラフDBも近年開発が進んでおり、Neo4jなどの製品が登場しています。
NoSQLはRDBを置き換えるか
このように、とりわけ2000年代の後半から盛んに従来のRDBの制約に対する新たなアプローチとしてNoSQLの製品群が登場してきたわけですが、ここまで読み進んできた読者には、一つの疑問が生じたのではないかと思います。それが、「NoSQLは、RDBを置き換える新たな破壊的技術だろうか?」というものです。この疑問に対する筆者の回答は、「現在のところそれはない」です。理由は二つあります。
一つ目の理由は、NoSQLの多くがトレードオフを発生させていることです。確かにNoSQL製品群は、RDBの欠点を補う目的で作られており、その意味では「新たな評価基準」においてRDBを凌駕しうるのですが、一方で「ACID」のスローガンでよく知られるトランザクション管理によるデータ整合性や耐久性、あるいはSQLで実現していた高度なデータ操作、テーブル間の関連を表す機能などを(承知のうえで)犠牲にしています。破壊的イノベーションが起きるには、こうした従来の評価基準においてもNoSQLがRDBを上回る必要がありますが、それが起きない間は、大勢としては、RDBとNoSQLは相互補完的な関係にとどまるでしょう。NoSQLが登場した当初は文字どおり「NO SQL」として解釈され、RDBのカウンターであるような印象を与えたのに対し、近年では「Not Only SQL」という解釈の方がより実態を表している、と言われるのも、一つにはこうした補完関係を反映しているのだと思います。
もう一つの理由は、RDBの方も、NoSQL的な機能を徐々にサポートするようになっており、両者の差が埋まり始めていることです。Oracle、Db2、MySQL、PostgreSQLなど主要なRDB製品は、JSONやXMLを扱う機能をサポートするようになっており、両者の区別は徐々に曖昧になってきているようにも見えます。OracleやDb2などはグラフデータへの対応もはじめており、そのような動きを見ると、NoSQLというのは、将来的にはRDBの機能の一つを指す言葉になることも、十分に考えられます。
まとめ
本稿では、RDBを中心に技術的な歴史を振り返ることで、大きな技術的変化が起きるのはどのようなときかというテーマについて考察してきました。本稿の内容をまとめると、以下のようになります。
- RDBが階層型DBを置き換えたのは、破壊的イノベーションの好例と呼ぶべき現象だった。RDBは、従来プログラマやエンジニアが扱うものとされていたデータベースを、エンドユーザーが扱えるものにしようした点が画期的だっった。
- 破壊的イノベーションは、従来の評価基準では測れない新機能を持った製品が引き起こすが、新機能があるだけでは不十分で、従来の評価基準でも既存の製品を上回る必要がある。トレードオフが発生する間は破壊的イノベーションは起きない。
- 2000年代に入ると、RDBの欠点であるパフォーマンスのスケーラビリティや非構造化データの扱いといった問題がクローズアップされるようになり、それに対する解決策としてNoSQLの製品群が登場してきた。しかし、第二の破壊的イノベーションというよりは、RDBと補完的関係として共存する可能性が高い。
参考文献
- クレイトン・クリステンセン『イノベーションのジレンマ 技術革新が巨大企業を滅ぼすとき』(翔泳社、2001)
クレイトン・クリステンセン、マイケル・レイナー『イノベーションへの解 利益ある成長に向けて』(翔泳社、2003) - 破壊的イノベーションという概念を使って技術的市場のパラダイムシフトを分析した古典的著作。本稿でもこの概念を全面的に援用させてもらいました。テーマは経営者向けですが、エンジニアやプログラマであっても自分が学んでいる/使っている技術が市場的にどのように位置づけられるのか、今後どのような技術的な変遷の可能性があるかを見通せるようになるために、読んで損はありません。
-
<

- 全米研究評議会(NRC)による「コンピュータ分野におけるイノベーションはどのようにして実現したか」をテーマとしたレポート。第6章でRDB黎明期の歴史が簡潔にまとめられています。本稿では取り上げませんでしたが、実はデータベースの歴史では国家機関(特に軍関係)が重要な役割を果たしているという面白い洞察が語られています。IMSがアポロ計画という大規模公共事業のために作られたことは本稿でも述べましたが、RDBにおいても、Ingresが軍関係機関から出資を受けたり、OracleがCIAのプロジェクトから開発をスタートさせるなど、データベースは軍事機関と浅からぬ縁を持っています。「国家がイノベーションのパトロンだった」という、クリステンセンとは異なる視点からの分析は興味深いものです。
- 本橋信也、河野達也、鶴見利章、太田 洋『NOSQLの基礎知識 ビッグデータを活かすデータベース技術』(リックテレコム、2012)
- やや刊行から時間が経過したため、情報が古くなったところはありますが、NoSQL製品について単に個々の製品や特長の紹介だけではなく、それらがどのような課題認識から登場し、どのようなアーキテクチャで解決を図ろうしているか、という全体像を与えてくれます。NoSQLを俯瞰的に知りたいと思ったときの最初の一冊として最適です。
- ジョー・セルコ『プログラマのためのSQLグラフ原論 リレーショナルデータベースで木と階層構造を扱うために』(翔泳社、2016)
- RDBで木構造を扱う選択肢について考察した書籍です。筆者が翻訳したのですが、おそらくこのテーマについて書かれた本としては最も網羅的です。同著者の『プログラマのためのSQL』のスピンオフ作品であり、それだけに読むにはSQLの知識がある程度要求されます。
執筆者プロフィール
編集:薄井千春(ZINE)
2017年、DB2は「Db2」に名称が変更された。↩
MySQL ABはのちにサン・マイクロシステムズに買収され、さらにサン・マイクロシステムズがOracleに買収されたことで、現在MySQLはOracleが保有している。↩
このようなもってまわった言い方をするのは、厳密には二次元表とテーブルは、異なる特性がいくつかあり、同じ概念というわけではないからです。しかし、SQLでそれほど複雑な処理を行わなければ、テーブルを二次元表としてイメージしても、それほど大きな問題はありません。↩
The 1981 ACM Turing Award Lecture Relational Database: A Practical Foundation for Productivity↩
クレイトン・クリステンセン『イノベーションのジレンマ―技術革新が巨大企業を滅ぼすとき』(翔泳社、2001)↩




