
PostgreSQLとMySQL、使うならどっち? データベース専門家が8つの視点で徹底比較!
オープンソースのデータベースとしてよく比較されるPostgreSQLとMySQL。どんな長所・短所があるのでしょう? それぞれの専門家による対談で明らかにします。
エンジニアとして働いていると必ず直面する悩み。それは、「どのリレーショナル・データベース(以下、RDB)を選ぶのが最善なのか?」です。
RDBごとに長所と短所は異なっています。そのため自社サービスにマッチしないRDBを選んでしまうと、それがボトルネックとなり開発・運用にトラブルが生じるケースは少なくありません。
なかでもよく比較検討されるのが、PostgreSQLとMySQL。ともにオープンソースRDBのデファクトスタンダードであり、高い性能と数多くの機能を持っています。
では、両者は具体的にどのような長所・短所があるのでしょうか。それを徹底解剖すべく、PostgreSQLの専門家である澤田雅彦さんとMySQLの専門家である田中翼さんの対談を実施。各機能ごとに特徴を比較しました。
RDBについて日本トップレベルの知見を持つ2人の意見。ぜひ、PostgreSQLとMySQLを選定する際の参考にしてください!
- 澤田雅彦(さわだ・まさひこ)

- 2012年、NTTデータに入社。以降、PostgreSQLに関する業務に従事し、主にPostgreSQLの本体開発、技術支援および、国内外問わずさまざまなカンファレンスにて講演を行っている。2016年より、NTT OSSセンタに勤務。PostgreSQLコミュニティでは、Contributorとしてレプリケーション、VACUUM、分散トランザクション機能の開発やバグ修正を通してコア開発に貢献。

- 【比較ポイント(1)】DDL操作のノンブロッキング
- 【比較ポイント(2)】DML文のパフォーマンス
- 【比較ポイント(3)】テーブル結合(JOIN)のアルゴリズム
- 【比較ポイント(4)】トランザクション処理の分離レベル
- 【比較ポイント(5)】ストアドプロシージャ、トリガー
- 【比較ポイント(6)】レプリケーションの論理型と物理型
- 【比較ポイント(7)】どちらかのDBだけにある便利機能
- 【比較ポイント(8)】データ型のゆるさ、型変換、文字列比較
- 【結論】どっちをどんなサービスに使うべき?
【比較ポイント(1)】DDL操作のノンブロッキング
―― 本日はよろしくお願いします。まずDDL(データ定義言語)について比較したいと思います。MySQLから教えてください。
田中 MySQLは、多くのDDL操作をノンブロッキング(トランザクション中でもテーブルへのブロックがかからない)で実行できるというメリットがあります。この機能はMySQLバージョン5.6から実装されました。
また、対象のカラムのみをスキャンするようなALTER TABLE(カラム名を変更する、カラムを追加するなど)の場合、テーブルをゼロからリビルドしないため処理速度が速く、サーバー全体の負荷が低減できるという特徴もあります。
―― 一方のPostgreSQLは、ALTER TABLEなどのDDL操作はノンブロッキングではないのでしょうか?
澤田 そうですね。どのようなDDL文を発行するかによっても変わってきますが、たとえばカラムを追加するなどテーブルを書き換える操作は、テーブルへのブロックが発生してしまい、参照もできなくなってしまいます。
―― とはいえ、本番環境のDBに対してALTER TABLEをかけたいケースもあるかと思います。その際には、どのような方法を取るべきなのでしょうか?
澤田 pg_repackというメンテナンス用の外部ツールが使用されることが多いです。それを使えば、REINDEXや一部のALTER TABLE操作を最小限のロックで実行できます。


―― PostgreSQLを保守・運用している方は、そのツールの存在をぜひ覚えておきたいですね。
【比較ポイント(2)】DML文のパフォーマンス
―― 次は、各種のDML(データ操作言語)を比較していきたいと思います。まず、SELECT文ですが。
田中 シンプルなSELECTなら、MySQLもPostgreSQLもそれほど変わらないと思います。いい勝負なんじゃないでしょうか。
澤田 そうですね。SELECTはあまり変わらないです。
田中 ただし、大量データのソートが必要なSELECT(ORDER BYをしたうえで、テーブルの全データを取得するなど)はMySQLだと遅くなってしまいます。
なぜなら、PostgreSQLと比較するとMySQLはソートのアルゴリズムがそれほど優れていないためです。MySQLは、大量データをソートすることを、基本的にユースケースとして想定していません。
―― どのような条件のSELECTなら、MySQLは強みを発揮するのですか?
田中 MySQLは、新規10件とか100件のデータ(TOP n レコード)を取得するような、たとえばTwitterのようなユースケースに特化しています。そういった場面では、PostgreSQLよりも速いです。
―― 他のDML文についてはどうですか? たとえばUPDATEは。
田中 UPDATEは、MySQLの方がパフォーマンスに優れていますね。
澤田 私もそう思います。
―― それはなぜでしょう?
澤田 PostgreSQLは追記型アーキテクチャといって、UPDATEする際にはINSERTに近い処理が実行されています。どういうことかというと、変更前の行に削除フラグのようなものを立てたうえで、変更後のデータを持った新しい行を追加しているんです。
田中 一方でMySQLは、UPDATE対象となる行の値を直接上書きしています。文字通りに“更新”しているんです。
―― そのアーキテクチャであれば確かにMySQLの方がUPDATE処理は早くなりそうですね。それでは、DELETEに関してはどうでしょうか?
田中 かつて、MySQLにはDELETEが遅いという欠点がありました。これは、データ削除後にセカンダリーインデックス(クラスタインデックス以外のすべてのインデックス)を同期処理で貼り直しており、その処理に時間がかかっていたためです。
ですが、バージョン5.5でかなり解消されました。セカンダリーインデックスの非同期のチェンジバッファ(セカンダリーインデックスエントリへの変更をバッファリングしておき、サーバがアイドル状態にあるときなどに変更内容をマージする仕組み)が効くようになったため、以前ほど「DELETEが遅い」ということはなくなりました。

【比較ポイント(3)】テーブル結合(JOIN)のアルゴリズム
―― 次はテーブル結合を比較します。よく使われるテーブル結合のアルゴリズムには「ネステッドループ結合(Nested Loop Join)」「ハッシュ結合(Hash Join)」「ソートマージ結合(Sort Merge Join)」の3種類がありますが。
田中 MySQLは、基本的にネステッドループ結合しかサポートしていません。なぜなら、MySQLは「複雑なアルゴリズムはなるべくサポートしない」という設計思想に基づいているからです。
―― どうしてMySQLはそういう設計思想になったのですか?
田中 Webアプリケーションに使われるようになる前に、MySQLはもともと組み込み系のシステムで使われていたことに起因しています。
組み込み機器の非常に容量が小さいディスクやメモリの中でDBを稼働させる必要があり、複雑なアルゴリズムをなるべくそぎ落とす方針で設計されてきたんです。
―― 納得ですね。一方のPostgreSQLはどうですか?
澤田 PostgreSQLは、3種類ともサポートしています。
―― それぞれの結合パターンは、どのようなユースケースに向いているのでしょうか?
澤田 結合対象のデータ量が多いときには、ハッシュ結合やソートマージ結合を使った方がいいと思います。そのデータが既にソートされている場合にはソートマージ結合の方がよく、そうでなければハッシュ結合がおすすめです。
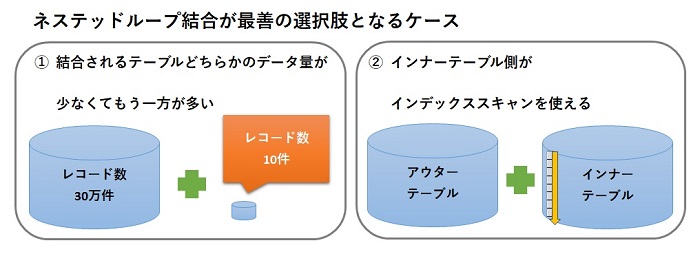
ネステッドループ結合が最善の選択肢となるのは、結合されるテーブルどちらかのデータ量が少なくてもう一方が多いようなとき。もしくはインナーテーブル側がインデックススキャンを使える場合などですね。これは、MySQLにおいても同様です。
【比較ポイント(4)】トランザクション処理の分離レベル
―― 次は、トランザクション処理についてお聞きします。PostgreSQLとMySQLでは、それぞれのデフォルトのトランザクション分離レベル(トランザクション処理が複数同時に実行された場合に、どれほどのデータ一貫性・正確性で実行するかを定義したもの)が異なっているという話を聞いたことがあります。
田中 そうですね。MySQLは、デフォルトがREPEATABLE-READとなっています。この方式だと、読み取り対象のデータが途中で他のトランザクションから変更されてしまう心配はありません。
ただし、ファントムリード(並行して動作している他のトランザクションが追加したデータが途中で見えてしまう現象)が起こる可能性があります。MySQLでは、このファントムリードを避けるため、ネクストキーロックという仕組みを採用しています。
―― それはどのようなものですか?
田中 トランザクションが走っている最中にレコードが増えないよう、主キーのインクリメント先の値までロックをかけるというものです。この仕組みによってデータの堅牢性は保たれるのですが、同時にこれが原因で意図せぬロックがかかり、トラブルの原因になってしまうこともあります。
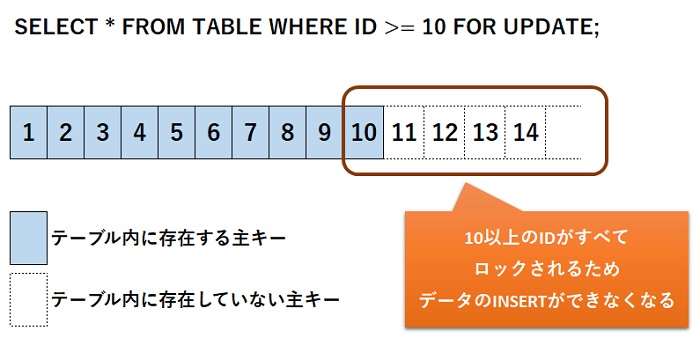
たとえば、SELECT FOR UPDATEなどでWHERE句に「<(不等号)」を使用し、「IDが10以上」のレコードを検索したとします。すると、10以上のキーが全てロックされてしまうんです。
こうなってしまうと新たな主キーが生成できず、INSERTできなくなってしまいます。この仕様はけっこうハマりどころなので、注意しておいた方がいいでしょう。
ロック競合を減らすため、トランザクション分離レベルを、より低いREAD-COMMITTED(常にコミット済みの最新データを読み取る形式)に変更して運用するケースもあります。
―― PostgreSQLでは、デフォルトのトランザクション分離レベルは何ですか?
澤田 READ-COMMITTEDです。この方式の場合、ファントムリードやノンリピータブルリード(同じトランザクション中でも同じデータを読み込むたびに値が変わってしまう現象)が起こる可能性があるため、運用ではその点に気をつける必要があります。
また、PostgreSQLではトランザクション分離レベルをREPEATABLE-READに変更したとしても、ネクストキーロックを取らず、違う方法でファントムリードを防いでいます。そのため、ロック競合を防ぎやすいという点はMySQLよりも優れているかもしれません。

【比較ポイント(5)】ストアドプロシージャ、トリガー
―― ストアドプロシージャについてはどうでしょうか?
澤田 PostgreSQLは、SQL以外にもPythonなどを利用した外部プロシージャが使えるのは利点だと思います。
田中 MySQLはSQLのみですね。また、MySQL単体ではストアドプロシージャのステップ実行ができないという欠点があります。
―― トリガーについては?
田中 MySQL 5.6以前では、1テーブルにつき最大6つまでしかマルチトリガーが仕掛けられないという欠点がありました。また、BEFORE INSERT TRIGGERが1テーブルにつき1個しか仕掛けられなかったため、かなり制限がありましたね。
現在では、トリガー個数の制限はなくなっています。ただし、MySQLのトリガーはFOR EACH ROWしかなくてFOR EACH STATEMENTがないため、その点は考慮しておく必要があります。
【比較ポイント(6)】レプリケーションの論理型と物理型
―― 次はレプリケーションについて。
田中 MySQLの場合、レプリケーションは論理型(SQL文そのものをコピー)または物理型(変更後の行イメージをコピー)のいずれかを選べるようになっています。従来は論理型がデフォルト設定だったんですが、MySQL 5.7以降では物理型がデフォルトになりました。
澤田 PostgreSQLは物理型のみですね。ただ、現在ベータ版としてリリースされているバージョン10からは論理型も使えるようになっています。
―― MySQLで「物理型がデフォルトになった」という話がありましたが、論理型は何か欠点を抱えていたのでしょうか?
田中 論理型は良くも悪くも柔軟なところがあって、たとえばマスターのテーブルとスレーブのテーブルのスキーマが多少違っていたとしても、SQLさえ通ってしまえばエラーにならないんです。
その仕様を利用してカジュアルな運用ができるという良さはあるんですが、マスターとスレーブに差異があっても検知できない可能性があるのは、データ堅牢性の面から見ると課題があります。このため「安全側をデフォルトにする」という思想から、物理型がデフォルトになったんです。
【比較ポイント(7)】どちらかのDBだけにある便利機能
―― どちらかにしかない便利な機能はあるでしょうか?
田中 これまでは、部分的に切り出した結果セットに集約関数を適用できるウィンドウ関数や、SELECT文の実行前にサブクエリを作成できるWITH句など、集計に適した機能がPostgreSQLにだけありました。このため、分析系の処理はPostgreSQLの方が強かったんです。
ただ、ウィンドウ関数もWITH句も、MySQLでもバージョン8.0から導入される予定です。
―― となると、分析系処理では将来的に違いがなくなってくるかもしれないですね。他に、一方にあってもう一方にはない機能はありますか?
澤田 パラレルクエリですかね。これは、処理速度をより速くするために、複数のCPUを活用してクエリを実行するというものです。
それから、多くのエンジニアがPostgreSQLを選択する理由として挙げるのが、PostGISというサードパーティのOSSツールですね。地図や幾何データの情報を扱うためのものです。MySQLのものより機能が豊富で、PostgreSQLが持つアドバンテージのひとつだと思います。


田中 何かPostgreSQLでうらやましい機能あったかな。そうだ、pg_basebackupがすごく便利ですよね。オンラインかつリモートでデータベースクラスタのベースバックアップが取れるので。
MySQLの場合は、オンラインでの物理バックアップの手段がXtraBackupもしくはEnterprise Backupしかないので、オンラインかつリモートではベースバックアップを実行できないんです。

【比較ポイント(8)】データ型のゆるさ、型変換、文字列比較
―― 最後は、データ型のゆるさ(暗黙的に実施される型変換や、文字列比較の厳格さなど)について聞かせてください。
田中 バージョン5.6以前のMySQLでは、データ型のゆるさが問題になることが多かったです。でも、5.7からは全体的にカタい方に修正されて、以前よりはデータ型が原因でバグが発生するケースが少なくなりました。
とはいえ、いくつか気をつけるべきユースケースが存在して、たとえばこれ。
(int) 1 = (string) '1' = (string) '1Q84'
MySQLの場合、この3つは「同じ値である」と認識されるんです。
―― えっ!? それはどうしてですか?
田中 なぜかというと、数字の「1」と文字列の「1」を比較するとき、暗黙的に文字列から数字への型変換がされます。だから、1つ目と2つ目は同じ値として認識されるわけです。
そして、数値の「1」と文字列の「1Q84」を比較する際にも、「1Q84」を数値へ暗黙的に型変換します。すると何が起こるかというと、データを前方から読みこんでいって、数値として認識できる部分まで型変換するんです。
―― なるほど。つまり「1Q84」の「1」までが読みこまれると。
田中 そう。だから「同じ値である」と認識されてしまうわけですね。
他にも暗黙的に型変換されるケースがあって、たとえば日付型の「2017-07-01」から数字の「1」を引くと「20170700」という整数が返ります。バグの原因になりやすい仕様なので、MySQLを使う場合は気をつけた方がいいと思いますね。
―― 型変換について、一方のPostgreSQLはどのような仕様ですか?
澤田 PostgreSQLは、各種の型変換に関してはかなりカタい方に寄せています。先ほど田中さんがおっしゃったような文字列型から数値型への暗黙的な型変換は起こらないので、SQLを書く人が明示的にキャストしなければいけないですね。もしくは、暗黙型変換をユーザが定義することで対応する方法もあります。
―― 文字列比較はどうですか?
田中 MySQLは、デフォルト設定では文字列比較において大文字小文字の区別をしないです。また、バージョン8.0からは、デフォルト設定だと濁音と半濁音を区別しなくなります。「は」と「ぱ」と「ば」はイコールになりますし、「びょういん」と「びよういん」もイコールになります。
―― その仕様なのは、何か理由があるんですか?
田中 Unicodeの仕様に依存しているんです。Unicodeは、照合順序(並べ替え)の厳格さの設定が、レベル1からレベル4まで段階的に分かれています。
「は」と「ぱ」と「ば」を区別するためにはレベル2以上の比較が、「びょういん」と「びよういん」を区別するためにはレベル3以上の比較が必要なのですが、MySQLのデフォルト設定では1レベルしか使わない比較になっています。
レベルを上げれば文字列の区別は正確になるんですが、処理は重たくなってきます。MySQLは「シンプルな処理を高速にする」という設計思想に基づいてつくられているので、処理スピードを捨ててまで文字列比較の厳格さを取るようなことはしないんです。
―― なるほど。そういった仕様からDBの設計思想がうかがえるのは非常に面白いですね。
【結論】どっちをどんなサービスに使うべき?
―― 最後に総括として、PostgreSQLとMySQLがそれぞれどのようなサービスに向いているかを語ってもらえますか?
澤田 PostgreSQLは「多機能であること」が最大の利点なので、その特徴が生きるようなシステムには向いていると思います。たとえば、Oracle Databaseからの移行やSIer系の企業で使われるケースが多いという印象を個人的には持っています。
あとは、分析系のシステムでもよく使われます。ただこれも前述のようにMySQLの分析機能が徐々に充実してきているため、将来的に差は少なくなってくるでしょう。
―― MySQLの方はどうですか?
田中 基本的には、シンプルなWebサービスに向いていると思います。
一定数の結果セットを取ってきて、そのデータを表示するといった感じの。たとえばTwitterのように、タイムラインの先頭部分を表示して、下にスクロールすると次のデータを読みこむようなサービスは、MySQLには特にマッチしていると思います。
とはいえ、バージョンが上がるごとにPostgreSQLもMySQLも高性能になってきているので、結局は使いたい方を使えばいいんじゃないでしょうか。
―― 最後はとても平和的な結論になりましたね。今回はどうもありがとうございました!

取材:中薗昴(サムライト)/写真:小堀将生
技術監修:松浦隼人




