
Haskellらしさって?「型」と「関数」の基本を解説!【第二言語としてのHaskell】
第二言語としてHaskellを学ぶ道案内。開発環境の準備から、Haskellらしいプログラミングの考え方まで、Haskell-jpのigrepさんが丁寧に解説します。
こんにちは。Haskell-jpの山本悠滋です。
この記事では、すでにプログラミング経験のある方向けに、第二言語としてHaskellを学ぶ道案内をしていきます。
環境の準備や、自明なサンプルプログラムの紹介にとどまらず、Haskellらしいプログラミングの考え方も伝えていく予定です。
Haskellについて
Haskellというと、「関数型」というキーワードが思い浮かぶ方も多いと思います。 確かにHaskellは、すべての関数がカリー化されており、それらを組み合わせてプログラムを書いていく関数プログラミングがしやすい言語です。 しかしHaskellは、関数型言語であると同時に、厳密かつ柔軟な型システムを持つ静的型付き言語でもあります。 さらに、その強力な型によってプログラムの副作用までも管理できる仕組みを備えています。 これらの特徴を、バグが少なく堅牢でメンテナンス性の高いソフトウェア作りに活用できるのが、Haskellというプログラミング言語だといえるでしょう。
実際、Haskellは、信頼性とスピードが求められる複雑なシステムやプロジェクトで数多く採用されています。 Facebookにおけるシステム悪用対策の基盤であるSigmaや、 朝日ネットの認証サーバーは、それなりに大きな規模でのHaskellの実用例として有名です。 Tsuru Capitalをはじめ、金融業界でも利用されています。 Haskellでプログラムを書いているというと、よく「何に使えるの」と聞かれるのですが、汎用プログラミング言語なのでだいたいの用途には利用できるのです。
現在、Haskellで書いたプログラムを実行するときにもっともよく利用されているのは、GHC(Glasgow Haskell Compiler)というコンパイラです。 GHCでは、標準のHaskellをさらに便利に使えるように、さまざまな言語拡張も提供されています。
2017年7月22日にGHC 8.2.1がリリースされていますが、本記事で説明するHaskellプログラムはすべて、「Haskellの開発環境を整備する」のセクションで解説するツール「stack」でインストールできるGHC 8.0.2(執筆時点)で動作を確認しています。
- Haskellについて
- Haskellの開発環境を整備する
- 試しに使ってみましょう(Haskellで関数の定義と呼び出し)
- Haskellの基本的な型に親しもう(GHCiをもっと使いこなしつつ)
- 動くアプリケーションを作ってみましょう(GHCを使った実行ファイルのビルド)
- もうちょっと凝った関数を作ってみましょう(次回予告)
Haskellの開発環境を整備する
Haskellの開発環境を整備する方法はいくつかありますが、今回は初めて環境を構築する方におすすめな、「stack」というツールを使用した方法を紹介します。 stackのインストールと設定方法はstackの公式サイトに一通り載っていますが、英語ということもあるので、この記事でも説明しておきます。


LinuxやMacでインストールする
LinuxやMacでstackをインストールする方法は簡単です。 下記のようにcurlコマンドでダウンロードしたシェルスクリプトをそのまま実行すれば、使用しているOSを自動で検出して、インストールしてくれます。
$ curl -sSL https://get.haskellstack.org/ | sh
Windowsでインストールする
Windowsでstackをインストールする場合も基本的には単純で、公式のドキュメントの「Windows」セクションに用意されているリンクから適切なインストーラーをダウンロードし、実行しましょう。また、Chocolateyをお使いの方は、choco install haskell-stackでもインストールできます。
Windowsでstackをインストールする場合には、次の点に注意してください。
Windowsのユーザー名が日本語になっていると失敗する
Windowsユーザーの方が上記の手順でstackを用意する際、OSのユーザー名が日本語となっていると、GHCのインストール時にエラーになってしまう場合があるそうです。 特にWindows 8やWindows 10では、そうと気づかないうちにユーザー名が日本語になってしまっていることが多いので、確認しておきましょう(筆者も長年のWindowsユーザーですが、たまたまこの問題に出くわすことはありませんでした)。
下記の記事などを参考に、新しくWindowsのユーザーを日本語以外で作り直して試してみるほうがいいかもしれません。
新しくWindowsのユーザーを作りたくない、という場合には、環境変数LOCALAPPDATAを変更して日本語を含まないパスに変えるという手もあります。
stackはLOCALAPPDATAに書かれたディレクトリーのPrograms\stack以下にインストールしたGHCを置きますが、このLOCALAPPDATAに日本語のパスが含まれているとエラーになるようです。
LOCALAPPDATAは、デフォルトでWindowsのユーザーフォルダーのパス(つまり C:\Users\[ユーザー名])より下に作られるので、ユーザー名に日本語が含まれていると問題になります。
環境変数LOCALAPPDATAを変更し、日本語を含まないパスに変えればよさそうですが、
LOCALAPPDATAはstackのほかにもさまざまなアプリケーションが使用しているディレクトリーなので、変更の際は注意が必要です。
影響を最小限にとどめるために、バッチファイルを作り、環境変数PATHにおけるより優先度の高い位置にあるディレクトリーに置いてラップする、という手もあります。
以下は、LOCALAPPDATAをC:\foobarに設定してstackを実行する場合の、ラップ用バッチファイルの例です。
@echo off set LOCALAPPDATA=C:\foobar [実際にstackがインストールされているパス]\stack %1 %2 %3 %4 %5 %6 %7 %8 %9
これをstack.batという名前で保存して、環境変数PATHの先頭のパスに配置すれば、stackコマンドを実行するときだけLOCALAPPDATAを変更することができます。
試しに使ってみましょう(Haskellで関数の定義と呼び出し)
ここまでの方法でstackをインストールできたら、早速動かしてみましょう。……とその前に、stackを使ってHaskellの最も有名なコンパイラー、GHCをインストールする必要があります。
stackは、たとえるなら、RubyのrbenvやPythonのpyenvのように、処理系(HaskellであればGHC)のさまざまなバージョンを分離してインストールできるようにするためのものです {$annotation_1}。なので本当にHaskellでの開発をできるようにするためには、stack setupコマンドを利用して、GHCをインストールする必要があります。
やり方は簡単で、下記のようにstack setupコマンドを実行するだけです。
$ stack setup
しばらく待つと、GHCのインストールが完了します。完了したら、確認のためにGHCのバージョンを見てみましょう。
stackでインストールしたGHCを利用するには、stack ghcコマンドを使います。
$ stack ghc --version Invalid option `--version' Usage: stack.exe ghc [-- ARGS (e.g. stack ghc -- X.hs -o x)] ([--plain] | [--[no-]ghc-package-path] [--[no-]stack-exe] [--package ARG] [--rts-options RTSFLAG]) [--help] Run ghc
おっと、「--versionというオプションは無効だ(Invalid option)」と言われてしまいました。ghcには--versionオプションがあるはずなのですが、これはどういうことでしょう?
これはstackの残念な仕様で、stackコマンド経由でghcに--versionなどのオプションを渡そうとした場合、意図に反してstackコマンドが(正確には、stackコマンドのサブコマンドであるstack ghcが)--versionオプションを解釈してしまうことによるエラーです。
これを回避するには、--versionオプションより前に--を渡します。
stackコマンドが--versionオプションを解釈するのをやめさせたうえで、あらためて実行してみましょう。
$ stack ghc -- --version The Glorious Glasgow Haskell Compilation System, version 8.0.2
ちゃんとGHCのバージョンが見えましたね!
「--を渡すことでそれ以降の引数をオプションとして解釈させない」というテクニックは、stackコマンドに限らず、オプションを解釈する大抵のコマンドで使用できるので、ぜひ覚えておいてください。
なお、上記の通り、今回は執筆時点でstack setupした場合にデフォルトでインストールされる、GHC 8.0.2を使用して説明します。
使用するバージョンによって表示される内容が異なる場合があります。あらかじめご了承ください。
対話環境GHCiを使ってみましょう
ここまでの方法でGHCのインストールが確認できたら、続いてGHC付属の対話環境(REPL)であるGHCiを使用してみましょう。
次のようにstack ghciコマンドを実行すると起動できます(出力結果は環境によって微妙に異なります)。
$ stack ghci Configuring GHCi with the following packages: GHCi, version 8.0.2: http://www.haskell.org/ghc/ :? for help Loaded GHCi configuration from C:\Users\user\AppData\Local\Temp\ghci4628\ghci-script Prelude>
GHCiを起動したら、とりあえず電卓のように使ってみましょう。
Prelude> 1 + 1 2 -- 身長170cm, 体重60kgの人のBMI Prelude> 60 / 1.70 ^ 2 -- 累乗にはキャレット「^」を使います。 20.761245674740486
ちゃんと計算できますね。
なお、「--」で始まる行はHaskellのコメントです。このようにGHCiのなかでも使えます。
Haskellでは関数をイコールで定義する
続いて、GHCiからHaskellのソースファイルを読んでみましょう。GHCiでは:lというコマンド(:loadの省略形)で、引数に渡したHaskellのソースファイルを読み、その動作を確認できます(:lはあくまでもGHCi専用のコマンドであり、Haskellの文法とは関係がありません。念のためご注意を)。
以降、この記事では、「まずHaskellのソースファイルを書き、:lコマンドでそのファイルを読んで動作を確認する」という手順を繰り返すことで説明を進めていきます。ここでGHCiに慣れておきましょう。
手始めに、身長(height)と体重(weight)を受け取って、肥満度を表すBMI(Body Mass Index)を返す関数でも定義してみましょう。
下記の1行を記述したファイルをbmi.hsという名前で保存してください。
bmi height weight = weight / height ^ 2
この1行で、bmiという関数を定義しています。
せっかくなので、ここでHaskellにおける関数定義の文法を解説しておきましょう。 Haskellでは、次のような形式で関数を定義します。
関数名 仮引数名1 仮引数名2 ... 仮引数名N = 〔関数の本体〕
先ほどのbmi関数でいうと、bmiが関数名、heightとweightが仮引数名です。
そして、イコール「=」より後ろの「weight / height ^ 2」の部分が〔関数の本体〕に該当します。仮引数のweightとheightを使った計算式になっていることがわかりますね。
このようにHaskellでは、関数を定義する際も、まるで変数を定義するかのように=を使います。ちょっと変わっていますね。
また、戻り値を示すのにreturnのような構文を一切使っていない点にも注目してください。
Haskellには「return文」のようなものはなく、=以降に書いた式の結果がそのまま関数の戻り値となります。

Haskellの関数は簡単な構文で使える
さてさて説明はこのくらいにして、定義したbmi関数をGHCi上で使用してみましょう。
まずは、:l bmi.hsとして、bmi関数を書いたファイルを読み込みます。
Prelude> :l bmi.hs [1 of 1] Compiling Main ( bmi.hs, interpreted ) Ok, modules loaded: Main.
関数を定義したファイルを読み込めたら、次のようにbmi 身長 体重という形式で入力してbmi関数を実行できます。
*Main> bmi 1.7 60 20.761245674740486
ちゃんと実行できるようですね!
上記の通り、Haskellでは、関数呼び出しの際に丸カッコを使うこともないですし、複数の引数を区切るのにカンマを使うこともありません。 関数名と引数を、すべてスペースで区切って並べるだけです(関数の呼び出しで丸カッコを使うとしたら、結合の優先順位を示すためだけに使います)。
Haskellに限らずとも、プログラミングでは関数呼び出しは非常に頻繁に書くものです。よく使うものが簡単な構文で使えるのはうれしいですよね!

最後に、GHCiを終了するときは:q(:quitの省略形)と入力しましょう。
> :q Leaving GHCi.
Haskellの基本的な型に親しもう(GHCiをもっと使いこなしつつ)
Haskellにおいて標準で使えるデータ型や、そのリテラルについて紹介します。
ついでに、もう少しGHCiと親しくなりましょう。
終了させた直後で恐縮ですが、もう一度stack ghciコマンドでGHCiを起動してください。
$ stack ghci
>
Bool型(ついでに「:t」コマンド)
Boolは、プログラミングでおなじみの論理値を表す型です。Haskellでは、真がTrue、偽がFalseで表されます
(Pythonの真偽値のように、大文字で始まります)。
> True True > False False
GHCiには、:tコマンド(:typeの省略形)という、式の型を確かめるためのコマンドが用意されています。
TrueとFalseがBool型であることを、:tコマンドを使って確かめてみましょう。
> :t True True :: Bool > :t False False :: Bool
:tコマンドを実行すると、式の後に続けて、:: 型の名前という形式で、対象の式の型が何かを教えてくれます。
上記の例は単純すぎてあまりありがたみがないですが、もっと複雑な式や、初めて使用する関数について調べるときには、:tコマンドで型を確認することがプログラムの理解を確実に促進してくれます。

論理積や論理和については、おなじみの&&や||が使えます。
> True && False > False > True && True > False > True || False > True > False || False > False
論理の否定も、多くのプログラミング言語でおなじみの!……と言いたいところですが、違います!
Bool型の否定は、文字通りnotです。
> not True False > not False True
個人的には、!が否定を表すことに違和感があるので、Haskellを学んで論理否定がnotであると知ったときは大変うれしかったです!
!よりも視覚的に目立ちますしね!
関数型
Haskellのnotと、多くのプログラミング言語における!には、見た目以外にも大きな違いがあります。
こうした論理演算子は、多くのプログラミング言語では関数とされていませんが、Haskellではnotもまた関数なのです。
関数なので、notにも:tコマンドを使えます。実際に試してみましょう。
> :t not not :: Bool -> Bool
型として、Bool -> Boolという文字列が返ってきました。
これは、「Bool(型の値)を受け取ってBool(型の値)を返す関数型」を表しています。
->という記号が、型を表すのに使われるという点に、ちょっと面食らった方がいるかもしれません。
Haskellでは、いわゆる「関数型プログラミング言語」の多くと同じように、関数もファーストクラスオブジェクトとなっています。
つまり、関数も、Boolや文字列、整数などと同様に、変数に代入したり、関数の引数として渡したりすることができるのです。
実をいえば、bmi関数を定義するときに使った
bmi height weight = weight / height ^ 2
という構文も、関数オブジェクトをbmiという変数に代入する構文(の1つ)に過ぎません。
リスト型
リスト型は下記のようなリテラルで表されます。
:tコマンドで型を見ながら確かめてみましょう。
> :t [True, False, False] [True, False, False] :: [Bool]
角括弧で囲った[Bool]という表記が、「Bool型(の値)のリスト型」であることを表しています。
リストの長さに制限はありませんが、リストの要素はすべて同じ型でなければなりません。
リストの長さを知りたいときは、length関数を使いましょう。
> length [True, False, False] 3
リストを結合したいときは、++という演算子を使います。
> [True] ++ [True, False] [True,True,False]
reverse関数を使うと、リストを逆順に並び替えることができます。
> reverse [True, True, False]
[False,True,True]
リストが空かどうか知りたいときは、nullという関数を使います。
ちょっと変な名前なのが悩ましいですね。
> null [False, False, True] False > null [] True
文字型・文字列型
Haskellでは、文字型と文字列型が厳密に分かれています。
まず、文字型の値は、下記のようにシングルクォート「'」で囲むことで表記します。
> :t 'a' 'a' :: Char
それに対して、文字列型の値は、ダブルクォート「"」で囲むことで表記します。
> :t "a" "a" :: [Char]
:tの結果が[Char]となっていることからわかるとおり、Haskellの標準の文字列は実際には「文字のリスト」です。
なので、"a"は['a']と等価です。
> ['a'] "a"
GHCi上でも、ダブルクォートで囲って表示されましたね。
上記のように:tコマンドでは[Char]と表示される文字列ですが、便宜のため、[Char]にはStringというおなじみの名前で、型の別名がついています。
例えば、何行にもまたがる文字列を受け取って1行ごとに分かれた文字列のリストへと変換する関数linesは、「Stringを受け取ってStringのリストを返す関数」として型付けされています。
> :t lines lines :: String -> [String]
ちなみに、シングルクォートで文字列を書こうとすると、下記のようなエラーを出してくれます。
> 'abc' <interactive>:27:1: error: • Syntax error on 'abc' Perhaps you intended to use TemplateHaskell or TemplateHaskellQuotes • In the Template Haskell quotation 'abc'
RubyやJavaScriptなどで、文字列をダブルクォートで書くかシングルクォートで書くかをめぐって議論になることもありますが、Haskellではそのような「自転車置場の議論(bike-shed discussion)」(自転車置き場の屋根を何色に塗るかという、あまり実益のない議論)に悩まされずに済みますね。
(なお、エラーメッセージで触れているとおり、シングルクォートで始まる文字列はTemplate Haskellというコンパイル時プログラミングのために使用されることがあります。 Template Haskellについては今回は割愛します。)
さて、この文字列、実際には文字のリストなので、リストに使える関数はすべて文字列に対しても使えます。
結合したいときは ++ が使えますし、
> "foo" ++ "bar" "foobar"
反転させたいときはreverse関数が使えます。
> reverse "abc" "cba"
文字型・文字列型についてもう少し
ここで、いいお知らせと悪いお知らせがあります。
まずは、いいお知らせです。 Haskellの文字型は、内部的にはUnicodeの1文字として表現されるので、日本語の文字も普通に使えます! 記念に自分の名前を漢字やカタカナでGHCiに打ち込んでみましょう!
> "山本悠滋" "\23665\26412\24736\28363"
おっと……、何やら符号化された形で出力されてしまいましたね。
これが、Haskellの文字型と文字列型についての悪いお知らせです。 GHCiで文字を表示すると、日本語で使われる文字は、上記のようなエスケープシーケンスを使った特別な文字リテラルで表示されてしまうのです(これについての詳細は「Real World Haskell」の付録が簡潔にまとまっています)。
ちゃんと日本語として読める状態で表示させたい場合には、後述するputStrLn関数を使うのが一番簡単でしょう。
> putStrLn "\23665\26412\24736\28363" 山本悠滋 > putStrLn "山本悠滋" 山本悠滋
あるいは、unicode-showパッケージを使うという手もあります。 下記のコマンドでunicode-showというパッケージを入れた上で、
$ stack install unicode-show
GHCiの設定ファイル~/.ghci(WindowsではC:\Users\<ユーザー名>\.ghci)に以下の内容を追加してください。
import qualified Text.Show.Unicode :set -interactive-print=Text.Show.Unicode.uprint
そのうえでstackからGHCiを再起動して、あらためて文字列リテラルで日本語を入力してみましょう。
$ stack ghci > "山本悠滋" "山本悠滋"
今度は無事に筆者の名前が表示されました!
数値型と型クラスについて簡単に
すでにbmi関数で数値を扱う例を見ましたが、Haskellにはいろいろな数値型もあります。
多くのプログラミング言語でお馴染みの「int」、「double」といったキーワードを、大文字で始まる名前に変えたものが、だいたい数値型として使えると思えばいいでしょう。
標準的な数値型
標準で使用できる数値型を下記の表にまとめます(なお、ここで「標準で」といっているのは、Preludeというパッケージにあるもの、という意味です。これら以外にも、Int32やRationalといった数値のための型がありますが、該当するパッケージのimportが必要になります)。
| 型名 | 種類 |
|---|---|
| Int | 固定長符号付き整数(使用できる精度は実装依存) |
| Integer | 任意精度の符号付き整数 |
| Float | 単精度浮動小数点数 |
| Double | 倍精度浮動小数点数 |
| Word | 固定長符号なし整数(使用できる精度は実装依存) |
これらの数値型には、やはり多くのプログラミング言語で見慣れたリテラルが用意されています。
-- 整数 > 114514 114514 -- 小数 > 3.141592 3.141592 -- 指数表記 > 1.43e6 1430000.0 -- 16進数 > 0x16 22 -- 8進数 > 0o16 14
もちろん、これらの数値型に対しては、各種の四則演算も定義されています。
> 114514 + 3.141592 114517.141592 > 3.141592 - 1.43e6 -1429996.858408 > 1.43e6 * 0x16 3.146e7 > 0x16 / 0o16 1.5714285714285714
上記の3つめの例では、1.43e6 * 0x16という具合に、指数表記の数値と16進数表記の数値とで掛け算をしています。
プログラミング言語によっては、指数表記の数値リテラルは浮動小数点数専用、16進数表記の数値リテラルは整数専用と決まっているので、このように四則演算を書けることが不思議に感じる方もいらっしゃるかもしれません。
そもそも*という演算子は、この例のような引数の組み合わせしか指定できないわけではありません。
指数表記の数値リテラルどうしの掛け算はもちろん、さまざまな数値リテラルどうしの掛け算を表すのに、同じ*という演算子が使えます。
型が厳格なHaskellで、どうしてそんなことが可能なのでしょうか? これらの数値リテラルは、いったいどんな型になっているのでしょう?
さっそく:tコマンドを使って確認してみましょう。
> :t 114514 114514 :: Num t => t > :t 3.141592 3.141592 :: Fractional t => t > :t 1.43e6 1.43e6 :: Fractional t => t > :t 0x16 0x16 :: Num t => t > :t 0o16 0o16 :: Num t => t
それぞれの数値リテラルに対して、その型が表示されているはずですが、Num t => tのように、なんだか見慣れない「=>」という記号を含んでいます。
これはいったい何でしょう?
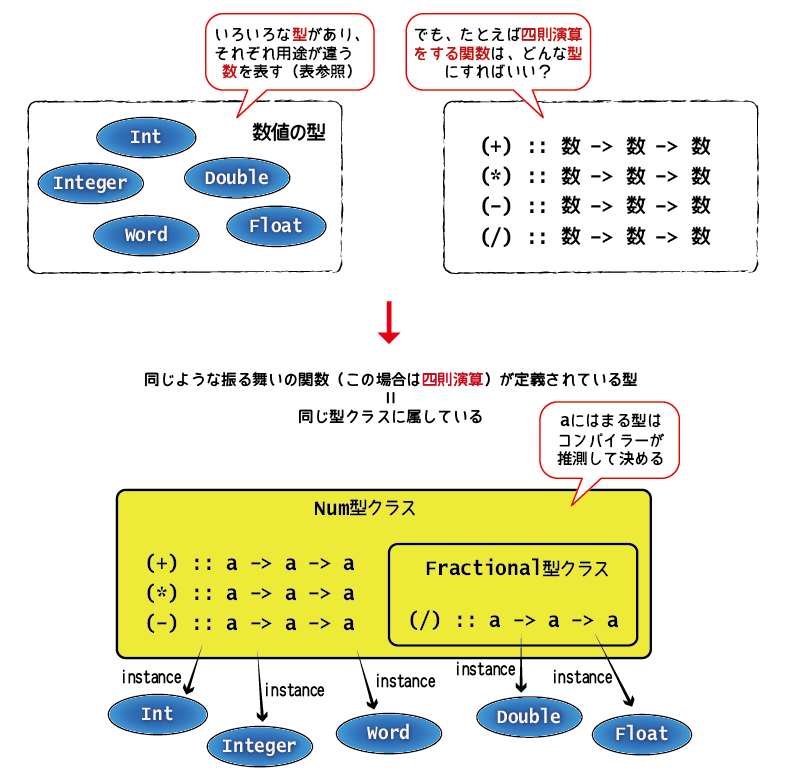
型クラス
「=>」は、Haskellの型クラス制約と呼ばれるものを表しています。
具体的には、=>の左側に出てくるNumや、Fractionalと書かれたものが型クラスです。
そして、=>の右側に出てくるもの(この場合はどれもt)は、「=>の左側で示されている型クラスに属している(とある)型」です。
型クラスについては次回も触れる予定なので、いまのところは「同じような特徴(振る舞い)を持った型を、ひっくるめて扱えるようにする仕組み」とだけ覚えておいてください (その意味では、Javaなどのプログラミング言語におけるinterfaceと少し似ている面があります)。
例えば、上記では114514や0x16といった数値リテラルに対してNum t => tという結果が示されていますが、これは、それらの数値リテラルの型が「Num型クラスに所属する型のうち何か」であることを示しています。
同様に、3.141592や1.43e6といった数値リテラルに対してはFractional t => tという結果が示されていて、これは「Fractional型クラスに所属する型のうち何か」であるという意味です。
つまり、これらの数値リテラルは、この時点では具体的な型が決まっていないのです。
ちょっと奇妙ですよね。
では、これらの数値リテラルの型はいつ決まるのでしょう? 実は、プログラムの中でその数値リテラルがどのような関数に渡されているか、どのような変数に代入されているかなどをコンパイラーが見て、それから型を推測して決めます。 推測しても型が決定できない場合は、コンパイルエラーとなります。
GHCiで型クラスを確認する
型クラスの定義をGHCi上で確認するには、:iコマンド(:infoの省略形)を使います(:iは、実際には型クラスだけでなく、普通の型や変数に対しても使えます)。
> :i Num class Num a where (+) :: a -> a -> a (-) :: a -> a -> a (*) :: a -> a -> a negate :: a -> a abs :: a -> a signum :: a -> a fromInteger :: Integer -> a {-# MINIMAL (+), (*), abs, signum, fromInteger, (negate | (-)) #-} -- Defined in ‘GHC.Num’ instance Num Word -- Defined in ‘GHC.Num’ instance Num Integer -- Defined in ‘GHC.Num’ instance Num Int -- Defined in ‘GHC.Num’ instance Num Float -- Defined in ‘GHC.Float’ instance Num Double -- Defined in ‘GHC.Float’
class Num a whereより下のインデントされている数行が、Num型クラスの定義に相当します。
詳しい説明は省きますが、+や*、negateのような、このNum型クラスに属する型で定義されているべき関数(演算子)が列挙されているのがなんとなくわかると思います。
さらに、その下に続く先頭がinstanceというキーワードの各行は、Num型クラスに属している具体的な型を示しています。
先の表に挙げた各数値型(IntegerやDoubleなど)がNum型クラスに属しているということが読み取れると思います。
1.43e6 * 0x16のような書き方ができる理由が、これでだいたい感じとってもらえたでしょうか?
Fractional型クラスの定義も見てみましょう。こちらは割り算(/)などが定義されているようですね。
> :i Fractional class Num a => Fractional a where (/) :: a -> a -> a recip :: a -> a fromRational :: Rational -> a {-# MINIMAL fromRational, (recip | (/)) #-} -- Defined in ‘GHC.Real’ instance Fractional Float -- Defined in ‘GHC.Float’ instance Fractional Double -- Defined in ‘GHC.Float’
Num型クラスとFractional型クラスのデフォルト型
先ほど、型が推測できない場合はコンパイルエラーになると言いましたが、 Num型クラスとFractional型クラスに限っては、それだと実用上不便なことが多いので、推測して型を判断できない場合には次のようなルールでデフォルトの型を決めます。
- 小数点を含まない数値のリテラル(整数のリテラル)だけどなんの型かわからない =>
Num型クラスとして解釈し、そのデフォルトの型であるInteger型に決める。 - 小数点を含む数値のリテラルだけどなんの型かわからない =>
Fractional型クラスとして解釈し、そのデフォルトであるDouble型に決める。
このことを確かめるために、GHCiで次のコマンドを打ってGHCの警告表示を有効にしてみましょう。
> :set -fwarn-type-defaults
この状態で、整数のリテラルをGHCiに入力してみてください。 下記のような警告が表示されるはずです。
> 1 <interactive>:7:1: warning: [-Wtype-defaults] • Defaulting the following constraints to type ‘Integer’ (Show a0) arising from a use of ‘print’ at <interactive>:7:1 (Num a0) arising from a use of ‘it’ at <interactive>:7:1 • In a stmt of an interactive GHCi command: print it 1 > 1 + 2 <interactive>:9:1: warning: [-Wtype-defaults] • Defaulting the following constraints to type ‘Integer’ (Show a0) arising from a use of ‘print’ at <interactive>:9:1-5 (Num a0) arising from a use of ‘it’ at <interactive>:9:1-5 • In a stmt of an interactive GHCi command: print it 3
長ったらしい警告の後に計算結果が表示されています。
警告を読むとわかりますが、整数のリテラルしか使用していなかった場合、GHCはそれらの値をIntegerとして解釈しているようです。
小数点が入ったリテラルを使用した場合も試してみます。
> 1 + 3.0 <interactive>:8:1: warning: [-Wtype-defaults] • Defaulting the following constraints to type ‘Double’ (Show a0) arising from a use of ‘print’ at <interactive>:8:1-7 (Fractional a0) arising from a use of ‘it’ at <interactive>:8:1-7 • In a stmt of an interactive GHCi command: print it 4.0
こんどはDoubleとして解釈されました。
左辺に整数のリテラルを使用しても、右辺に小数点が入ったリテラルを使用していると、GHCは両方の値をDoubleとして解釈するようです。
細かいところですが、C言語のように1をIntとして解釈してからDoubleに暗黙にキャストしているわけではないのでご注意ください。
タプル型
次のように丸カッコ()でカンマ区切りの値を囲むと、タプルという型の値になります。
> ('a', True) -- CharとBoolのタプル ('a',True) > :t ('a', True) ('a', True) :: (Char, Bool) -- ^ 文字通り、「CharとBool(でサイズは2)のタプル」という型になる > :t (False, True, False) -- サイズ3のタプル (False, True, False) :: (Bool, Bool, Bool) -- ^ Boolが3つ入ったタプル。「BoolとBoolとBool(でサイズは3)のタプル」という型になる
複数の値を保持できるので、よくリストと対比して説明されますが、タプルは使い方も内部の構造もリストとはまったく異なります。 リストの場合、同じリストに入っている値はすべて同じ型でないといけませんが、タプルでは型の情報に「1個目の要素の型」、「2個目の要素の型」、…「N個目の要素の型」がそれぞれ書かれているので、それらが違っていてもかまいません。
このような特徴から、タプルは、1つの関数から複数の値を返したい場合などに「お気楽な構造体」として使用されます。
例えば、整数同士の割り算において「商」と「余り」を返すdivModという関数は、商と余りをタプルに入れることで返します。
> divMod 9 4 (2,1)
タプルから個々の要素を取り出したい場合は、次のように、JavaScriptのデストラクチャリングのような記法を使用しましょう。
> (quotient, remainder) = divMod 9 4 > quotient 2 > remainder 1
上記のようなサイズ2のタプルはよく使われるので、各要素を取り出すための専用の関数が用意されています。
それぞれ、fstとsndといいます。
> quotientAndRemainder = divMod 9 4 > fst quotientAndRemainder 2 > snd quotientAndRemainder 1
ユニット型
ユニット型は、取り得る値が1個しかない、たいへん特別な型です。
「()」で表されます。
> ()
()
:tで型を尋ねても、「()は()だよ」としか教えてくれません。
まるでトートロジーですね。
> :t () () :: ()
一体、こんなものがなんの役に立つのでしょう?
Haskellにおけるユニット型の役割は、C言語やJavaなどにおけるvoid型と似ています。
次の節で説明しますが、戻り値が「ない」ような関数を表現するのに使用します。
動くアプリケーションを作ってみましょう(GHCを使った実行ファイルのビルド)
さて、ここまでの解説では対話環境であるGHCi上でHaskellのコード片を簡易的に試してきましたが、そろそろコンパイルして実行できるアプリケーションを書きたくなってきた頃でしょう。
コードの中身は後で解説しますので、とりあえず下記の2行をお好きなエディターを使ってコピペし、hello.hsという名前で保存してください!
main :: IO () main = putStrLn "Hello, world!"
保存できたら、下記のようにstack ghcコマンドでコンパイルしましょう。
$ stack ghc hello.hs [1 of 1] Compiling Main ( hello.hs, hello.o ) Linking hello ...
コンパイルが無事に終わったら、helloという名前の実行ファイル(Windowsの場合はhello.exe)ができるはずです。
できたファイルは、直接マシンで実行できます。
実行すると何が起こるでしょうか?!
$ ./hello Hello, world!
お察しの通り、「Hello, world!」が表示されました。
それでは約束どおり、先ほどのコードの中身を解説しましょう。
mainとIOについて簡単に
Haskellでアプリケーションを書くには、mainという関数を定義する必要があります。
main = putStrLn "Hello, world!" ^^^^ -- この部分!
mainは、C言語などのmain関数と同じで、コンパイルしたプログラムを実行したときに最初に実行される関数です。
main関数を定義するときも、Haskellの他の関数を定義するときと同じように、まるで変数を定義するかのように=を使います。
=の右側のputStrLn "Hello, world!"という部分についても掘り下げていきましょう。
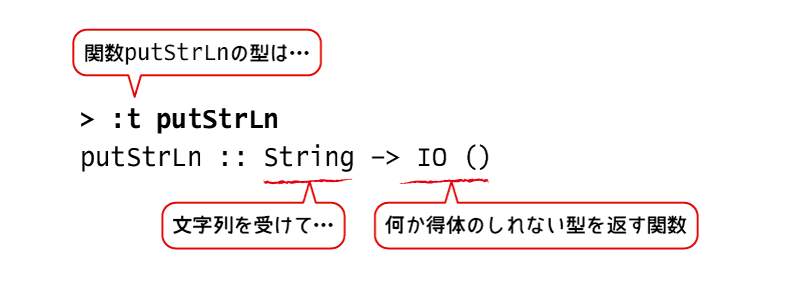
まずは、putStrLnが何なのかを調べるために、GHCiを起動しておなじみの:tコマンドを使ってみます。
$ stack ghci > :t putStrLn putStrLn :: String -> IO ()
どうやらputStrLnは、
文字列(String)を受け取り、「IO ()」という何か得体の知れない型の値を返す関数のようです。
ここまでの復習をかねて注釈を入れるとこんな感じです。
さて、putStrLnが「文字列を受け取って何かを返す」関数であることは、先ほどのコードで「Hello, world!」という文字列を渡していたことから想像がつくかも知れません。
しかし、返ってくるこの「IO ()」というのは何者でしょうか?
「純粋な関数」と「IOアクション」
端的に言うと、IO ()は入出力などの副作用が認められた特別な関数であり、戻り値としてユニット型()を返します。
他のHaskellの関数のように引数を受け取るわけではないので、あまり関数っぽく見えないかもしれませんが、C言語における「関数」や、オブジェクト指向プログラミング言語における「メソッド」のように捉えると、少しそれらしく見えるでしょう (「プロシージャー」という言い方のほうがピンとくる人もいるかもしれませんね)。
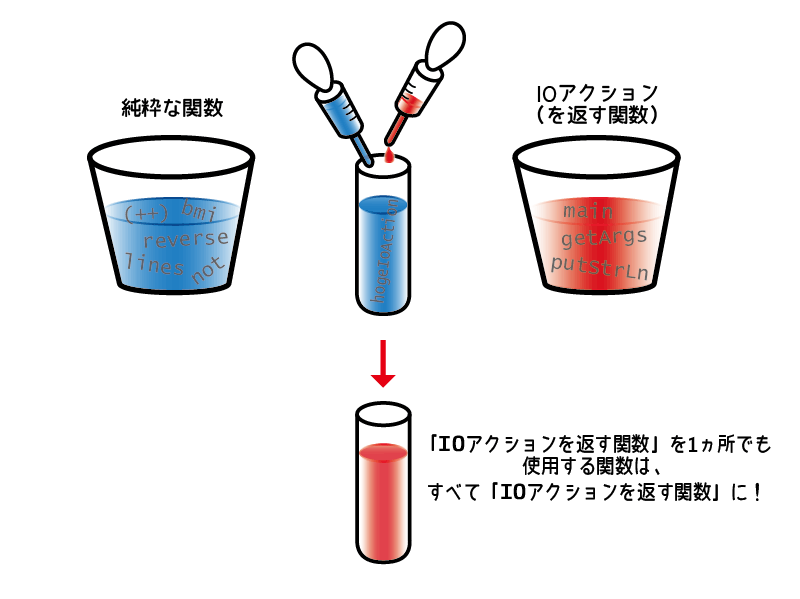
実は、Haskellの世界では、「(引数を受け取って)何か値を返す関数(ただし入出力処理はできない)」と、「(引数は受け取らないけど)入出力処理をしつつ何か値を返すことができる関数」の2つが厳密に分けられています。
そして、一般に前者は「純粋な関数」、後者は「IOアクション」と呼ばれています。
putStrLnのような、Haskellで入出力処理を行う関数は、「純粋な関数」が引数を受け取り、それを元に「IOアクション」を返すことで実装されています。
なぜ、「純粋な関数」と「IOアクション」とが分けられているのでしょう?
それは、この記事の冒頭でHaskellの特徴として挙げた「型によってプログラムの副作用を管理できる仕組み」を提供するためです。
原則として、putStrLnのような「IOアクションを返す関数」を1ヵ所でも使用する関数は、すべて「IOアクションを返す関数」になります(例外もありますが、それは主にデバッグのために使われる関数です)。
結果として、「IOアクションを返す関数」は、すべてputStrLnと同じような「IO 〔何か〕」を返す関数となります。
つまり、IOアクションがどこかに出てくる関数hogeIoActionがあったとして、:tでその関数の型を調べると、たとえば次のように表示されるということです。
hogeIoAction :: Int -> IO 〔何か〕
〔何か〕の部分には、「IOアクション」が返す値の型が書かれます。
つまり、「入出力処理をしつつ何か値を返すことができる関数」の、その返す値の型です。
putStrLnの場合、〔何か〕は()だったので、返す値はユニット型()です。
ユニット型は、何も役に立たない値なのでした。
前節の最後で、ユニット型のことを「C言語やJavaなどにおけるvoidと似たようなもの」といったのは、そういうわけだったのです。
IOアクションを含む関数はすべて「IO 〔何か〕」という型を持っているということは、Haskellのコードを読む際には関数の型を読むだけで、その関数が入出力処理などの副作用を行うのかどうかが判明するということです。
関数の副作用の有無を型によって管理できるので、プログラムにおける副作用を確実に切り分けることができます。
IOアクションの結果を受け取る
実際にプログラムを書いていくと、「IOアクション」が「返す値」を変数に代入したくなることも多々あります。 たとえば、実行時にユーザーに値を入力してもらい、その値をプログラムで取得して利用する、といった場合です。
例として、身長と体重を入力してもらい、その値から前に作ったbmi関数でBMI値を計算するプログラムを作ってみましょう。
このプログラムの完成形を下記に示します。
import System.Environment (getArgs) main = do (heightString:weightString:_) <- getArgs print (bmi (read heightString) (read weightString)) bmi height weight = weight / height ^ 2
上記のプログラムには、ここまでの説明では登場していないHaskellの概念がいくつか登場しています。以下、すべてを完全には解説できませんが、かいつまんで概略を説明します。
ます、このプログラム全体を見ると、main関数を1つのdoという文で定義していることが推察できると思います。
そして、そのdoの中(インデントに注目してください)に、実行したいIOアクションを並べて書いていますね。
1つめのIOアクションは、getArgsです。
この関数は、プログラムの実行時に与えられたコマンドライン引数をそれぞれ文字列として取得して、そのリストを返すというIOアクションです(getArgsはSystem.Environmentというモジュールで提供されているので、1行めでこのモジュールをimportしています)。
getArgsを以下のように使うことで、heightStringという変数に1つめのコマンドライン引数が、weightStringという変数に2つめのコマンドライン引数が代入されるようにしています。
(heightString:weightString:_) <- getArgs
2つめのIOアクション(を返す関数)は、printです。
この関数は、画面に表示できるような値を引数にとり、それを実際に出力します。
このprintを使って、heightStringとweightStringの値をもとにbmi関数で計算した結果を出力するようにしています。
readという関数は、引数として受け取った文字列を、別の、いろいろな型の値に変換する関数です。
ここでは、heightStringとweightStringをそれぞれ渡すことによって、bmi関数の引数として適切な型の値へと変換するために使っています。
それでは、上記のコードをbmi.hsのような名前で保存し、GHCでコンパイルして実行してみましょう。
$ stack ghc bmi.hs [1 of 1] Compiling Main ( bmi.hs, bmi.o ) Linking bmi ... $ ./bmi 1.7 60 20.761245674740486
うまくいきましたね!
もうちょっと凝った関数を作ってみましょう(次回予告)
ここまで、Haskellの開発環境の構築方法に始まり、対話環境であるGHCiの使い方を通して、関数の定義方法や、基本的な型とそのリテラルについて説明してきました。
ここから先は、もっと本格的なサンプルアプリケーションの開発に向けて、より実践的なHaskellの機能を説明していくことにします。 具体的には、アプリケーションの仕様に基づいてオリジナルの型を定義し、その型を利用する複雑な関数を書いていきます。
「この記事では関数の書き方しか説明しないの?」と、ちょっと落胆してしまう方もいるかもしれません。 しかし、落胆するには及びません。 Haskellによるプログラミングの大きな部分を占めるのは、問題に合わせた型を自分で考えて定義し、その型を利用した関数を書くことです。 その醍醐味を次回は味わっていただく予定です。
題材として取り上げるのは、トランプゲームの「ブラックジャック」です。 ブラックジャックは、親から配られる手札の合計を21にすることを目指すゲームです。 合計の計算では、次のようなルールに従ってカードを数えます。
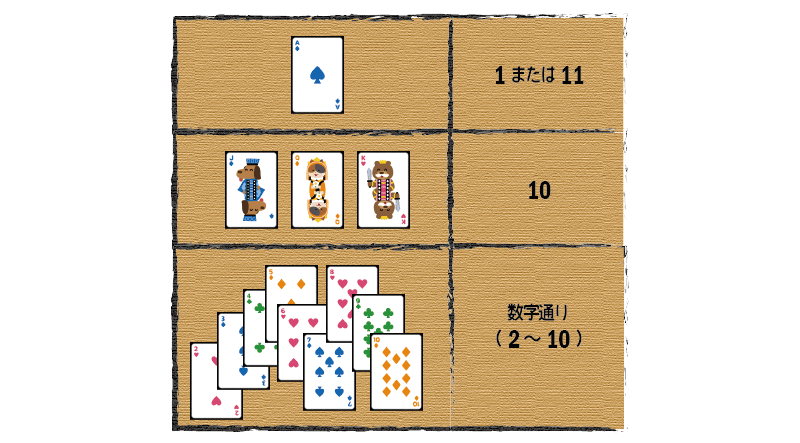
最初に親から配られる手札は2枚ですが、子は追加のカードを好きなだけ要求できます。追加のカードを要求することで、合計を21になるべく近づけていくのですが、それによって合計が21を越えてしまったら負けです。
エース(A)の数え方が2通りあるので、手札の数字を単純に合算するだけでなく、他のカードとの組み合わせを考えた条件分岐が必要になることが想像できますね。 そこで次回の記事では、この「手札のカードから最も勝ちに近い点数を計算する」部分までを作ってみることにします。
その実装を通して、今回の記事で説明した入門から一歩足を踏み出す「Haskellらしいプログラムの設計の仕方と実装の仕方」を実体験していただけると思います。
お楽しみに!
実践編!Haskellらしいアプリケーション開発。まず型を定義すべし【第二言語としてのHaskell】
発展編! Haskellで「型」のポテンシャルを最大限に引き出すには?【第二言語としてのHaskell】
執筆者プロフィール
山本悠滋(やまもと・ゆうじ) 



日本Haskellユーザーグループ(愛称、Haskell-jp)発起人の一人にして、Haskell-jpで一番のおしゃべり。本業はGMOクリックホールディングス所属のプログラマー。Haskellとプリキュアとポムポムプリンをこよなく愛する。
the.igreque.info
the.igreque.info
▽ 日本Haskellユーザーグループ - Haskell-jp
編集協力:鹿野桂一郎(しかの・けいいちろう、
-
実際のところ、
PATHを書き換えたりすることもなく、stackコマンドを通して使用するものなので、やることはrbenvやpyenvよりかなり控えめで、その分ハマりにくいです。↩




