
実践的なアプリケーションを書いてみよう! Rustの構造化プログラミング【第二言語としてのRust】
Rustを使って、実際にアプリケーションを3つ書いてみましょう! その前に、プログラムの構造化に必要な手法、ジェネリクス、構造体、列挙型、それにトレイトといった概念についても説明します。
前回の記事では、Rustの基本的な文法や型を説明し、他のプログラミング言語ではあまり見かけない、Rustならではのメモリ管理の仕組み(所有権・参照・ライフタイム)についても解説しました。
今回は、Rustを使って、実際にアプリケーションを書いてみましょう。
制作するのは、Unix環境ではお馴染みの文字列検索プログラムであるgrep(その機能限定版をRustで書いたrsgrep)、アナグラム(単語の文字を入れ替えた単語)を求めるプログラム、そしてHTTP/0.9サーバです。
しかし、アプリケーション開発に入る前に、もう少しだけ説明しておくことがあります。それは、プログラムの構造化に必要な手法です。ある程度の規模のプログラムをRustで書いていくには、前回説明した基礎に加え、ジェネリクス、構造体・列挙型、それにトレイトといった概念を知っておく必要があります。
今回はまず、単純なサンプルコードを例に、これらの概念について説明しましょう。
- ジェネリクス
- 構造体
- 列挙型
- トレイト
- Rustで実践的な実装 その1. rsgrep
- Rustで実践的な実装 その2. アナグラム
- Rustで実践的な実装 その3. HTTP/0.9
- 結びに代えて
- 執筆者プロフィール
ジェネリクス
ジェネリクスは、関数やデータ型を任意の型に対して動作するように一般化するときに使える仕組みです。ジェネリクスを利用することで、何度も同じような関数やデータ型の定義をしなくて済みます。
関数については、次のように定義することで、ジェネリックな型を持つ関数を定義できます。
fn 関数名<型パラメータ, ...>(引数) -> 返り値の型 { 関数本体 }
型パラメータとして指定したものは、引数と返り値の両方で使えます。
例として、任意の型の引数を2つ取り、それらのタプルを返す関数を定義して使ってみましょう。
fn pair<T, S>(t: T, s: S) -> (T, S) { (t, s) } fn main() { // T = i32, S = f64で呼び出す let i = pair(1, 1.0); // 型を明示する方法もある let i = pair::<isize, f64>(1, 1.0); // T = &str, S = Stringで呼び出す let s = pair("str", "string".to_string()); }
関数だけでなく、これから説明する構造体や列挙型を含むさまざまなデータ型も、同様の構文でジェネリックにできます。後半の実践例でも、そのようなジェネリクスの例が登場する予定です。
構造体
Rustでは、複数のデータ型を集めて構造体を定義できます。
Rustの構造体は、オブジェクト指向プログラミングの際によく使われ、Javaのような言語におけるクラスと同じような使い方ができます。
ただし、Rustの構造体には継承がありません。これにはさまざまな理由(技術的トレードオフ、エルゴノミクス的トレードオフなど)があるのですが、後述するトレイトが強力なので継承が必要ないという面もあるでしょう。
Rustで構造体を定義するにはstructを使います。structには、データを持たないUnit構造体を定義する場合、フィールドに名前がないタプル構造体を定義する場合、それ以外の通常の構造体を定義する場合の3種類の構文があります。
これら3種類の構造体をすべて使った例を下記に用意しました。
// struct 名前; (Unit構造体の構文) struct Dummy; // struct 名前(型, ..); (タプル構造体の構文) struct Point(f64, f64); // struct 名前 {フィールド: 型, ..} (通常の構造体の構文) struct Color { r: u8, g: u8, // 最後のフィールドの末尾にもカンマを付けられる b: u8, } fn main() { // Unit構造体は名前でそのまま初期化 let dummy = Dummy; // タプル構造体は関数のように初期化 // 実際、関数として扱うこともできる let point = Point(0.0, 0.0); // タプル構造体のフィールドへのアクセス let x = point.0; // 普通の構造体の初期化 let black = Color { r: 0, g: 0, b: 0}; // 普通の構造体のフィールドへのアクセス let r = black.r; }
Unit構造体は、あまり馴染みがないかもしれませんが、後述のimplやトレイトでよく使います。
タプル構造体は、フィールドが1、2個の構造体を使うときに用いることが多いようです。フィールドに名前がありませんが、タプルと同じように値.インデックスとすることでフィールドにアクセスできます。
構造体の実装(impl)
構造体の名前にimplをつけることで、メソッドや関連関数(クラスメソッドのようなもの)を定義できます。
下記は、絶対温度と摂氏を変換するプログラムです。それぞれをKelvinおよびCelsiusというタプル構造体として定義し、Celsiusに対してKelvinとの変換をする関数をimplで実装しています。
struct Celsius(f64); struct Kelvin(f64); // `impl 型名 {..}`で型に対する実装を書ける impl Celsius { // `{..}`の中には関数が書ける。 // 第一引数が`self`、`&mut self` `&self`, `Box<self>`の場合はメソッドとなる fn to_kelvin(self) -> Kelvin { // selfを通じてフィールドにアクセスできる。 Kelvin(self.0 + 273.15) } // 第一引数が`self`系でない場合は関連関数となる fn from_kelvin(k: Kelvin) -> Self { Celsius(k.0 - 273.15) } } fn main() { let absolute_zero = Kelvin(0.0); let triple_point = Celsius(0.0); // 関連関数は`型名::関数名(引数)`で呼び出す。 let celsius = Celsius::from_kelvin(absolute_zero); // メソッドは`値.関数名(引数)`で呼び出す。 let kelvin = triple_point.to_kelvin(); }
列挙型
構造体と並んでRustでよく使われるのが、列挙型です。
列挙型は、列挙子の「どれか1つ」を表す型です。このような型は関数型言語では古くから使われていて、「代数的データ型」「直和型」「タグ付きUnion」などの呼び方もあります。関数型言語での実績が認められ、ようやくRustのような言語でも採用されるようになってきたといったところでしょうか。
列挙型を定義するには、enumを使い、enum 名前 {列挙子, ..}のようにします。列挙子には、構造体の3種類の構文と同じ要領で、3種類の定義方法があります。
例を見てみましょう。下記では、Right、Up、Move、Printという列挙子を持つCommandという名前の列挙型を定義しています。指定した方向に進んだり座標に移動したりして何かをするコマンドを定義しているイメージです。
enum Command { // 列挙子は構造体のように3種類の定義ができる Right(i64), Up(i64), Move { x: i64, y: i64 }, Print, }
列挙子へのアクセスには、列挙型名::列挙子名という構文を使います。
上記で定義した列挙型を使って、コマンドを登録して実行するプログラムを書いてみましょう。この例のように、列挙型を利用するときはmatch式と組み合わせることがよくあります。
fn main() { let mut cur = (0, 0); // 列挙子を指定してコマンドを登録 let commands = &[Command::Move { x: 0, y: 0 }, Command::Right(5), Command::Up(5), Command::Print, Command::Move { x: 10, y: 10 }, Command::Print]; for c in commands { // match式で値を取り出す match *c { // match式でのパターンマッチでも、列挙型名を明記する Command::Right(x) => cur.0 += x, Command::Up(y) => cur.1 += y, // フィールド名がある列挙子のパターンマッチ Command::Move { x, y } => { cur.0 = x; cur.1 = y; } Command::Print => { println!("{:?}", cur); } } } // => (5, 5) // (10, 10) }
Option型とResult型
ここで、Rustのプログラミングでよく使う列挙型を2つ紹介しておきましょう。Option型とResult型です。どちらも標準ライブラリで定義されています。
// 構造体や列挙型、トレイトにもジェネリクスはある。 enum Option<T> { // 値がないか None, // ある Some(T), } enum Result<T, E> { // 計算が成功したか Ok(T), // 失敗してエラーが出たか Err(E), }
Rustには例外というものがなく、エラーも返り値で表します。そのときに活躍するのがこれらの型です。
Option型は、ハッシュマップからの値の取得など「値があれば返すが見つからなければnil」という処理をするときに使われます。Result型は、計算が失敗するかもしれないときに使われる型です。なお、Result型については特別な構文糖衣もあります。
トレイト
トレイトは、Rustでポリモーフィズムを実現する手段の1つです。他の言語にも、Rustのトレイトと似た機能は、インターフェースやモジュールといった名前で用意されています。一番近いのは、Haskellなどにある型クラスでしょうか。
Rustでは、トレイトのおかげで、無関係な型同士で共通する振る舞いを作ったり、(プリミティブを含む)既存の型を拡張できたりといった、素晴らしい抽象化が可能です。私はJavaのインターフェースがクラスの定義時にしか実装できないことに不満があったのですが、トレイトではその問題も見事に解決されます。
トレイトは、「あるメソッドを実装している型」を表すのにも向いています。静的型付き言語で合法的にダックタイピングができるようになる楽しい機能だといえるかもしれません。その意味では、ダックタイピングに馴染んでいる人にとって、しっくりくる機能だといえるでしょう。
実際にトレイトを使ったプログラムを見てみましょう。下記のサンプルプログラムでは、DuckLikeというトレイトを定義しています。DuckLikeを実装するデータ型には、鳴き方を表すquackメソッドと、歩き方を表すwalkというメソッドが必要です。
このうちwalkについては、デフォルト実装("walking")を用意しています。コード中のコメントを参考に、何が起きているのか追ってみてください。
// `trait トレイト名 {..}`でトレイトを定義 trait DuckLike { // トレイトを実装する型が実装すべきメソッドを定義 fn quack(&self); // デフォルトメソッドを定義することもできる fn walk(&self) { println!("walking"); } } // トレイトを実装するためだけのデータ型にはUnit構造体が便利 struct Duck; // `impl トレイト名 for 型名 {..}`で定義可能 impl DuckLike for Duck { // トレイトで実装されていないメソッドを実装側で定義する fn quack(&self) { println!("quack"); } } struct Tsuchinoko; // 別の型にも実装できます。 impl DuckLike for Tsuchinoko { fn quack(&self) { // どうやらこのツチノコの正体はネコだったようです println!("mew"); } // デフォルトメソッドを上書きすることもできる fn walk(&self) { println!("wriggling"); } } // 既存の型にトレイトを実装することもできる // モンキーパッチをしているような気分 impl DuckLike for i64 { fn quack(&self) { for _ in 0..*self { println!("quack"); } } } fn main() { let duck = Duck; let tsuchinoko = Tsuchinoko; let i = 3; duck.quack(); // => quack tsuchinoko.quack(); // => mew i.quack(); // => quack; quack; quack }
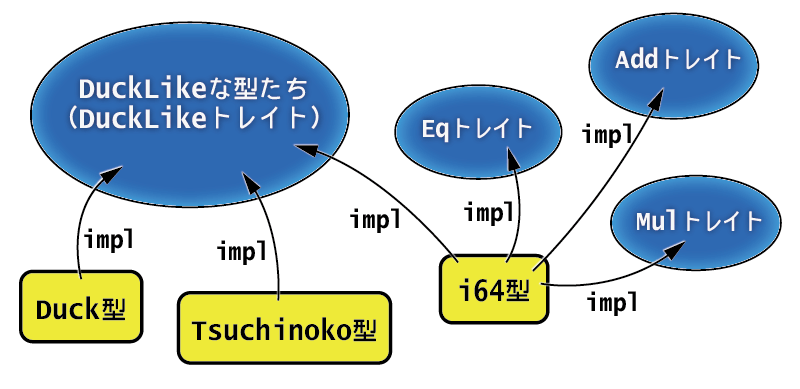
トレイト
このように素晴らしい抽象化を提供してくれるトレイトですが、なんと、トレイトを使うコストはゼロです(静的ディスパッチ)。トレイトを使っても使わなくても、プログラムの速度が変わらないのです。そのため、他の言語でクラスの継承を用いて動的ディスパッチをするよりも高速に動作します。
トレイトは、Rustが掲げるゼロコスト抽象化のひとつの実践例だといえるでしょう。
トレイト境界
「あるトレイトを実装する型」をジェネリクスで受け取ることもできます。これを、トレイト境界といいます。型は値の集合を定義するのに対し、トレイト境界は型の集合を定義するものだと考えられます(集合の集合を扱っているようで、変な気分になりますね)。
下記に、トレイト境界を使ったプログラムの例を示します。ジェネリックな関数を定義するときに、型パラメータ名: トレイト名という具合に型パラメータにトレイト境界を付けることで、その関数の本体でトレイトのメソッドが使えるようになります。
// 上記のmain以外の定義たち // ジェネリクスの型パラメータに`型パラメータ名: トレイト名`で境界をつけることができる fn duck_go<D: DuckLike>(duck: D) { // 境界をつけることで関数本体でトレイトのメソッドが使える duck.quack(); duck.walk(); } fn main() { let duck = Duck; let f = 0.0 duck_go(duck); // => quack; walking // DuckLikeを実装していない型は渡せない // duck_go(f); // the trait `DuckLike` is not implemented for `{float}` }
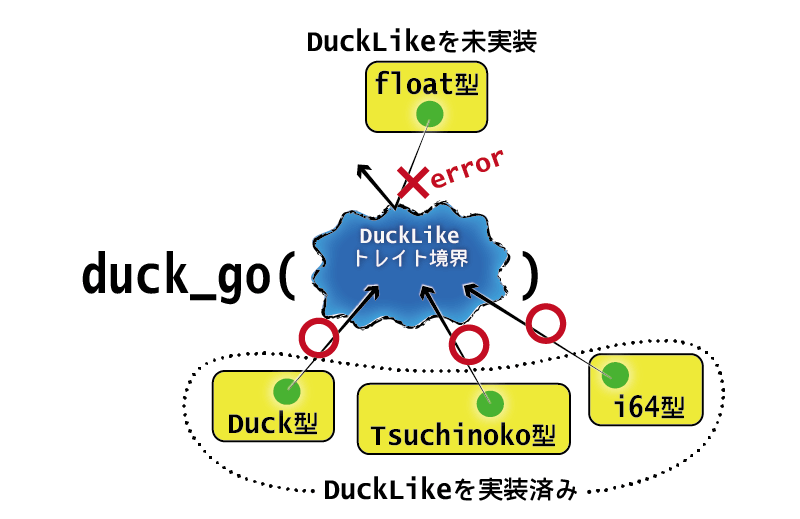
トレイト境界
Rustで実践的な実装 その1. rsgrep
さて、このあたりで1つ、アプリケーションを作ってみましょう。
引数として与えた正規表現で、別の引数として与えたファイルの中を検索し、マッチした行を返すというアプリケーションです。同じような挙動をするUnixコマンドにちなんで、rsgrepと名付けましょう。
Hello Cargo
ここまでのRustプログラムは、すべてrustcコマンドでコンパイルして実行するだけの単純なものでした。ここからは、ある程度まとまったアプリケーションを作っていくので、RustのビルドツールのCargoを使います。
cargoコマンドにより、プログラムのビルドのほか、パッケージのインストールやプロジェクトテンプレートの作成が可能です。
まずは、cargo newで新しいプロジェクトの雛型を作りましょう。
$ cargo new rsgrep --bin Created binary (application) `rsgrep` project $ cd rsgrep
--binというのは、このプロジェクトがライブラリではなく、実行可能なプログラムのものである(後述するbinクレートであること)を示しています。
プロジェクトの雛形ができたら、cargo runとすることでテンプレートを走らせてみましょう。cargo newによって生成される雛形には、あらかじめHello Worldプログラムが用意されているので、下記のような結果になるはずです。
$ cargo run Compiling rsgrep v0.1.0 (file:///home/kim/Rust/rsgrep) Finished dev [unoptimized + debuginfo] target(s) in 0.23 secs Running `target/debug/rsgrep` Hello, world!
最初のコード
Rustのソースコードはsrc以下に置きます。実行のエントリポイントとなるのはmain.rsファイルです。cargo newした直後は、下記のような内容になっているはずです。
fn main() { println!("Hello, world!"); }
このファイルを編集してアプリケーションを作っていきます。いきなり完成を目指すのではなく、まずは引数で受け取ったファイルの中身を1行ずつプリントできるようにしてみましょう。
最初に、標準ライブラリからいくつかの機能をインポートします。インポートには、他の多くの言語のように、プログラムの冒頭で次のように指定します。
// stdクレートのfsモジュールにあるFile型をインポート。以後は`File`として参照できる。 use std::fs::File; // 同じモジュールから複数インポートする際は`{}`でまとめて指定できる。 use std::io::{BufReader, BufRead}; // モジュール全体をインポートすることもできる。 use std::env;
Rustでは、プログラムをクレートという単位で管理しています。今まで作ってきたプログラムのように単体で実行可能なプログラムは、すべてbinクレートとして管理されます。これに対し、ライブラリとして機能するプログラムは、libクレートとして管理されます。
クレートには、複数のモジュールが所属します。Rustでは、モジュールがプログラムの可視性を扱う単位であり、モジュールごとにエクスポートやインポートを管理できます。
モジュールは入れ子にでき、多くは1ファイル/ディレクトリで1モジュールですが、もっと細かい単位で管理することもできます。上記のuse std::fs::File;は、stdクレートのfsモジュールのFile型をインポートするという意味です。
stdクレートは、Rustで標準的に使えるモジュールが所属しているクレートで、fsのほかにもioやenvなどのモジュールが所属しています。
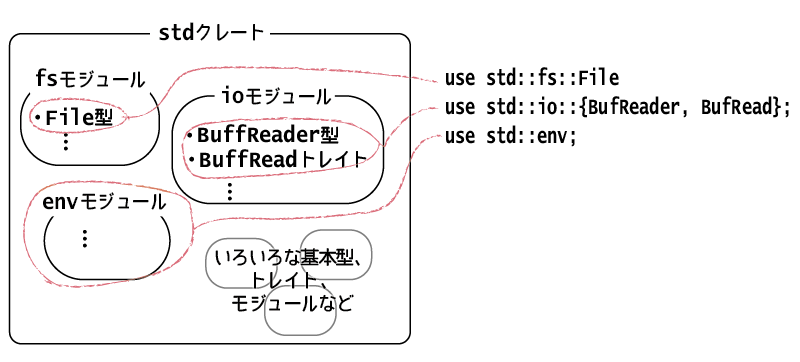
クレートとモジュール
それでは、続けて一気にコード全体を掲載します。もう少しスマートな書き方もできますが、最初なので分かりやすく書いてます。細かくコメントも入れてあるので、参考にしながら内容を追ってみてください。
// stdクレートのfsモジュールにあるFile型をインポート。以後は`File`として参照できる。 use std::fs::File; // 同じモジュールから複数インポートする際は`{}`でまとめて指定できる。 use std::io::{BufReader, BufRead}; // モジュール自体をインポートすることもできる。 use std::env; fn usage() { println!("rsgrep PATTERN FILENAME") } fn main() { // envモジュールのargs関数でプログラムの引数を取得できる。 // そのうち2番目を`nth`で取得(0番目はプログラムの名前、1番目はパターンで今は無視)。 // 引数があるか分からないのでOptionで返される。 let filename = match env::args().nth(2) { // あれば取り出す。 Some(filename) => filename, // なければヘルプを表示して終了 None => { usage(); return; } }; // `File`構造体の`open`関連関数でファイルを開ける。 // 失敗する可能性があるので結果は`Result`で返される。 // 下の方でもう一度`filename`を使うためにここでは`&filename`と参照で渡していることに注意。 let file = match File::open(&filename) { // 成功すれば取り出す。 Ok(file) => file, // ファイルが見つからないなどのエラーの場合はそのままプログラム終了 Err(e) => { println!("An error occurred while opening file {}:{}", filename, e); return; } }; // Fileをそのまま使うと遅いのと`lines`メソッドを使うために`BufReader`に包む。 // この`new`もただの関連関数。 let input = BufReader::new(file); // `BufReader`が実装するトレイトの`BufRead`にある`lines`メソッドを呼び出す。 // 返り値はイテレータなので`for`式で繰り返しができる for line in input.lines() { // 入力がUTF-8ではないなどの理由で行のパースに失敗することがあるので // `line`もResultに包まれている。 let line = match line { Ok(line) => line, // 失敗したらそのまま終了することにする。 Err(e) => { println!("An error occurred while reading a line {}", e); return; } }; println!("{}", line); } }
注目してほしいのは、Result型やOption型を多用している点です。プログラムの外の世界は怖いことだらけなので、このようにResult型やOption型で値をくるんで安全に使えるようにしています。
この状態で、プログラムをcargo runで実行してみましょう。実行の際の引数として、パターンとファイル名を与えるのを忘れずに。ここでは、プロジェクトディレクトリに作られているはずのCargo.tomlというファイルを指定して実行してみることにします。
$ cargo run -- pattern Cargo.toml Compiling rsgrep v0.1.0 (file:///home/kim/Rust/rsgrep) Finished dev [unoptimized + debuginfo] target(s) in 0.37 secs Running `target/debug/rsgrep Cargo.toml` [package] name = "rsgrep" version = "0.1.0" authors = ["Sunrin SHIMURA (keen) <3han5chou7@gmail.com>"] [dependencies]
[package]から始まる6行が、皆さんの手元にあるはずのCargo.tomlの内容と一致していれば成功です。
regexとcrates.io
指定したファイルの内容をすべて出力できるようになったところで、検索したい正規表現のパターンを指定できるようにしましょう。
ここまではstdクレートしか使っていませんが、Rustでは標準ライブラリ以外にもさまざまなクレートが利用可能です。それらは、crates.ioに登録されており、Cargoから手軽に扱えるようになっています。

crates.ioに登録されているクレートを使うには、Cargo.tomlを編集します。いまは正規表現が必要なので、crates.ioに登録されているregexクレートを使うように、次のように編集してください。
# ... # dependenciesに依存クレートを書く [dependencies] # regexの0.2.1かそれ以上の互換性のあるバージョンを使う regex = "0.2.1"
バージョンの指定では多彩な書き方が可能ですが、とりあえず欲しいバージョンを直に書いておけば大丈夫です。
この状態でビルドしてみましょう(runでもビルドが走りますが、いまは実行する必要はないのでbuildを使います)。
$ cargo build
Updating registry `https://github.com/rust-lang/crates.io-index`
Compiling regex-syntax v0.4.0
Compiling void v1.0.2
Compiling libc v0.2.21
Compiling utf8-ranges v1.0.0
Compiling unreachable v0.1.1
Compiling memchr v1.0.1
Compiling thread-id v3.0.0
Compiling thread_local v0.3.3
Compiling aho-corasick v0.6.3
Compiling regex v0.2.1
Compiling rsgrep v0.1.0 (file:///home/kim/Rust/rsgrep)
Finished dev [unoptimized + debuginfo] target(s) in 8.85 secs
上記のように、regexやその依存クレートをCargoがビルドしてくれます。
完成
regexクレートの機能を使って、rsgrepプログラムを完成させましょう。
stdではないクレートをプログラムから使うには、まずextern crate クレート名;で宣言が必要です。宣言したあとは、他のモジュールと同じようにプログラムから参照できるようになります(Unixファイルシステムのマウントにちょっと似ていますね)。
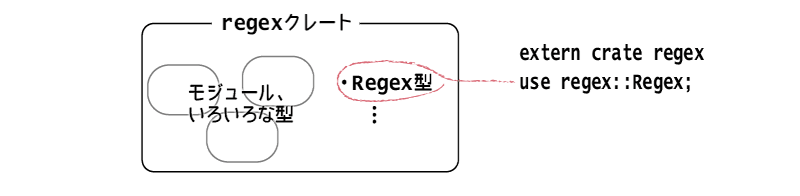
標準ライブラリ以外のクレート
先ほどのコードに、以下の内容を追記してください。
// regexを宣言 extern crate regex; // regexからRegex型をインポート use regex::Regex; // .. fn main { // 引数からパターンを取り出す let pattern = match env::args().nth(1) { Some(pattern) => pattern, None => { usage(); return; } }; // 取り出したパターンから`Regex`をあらためて作る // 無効な正規表現だった場合などにはエラーが返る let reg = match Regex::new(&pattern) { Ok(reg) => reg, Err(e) => { println!("invalid regexp {}: {}", pattern, e); return } }; // .. for line in input.lines() { // .. // パターンにマッチしたらプリントする // is_matchはリードオンリーなので参照型を受け取る if reg.is_match(&line) { // 上で参照型で引数に渡したので、ここでも使える println!("{}", line); } } }
上記を追記したら、ファイルとパターンを指定して実行してみましょう。
# '[' で始まる行を抜き出してみる $ cargo run -- '^[\[]' Cargo.toml Compiling rsgrep v0.1.0 (file:///home/kim/Rust/rsgrep) Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs Running `target/debug/rsgrep '^[\[]' Cargo.toml` [package] [dependencies]
ちゃんと動きました!
Rustで実践的な実装 その2. アナグラム
文字列を扱うプログラムを実直に書いてみたところで、もう少しスマートに書いたプログラムの例をお見せします。 ギアを上げていきますよ(ガチャン!)。
下記は、与えられた単語に対し、その文字を並べ変えてできる単語(アナグラム)を表示するプログラムです。例えば「eat」のアナグラムには「ate」「eat」「eta」「tea」などがあります。
並び替えた文字列が単語として存在するかどうか、辞書を使って調べる必要がありますが、たいていのUnix環境で用意されているスペルチェック用のファイル(words)を、辞書として利用します。
// 標準ライブラリにハッシュマップがある。 use std::collections::HashMap; use std::fs::File; use std::io; use std::io::BufRead; use std::path::Path; // (1) fn sorted_string(s: &str) -> String { let mut s = s.chars().collect::<Vec<_>>(); s.sort(); s.into_iter().collect::<String>() } // (2) struct Anagram(HashMap<String, Vec<String>>); impl Anagram { // トレイト境界`AsRef<Path>`は、ざっくり意訳すると「パス名っぽいもの」を表す // `Self`は、`Anagram`へのエイリアス fn new<P: AsRef<Path>>(dictfile: P) -> Result<Self, io::Error> { let file = File::open(dictfile)?; // ★ let file = io::BufReader::new(file); // ハッシュマップを準備しておく let mut anagram = Anagram(HashMap::new()); for line in file.lines() { let word = line?; // ★ anagram.add_word(word); } Ok(anagram) } // テーブルを更新するので`&mut self`を使う // 登録した単語をテーブルが所有するので、`word`の所有権も奪う fn add_word(&mut self, word: String) { // 単語をアルファベット順にソートしたものを作ってキーにする let sorted = sorted_string(&word); // キーに対応する値があればそれを、なければ新たにデフォルト値(Vec::new())を入れる // 返り値はキーに対応する値 // ハッシュマップはデータの所有者なので、キーもデフォルト値も所有権を奪う self.0.entry(sorted).or_insert(Vec::new()).push(word); } // 検索はリードオンリーなので`&self`を使う // キーはリードオンリーなので`word`も参照で受け取る fn find(&self, word: &str) -> Option<&Vec<String>> { let word = sorted_string(word); // データの所有権はハッシュマップにあるので、返り値は参照型 // 参照型なのでコピーは発生せず、高速 self.0.get(&word) } } fn main() { // 実行時にコマンドライン引数として単語を受け取る let word = std::env::args().nth(1).expect("USAGE: word"); // 辞書からAnagram構造体を作る // 多くのUnix環境では、このパスに辞書がある(ない場合は、手で辞書を準備してパスを変えてください) let table = Anagram::new("/usr/share/dict/words").expect("failed to make table"); println!("{:?}", table.find(&word)); }
(1)は、文字列中の文字をアルファベット順に並べ替える関数です。
まず、受け取った文字列から文字のイテレータを取り出し(chars())、文字からなるベクトルにしています(collect)。新しいsはVec<char>型になりますが、要素が文字であることは文脈から分かるので、Vec<_>という省略記法を使っています。
新しいsにmutをつけているのは、ソートで変更を加えるためです。ソートを行うsort()は、ミュータブルな参照としてsを受け取るので、sの値は変更されたあとでも使えます。
最後に、into_iter()を使って、文字のイテレータから文字列を作ります。into_iter()は所有権を奪うので、感覚的には、文字のベクトルを文字列に変化させているような形になります。
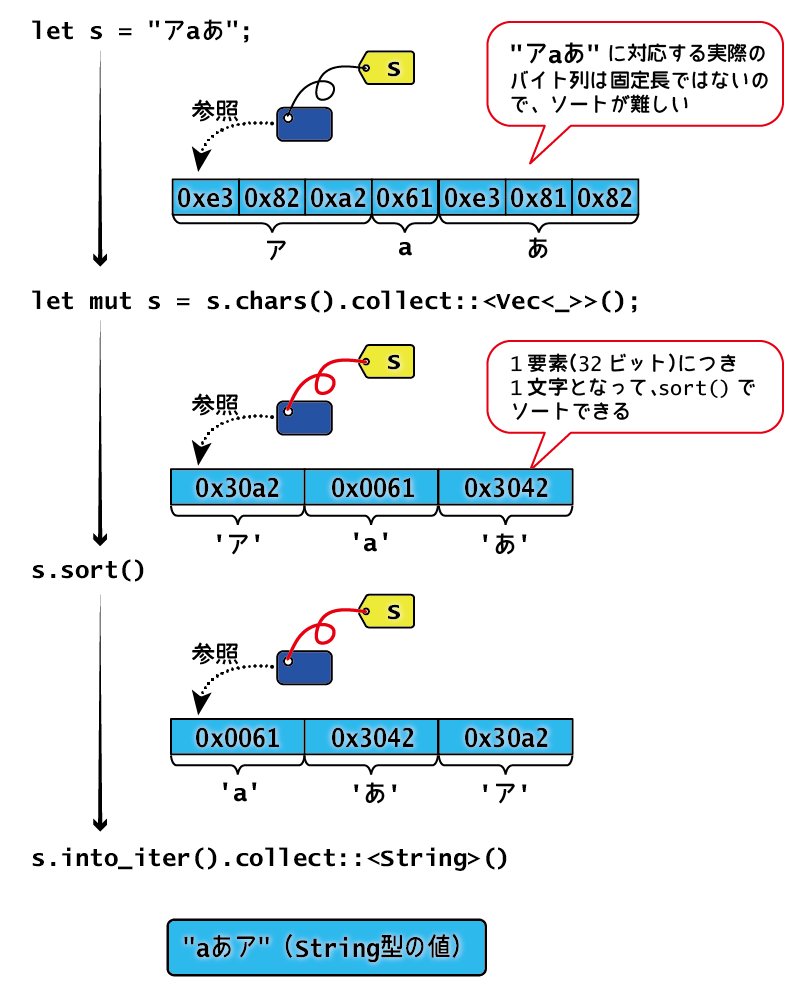
&strのままだとsort()を使えない
(2)では、Anagramという構造体を定義しています。この構造体のフィールドは、文字がアルファベット順に並んでいる文字列をキーとし、それに「キーを構成する文字を並び替えてできている単語」が対応しているハッシュマップです(HashMap<String, Vec<String>>)。
その実装では、そのようなAnagramを単語辞書から生成するnewおよびadd_wordメソッドと、キーから結果を探すfindメソッドを用意しています。
mainでは、コマンドライン引数から単語を取り出し、システムの辞書からAnagram構造体を作っています。そして、引数の単語をアルファベット順にした文字列をキーとして、Anagramからアナグラムのベクトルを探しています。
ここで、Rustのプログラミングで頻出するResultとOptionの使い方を、少し補足しておきます。mainのなかでは、1つ目のコマンドライン引数を取り出すのにstd::env::args().nth(1)としていますが、そのあとでexpect("[メッセージ]")としています。
std::env::args().nth(1)が返すのはOption型の値ですが、ResultやOptionで包まれている値は、このようにしてexpect("[メッセージ]")やunwrap()で無理矢理取り出せるのです。一見すると便利に見えますが、エラーの場合はそのままプログラムが終了(パニック)するので、mainの中以外ではあまり使ってはいけません。
「計算に成功したらその値を取り出し、失敗したらResultのErrで関数から抜ける」という処理が必要な場合は、?後置演算子が使えます。?後置演算子は、Anagram構造体のnewメソッドの実装で使ってます(★)。たとえばFile::open(dictfile)?では、openの結果はResultに包まれていますが、fileには単なるFile型が取り出せます。
Cargoでプロジェクトを作っているなら、次のようにして実行できます。
$ cargo run "ate" Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs Running `target/debug/anagram ate` Some(["ate", "eat", "eta", "tea"])
きちんとアナグラムが取り出せていますね!
Rustで実践的な実装 その3. HTTP/0.9
最後に、HTTP/0.9について、Rustによるサーバの実装例をお見せします{$annotation_1}。
ソケットやスレッドを使うことになるので、今までのサンプルコードより、「Rustっぽさ」を味わってもらえると思います。モジュールやテストについても少し触れてみます。ギアをさらに上げていきましょう(ガチャガチャ)。
まずはCargoで新しいプロジェクトを作ってください。
$ cargo new http_server --bin $ cd http_server
エコーサーバ
いきなりHTTPを実装するのではなく、最初はリクエストを受けてレスポンスを返すだけのTCPエコーサーバを作りましょう。main.rsを開いて以下のコードを記述してください。
use std::net::TcpListener; use std::thread; use std::io::{Read, Write}; use std::io; fn server_start() -> io::Result<()> { let lis = TcpListener::bind("127.0.0.1:8080")?; // (1) // (2) for stream in lis.incoming() { // (3) let mut stream = match stream { Ok(stream) => stream, // (4) Err(e) => { println!("An error occurred while accepting a connection: {}", e); continue; } }; // (5) let _ = thread::spawn( // (6) move || -> io::Result<()> { loop { let mut b = [0; 1024]; let n = stream.read(&mut b)?; if n == 0 { return Ok(()); } else { stream.write(&b[0..n])?; } }}); } Ok(()) } fn main() { match server_start() { Ok(_) => (), Err(e) => println!("{:?}", e), } }
server_start関数が、エコーサーバの本体です。
(1)では、TcpListener::bind("127.0.0.1:8080")により、IPv4ローカルホストのTCP 8080ポートをlisten/acceptしつづけるリスナーを作成しています。このリスナーはResultで包まれていますが、ここでは?後置演算子を使ってエラー時には単に関数から抜けるようにしています。
リスナーのメインループが(2)です。incomingはTcpListenerのメソッドで、「acceptを実行し、コネクションがあるたびにそれをストリームとして取り出す」というループを行います。
ストリームはやはりResultで包まれていますが、エラーが出てもループを継続したいので、ここでは?を使わずにパターンマッチでエラー時の処理を書いています((3))。具体的には、エラーが起きたらそれを通知して、再びループを繰り返します((4))。
エラーが起きなかったら、受け付けたストリームの内容を読み込んでクライアントに返す処理を実行します。このIO処理はブロックするので、リクエストを処理しつつ新たなコネクションを受け付けられるように、別スレッドを立てます。これにはthread::spawnを使います((5))。
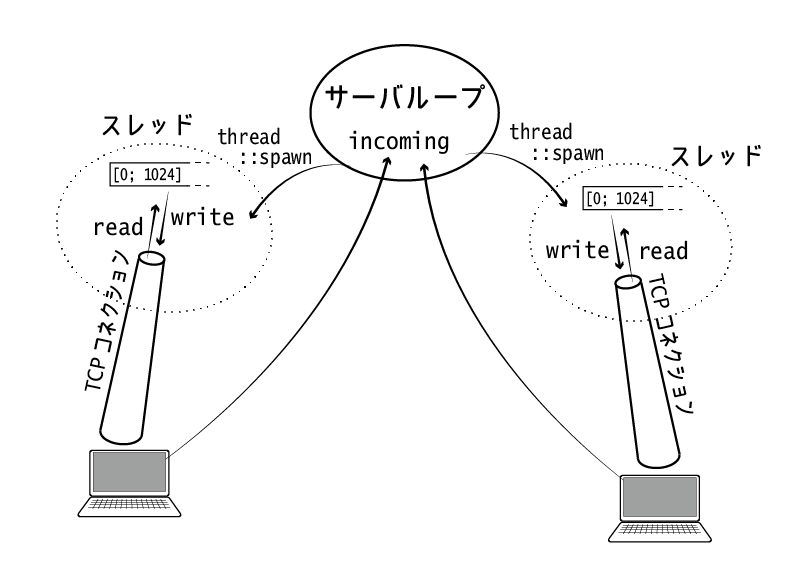
TCPコネクションは別スレッドで処理
thread::spawnは、引数としてクロージャを取り、スレッドハンドルを返します(この例では、spawnしたあとのスレッドは見捨てるので、_で受けています)。引数として渡すクロージャが、spawnしたスレッドで処理する仕事になります。
Rustでクロージャを生成するには下記の構文を使います(関数と違って、型を推論できるなら、引数の型や-> 返り値の型を省略できます)。
|引数| -> 返り値の型 { 本体 }
なお、moveというのは、クロージャが捕捉した変数(今回はstream)の所有権をクロージャにムーブするためのキーワードです。この例でthread::spawnに渡しているクロージャの内容((6))は、
- 1024バイトのバッファをスタックに確保して
- そのバッファにクライアントからの入力を読み込み
- 読み込んだバイト数が0ならストリームの終了(スレッドから抜ける)
- それ以外であれば読み込んだバッファの内容を書き戻す
という処理になります。
シェルからcargo runを実行して、このTCPエコーサーバを動かしてみましょう。
サーバが起動したら、別のターミナルを開いてローカルホストの8080ポートにtelnetで接続し、何か文字列を送信してみてください。
$ cargo run # 以下は別のターミナルから実行 $ telnet 127.0.0.1 8080 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. Hello Hello # Ctrl+]で抜ける
HTTP/0.9のリクエストをパースする
いま作ったTCPエコーサーバを、HTTP/0.9サーバへと仕立てていきましょう。まずは、HTTP/0.9のリクエストを解釈するためのパーサを作ります。
パーサのコードは、サーバ本体のコードとは別ファイルに分けることにします。別ファイルにするので、ここで定義した関数などをmain.rsでそのまま自由に利用することはできません。http_serverクレートのモジュールにし、上位のモジュールであるmain.rsから見えるようにしたいものにはpubをつける必要があります。
今回も、まずはコード全体をお見せしましょう。現状、src以下には先ほどエコーサーバを実装したmain.rsのみがあると思いますが、同じディレクトリに新たにparser.rsというファイルを作り、下記のコードを記述してください。
下記のコードでは、バイト列を受け取ってパースし、その結果を返す、parse関数を定義しています。
use std::str::from_utf8; // (1) pub enum ParseResult<T> { Complete(T), Partial, // 簡単のため今回はエラーデータを省略 Error, } // (2) impl<T> ParseResult<T> { fn is_complete(&self) -> bool { use self::ParseResult::*; // ★ match *self { Complete(_) => true, _ => false } } fn is_partial(&self) -> bool { use self::ParseResult::*; // ★ match *self { Partial => true, _ => false } } } // (3) impl<T, E> From<Result<T, E>> for ParseResult<T> { fn from(r: Result<T, E>) -> Self { use self::ParseResult::*; // ★ match r { Ok(t) => Complete(t), Err(_) => Error, } } } // (4) pub struct Request<'a>(pub &'a str); // (5) pub fn parse(mut buf: &[u8]) -> ParseResult<Request> { use self::ParseResult::*; // ★ // b".." は、バイト列リテラル let get = b"GET "; let end = b"\r\n"; // GET がこなければエラー if !buf.starts_with(get) { return Error; } // GET をパースした残りは、パスネームと\r\n buf = &buf[get.len()..]; if buf.ends_with(end) { buf = &buf[0..buf.len() - end.len()] } else { // 末尾が\r\nでなければ、入力が完了していないとみなす // 本当は途中に\r\nがある可能性もあるが、簡単のためスルー return Partial; } // from_utf8で、&[u8]から&strが作れる。データのコピーはしない // ただし失敗するかもしれないので、返り値はResultに包まれる from_utf8(buf) // タプル構造体は関数としても扱える // Result<&str, Utf8Error> -> Result<Request, Utf8Error> .map(Request) // Fromを実装したのでIntoのintoメソッドが自動で実装されている // Result<Request, Utf8Error> -> ParseResult<Request> .into() }
(1)では、ParseResultという列挙型をジェネリクスとして定義しています。このParseResultは、パース結果を包むのに使います。パーサでは、成功と失敗のほかに「パースの途中で入力が終わってしまった」もあり、Resultが使えないので、このように自前で定義しています。
ParseResult型の実装では、is_completeとis_partialというメソッドを定義しておきます((2))。これらのメソッドにはpubがついていないため、上位のモジュールからは見えません。
メソッド定義の中でuse self::ParseResult::*;としているのは(★コメントの部分)、この列挙型ParseResultの列挙子をインポートするという意味です(このselfはparserモジュールを指しています)。こうすることで、以降ではParseResult::CompleteなどとせずにCompleteのように書けます。
さらに、標準ライブラリのFromトレイトをParseResultに実装しておきます((3))。これにより、普通のResultをParseResultに変換できるようになります。
(4)のRequestは、パース結果を表す構造体です。ここではタプル構造体として定義しました。構造体のフィールドも上位のモジュールから利用するので、フィールドにもpubを付けています。
構造体の定義で'aというパラメータが使われているのは、&strのライフタイムを越えてRequestが参照されないように、参照のライフタイムを明示するためです。このような'で前置されたパラメータをライフタイムパラメータといいます。ライフタイムも、型と同じようにして、プログラム上で扱えるというわけです。
最後に、(5)でparse関数を定義しています。HTTP/0.9のリクエストはGET path\r\nという形をしているので、それをパースしてParseResultで包んで返します。そもそもHTTP/0.9が非常に単純なプロトコルなのでパースがやさしいこともありますが、Rustがバイト列も楽に扱えるのもあり、最低限のパーサが簡単に書けてしまいました。
このパーサでは、メモリ上のデータのコピーが一切発生していない点にも注目してください。parse関数のうち、from_utfで&[u8]から&strを作る部分を下記に図示しました。Rustでは、スライスなどの機能のおかげで、このように非常に高速にデータを扱えるのです。
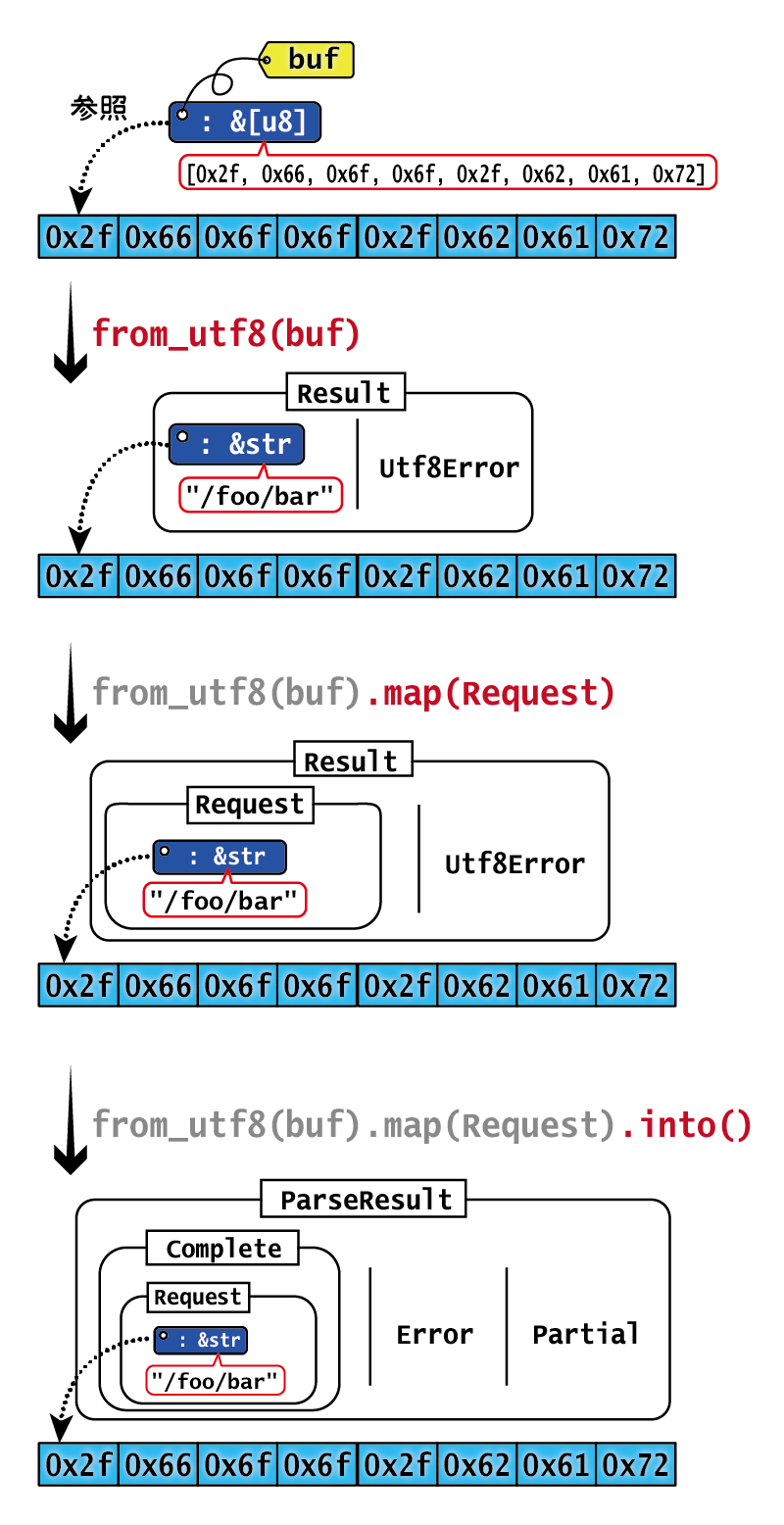
from_utfで&[u8]から&strを作る
パーサのテスト
このパーサをイベントループに繋ぐ前にテストしましょう。パーサのように仕様が明確で副作用がなく入力を簡単に用意できるものは必ずテストすべきです。
Rustのテストはいくつか書き方がありますが、最も手軽なのは同じファイルにテストを書く方法です。以下のコードを先ほどのparser.rsの末尾に追記しましょう。
// `#[..]`でその次にくるアイテムに「アトリビュート」をつけられる // `#[test]`アトリビュートでアイテムがテストであることをコンパイラに伝える #[test] fn http09_get_success_root() { let req = b"GET /\r\n"; let res = parse(req); // テストの中身では主に`assert`マクロを使い何もなければok、パニックならfailとなる assert!(res.is_complete()); } #[test] fn http09_get_success_foo_bar() { let req = b"GET /foo/bar\r\n"; let res = parse(req); assert!(res.is_complete()); } #[test] fn http09_get_partial_root() { let req = b"GET /\r"; let res = parse(req); assert!(res.is_partial()); } // テストに`should_panic`アトリビュートをつけることでパニックしたらok、しなかったらfailとなる #[test] #[should_panic] fn http09_post_failure() { let req = b"POST /\r\n"; let res = parse(req); assert!(res.is_complete()); }
簡単ですね。
テストを走らせるのも簡単です{$annotation_2}。
$ cargo test Compiling http_server v0.1.0 (file:///home/kim/Rust/http_server) Finished dev [unoptimized + debuginfo] target(s) in 0.41 secs Running target/debug/deps/http_server-1089f94604346b27 running 4 tests test parser::http09_get_partial ... ok test parser::http09_get_success_foo_bar ... ok test parser::http09_post_failure ... ok test parser::http09_get_success_root ... ok test result: ok. 4 passed; 0 failed; 0 ignored; 0 measured
同じファイルにテストを書くと、プライベートな関数などもテストができ、便利です。
parserモジュールを使う
parser.rsは、この時点では、いま開発しているhttp_serverクレートには所属していません。main.rsでparser.rsを使うには、main.rsの先頭にこう書きます。
mod parser; // 以降は同じ use std::net::TcpListener; // ...
これで、http_serverクレートに、parserモジュールという形でparser.rsが加わりました。2つのファイルの関係は、以下のように、main.rsをルートとしてparser.rsが子になっています。
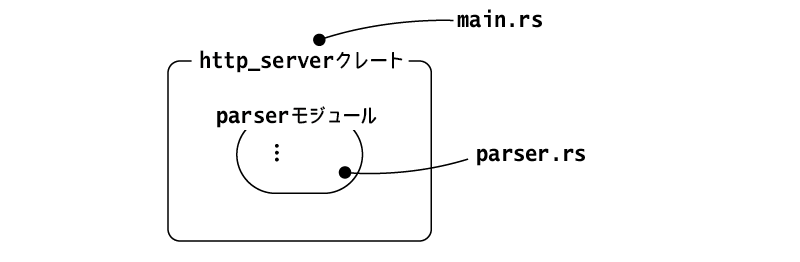
TCPコネクションは別スレッドで処理
Rustのモジュールについては、ひとまず次の2点をおさえておきましょう。
- 新たにファイルを作ると、プログラム上はモジュールとして管理される
- モジュールは、
main.rs(libクレートならlib.rs)をルートとした階層構造になる
ディレクトリを作るとまたモジュールが作られ、mod.rsなどのファイルも出てきます。その他、モジュールについての詳細は、ドキュメント『プログラミング言語Rust』の「クレートとモジュール」を参照してください。
エコーサーバをHTTPサーバに改修
あとは、スレッドに渡していたクロージャを次のように書き換えれば、クライアントからのリクエストをHTTPのメソッドとしてパースして処理結果を返すサーバの土台が完成です。
move || -> io::Result<()> { use parser::ParseResult::*; // リクエスト全体を格納するバッファ let mut buf = Vec::new(); loop { // 1回のread分を格納する一時バッファ let mut b = [0; 1024]; // 入力をバッファに読み込む // nには読み込んだバイト数が入る let n = stream.read(&mut b)?; if n == 0 { // 読み込んだバイト数が0ならストリームを終了してスレッドから抜ける return Ok(()); } // リクエスト全体のバッファに、いま読み込んだ分を追記 buf.extend_from_slice(&b[0..n]); // それ以外ではHTTP/0.9のリクエストの処理 match parser::parse(buf.as_slice()) { // 入力の途中なら新たな入力を待つため次のイテレーションへ Partial => continue, // エラーなら不正な入力なので何も返さずスレッドから抜ける // スレッドから抜けると stream のライフタイムが終わるため、コネクションが自動で閉じられる Error => { return Ok(()); }, // リクエストが届けば処理をする Complete(req) => { // レスポンスを返す処理をここに書く // 本来はファイルの中身を返すが、ここではリクエストの内容を含んだ文字列を返す write!(stream, "OK {}\r\n", req.0)?; // 処理が完了したらスレッドから抜ける return Ok(()); }, }; } }
さっそく動かしてみましょう。
$ cargo run # 以下は別のターミナルから実行 $ telnet 127.0.0.1 8080 Trying 127.0.0.1... Connected to 127.0.01. Escape character is '^]'. GET /foo/bar OK /foo/bar Connection closed by foreign host.
本来ならGET /foo/barというHTTPリクエストに対しては該当するファイルの中身を返すべきですが、それは練習問題と思って自身で書いてみてください。ファイルの中身を返すだけなら難しくないと思います。
発展課題にチャレンジ
さらに発展的な内容として、以下のような課題にチャレンジしてみても面白いかもしれません。今回のmainでは使う機会がなかったis_completeやis_partialもうまく使ってみましょう。
- ☆ ディレクトリトラバーサル対策をする
- ☆☆ HTTP/1.0のヘッダもパースする
- ☆☆ パス名を使ったルーティングを実装してアプリケーションを作ってみる
- ☆☆☆ スレッドや
Vecを前もって確保しておいて、コネクションがあるたびに作らないようにする - ☆☆☆☆ set_nonblockingなどを使ってノンブロッキング化してみる
もちろん、Rustには既に、HTTPパーサや、Webアプリケーションフレームワーク、非同期ライブラリ、などが存在するので、実用的なHTTPサーバを自分で作る必要は特にないともいえます。
しかし、こうした課題に挑戦してみることで、普段は意識しないライブラリの中身を知るよい機会になるはずです。
今回のHTTPサーバのコードは、私のGitHubに置いてあります。練習問題や発展課題の一部を実装したブランチもあるので練習と答え合わせに利用してみてください。

結びに代えて
限られたボリュームの中、駆け足でプログラミング言語Rustの基本を一通り眺めてきました。Rustの所有権の概念、強力なトレイト、ゼロコスト抽象化、オーバーヘッドの少ないライブラリ設計などについて概略が伝わったなら幸いです。
最後に、この記事でRustをもっと使いたいと思った方向けに、今後の学習方法や参照するとよいサイトを紹介します。
- ▼ The Rust Programming Language

- ドキュメントを読みたいなら、本稿で説明しきれなかったイテレータ、パニック、マクロ、Dropといった多くの機能が載っている本書の一読をぜひお勧めします。コミュニティによる和訳版『プログラミング言語Rust

- ▼ std - Rust

- 標準ライブラリのリファレンスです。特に`Vec`や`String`のドキュメントには何度もお世話になるでしょう。
-
Rust by Example

- コードを読みつつ学習したいときにお勧めです。こちらも、コミュニティによる和訳版

-

- 各地で勉強会などが開催されています。関東地方であればconnpassの「Rustグループ」に参加しておくとよいでしょう。
-
- 質問できる人がほしいのなら、日本Rustユーザが集うSlackに参加するとよいでしょう。ここから誰でも参加できます。
Rustはまだ比較的新しい言語で、1.0.0がリリースされてまだ2年ほどしか経っていません。それでも、6週間に1度リリースするサイクルをずっと続けており、この間にずいぶんと進化しました。新しいライブラリも次々に出てきています。みなさんが作ったライブラリがデファクトスタンダードになる日がくる可能性もあります。
この記事を読んでRustに興味を持った方は、Rustの世界に飛び込んでみてください。私もRust界隈でいろいろ手掛けているので、Rustによるプログラミングを続けていればお目にかかることがあるかもしれません。そのときにまたお会いしましょう。
執筆者プロフィール
κeen(


1992年生まれ。好きな言語はRustのほかにはLisp、ML、Shell。現Idein Incのエンジニア。Ideinでは社内インフラや自社サービスをRustで開発する。プライベートではRustでOSSやコンパイラを開発するほか、Rustの公式ドキュメントや公式Webサイトの翻訳など。自宅のGCアルゴリズムは投機的Sweep。
編集協力:鹿野桂一郎(しかの・けいいちろう、Twitter) 技術書出版ラムダノート
【2017年7月19日18時 修正】ご指摘により、最初のコードにあった// T = isize, S = f64で呼び出すというコメントを、// T = i32, S = f64で呼び出すと修正しました。
【2017年8月9日21時 修正】ご指摘により、ソースコード中のエラーメッセージにあった誤字を修正いたしました。
【2017年10月31日21時 修正】ご指摘により、「パーサのテスト」セクションの後半の本文「テストを走らせるのも簡単です。」の文末に脚注を追記しました。
*1:HTTP/0.9は、1991年に文書化(https://www.w3.org/Protocols/HTTP/AsImplemented.html)された最初期のHTTP仕様。メソッドはGETのみで、レスポンスコードも規定されてない。
*2:実際には、この時点ではまだparserはクレートに入っていないため、パーサのテストは下記の「parserモジュールを使う」の後でないと走りません。




