
なぜ、SQLは重たくなるのか?──『SQLパフォーマンス詳解』の翻訳者が教える原因と対策
『SQLパフォーマンス詳解』の翻訳者の松浦隼人さんに、8つの「SQLが重たくなる原因とその対策」を聞きました。システムのボトルネックになるような「問題のあるSQL」を回避するノウハウを学びましょう。
データの操作や定義をする言語「SQL」は、どのような領域を担うエンジニアにとっても必修科目です。しかし、その仕様をきちんと理解し、パフォーマンスに優れたSQLを書ける方はそれほど多くありません。問題のあるSQLを書いてしまい、知らぬ間にそれがシステムのボトルネックになってしまう事態はよく発生します。
では、どうすればそうした事態を回避できるのでしょうか? そのノウハウを学ぶため、今回は『SQLパフォーマンス詳解』の翻訳者であり、自身もエンジニアでもある松浦隼人(まつうら・はやと/@dblmkt)さんに8つの「SQLが重たくなる原因とその対策」について聞きました。実地で技術を磨き上げたスペシャリストが語る珠玉のメソッド、全エンジニアにとって必見の内容です。
- 【原因(1)】ORMが生成するSQLを確認していない
- 【原因(2)】複合インデックスを適切に使えていない
- 【原因(3)】複合インデックスの走査範囲を考慮していないため、大なり小なり記号やBETWEENが遅い
- 【原因(4)】LIKE句において、ワイルドカードが文字列の前方についている
- 【原因(5)】テーブル結合が不得意なデータベースで、テーブル結合を多用している
- 【原因(6)】ORDER BY / GROUP BYで、大量のソートが発生している
- 【原因(7)】データ量が増えると処理が重たい。「良くないSQL」を書いているから
- 【原因(8)】複数クエリの総実行時間が長い
- 大切なのは、データベースの仕組みを理解すること
【原因(1)】ORMが生成するSQLを確認していない
──本日はよろしくお願いします! 1つ目は、「ORMが生成するSQLを確認していない」。これは特に、若手エンジニアの場合はやってしまいがちかもしれないですね。
松浦 そうですね。ORMは、どんなときでも適切なSQLを生成する魔法のツールではありません。使い方を工夫しなければ、効率の悪いSQLが生成されてしまうケースだってあるんです。だからこそ、その内容をきちんと確認することが重要になってきます。

松浦隼人さん
──「効率の悪いSQL」の例は、どのようなものがありますか?
松浦 最も有名なのは、「N+1問題」です。たとえば、データベース内にあるブログ記事の情報を取得するケースを考えてください。
それぞれのブログ記事には、「料理」とか「日記」などのタグが紐づいており、タグ情報は別テーブルにあるとします。通常であれば、全データを取得する際にはJOIN句を用いるなどして、1つのSELECT文だけでこと足りるでしょう。
しかしORMの場合、仮に10記事取得するケースだとSELECT文が「1回(記事一覧を取得)+10回(各記事に紐づくタグを取得)=合計11回」発行されてしまうことがあります。これがN+1問題です。この問題が発生すると、クエリ数が指数関数的に増え、パフォーマンス劣化につながってしまいます。
──それを避けるには、何をすればいいのでしょうか?
松浦 有名なORMのほとんどには、JOIN句を生成するなどN+1問題を回避するための機能が備わっています。その機能をきちんと理解し、適切に使用するといいでしょう。
もしORMの機能を使っても問題が避けられない場合には、素のSQL文を実行することも検討すべきです。もちろんその際には、検索条件に設定される値によってSQLインジェクションが発生しないか、チェックを忘れないようにしてください。
【原因(2)】複合インデックスを適切に使えていない
──次は、「複合インデックスを適切に使えていない」。どのようなときに、この問題は発生するのでしょうか?
松浦 たとえば、社員の情報が格納されたテーブルがあり、複合インデックスとして(社員ID, 部署ID)を設定しているとします。このテーブルに対し、「部署ID」のみをWHERE句条件に指定した場合には、インデックスが無効になってしまうんです。
なぜかというと、データベースは複合インデックスのエントリをソートする際、インデックスの定義に書かれている順序に従って列を識別するためです。つまりこの場合は、インデックスが作成される際に「社員ID」の列がまずソートされ、「社員ID」に同じ値が複数あるときに限り「部署ID」の列もソートされます。
そして、検索も「社員ID」⇒「部署ID」の順で実施されるため、「部署ID」だけではインデックスが効かないというわけです。
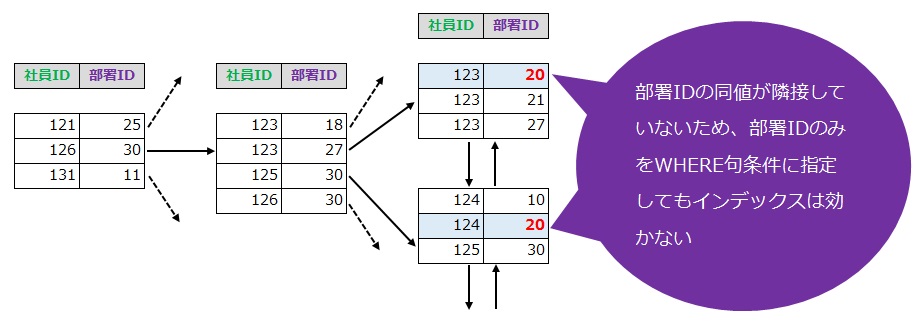
四角形の各ブロックはインデックスツリー内にあるノードを示す。 (社員ID, 部署ID)という複合インデックスが張られている場合、社員IDの同値は隣接しているものの、部署IDの同値は隣接しているわけではない。このようなツリーでは、 2番目の列だけで検索するクエリは役に立たなくなる
──この問題を避けるには、どのような対策を取るべきですか?
松浦 「どのようなWHERE句が使用されるケースが多いのか」を事前にリサーチし、それに沿った形でインデックスを張ることが重要になります。たとえば、WHERE句の条件に「部署ID」が使用されるケースが多いならば、(部署ID, 社員ID)という順の複合インデックスにした方が効果的でしょう。
むやみに複合インデックスを張っても、パフォーマンスは改善されません。データベースが利用される状況に応じて、適切な複合インデックスを張ることが大切なんです。
【原因(3)】複合インデックスの走査範囲を考慮していないため、大なり小なり記号やBETWEENが遅い

松浦 「大なり小なり記号やBETWEENが遅い」というのも、先ほど解説した複合インデックスに関連したものです。たとえば、社員の情報が格納されたテーブルがあり、複合インデックスが(誕生日, 部署ID)で設定されているとします。
この場合にWHERE句として「誕生日(BETWEEN句)」「部署ID」を使用した場合、まずはBETWEEN句により誕生日の大小比較の走査が走り、その後に部署IDが走査されるため、検索される範囲が非常に広くなってしまうんです。
これを避けるには、(部署ID, 誕生日)という順の複合インデックスに変えることがおすすめです。そうすることで、部署IDが合致したデータのみ誕生日によるBETWEEN検索がかかるため、走査する範囲が小さくなります。
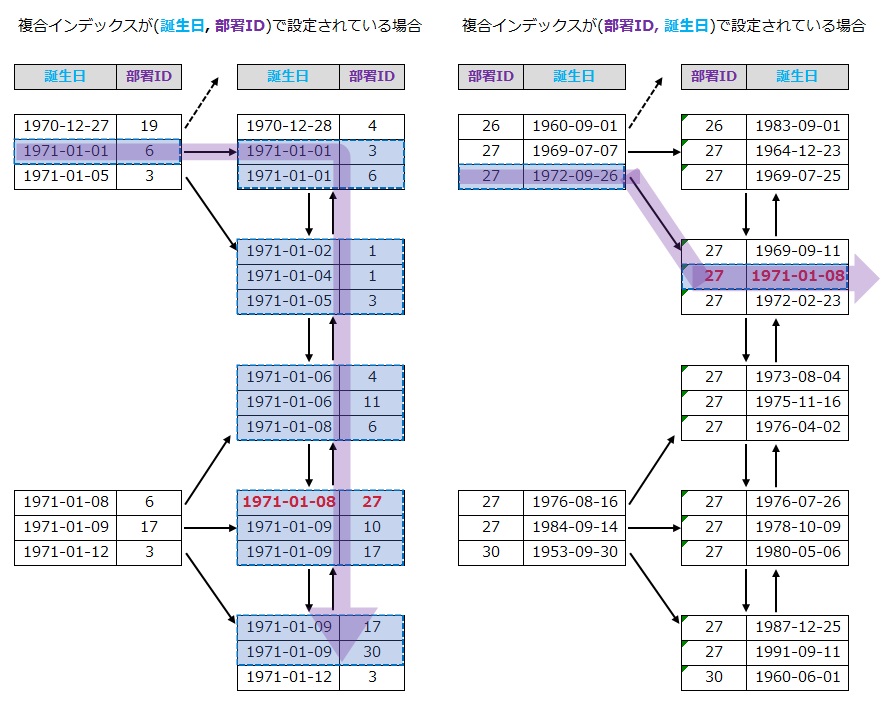
四角形の各ブロックはインデックスツリー内にあるノードを示し、青枠は走査される範囲を示す。「誕生日 1971-01-01~1971-01-09」「部署ID 27」という条件で検索した場合、走査される範囲にはこれだけの差が生じる
──なるほど! 確かにその通りですね。
松浦 要するに、インデックスのどこからどこまでが走査されるのかをイメージしてWHERE句条件を指定しなければ、ムダなアクセスが発生する可能性があるということなんです。
【原因(4)】LIKE句において、ワイルドカードが文字列の前方についている
松浦 これは簡単に言うと、LIKE句の%(ワイルドカード)を使用する際に、データベース内でどのような走査がされているのかを理解しなければ、非効率的な検索となってしまうということです。実は、インデックスの走査においてLIKEが有効なのは、ワイルドカードの前までなんです。
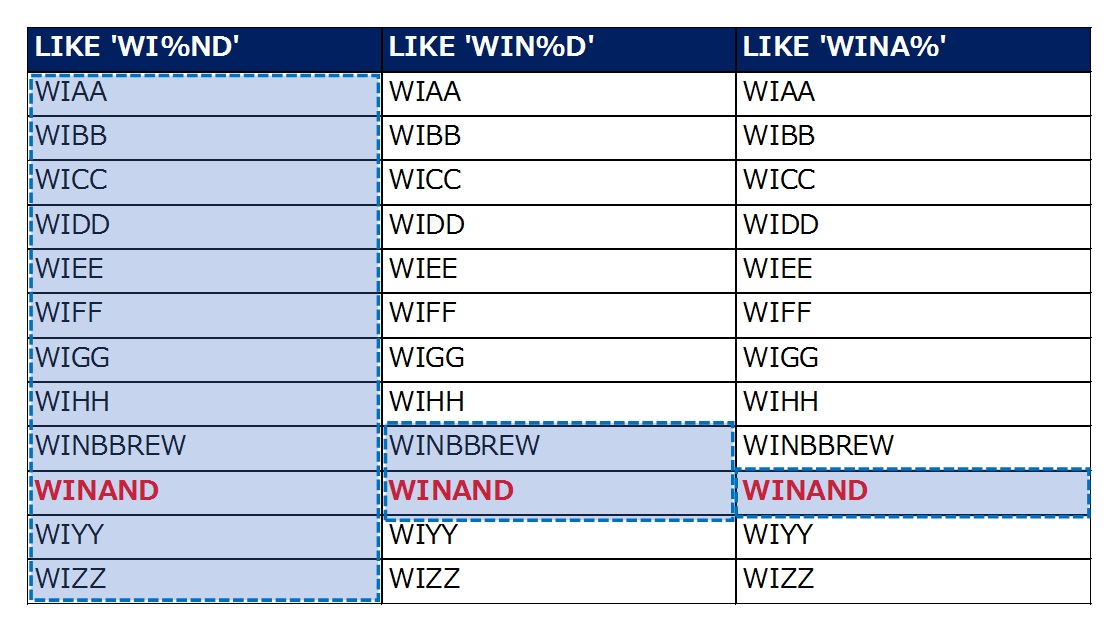
青枠は走査される範囲を示す
たとえば「LIKE 'WIN%D'」のように真ん中に%を入れた場合、%の前である「WIN」まではインデックスが効きます。一方で、「LIKE '%WIND'」のように%が前方につく「後方一致検索」の場合ですと、インデックスは無効となり非常に重たいクエリになってしまいます。
──その前提があったとして、「それでも後方一致検索をしたい」場合には、どうすれば良いのでしょうか?
松浦 そこまでいくとリレーショナルデータベースが苦手とする領域になるので、代わりにElasticsearchやApache Solrなどの全文検索システムを使うことが必要になります。つまり、リレーショナルデータベースが得意な検索条件と苦手な検索条件を理解しているからこそ、これらのツールを適切に使いわけることが可能になるんです。
【原因(5)】テーブル結合が不得意なデータベースで、テーブル結合を多用している
──「テーブル結合が不得意なデータベース」とは、どういうことですか?
松浦 これは、「対応できるテーブル結合のアルゴリズムが少ないデータベース」と言い換えた方がいいかもしれません。
よく使われるテーブル結合のアルゴリズムには「ネステッドループ結合(Nested Loop Join)」「ハッシュ結合(Hash Join)」「ソートマージ結合(Sort Merge Join)」という3種類があります。この中で、最もテーブル結合の処理が遅くなる可能性が高いのが「ネステッドループ結合」です。これは、1つ目のテーブルの各行に対して、2つ目のテーブルの対応値を引き当てるアルゴリズムです。
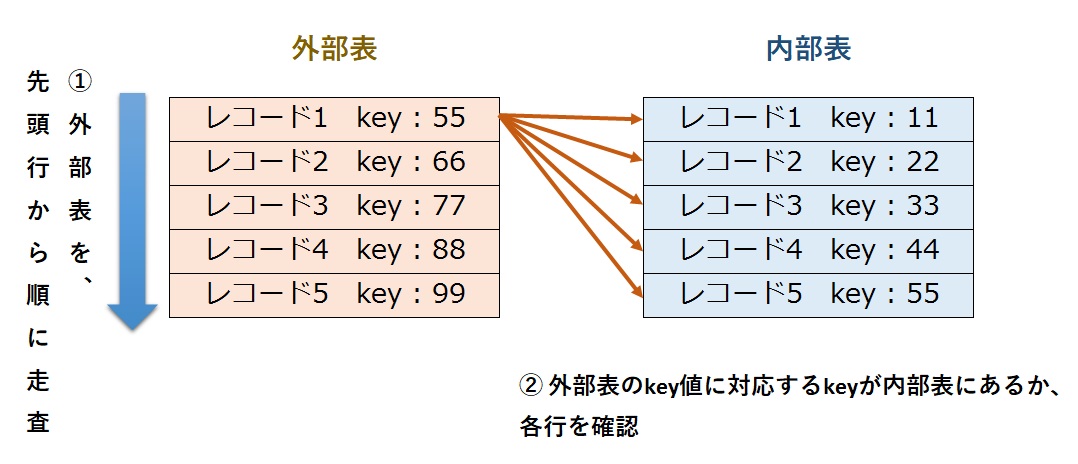
ネステッドループ結合の概念図
この手法を用いたときには、最悪の場合、1つ目のテーブルの行数分だけ2つ目のテーブルのソートと走査が発生する可能性があります。アルゴリズムの仕組みはシンプルなのですが、処理が重くなってしまいがちです。そして実は、MySQLはテーブル結合にこのアルゴリズムしか使えません。
──そうだったんですか! MySQLで他のアルゴリズムを利用できないのはどうしてですか?
松浦 MySQLは、「複雑なアルゴリズムはなるべくサポートしない」という設計思想に基づいて作られているからです。その代わりに、「よく使われる機能を高速にすること」を重視しています。よく性能を比較されるPostgreSQLとの違いはそこにあります。
たとえば、テーブル結合を使わないシンプルなSQL文の実行速度は、PostgreSQL よりもMySQLの方が上です。こうした情報を知っておくと、データベースを選定する際にも役立つと思います。
【原因(6)】ORDER BY / GROUP BYで、大量のソートが発生している
松浦 ORDER BYやGROUP BYは、どちらもデータのソートが必要な処理です。ソートをする際には、データをメモリ上に展開し大小比較をして並べ替えるのですが、この処理にはメモリもCPUもたくさん必要になります。そして、処理に必要なメモリとCPUの量は、データが多くなればなるほど指数関数的に大きくなっていきます。
──なるべく処理の負荷が大きくならないようにするには、どのような方法をとるべきですか?
松浦 「インデックスを張った列をORDER BYやGROUP BYに使用する」というのは基本テクニックになります。なぜかというと、インデックスを張った列は既にソートがされているので、並べ替える処理が不要だからです。

『SQLパフォーマンス詳解』の各ページを開きながら、松浦さんはSQLやデータベースの仕組みを丁寧に解説してくれた
──とはいえ、実務の中ではインデックスが張られてない列に対してORDER BYやGROUP BYをかけるケースは発生すると思います。その場合にはどうすればいいのでしょうか?
松浦 「適切なWHERE句を書くことで、処理対象となるデータの量を少なくする」ということが重要になってきます。そうすることで、使用するメモリやCPUの量が少なくなり、サーバにかかる負荷が軽減されるからです。
【原因(7)】データ量が増えると処理が重たい。「良くないSQL」を書いているから
松浦 データ量が少ないうちは、不適切なSQLでも実行速度はそれほど落ちません。けれどデータ量が増えるにつれて、データがメモリに乗らないとかCPUの使用率が高くなるという問題が発生し、処理が重たくなってきます。
その状態になったときには、ここまで解説してきたような「良くないSQL」を書いている可能性が高いです。それぞれの項目を、再度見直してみると良いかもしれません。

──データ量が増えるにつれて、隠蔽されていた問題が顕在化してくるわけですね。
松浦 はい。よくあるパターンとしては、開発環境で少ないデータで試した際には問題がなかったのに、本番環境にアプリをデプロイして大量データを処理した際に、問題が発生するというケースです。
それを避けるには、開発環境でもなるべく本番環境と同等のデータを使うことをおすすめします。その例として、近年大きなIT企業では、「個人情報などがわからないようにマスキングした上で、本番環境のデータを開発環境に持ってくる」ケースが多くなっています。
──なるほど。結局、本番環境で発生する不具合を発見するには、本番環境と同じようなデータを使うことが近道なんですね。
【原因(8)】複数クエリの総実行時間が長い
──最後は、「複数クエリの総実行時間が長い」。これはどういうことですか?
松浦 たとえば、「処理に10秒かかるクエリを、1分間に1回だけ実行する」場合と、「処理に0.1秒かかるクエリを、1秒に10回×60秒間実行する」場合を比較してください。
前者は、1分間に10秒しかCPUを使っていませんが、後者は60秒間継続的にCPUを使っていることがわかるでしょうか。要は、この後者のようなパターンがマズいということです。
──なるほど。つまり、クエリ単体を見た場合には前者の方がパフォーマンスに問題を抱えているようですが、実は後者の方が問題としては根深い、というわけですね。
松浦 はい。この例のように、「処理が重たいけれど、たまにしか発行されないクエリ」を改善するよりも「処理が軽いけれど、頻繁に発行されるクエリ」を改善した方が効果的なケースも多いです。
これを実現するには、アプリケーションの仕様そのものを変えてSQLの実行回数を減らすとか、さまざまなキャッシュの仕組みを使って物理的なアクセスを減らすといった方法がおすすめです。
──データベースの専門家である松浦さんのノウハウ、本当に参考になりました。今回はどうもありがとうございました!
大切なのは、データベースの仕組みを理解すること
松浦さんが解説してくれたノウハウ全てに共通しているのは、「データベースの仕組みを理解すること」の重要さです。
どのようなアルゴリズムで検索や更新がされているのか。そのアルゴリズムはどういった利点や欠点を抱えているのか。それらを理解した上でクエリを書けば、SQLのパフォーマンスは劇的に改善します。
今回学んだ内容を元にして、優れたSQLを書けるようになっていきましょう。
松浦隼人/@dblmkt
Linuxサーバのサポート、フィールドエンジニアとして働く中でリレーショナルデータベースの重要性に気づき、大規模なデータを扱うサービスに関わるべくサイバーエージェントに入社。同社の各種Webサービスのインフラエンジニアとして、MySQLを中心とした各種ミドルウェアを使ったシステムの構築や運用に携わる。現在はGitHubにて、企業向けの技術サポートエンジニアとして勤務。英語と日本語の情報量の格差をできる限り小さくしたいという思いから、本業のかたわら、英語の情報を翻訳して紹介するYakstを主宰する。
Linuxサーバのサポート、フィールドエンジニアとして働く中でリレーショナルデータベースの重要性に気づき、大規模なデータを扱うサービスに関わるべくサイバーエージェントに入社。同社の各種Webサービスのインフラエンジニアとして、MySQLを中心とした各種ミドルウェアを使ったシステムの構築や運用に携わる。現在はGitHubにて、企業向けの技術サポートエンジニアとして勤務。英語と日本語の情報量の格差をできる限り小さくしたいという思いから、本業のかたわら、英語の情報を翻訳して紹介するYakstを主宰する。
取材:中薗昴(サムライト)/写真:小堀将生




